Mediuri sandbox izolate, concepute pentru a valida, evalua și depana modelele și aplicațiile de inteligență artificială înainte de implementarea în producție. Aceste spații controlate permit testarea performanței conținutului AI pe diferite platforme, măsurarea metricilor și asigurarea fiabilității fără a afecta sistemele live sau a expune date sensibile.
Mediu de Testare AI
Mediuri sandbox izolate, concepute pentru a valida, evalua și depana modelele și aplicațiile de inteligență artificială înainte de implementarea în producție. Aceste spații controlate permit testarea performanței conținutului AI pe diferite platforme, măsurarea metricilor și asigurarea fiabilității fără a afecta sistemele live sau a expune date sensibile.
Definiție & Concept de Bază
Un Mediu de Testare AI este un spațiu computațional controlat și izolat, proiectat pentru a valida, evalua și depana modelele și aplicațiile de inteligență artificială înainte de implementarea în sistemele de producție. Acesta funcționează ca un sandbox unde dezvoltatorii, data scientist-ii și echipele QA pot rula în siguranță modele AI, testa diferite configurații și măsura performanța conform unor metrici predefinite, fără a afecta sistemele live sau a expune date sensibile. Aceste medii replică condițiile din producție, menținând totodată izolarea completă, permițând echipelor să identifice problemele, să optimizeze comportamentul modelelor și să asigure fiabilitatea în diverse scenarii. Mediul de testare acționează ca o poartă critică de calitate în ciclul de viață al dezvoltării AI, făcând legătura între prototiparea experimentală și implementarea la nivel enterprise.
Componente Cheie & Arhitectură
Un Mediu de Testare AI complet cuprinde mai multe straturi tehnice interconectate care lucrează împreună pentru a oferi capabilități de testare complete. Stratul de execuție a modelului se ocupă de inferența și calculul propriu-zis, suportând mai multe framework-uri (PyTorch, TensorFlow, ONNX) și tipuri de modele (LLM-uri, viziune computerizată, serii temporale). Stratul de management al datelor gestionează seturile de date de test, fixture-urile și generarea de date sintetice, asigurând izolarea datelor și conformitatea. Framework-ul de evaluare include motoare de metrici, biblioteci de aserții și sisteme de scorare care măsoară ieșirile modelelor față de rezultatele așteptate. Stratul de monitorizare și logging captează urmele execuției, metrici de performanță, date de latență și loguri de erori pentru analiza post-test. Stratul de orchestrare gestionează fluxurile de lucru de testare, execuția paralelă, alocarea resurselor și provizionarea mediului. Mai jos este prezentată o comparație a componentelor arhitecturale cheie pentru diferite tipuri de medii de testare:
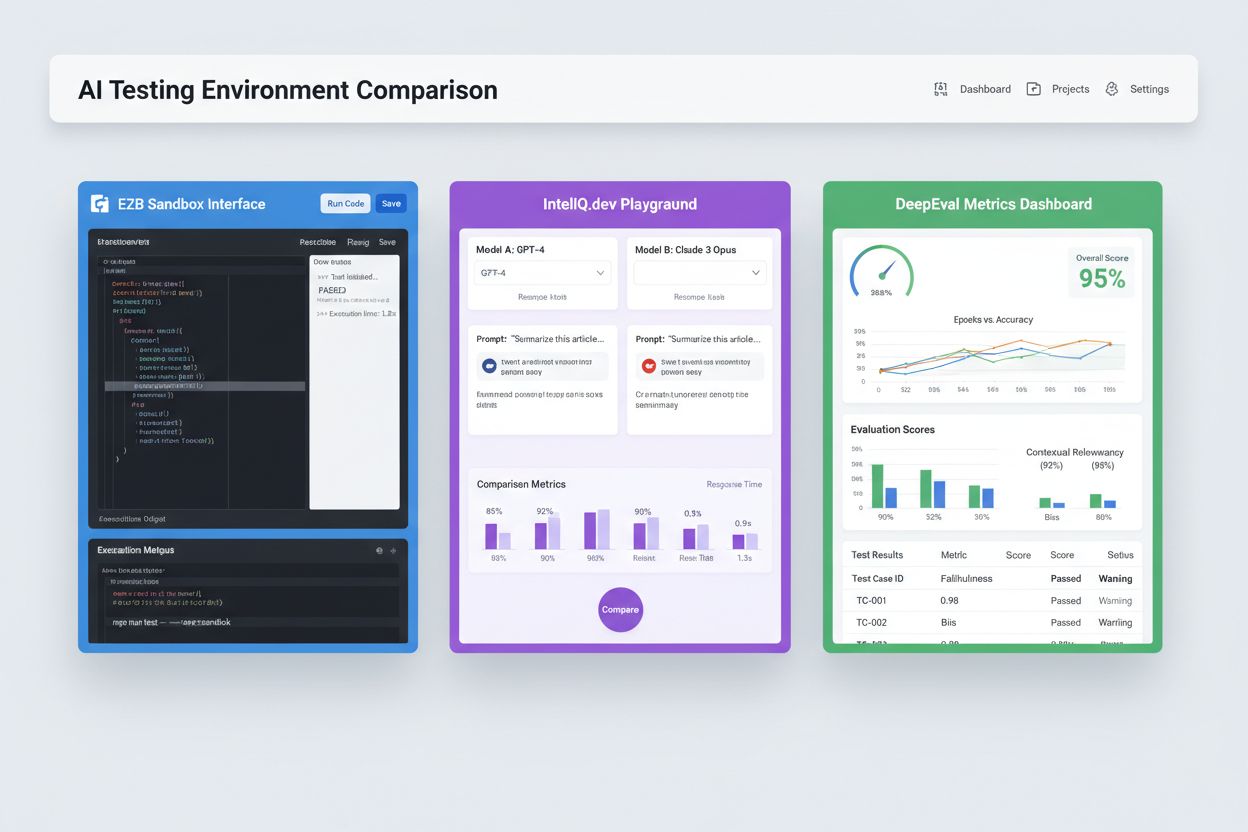
Mediile moderne de testare AI trebuie să suporte ecosisteme eterogene de modele, permițând echipelor să evalueze aplicații pe diferiți furnizori LLM, framework-uri și ținte de implementare simultan. Testarea multi-platformă permite organizațiilor să compare rezultatele modelelor de la GPT-4 al OpenAI, Claude al Anthropic, Mistral și alternative open-source precum Llama în același sistem de test, facilitând decizii informate de selecție a modelului. Platforme precum E2B oferă sandbox-uri izolate ce execută cod generat de orice LLM, suportând Python, JavaScript, Ruby și C++ cu acces complet la sistemul de fișiere, terminal și instalare de pachete. IntelIQ.dev permite comparații side-by-side ale mai multor modele AI cu interfețe unificate, astfel încât echipele pot testa prompturi cu gardă de siguranță și șabloane conforme cu politicile pe diferiți furnizori. Mediile de testare trebuie să gestioneze:
Abstractizare a furnizorilor de modele: API-uri unificate ce funcționează cu OpenAI, Anthropic, Mistral, Groq și modele open-source
Compatibilitate cu framework-uri: Suport pentru LangChain, LlamaIndex, LangGraph și framework-uri de orchestrare custom
Standardizare a output-ului: Metrici de evaluare consistente, indiferent de arhitectura modelului de bază
Monitorizare a costurilor: Urmărirea utilizării API-ului și costurilor de inferență pe diferiți furnizori în timpul testării
Mecanisme de fallback: Comutare automată a modelului când furnizorii principali ating limite de rată sau au erori
Cazuri de Utilizare & Aplicații
Mediile de Testare AI răspund unor nevoi organizaționale diverse din dezvoltare, asigurarea calității și conformitate. Echipele de dezvoltare folosesc mediile de testare pentru a valida comportamentul modelelor în timpul dezvoltării iterative, testând variații de prompturi, ajustând parametri și depanând rezultate neașteptate înainte de integrare. Echipele de data science utilizează aceste medii pentru a evalua performanța pe seturi de date de holdout, a compara diferite arhitecturi și a măsura metrici precum acuratețea, precizia, recall-ul și scorurile F1. Monitorizarea în producție implică testare continuă a modelelor implementate față de metrici de bază, detectarea degradării performanței și declanșarea pipeline-urilor de reantrenare când pragurile de calitate sunt depășite. Echipele de conformitate și securitate folosesc mediile de testare pentru a valida îndeplinirea cerințelor de reglementare, absența bias-ului și gestionarea corectă a datelor sensibile. Aplicații enterprise includ:
Evaluarea chatbot-urilor și agenților: Testarea AI conversaționale pentru coerență, factualitate și siguranță înainte de expunerea la utilizatori
Validarea generării de cod: Verificarea faptului că codul generat de AI este sintactic corect, sigur și performant
Fluxuri de analiză a datelor: Testarea capabilităților AI de explorare și vizualizare a datelor reale
Învățare prin întărire: Rularea a mii de instanțe sandbox concurente pentru evaluarea funcțiilor de recompensă și îmbunătățirea politicilor
Sisteme agentice: Testarea fluxurilor multi-pas unde agenții AI folosesc instrumente, iau decizii și interacționează cu sisteme externe
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Instrumente Populare pentru Medii de Testare AI
Peisajul testării AI include platforme specializate pentru diferite scenarii și dimensiuni organizaționale. DeepEval este un framework open-source de evaluare LLM care oferă peste 50 de metrici validate științific, inclusiv corectitudinea răspunsului, similaritate semantică, detecție de halucinații și scorare a toxicității, cu integrare nativă Pytest pentru fluxuri CI/CD. LangSmith (dezvoltat de LangChain) oferă capabilități complete de observabilitate, evaluare și implementare cu tracing integrat, versionare de prompturi și management de seturi de date pentru aplicații LLM. E2B furnizează sandbox-uri sigure și izolate, bazate pe microVM-uri Firecracker, cu execuție de cod și timpi de pornire sub 200ms, sesiuni de până la 24 de ore și integrare cu principalii furnizori LLM. IntelIQ.dev pune accent pe testarea cu prioritate pentru confidențialitate, cu criptare end-to-end, controale de acces pe bază de roluri și suport pentru mai multe modele AI inclusiv GPT-4, Claude și alternative open-source. Tabelul de mai jos compară principalele capabilități:
Instrument
Focus Principal
Metrici
Integrare CI/CD
Suport Multi-Model
Model de Preț
DeepEval
Evaluare LLM
50+ metrici
Pytest nativ
Limitat
Open-source + cloud
LangSmith
Observabilitate & evaluare
Metrici custom
API-based
Ecosistem LangChain
Freemium + enterprise
E2B
Execuție cod
Metrici performanță
GitHub Actions
Toate LLM-urile
Pay-per-use + enterprise
IntelIQ.dev
Testare confidențialitate
Metrici custom
Workflow builder
GPT-4, Claude, Mistral
Abonament
Securitate, Conformitate & Cele Mai Bune Practici
Mediile enterprise de Testare AI trebuie să implementeze controale de securitate riguroase pentru a proteja datele sensibile, a menține conformitatea și a preveni accesul neautorizat. Izolarea datelor presupune ca datele de test să nu ajungă niciodată la API-uri externe sau servicii terțe; platforme precum E2B utilizează microVM-uri Firecracker pentru izolare completă a proceselor, fără acces la kernel comun. Standardele de criptare trebuie să includă criptare end-to-end pentru datele în repaus și în tranzit, cu suport pentru cerințele HIPAA, SOC 2 Type 2 și GDPR. Controalele de acces trebuie să impună permisiuni bazate pe roluri, audit logging și fluxuri de aprobare pentru scenarii de testare sensibile. Cele mai bune practici includ: menținerea unor seturi de date de test separate, care să nu conțină date de producție, implementarea de data masking pentru date cu caracter personal (PII), utilizarea de generare de date sintetice pentru teste realiste fără riscuri de confidențialitate, efectuarea de audituri de securitate regulate asupra infrastructurii de testare și documentarea tuturor rezultatelor de test pentru conformitate. Organizațiile ar trebui, de asemenea, să implementeze mecanisme de detecție a bias-ului pentru identificarea comportamentului discriminatoriu al modelelor, să folosească instrumente de interpretabilitate precum SHAP sau LIME pentru a înțelege deciziile modelelor și să stabilească logging decizional pentru a urmări cum ajung modelele la anumite rezultate, pentru responsabilitate în fața reglementărilor.
Integrare cu CI/CD & DevOps
Mediile de Testare AI trebuie să se integreze perfect în pipeline-urile existente de integrare continuă și implementare continuă pentru a permite verificări automate de calitate și cicluri rapide de iterație. Integrarea nativă CI/CD permite ca testele să fie executate automat la fiecare commit de cod, pull request sau la intervale programate, folosind platforme precum GitHub Actions, GitLab CI sau Jenkins. Integrarea Pytest a DeepEval permite dezvoltatorilor să scrie cazuri de test ca teste standard Python care se execută în fluxurile CI existente, cu rezultate raportate alături de testele unitare tradiționale. Evaluarea automată poate măsura metrici de performanță ale modelului, compara output-urile cu versiunile de bază și poate bloca implementările dacă nu se ating pragurile de calitate. Managementul artefactelor implică stocarea seturilor de date de test, checkpoint-urilor de model și rezultatelor evaluărilor în sisteme de versionare sau depozite de artefacte pentru reproductibilitate și trasabilitate. Modelele de integrare includ:
Porți pre-implementare: Rularea unor suite de teste complete înainte de promovarea modelelor în staging sau producție
Implementări canar: Testarea noilor versiuni de model cu subseturi mici de utilizatori și monitorizarea metricilor de performanță
Rollback automatizat: Revenirea la versiunile anterioare ale modelului dacă metricile de evaluare scad sub pragurile acceptabile
Urmărirea performanței: Menținerea de dashboard-uri care vizualizează metricile de calitate ale modelelor de-a lungul timpului și pe diferite versiuni
Tendințe Viitoare & Considerații
Peisajul Mediilor de Testare AI evoluează rapid pentru a răspunde provocărilor emergente legate de complexitatea, scara și eterogenitatea modelelor. Testarea agentică devine tot mai importantă pe măsură ce sistemele AI trec de la inferență single-model la fluxuri multi-pas unde agenții folosesc instrumente, iau decizii și interacționează cu sisteme externe—ceea ce necesită framework-uri noi de evaluare a finalizării task-urilor, siguranței și fiabilității. Evaluarea distribuită permite testarea la scară prin rularea a mii de instanțe de test concurente în cloud, esențială pentru învățarea prin întărire și antrenarea modelelor la scară mare. Monitorizarea în timp real trece de la evaluare batch la testare continuă, de producție, care detectează degradarea performanței, drift-ul datelor și bias-ul emergent în sistemele live. Platformele de observabilitate precum AmICited devin instrumente esențiale pentru monitorizare completă și vizibilitate AI, oferind dashboard-uri centralizate ce urmăresc performanța modelelor, tiparele de utilizare și metricile de calitate la nivelul întregului portofoliu AI. Mediile de testare viitoare vor incorpora tot mai mult remedierea automată, unde sistemele nu doar detectează problemele, ci declanșează automat pipeline-uri de reantrenare sau actualizări de model, și evaluare cross-modală, suportând testarea simultană a modelelor de text, imagine, audio și video în cadrul acelorași framework-uri unificate.
Întrebări frecvente
Care este diferența dintre un Mediu de Testare AI și implementarea în producție?
Un Mediu de Testare AI este un sandbox izolat unde poți testa în siguranță modele, prompturi și configurații fără a afecta sistemele sau utilizatorii live. Implementarea în producție reprezintă mediul live unde modelele deservesc utilizatori reali. Mediile de testare îți permit să identifici probleme, să optimizezi performanța și să validezi modificările înainte de a ajunge în producție, reducând riscul și asigurând calitatea.
Pot testa mai multe modele AI simultan într-un mediu de testare?
Da, mediile moderne de testare AI suportă testarea multi-model. Platforme precum E2B, IntelIQ.dev și DeepEval îți permit să testezi același prompt sau input pe diferiți furnizori LLM (OpenAI, Anthropic, Mistral etc.) simultan, permițând comparații directe ale rezultatelor și metricilor de performanță.
Ce măsuri de securitate există în Mediile de Testare AI?
Mediile enterprise de Testare AI implementează mai multe straturi de securitate, inclusiv izolare a datelor (containerizare sau microVM-uri), criptare end-to-end, controale de acces bazate pe roluri, jurnalizare de audit și certificări de conformitate (SOC 2, GDPR, HIPAA). Datele nu părăsesc niciodată mediul izolat decât dacă sunt exportate explicit, protejând informațiile sensibile.
Cum ajută Mediile de Testare AI la cerințele de conformitate?
Mediile de testare permit conformitatea prin furnizarea unor trasee de audit pentru toate evaluările de modele, suport pentru mascarea datelor și generarea de date sintetice, impunerea controalelor de acces și menținerea izolării complete a datelor de test față de sistemele de producție. Această documentație și control ajută organizațiile să respecte cerințele de reglementare precum GDPR, HIPAA și SOC 2.
Ce metrici ar trebui să urmăresc când testez modele AI?
Metricile cheie depind de cazul tău de utilizare: pentru LLM-uri, urmărește acuratețea, similaritatea semantică, ratele de halucinație și latența; pentru sisteme RAG, măsoară precizia/recall-ul contextului și fidelitatea; pentru modele de clasificare, monitorizează precizia, recall-ul și scorurile F1; pentru toate modelele, urmărește degradarea performanței în timp și indicatorii de bias.
Cât costă utilizarea unui Mediu de Testare AI?
Costurile variază în funcție de platformă: DeepEval este open-source și gratuit; LangSmith oferă un plan gratuit cu abonamente plătite de la 39$/lună; E2B folosește tarifarea pay-per-use bazată pe durata sandbox-ului; IntelIQ.dev oferă prețuri pe bază de abonament. Multe platforme oferă și prețuri enterprise pentru implementări la scară largă.
Pot integra Mediile de Testare AI cu pipeline-ul meu CI/CD existent?
Da, majoritatea mediilor moderne de testare suportă integrarea CI/CD. DeepEval se integrează nativ cu Pytest, E2B funcționează cu GitHub Actions și GitLab CI, iar LangSmith oferă integrare bazată pe API. Acest lucru permite testare automată la fiecare commit de cod și aplicarea unor gate-uri la implementare.
Care este diferența dintre testarea la nivel de componentă și testarea end-to-end?
Testarea end-to-end tratează întreaga ta aplicație AI ca pe o cutie neagră, testând rezultatul final față de rezultatul așteptat. Testarea la nivel de componentă evaluează separat părțile individuale (apeluri LLM, retrieveri, utilizarea instrumentelor) folosind instrumentare și tracing. Testarea la nivel de componentă oferă perspective mai detaliate despre unde apar problemele, în timp ce testarea end-to-end validează comportamentul general al sistemului.
Monitorizează performanța AI-ului tău pe toate platformele
AmICited urmărește modul în care sistemele AI fac referire la brandul și conținutul tău pe ChatGPT, Claude, Perplexity și Google AI. Obține vizibilitate în timp real asupra prezenței AI-ului tău prin monitorizare și analize cuprinzătoare.
Testarea A/B pentru Vizibilitatea AI: Metodologie și Cele Mai Bune Practici
Stăpânește testarea A/B pentru vizibilitatea AI cu ghidul nostru complet. Învață despre experimente GEO, metodologie, cele mai bune practici și studii de caz re...
Află ce este un Centru de Excelență pentru Vizibilitatea AI, responsabilitățile cheie, capacitățile de monitorizare și cum ajută organizațiile să mențină transp...
Testarea prompturilor pentru Vizibilitatea AI: Testarea Prezenței Tale
Află cum să testezi prezența brandului tău în motoarele AI prin testarea prompturilor. Descoperă metode manuale și automate pentru a monitoriza vizibilitatea AI...
8 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.