Cum te poți retrage din antrenarea AI pe principalele platforme
Ghid complet pentru retragerea din colectarea datelor de antrenare AI pe ChatGPT, Perplexity, LinkedIn și alte platforme. Află instrucțiuni pas cu pas pentru a-...
8 min citire
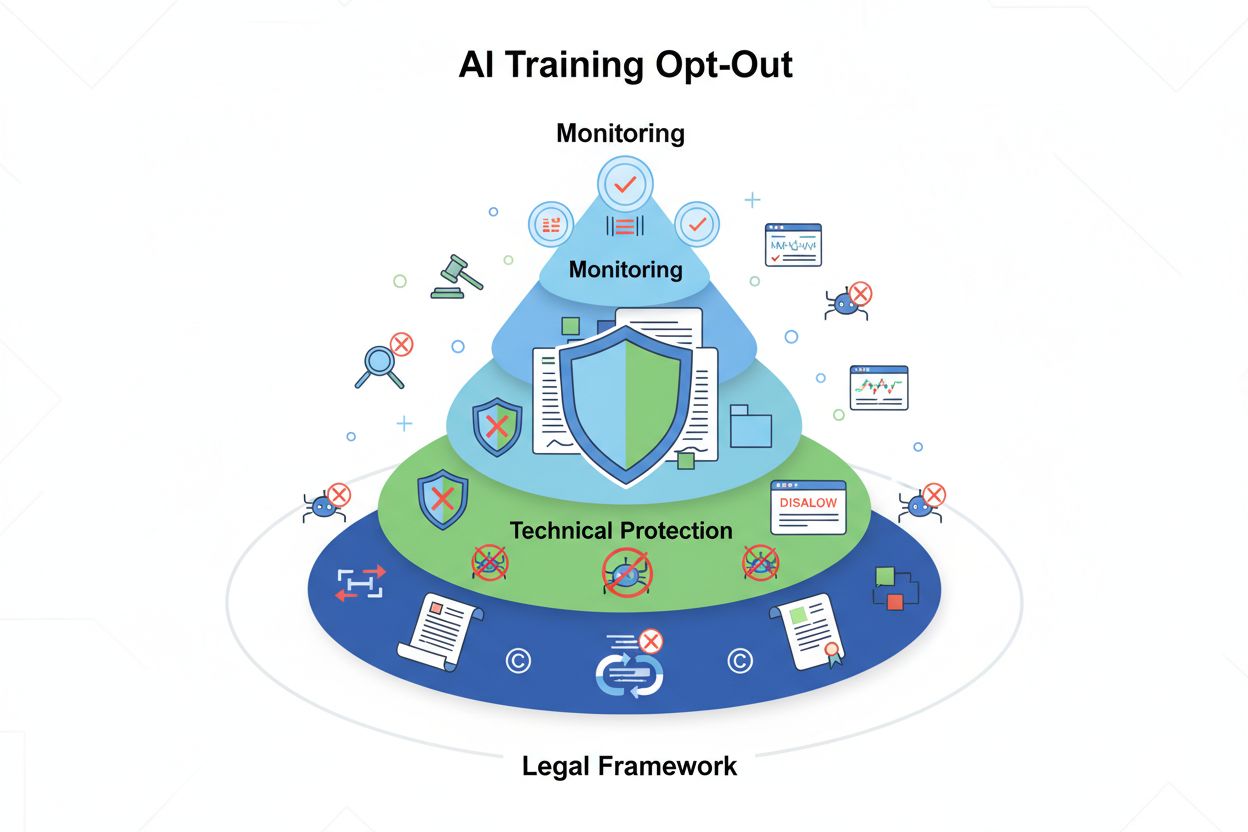
Mecanisme tehnice și juridice care permit creatorilor de conținut și titularilor de drepturi de autor să împiedice utilizarea lucrărilor lor în seturile de date pentru instruirea modelelor lingvistice mari. Acestea includ directive robots.txt, declarații legale de renunțare și protecții contractuale conform unor reglementări precum Legea AI a UE.
Mecanisme tehnice și juridice care permit creatorilor de conținut și titularilor de drepturi de autor să împiedice utilizarea lucrărilor lor în seturile de date pentru instruirea modelelor lingvistice mari. Acestea includ directive robots.txt, declarații legale de renunțare și protecții contractuale conform unor reglementări precum Legea AI a UE.
Renunțarea la instruirea AI se referă la mecanismele tehnice și juridice care permit creatorilor de conținut, titularilor de drepturi de autor și proprietarilor de site-uri web să împiedice utilizarea lucrărilor lor în seturile de date pentru instruirea modelelor lingvistice mari (LLM). Pe măsură ce companiile AI extrag cantități uriașe de date de pe internet pentru a instrui modele tot mai sofisticate, abilitatea de a controla dacă propriul conținut participă la acest proces a devenit esențială pentru protejarea proprietății intelectuale și menținerea controlului creativ. Aceste mecanisme de renunțare operează pe două niveluri: directive tehnice care instruiesc crawler-ele AI să evite conținutul tău și cadre juridice care stabilesc drepturi contractuale de excludere a lucrărilor tale din seturile de date de instruire. Înțelegerea ambelor dimensiuni este crucială pentru oricine este preocupat de modul în care conținutul său este folosit în era AI.

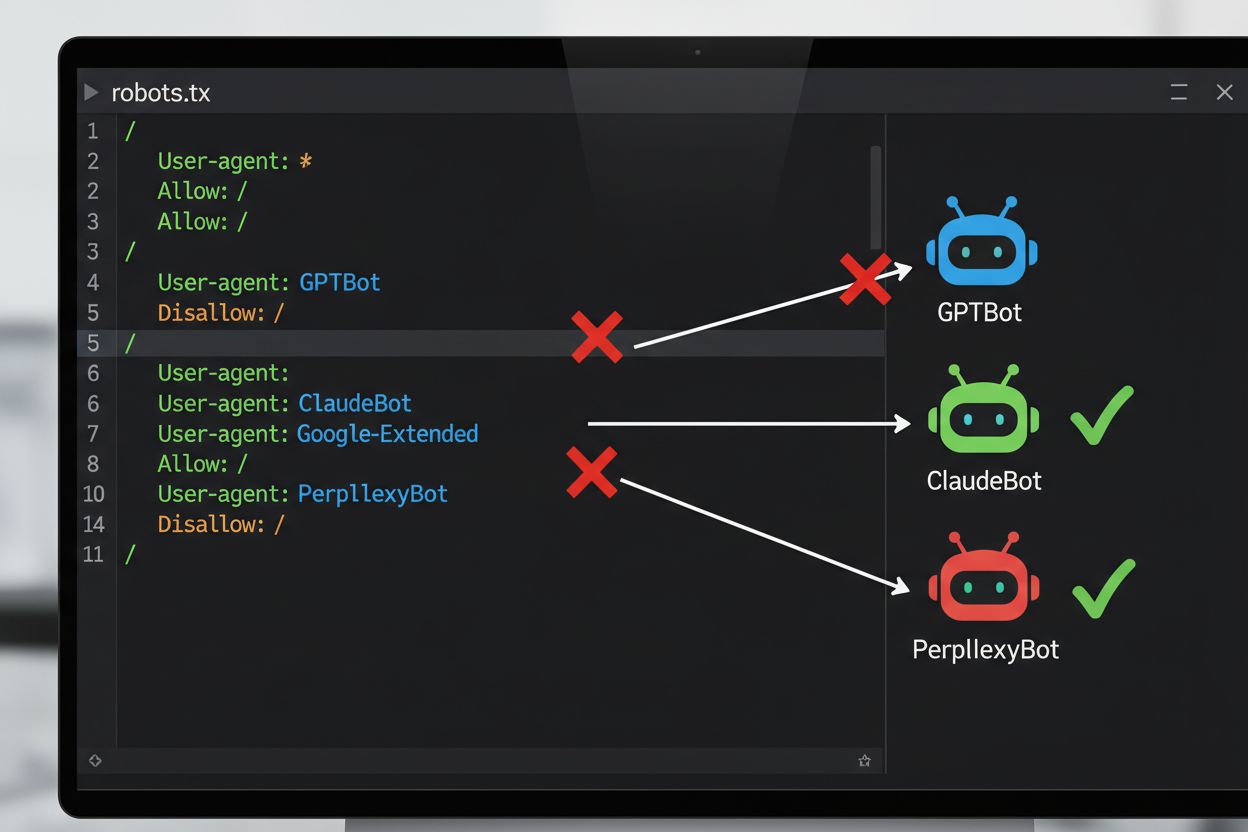
Cea mai des întâlnită metodă tehnică pentru renunțarea la instruirea AI este fișierul robots.txt, un fișier text simplu plasat în directorul rădăcină al unui site web, care comunică permisiunile către crawler-ele automate. Când un crawler AI îți vizitează site-ul, verifică mai întâi robots.txt pentru a vedea dacă are voie să acceseze conținutul. Prin adăugarea unor directive Disallow pentru anumiți agenți utilizatori de crawler, poți instrui bot-urile AI să evite complet site-ul tău. Fiecare companie AI operează mai multe crawler-e cu identificatori de agent utilizator distincți—practic „numele” cu care bot-urile se prezintă la accesarea resurselor. De exemplu, GPTBot al OpenAI se identifică cu stringul de agent utilizator “GPTBot”, în timp ce Claude al Anthropic folosește “ClaudeBot”. Sintaxa este simplă: specifici numele agentului utilizator și apoi declari ce căi sunt interzise, precum “Disallow: /” pentru a bloca întregul site.
| Companie AI | Nume Crawler | Token Agent Utilizator | Scop |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Colectare date pentru instruirea modelelor |
| OpenAI | OAI-SearchBot | OAI-SearchBot | Indexare căutare ChatGPT |
| Anthropic | ClaudeBot | ClaudeBot | Preluare citări pentru chat |
| Google-Extended | Google-Extended | Date de instruire Gemini AI | |
| Perplexity | PerplexityBot | PerplexityBot | Indexare căutare AI |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | Instruire modele AI |
| Common Crawl | CCBot | CCBot | Set de date deschis pentru instruirea LLM |
Peisajul juridic al renunțării la instruirea AI a evoluat semnificativ odată cu introducerea Legii AI a UE, care a intrat în vigoare în 2024 și integrează prevederi din Directiva privind textul și data mining (TDM). Conform acestor reglementări, dezvoltatorii AI pot folosi lucrări protejate de drepturi de autor pentru învățare automată doar dacă au acces legal la conținut și titularul dreptului de autor nu a rezervat în mod expres dreptul de a exclude lucrarea din procesul de text și data mining. Acest lucru creează un mecanism juridic formal de renunțare: titularii de drepturi pot depune rezervații de renunțare pentru lucrările lor, împiedicând utilizarea lor pentru instruirea AI fără permisiune explicită. Legea AI a UE marchează o schimbare majoră față de abordarea anterioară „move fast and break things”, stabilind că firmele care instruiesc modele AI trebuie să verifice dacă titularii de drepturi și-au rezervat conținutul și să implementeze măsuri tehnice și organizaționale pentru a preveni utilizarea neintenționată a lucrărilor renunțate. Acest cadru legal se aplică în toată Uniunea Europeană și influențează modul în care companiile AI globale colectează date și instruiesc modele.
Implementarea unui mecanism de renunțare implică atât configurare tehnică, cât și documentație juridică. Din punct de vedere tehnic, proprietarii de site-uri adaugă directive Disallow în fișierul robots.txt pentru anumiți agenți utilizatori de crawler AI, pe care crawler-ele conforme le vor respecta când vizitează site-ul. Din punct de vedere juridic, titularii de drepturi pot depune declarații de renunțare la societăți de gestiune colectivă și organizații de drepturi—de exemplu, societatea colectivă olandeză Pictoright și societatea franceză de muzică SACEM au proceduri formale de renunțare care permit creatorilor să-și rezerve drepturile împotriva utilizării pentru instruirea AI. Multe site-uri și creatori de conținut includ acum declarații explicite de renunțare în termenii și condițiile site-ului sau în metadate, declarând că lucrările lor nu trebuie folosite pentru instruirea modelelor AI. Totuși, eficiența acestor mecanisme depinde de conformitatea crawler-elor: deși companii precum OpenAI, Google și Anthropic au declarat public că respectă directivele robots.txt și rezervațiile de renunțare, lipsa unui mecanism centralizat de aplicare înseamnă că verificarea respectării renunțării necesită monitorizare și verificare continuă.
În ciuda existenței mecanismelor de renunțare, există provocări semnificative care limitează eficiența acestora:
Pentru organizațiile care doresc o protecție mai puternică decât cea oferită de robots.txt, pot fi implementate câteva metode tehnice suplimentare. Filtrarea agenților utilizatori la nivel de server sau firewall poate bloca cererile de la anumiți identificatori de crawler înainte ca acestea să ajungă la aplicație, deși această metodă rămâne vulnerabilă la falsificare. Blocarea adreselor IP poate viza intervale de IP cunoscute, publicate de companiile AI majore, deși scraper-ele determinate pot ocoli acest lucru prin rețele de proxy. Limitarea și controlul ratei de acces pot încetini scraper-ele stabilind o limită de cereri pe secundă, făcând scraping-ul neeconomic, deși bot-urile sofisticate pot distribui cererile pe mai multe IP-uri pentru a ocoli aceste limite. Cererea de autentificare și paywall-urile oferă protecție puternică, restricționând accesul doar la utilizatorii autentificați sau plătitori, prevenind astfel scraping-ul automatizat. Amprentarea dispozitivelor și analiza comportamentală pot detecta bot-urile analizând tipare precum API-urile browserului, handshake-uri TLS și comportamente diferite de cele ale utilizatorilor umani. Unele organizații au implementat chiar honeypot-uri și tarpit-uri—linkuri ascunse sau labirinturi infinite de linkuri pe care doar bot-urile le-ar accesa—pentru a consuma resursele crawler-elor și, eventual, a polua seturile de date de instruire cu date inutile.
Tensiunea dintre companiile AI și creatorii de conținut a generat mai multe confruntări de profil înalt care ilustrează provocările practice ale aplicării renunțării. Reddit a luat măsuri agresive în 2023, crescând dramatic prețurile de acces la API special pentru a taxa companiile AI pentru date, eliminând practic scraper-ele neautorizate și forțând companii precum OpenAI și Anthropic să negocieze acorduri de licențiere. Twitter/X a implementat măsuri și mai extreme, blocând temporar accesul neautentificat la tweet-uri și limitând numărul de tweet-uri care pot fi citite de utilizatorii autentificați, vizând explicit scraper-ele de date. Stack Overflow a blocat inițial GPTBot-ul OpenAI în fișierul robots.txt, invocând probleme de licențiere cu codul generat de utilizatori, dar ulterior a eliminat blocarea—posibil în urma negocierilor cu OpenAI. Organizațiile media de știri au reacționat în masă: peste 50% dintre site-urile mari de știri au blocat crawler-ele AI până în 2023, publicații precum The New York Times, CNN, Reuters și The Guardian adăugând GPTBot pe listele de blocare. Unele organizații media au ales acțiunea legală, The New York Times intentând proces pentru încălcarea drepturilor de autor împotriva OpenAI, în timp ce altele, precum Associated Press, au negociat acorduri de licențiere pentru a-și monetiza conținutul. Aceste exemple arată că, deși mecanismele de renunțare există, eficiența lor depinde atât de implementarea tehnică, cât și de disponibilitatea de a urma căi legale când apar încălcări.
Implementarea mecanismelor de renunțare este doar jumătate din proces; verificarea faptului că acestea chiar funcționează necesită monitorizare și testare continuă. Există mai multe instrumente care ajută la validarea configurației tale: Google Search Console include un tester robots.txt pentru validarea specifică Googlebot, în timp ce Merkle’s Robots.txt Tester și TechnicalSEO.com’s tool testează comportamentul individual al crawler-elor pentru anumiți agenți utilizatori. Pentru monitorizarea completă a respectării directivei de renunțare de către companiile AI, platforme precum AmICited.com oferă monitorizare specializată care urmărește modul în care sistemele AI fac referire la brandul și conținutul tău în GPT, Perplexity, Google AI Overviews și alte platforme AI. Acest tip de monitorizare este util mai ales deoarece arată nu doar dacă crawler-ele îți accesează site-ul, ci și dacă conținutul tău apare efectiv în răspunsuri generate de AI—indicând dacă renunțarea ta funcționează în practică. Analiza regulată a jurnalelor serverului poate arăta ce crawler-e încearcă să acceseze site-ul și dacă respectă directivele din robots.txt, deși acest lucru necesită expertiză tehnică pentru interpretare corectă.
Pentru a-ți proteja eficient conținutul împotriva utilizării neautorizate în instruirea AI, adoptă o abordare pe mai multe niveluri, combinând măsuri tehnice și juridice. În primul rând, implementează directive robots.txt pentru toți crawler-ii majori de instruire AI (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot și alții), înțelegând că aceasta oferă o protecție de bază împotriva companiilor conforme. În al doilea rând, adaugă declarații explicite de renunțare în termenii și condițiile site-ului tău și în metadate, declarând clar că lucrările tale nu trebuie folosite pentru instruirea modelelor AI—acest lucru consolidează poziția ta juridică în cazul unor încălcări. În al treilea rând, monitorizează-ți configurația regulat folosind instrumente de testare și jurnale de server pentru a verifica dacă crawler-ele respectă directivele și actualizează-ți robots.txt trimestrial, deoarece apar constant noi crawler-e AI. În al patrulea rând, ia în considerare măsuri tehnice suplimentare precum filtrarea agenților utilizatori sau limitarea ratei de acces dacă ai resurse tehnice, recunoscând că acestea oferă protecție suplimentară împotriva scraper-elor sofisticate. În cele din urmă, documentează-ți eforturile de renunțare temeinic, deoarece această documentație devine crucială dacă trebuie să urmezi o acțiune legală împotriva companiilor care îți ignoră directivele. Amintește-ți că renunțarea nu este o configurație unică, ci un proces continuu care necesită vigilență și adaptare pe măsură ce peisajul AI evoluează.
robots.txt este un standard tehnic, voluntar, care instruiește crawler-ele să evite conținutul tău, în timp ce renunțarea legală implică depunerea de rezervații formale la organizații de drepturi de autor sau includerea de clauze contractuale în termenii și condițiile tale. robots.txt este mai ușor de implementat, dar nu oferă aplicabilitate, în timp ce renunțarea legală oferă protecție juridică mai puternică, dar necesită proceduri mai formale.
Companiile AI majore precum OpenAI, Google, Anthropic și Perplexity au declarat public că respectă directivele robots.txt. Totuși, robots.txt este un standard voluntar, fără mecanism de aplicare, astfel încât crawler-ele neconforme și scraper-ele rău intenționate pot ignora complet directivele tale.
Nu. Blocarea crawler-elor de instruire AI precum GPTBot și ClaudeBot nu va afecta clasamentul tău în Google sau Bing, deoarece motoarele de căutare tradiționale folosesc alți crawler-i (Googlebot, Bingbot) care operează independent. Blochează-i doar dacă dorești să dispari complet din rezultatele căutării.
Legea AI a UE impune ca dezvoltatorii de AI să aibă acces legal la conținut și să respecte rezervațiile de renunțare ale titularilor de drepturi de autor. Titularii de drepturi pot depune declarații de renunțare pentru lucrările lor, împiedicând astfel utilizarea acestora pentru instruirea AI fără permisiune explicită. Acest lucru creează un mecanism juridic formal de protecție a conținutului împotriva utilizării neautorizate pentru instruire.
Depinde de mecanismul specific. Blocarea tuturor crawler-elor AI va împiedica apariția conținutului tău în rezultatele căutării AI, dar te va elimina complet și din platformele de căutare alimentate de AI. Unii editori preferă blocarea selectivă—permitând crawler-ele de căutare, dar blocându-le pe cele de instruire—pentru a menține vizibilitatea în căutarea AI, protejând totodată conținutul de instruirea modelelor.
Dacă o companie AI ignoră directivele tale de renunțare, ai căi legale prin acțiuni pentru încălcarea drepturilor de autor sau a contractului, în funcție de jurisdicție și circumstanțe. Totuși, acțiunea legală este costisitoare și lentă, cu rezultate incerte. De aceea, monitorizarea și documentarea eforturilor tale de renunțare sunt cruciale.
Revizuiește și actualizează configurația robots.txt cel puțin trimestrial. Apar constant noi crawler-e AI, iar companiile introduc frecvent noi agenți utilizatori. De exemplu, Anthropic a combinat bot-urile 'anthropic-ai' și 'Claude-Web' în 'ClaudeBot', oferind noului bot acces temporar nelimitat pe site-urile care nu și-au actualizat regulile.
Renunțarea este eficientă împotriva companiilor AI de renume, care respectă robots.txt și cadrele legale. Totuși, este mai puțin eficientă împotriva crawler-elor rău intenționate și a scraper-elor neconforme care operează în zone gri legale. robots.txt oprește aproximativ 40-60% dintre bot-urile AI, motiv pentru care este recomandat un demers pe mai multe niveluri, combinând măsuri tehnice și legale.
Urmărește dacă conținutul tău apare în răspunsurile generate de AI pe ChatGPT, Perplexity, Google AI Overviews și alte platforme AI cu AmICited.
Ghid complet pentru retragerea din colectarea datelor de antrenare AI pe ChatGPT, Perplexity, LinkedIn și alte platforme. Află instrucțiuni pas cu pas pentru a-...
Înțelegeți provocările privind drepturile de autor cu care se confruntă motoarele de căutare AI, limitele utilizării echitabile, procesele recente și implicații...
Află despre meta tag-ul noai, cum funcționează pentru a preveni colectarea datelor pentru antrenarea AI, care sunt limitările sale și cum să îl implementezi pe ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.