
Recunoașterea Entităților
Recunoașterea Entităților este o capacitate NLP AI care identifică și categorizează entități denumite în text. Află cum funcționează, aplicațiile sale în monito...
11 min citire

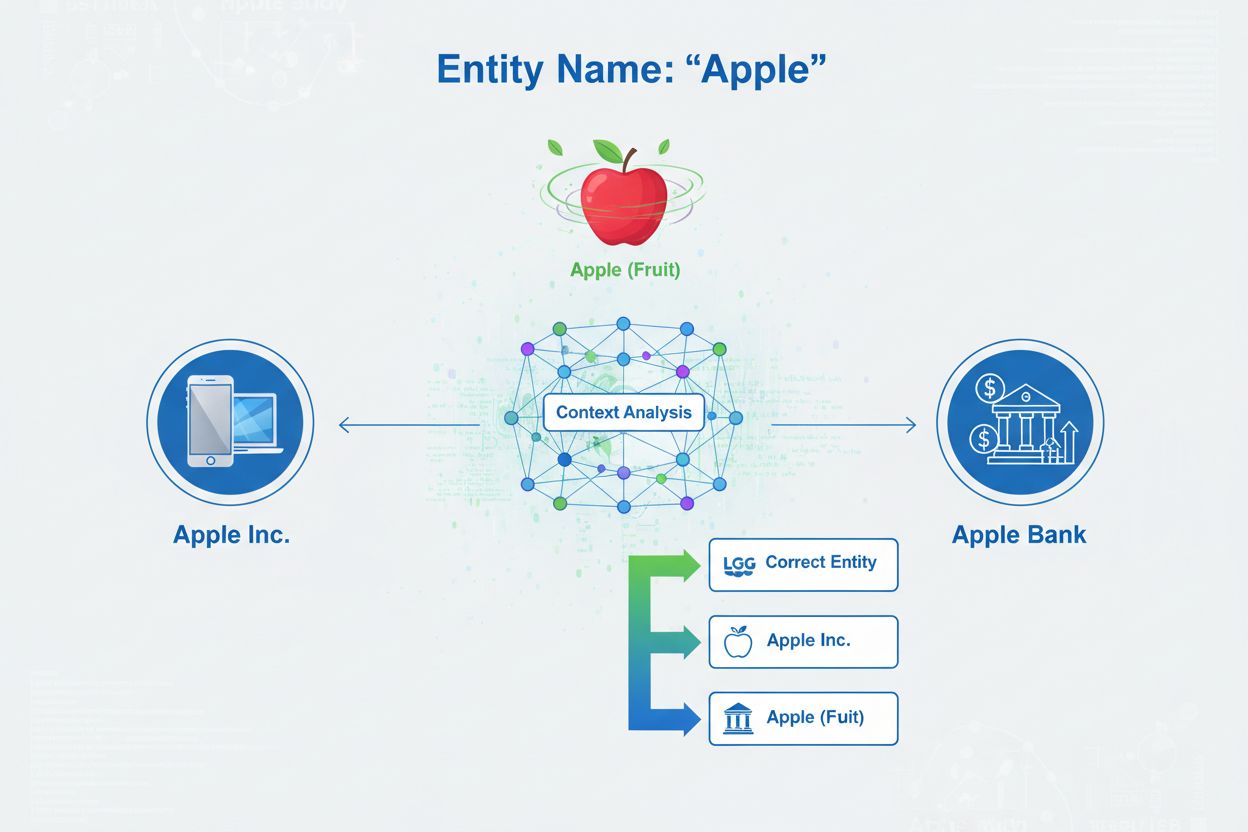
Dezambiguizarea entităților este procesul de determinare a entității specifice la care se referă o anumită mențiune atunci când mai multe entități împart același nume. Acest proces ajută sistemele AI să înțeleagă și să citeze corect conținutul prin rezolvarea ambiguității referințelor la entități denumite, asigurând că mențiunile despre „Apple” identifică corect dacă se face referire la Apple Inc., fructul sau o altă entitate cu același nume.
Dezambiguizarea entităților este procesul de determinare a entității specifice la care se referă o anumită mențiune atunci când mai multe entități împart același nume. Acest proces ajută sistemele AI să înțeleagă și să citeze corect conținutul prin rezolvarea ambiguității referințelor la entități denumite, asigurând că mențiunile despre „Apple” identifică corect dacă se face referire la Apple Inc., fructul sau o altă entitate cu același nume.
Dezambiguizarea entităților reprezintă procesul de determinare a entității specifice la care se face referire într-o mențiune, atunci când mai multe entități împart același nume sau referințe similare. În contextul inteligenței artificiale și al procesării limbajului natural (NLP), dezambiguizarea entităților asigură că, atunci când un sistem AI întâlnește o entitate denumită într-un text, aceasta este identificată corect ca obiect, persoană, organizație sau locație din lumea reală. Acest proces este fundamental diferit de recunoașterea entităților denumite (NER), care identifică simplu existența unei entități și o clasifică într-o categorie precum „persoană”, „organizație” sau „locație”. Dacă NER răspunde la întrebarea „Există o entitate aici?”, dezambiguizarea entităților răspunde „Care este entitatea specifică?”. De exemplu, când procesează fraza „Apple a fost creația lui Steve Jobs”, NER identifică „Apple” ca organizație, dar dezambiguizarea stabilește dacă este vorba despre Apple Inc., compania de tehnologie, sau despre o altă entitate cu același nume. Această distincție este crucială pentru sistemele AI care trebuie să înțeleagă și să citeze corect conținutul, motiv pentru care AmICited.com monitorizează modul în care sisteme AI precum ChatGPT, Perplexity și Google AI Overviews gestionează dezambiguizarea entităților atunci când generează răspunsuri despre branduri și organizații.
Problema fundamentală rezolvată de dezambiguizarea entităților este ambiguitatea — realitatea că multe nume de entități pot face referire la mai multe obiecte diferite din lumea reală. Această ambiguitate creează provocări semnificative pentru sistemele AI care încearcă să înțeleagă și să genereze conținut corect. Conform Stanford AI Index 2024, peste 18% din rezultatele LLM care implică entități de brand conțin halucinații sau atribuire greșită a entităților, ceea ce înseamnă că sistemele AI confundă frecvent o entitate cu alta sau generează informații false despre entități. Această rată de eroare are implicații serioase pentru reprezentarea brandurilor și acuratețea conținutului. Când un sistem AI identifică greșit o entitate, poate oferi informații incorecte, poate atribui afirmații organizației greșite sau poate să nu citeze sursa corectă a informațiilor.
| Numele entității | Posibile sensuri | Rată de confuzie AI |
|---|---|---|
| Apple | Companie Tech / Fruct / Bancă | Ridicată |
| Delta | Companie aeriană / Baterii sanitare / Literă grecească | Ridicată |
| Jaguar | Producător auto / Specie animală | Medie |
| Amazon | Companie e-commerce / Pădure tropicală / Râu | Ridicată |
| Orange | Culoare / Fruct / Companie telecom | Medie |
Consecințele unei dezambiguizări defectuoase depășesc simplele erori factuale. Pentru creatori de conținut și branduri, identificarea greșită în răspunsurile AI poate duce la pierderea vizibilității, atribuire incorectă și afectarea reputației brandului. Când un utilizator întreabă un sistem AI despre „Delta”, ar putea dori informații despre Delta Airlines, dar dacă sistemul o confundă cu Delta Faucet Company, utilizatorul primește informații irelevante. Acesta este motivul pentru care AmICited.com monitorizează modul în care sistemele AI dezambiguizează entitățile — pentru a ajuta brandurile să înțeleagă dacă sunt identificate și citate corect în conținutul generat de AI pe mai multe platforme.
Dezambiguizarea entităților operează printr-un proces sistematic care combină mai multe tehnici NLP pentru a rezolva ambiguitatea și a identifica corect entitățile. Înțelegerea acestui proces explică de ce unele sisteme AI oferă o acuratețe mai mare a citărilor decât altele.
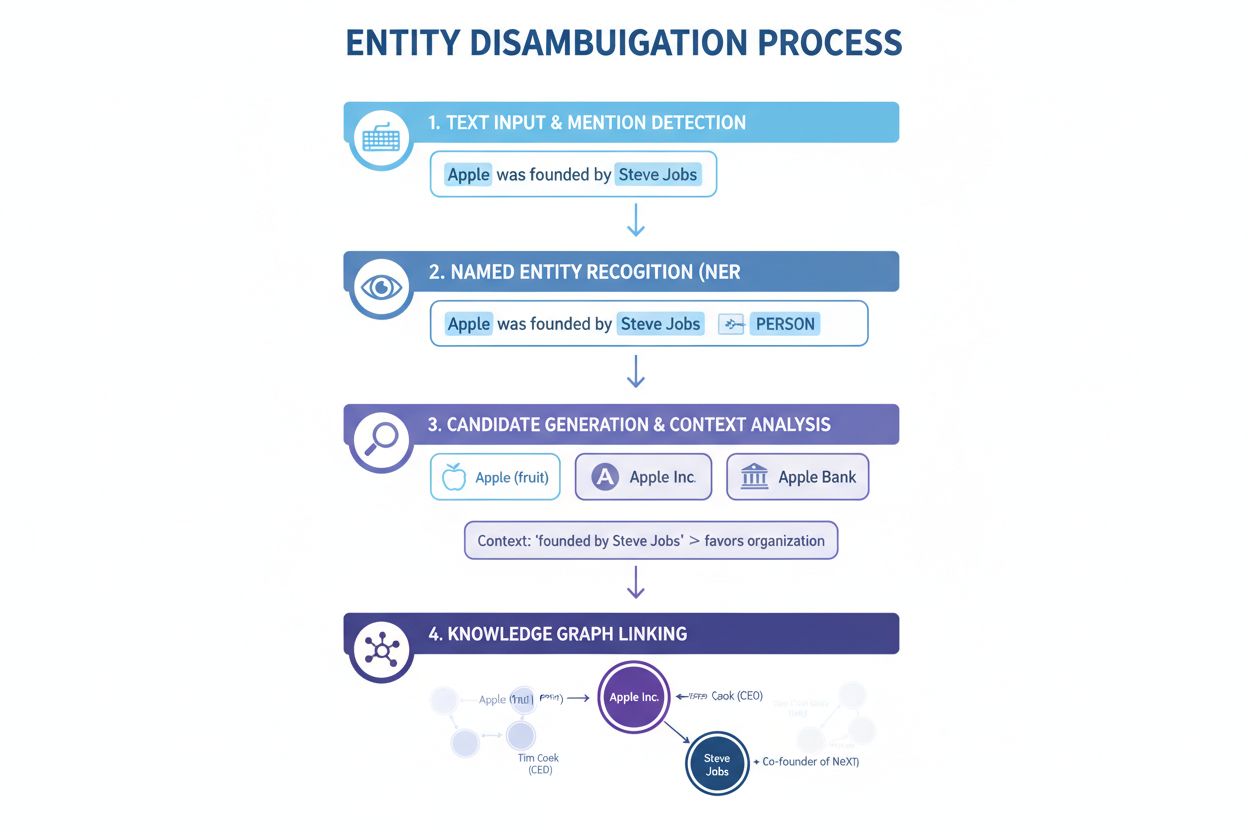
Recunoașterea entităților denumite (NER): Primul pas constă în identificarea și clasificarea entităților denumite într-un text. Sistemele NER parcurg textul și localizează mențiunile entităților, atribuindu-le categorii predefinite precum persoană, organizație, locație, produs sau dată. De exemplu, în fraza „Apple a fost creația lui Steve Jobs”, NER identifică atât „Apple”, cât și „Steve Jobs” ca entități și le clasifică drept organizație, respectiv persoană. Acest pas fundamental este esențial deoarece dezambiguizarea nu poate avea loc fără identificarea în prealabil a entităților prezente în text.
Categorisirea entităților: După identificarea entităților, acestea trebuie categorisite mai precis. Nu este vorba doar de clasificare largă, ci de înțelegerea tipului și contextului specific al fiecărei entități. Sistemul analizează textul din jur pentru a stabili dacă „Apple” apare într-un context tehnologic (sugerând Apple Inc.), alimentar (fructul) sau financiar (Apple Bank). Această analiză contextuală restrânge posibilitățile înaintea dezambiguizării propriu-zise.
Dezambiguizarea: Acesta este pasul central în care sistemul determină la ce entitate specifică se face referire. Sistemul evaluează mai multe entități candidate care corespund numelui identificat și utilizează diverse semnale — context, descrieri de entitate, relații semantice și informații din grafuri de cunoștințe — pentru a selecta cea mai probabilă entitate corectă. Pentru „Apple a fost creația lui Steve Jobs”, sistemul recunoaște asocierea puternică dintre Steve Jobs și Apple Inc., alegând această entitate în mod corect.
Legarea la baza de cunoștințe: Ultimul pas constă în legarea entității dezambiguizate la un identificator unic într-o bază de cunoștințe sau graf de cunoștințe extern, precum Wikidata, Wikipedia sau o bază de date internă. Această legare confirmă identitatea entității și îmbogățește textul cu informații semantice pentru procesări și analize ulterioare. Entității îi este atribuit un URI (Uniform Resource Identifier) unic ce servește ca punct de referință definitiv.
Au evoluat diferite abordări pentru dezambiguizarea entităților, fiecare cu avantaje și limitări specifice. Înțelegerea acestor abordări explică de ce sistemele AI moderne pot varia ca acuratețe a dezambiguizării.
Abordări bazate pe reguli: Aceste sisteme utilizează reguli lingvistice predefinite și tipare euristice pentru a dezambiguiza entitățile. Pot aplica reguli precum „dacă ‘Apple’ apare lângă ‘iPhone’ sau ‘MacBook’, se referă la Apple Inc.” sau „dacă ‘Delta’ apare lângă ‘aeriană’ sau ‘zbor’, se referă la Delta Airlines”. Deși sunt interpretabile și nu necesită mari seturi de date pentru antrenament, sistemele bazate pe reguli nu se adaptează la contexte noi fără actualizări manuale.
Abordări bazate pe machine learning: Modelele de învățare automată supravegheată învață din date de antrenament adnotate pentru a prezice entitatea corectă pe baza caracteristicilor contextuale. Aceste sisteme extrag trăsături din textul din jur și utilizează algoritmi ca Support Vector Machines sau Random Forests pentru a clasifica entitatea probabilă. Sunt mai flexibile decât sistemele bazate pe reguli, dar necesită seturi mari de date etichetate și pot avea dificultăți cu entități noi.
Modele de deep learning și arhitecturi transformer: Dezambiguizarea modernă se bazează tot mai mult pe arhitecturi de tip transformer precum BERT, RoBERTa și modele specializate ca GENRE și BLINK. Aceste modele folosesc rețele neuronale pentru a înțelege contextul la un nivel profund, captând relații semantice și nuanțe lingvistice. Modelele transformer oferă performanțe superioare pe benchmark-uri standard și pot gestiona scenarii complexe de dezambiguizare. De exemplu, sistemul CEEL (Common English Entity Linking) de la Ontotext folosește o arhitectură transformer optimizată pentru eficiență CPU, menținând o acuratețe de recunoaștere de 96% și de legare a entităților de 76% pe benchmark-uri standard.
Integrarea grafurilor de cunoștințe: Sistemele moderne combină tot mai des machine learning cu grafurile de cunoștințe — baze de date structurate care reprezintă entități și relațiile dintre ele. Grafurile de cunoștințe oferă informații contextuale bogate despre entități, proprietățile și relațiile acestora. Interogarea acestora în timpul dezambiguizării ajută la rezolvarea ambiguității cu mai multă acuratețe.
Dezambiguizarea entităților a devenit esențială în numeroase industrii și aplicații, fiecare beneficiind de identificarea și citarea corectă a entităților.
Motoare de căutare: Google, Bing și alte motoare de căutare se bazează puternic pe dezambiguizarea entităților pentru a returna rezultate relevante. Când un utilizator caută „Apple”, motorul trebuie să determine dacă se referă la Apple Inc., la fruct sau la altă entitate. Motoarele folosesc contextul interogării, istoricul utilizatorului și grafuri de cunoștințe pentru dezambiguizare, motiv pentru care rezultatele pentru „Apple” afișează de obicei compania tehnologică — sistemul a învățat că aceasta este entitatea cel mai des căutată.
Media și publishing: Organizațiile de știri și platformele de conținut folosesc dezambiguizarea entităților pentru a spori descoperirea conținutului și pentru a lega articolele relevante. Dacă un articol menționează „Apple”, sistemul poate lega automat către pagina Apple Inc. din baza de cunoștințe, oferind cititorilor contexte suplimentare și articole asociate. Acest lucru crește implicarea și ajută la înțelegerea contextului general al știrilor.
Sănătate: Instituțiile medicale utilizează dezambiguizarea entităților pentru a identifica corect medicamente, boli și proceduri medicale în fișe clinice și literatură de specialitate. Dezambiguizarea denumirilor de medicamente este critică — „aspirină” poate desemna substanța generică, un brand anume sau o variantă de dozaj. Dezambiguizarea corectă asigură accesul la informații precise și organizarea corectă a fișelor medicale.
Servicii financiare: Instituțiile de investiții și analiștii financiari folosesc dezambiguizarea entităților pentru a urmări mențiunile companiilor în știri, rapoarte financiare și date de piață. Pentru analiza expunerii la piață, trebuie identificate corect toate mențiunile despre o companie. Dezambiguizarea asigură că referințele la „Apple” sunt atribuite Apple Inc., nu altor entități, permițând evaluări exacte de risc și analiză de portofoliu.
E-commerce: Retailerii online folosesc dezambiguizarea entităților pentru a potrivi mențiunile de produse cu articolele reale din catalog. Când un client caută „laptop Apple”, sistemul trebuie să dezambiguizeze „Apple” ca firmă și să potrivească cu produsele relevante. Astfel, se îmbunătățește acuratețea căutărilor și experiența utilizatorului.
AmICited.com aplică principiile dezambiguizării pentru a monitoriza modul în care AI precum ChatGPT, Perplexity și Google AI Overviews gestionează mențiunile de branduri. Urmărind dacă aceste sisteme dezambiguizează corect brandurile și le citează precis, AmICited ajută brandurile să înțeleagă vizibilitatea și reprezentarea lor în conținutul AI.
Grafurile de cunoștințe au devenit fundamentale pentru sistemele moderne de dezambiguizare, oferind reprezentări structurate ale entităților și relațiilor dintre acestea. Un graf de cunoștințe este practic o bază de date de entități (noduri) și relațiile dintre ele (arce). Fiecare nod de entitate conține metadate precum nume, descriere, tip și proprietăți. De exemplu, în graf, „Apple Inc.” poate avea proprietăți precum „fondată în 1976”, „sediu în Cupertino”, „industrie: tehnologie” și relații de tip „fondată de Steve Jobs” sau „produce iPhone”.
Când un sistem de dezambiguizare întâlnește o mențiune ambiguă, poate interoga graful de cunoștințe pentru a accesa informații contextuale bogate despre entitățile candidate. Aceste date ajută sistemul să ia decizii mai informate. De exemplu, dacă sistemul încearcă să dezambiguizeze „Apple” și găsește în text referiri la „Steve Jobs”, poate interoga graful și descoperi asocierea puternică cu Apple Inc. Grafuri precum Wikidata și Wikipedia oferă informații publice folosite de multe sisteme AI. Grafurile proprietare dezvoltate de Google, Microsoft și alții adaugă date de domeniu suplimentare. Integrarea grafurilor cu modelele de machine learning a îmbunătățit semnificativ acuratețea dezambiguizării, combinând tipare învățate cu informații structurate.
În ciuda progreselor, sistemele de dezambiguizare se confruntă cu provocări persistente care limitează acuratețea și aplicabilitatea lor.
Polisemia și ambiguitatea: Multe denumiri de entități au mai multe sensuri legitime, iar contextul poate să nu fie suficient pentru dezambiguizare. „Bancă” poate desemna o instituție financiară sau malul unui râu. „Crane” poate fi o pasăre sau o macara de construcții. Unele denumiri sunt atât de ambigue încât chiar și oamenii au dificultăți fără context suplimentar. Sistemele AI trebuie să recunoască aceste cazuri și să le gestioneze adecvat.
Entități noi și emergente: Bazele de cunoștințe și seturile de date de antrenament devin învechite pe măsură ce apar entități noi. Când se fondează o companie sau apare un produs nou, sistemele pot să nu aibă informații despre acestea. Legarea zero-shot — abilitatea de a dezambiguiza entități necunoscute — rămâne o provocare. Sistemele trebuie să recunoască entitățile noi și să le gestioneze, nu să le asocieze greșit cu altele existente.
Variații de nume și greșeli de scriere: Entitățile au adesea mai multe denumiri, abrevieri și variante. „Statele Unite”, „SUA”, „U.S.” și „America” desemnează aceeași entitate. Greșelile de scriere complică și mai mult dezambiguizarea, mai ales în conținutul generat de utilizatori.
Date incomplete sau învechite: Bazele de cunoștințe pot conține informații incomplete sau învechite. Sediul unei companii poate fi schimbat, conducerea modificată sau compania achiziționată. Dacă baza nu se actualizează prompt, sistemul poate lua decizii pe baza unor date depășite.
Scalabilitate și performanță: Procesarea unor volume mari de text cu dezambiguizare de acuratețe ridicată necesită resurse computaționale semnificative. Dezambiguizarea în timp real pentru aplicații la scară web este costisitoare. Sistemele trebuie să echilibreze acuratețea cu viteza și costurile, acceptând uneori compromisuri.
Pentru branduri și creatori de conținut, înțelegerea dezambiguizării este esențială pentru a asigura reprezentarea corectă în conținutul generat de AI. Pe măsură ce AI devine tot mai influent în modul în care informația este descoperită și consumată, brandurile trebuie să ia măsuri proactive pentru a fi dezambiguizate și citate corect.
Strategii de pre-dezambiguizare: Brandurile pot implementa strategii pentru a facilita identificarea lor corectă de către AI. Una dintre cele mai importante este implementarea de date structurate folosind markup Schema.org și format JSON-LD pe site-urile de brand. Aceste date structurează explicit identitatea brandului — nume oficial, descriere, logo, sediu și alte caracteristici relevante. Când AI întâlnește numele brandului, poate consulta aceste date pentru confirmare.
Optimizarea prezenței în grafuri de cunoștințe: Brandurile ar trebui să aibă o prezență solidă în grafuri majore precum Wikidata și Wikipedia. Asta implică existența unor articole precise pe Wikipedia, completarea și actualizarea intrărilor Wikidata și crearea de relații cu alte entități relevante. Cu cât prezența este mai completă și corectă, cu atât AI are mai multe informații pentru dezambiguizare.
Strategie de conținut contextual: Brandurile pot crea conținut care clarifică identitatea lor și le diferențiază de alte entități cu nume similare. Conținutul ce menționează explicit industria, produsele, fondatorii și avantajele unice ajută AI să înțeleagă caracteristicile distinctive ale brandului. Acest conținut devine parte din datele de antrenament și contextul folosit de AI la dezambiguizare.
Monitorizarea citărilor: Instrumente precum AmICited.com permit brandurilor să monitorizeze modul în care AI le dezambiguizează și citează pe diferite platforme. Urmărind dacă ChatGPT, Perplexity, Google AI Overviews și alte sisteme identifică și citează corect brandul, pot fi identificate erori de dezambiguizare și pot fi luate măsuri corective. Această monitorizare este esențială pentru vizibilitatea brandului în era AI generativ.
Optimizarea pentru Generative Engine (GEO): Pe măsură ce dezambiguizarea devine vitală pentru vizibilitatea în AI, brandurile trebuie să includă optimizarea entității în strategia lor GEO. Asta presupune ca entitatea brandului să fie clar definită, bine documentată și ușor de distins față de competitori. GEO înseamnă nu doar SEO tradițional, ci și optimizare pentru modul în care AI înțelege și prezintă brandurile.
Dezambiguizarea entităților continuă să evolueze odată cu avansul tehnologiei AI și apariția de noi provocări. Mai multe tendințe modelează viitorul acestei capabilități critice:
Dezambiguizarea multilingvă: Pe măsură ce AI devine global, capacitatea de a dezambiguiza entități în mai multe limbi devine esențială. Un nume poate fi scris diferit în diverse limbi, iar aceeași entitate poate fi desemnată prin denumiri variate. Modele multilingve avansate sunt dezvoltate pentru a gestiona dezambiguizarea peste bariere lingvistice.
Dezambiguizare în timp real în LLM: Modelele mari de limbaj precum GPT-4 și Claude integrează din ce în ce mai mult dezambiguizarea entităților în timp real în timpul generării textului. Aceste modele pot interoga grafuri de cunoștințe și baze externe pentru a verifica informația și a asigura acuratețea dezambiguizării, reducând halucinațiile și îmbunătățind citarea.
Îmbunătățirea zero-shot learning: Sistemele viitoare vor performa mai bine în dezambiguizarea entităților neîntâlnite în antrenament. Tehnicile de few-shot și zero-shot learning vor permite recunoașterea mai eficientă a entităților noi, reducând nevoia de reantrenare frecventă.
Integrarea cu Retrieval-Augmented Generation (RAG): Sistemele RAG, care combină modele lingvistice cu recuperarea informației, devin tot mai populare. Acestea pot extrage în timp real informații despre entități din baze de cunoștințe în timpul generării textului, îmbunătățind acuratețea dezambiguizării și calitatea citării.
Standardizare și interoperabilitate: Pe măsură ce dezambiguizarea devine critică, este probabilă apariția unor standarde de industrie pentru reprezentarea și dezambiguizarea entităților. Acestea vor permite interoperabilitatea între sisteme și baze de date, facilitând accesul și utilizarea consistentă a informațiilor despre entități.
Dezambiguizarea entităților a evoluat dintr-o sarcină de nișă NLP într-o capabilitate esențială pentru ca sistemele AI să înțeleagă și să reprezinte corect informațiile. Pe măsură ce AI devine din ce în ce mai influent în descoperirea și consumul de informații, importanța dezambiguizării corecte a entităților va crește. Pentru branduri, creatori de conținut și organizații, înțelegerea și optimizarea pentru dezambiguizare este vitală pentru menținerea vizibilității și reprezentării corecte în era AI-ului generativ.
Recunoașterea entităților denumite identifică faptul că o entitate există într-un text și o clasifică în categorii precum persoană, organizație sau locație. Dezambiguizarea entităților merge mai departe, determinând care entitate specifică este referită atunci când mai multe entități împart același nume. De exemplu, NER identifică „Apple” ca organizație, în timp ce dezambiguizarea entităților stabilește dacă este vorba despre Apple Inc., Apple Bank sau o altă entitate.
Dezambiguizarea entităților asigură că sistemele AI înțeleg corect despre ce entitate este vorba și o citează în mod corespunzător. Conform Stanford AI Index 2024, peste 18% dintre rezultatele LLM care implică entități de brand conțin halucinații sau atribuire greșită. Dezambiguizarea corectă previne ca sistemele AI să confunde o entitate cu alta, ceea ce este esențial pentru menținerea reputației brandului și acurateței citărilor.
Grafurile de cunoștințe oferă informații structurate despre entități și relațiile dintre ele. Când un sistem AI întâlnește o mențiune ambiguă a unei entități, poate interoga graful de cunoștințe pentru a accesa metadate, descrieri și informații despre relațiile dintre entitățile candidate. Aceste informații contextuale ajută sistemul să ia decizii mai informate pentru dezambiguizare și să selecteze entitatea corectă.
Da, prin abordări de legare zero-shot a entităților. Sistemele moderne pot recunoaște când o entitate este nouă și o pot gestiona corespunzător, în loc să o potrivească incorect cu o entitate existentă. Totuși, aceasta rămâne o problemă dificilă, iar sistemele au performanțe mai bune când entitățile noi prezintă semnale contextuale clare care le diferențiază de cele existente.
Dezambiguizarea corectă a entităților asigură că brandul tău este identificat și citat corect în răspunsurile generate de AI. Când sistemele AI dezambiguizează corect brandul tău, utilizatorii primesc informații exacte despre organizația ta, ceea ce îmbunătățește vizibilitatea și reputația brandului. Dezambiguizarea greșită poate duce la confundarea brandului cu competitori sau alte entități, reducând vizibilitatea și putând afecta reputația.
Provocările cheie includ polisemia (mai multe sensuri pentru același nume), entități noi care nu sunt în datele de antrenament, variații de nume și greșeli de scriere, baze de cunoștințe incomplete sau învechite și probleme de scalabilitate. De asemenea, unele nume de entități sunt inerent ambigue, iar contextul singur poate să nu fie suficient pentru determinarea entității corecte.
Brandurile pot implementa date structurate folosind markup Schema.org, pot menține pagini precise pe Wikipedia și Wikidata, pot crea conținut contextual care să diferențieze clar brandul și pot monitoriza modul în care AI dezambiguizează brandul folosind instrumente precum AmICited. Aceste strategii ajută sistemele AI să identifice și să citeze corect brandul tău.
Contextul este esențial pentru dezambiguizarea entităților. Textul înconjurător, entitățile asociate și relațiile semantice oferă semnale care ajută sistemele AI să determine la ce entitate se face referire. De exemplu, dacă „Apple” apare lângă „Steve Jobs” și „tehnologie”, sistemul poate folosi acest context pentru a stabili corect că este vorba despre Apple Inc., nu despre fruct.
Urmărește acuratețea dezambiguizării entităților pe platformele AI și asigură-te că brandul tău este identificat și citat corect în răspunsurile generate de AI.
Recunoașterea Entităților este o capacitate NLP AI care identifică și categorizează entități denumite în text. Află cum funcționează, aplicațiile sale în monito...

Explorează modul în care sistemele AI recunosc și procesează entitățile din text. Află despre modelele NER, arhitecturi transformer și aplicații reale ale înțel...

Află cum legarea entităților conectează brandul tău între sistemele AI. Descoperă strategii pentru îmbunătățirea recunoașterii brandului în ChatGPT, Perplexity ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.