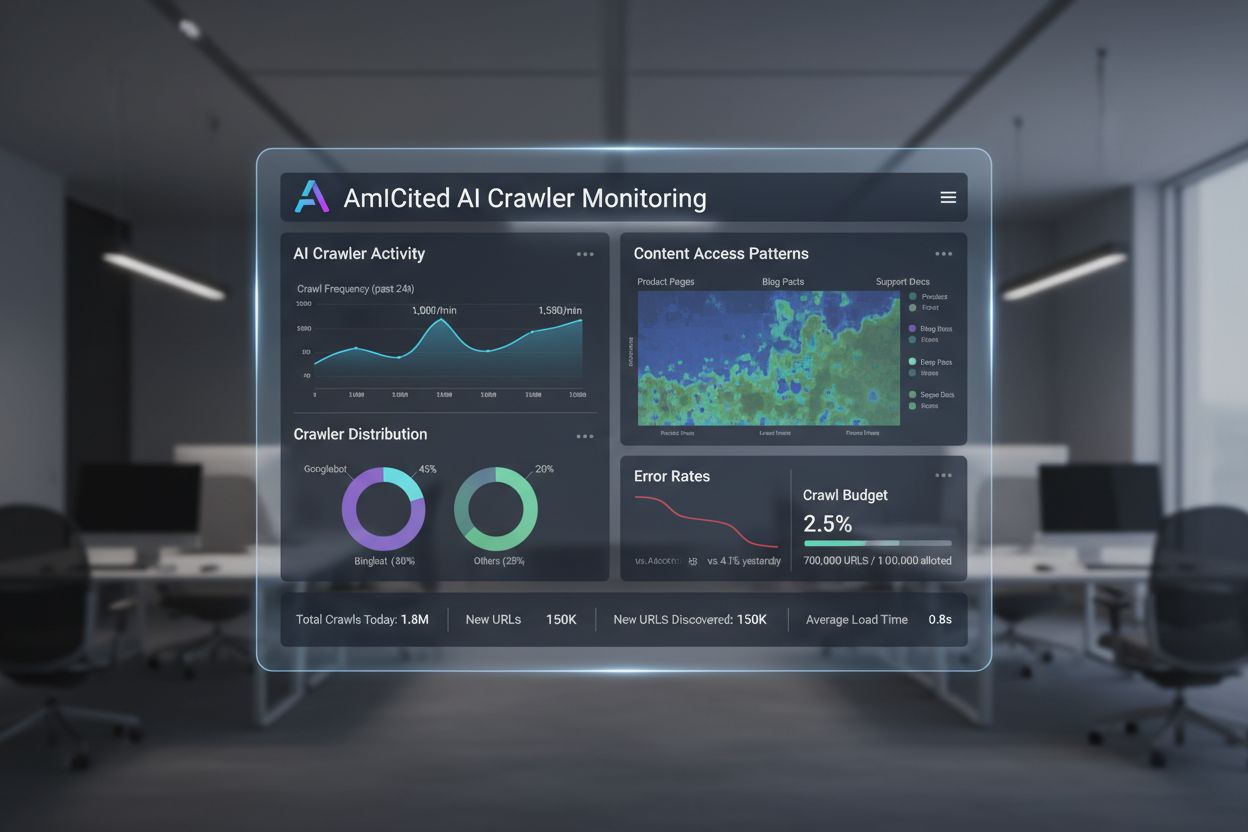
Analitica Crawl AI
Află ce este analitica crawl AI și cum analiza jurnalelor de server monitorizează comportamentul crawler-elor AI, tiparele de acces la conținut și vizibilitatea...
11 min citire

Analiza fișierelor jurnal este procesul de examinare a jurnalelor de acces ale serverului pentru a înțelege modul în care crawler-ele motoarelor de căutare și boții AI interacționează cu un site web, dezvăluind modele de accesare, probleme tehnice și oportunități de optimizare pentru performanța SEO.
Analiza fișierelor jurnal este procesul de examinare a jurnalelor de acces ale serverului pentru a înțelege modul în care crawler-ele motoarelor de căutare și boții AI interacționează cu un site web, dezvăluind modele de accesare, probleme tehnice și oportunități de optimizare pentru performanța SEO.
Analiza fișierelor jurnal este examinarea sistematică a jurnalelor de acces ale serverului pentru a înțelege cum interacționează crawler-ele motoarelor de căutare, boții AI și utilizatorii cu un site web. Aceste jurnale sunt generate automat de serverele web și conțin înregistrări detaliate ale fiecărei cereri HTTP făcute către site-ul tău, inclusiv adresa IP a solicitantului, marcajul temporal, URL-ul solicitat, codul de stare HTTP și șirul user-agent. Pentru profesioniștii SEO, analiza fișierelor jurnal este sursa supremă de adevăr despre comportamentul crawler-elor, dezvăluind modele pe care instrumentele de suprafață, precum Google Search Console sau crawler-ele tradiționale, nu le pot detecta. Spre deosebire de crawl-urile simulate sau datele de analiză agregate, jurnalele serverului oferă dovezi nefiltrate și de primă mână despre ce fac exact motoarele de căutare și sistemele AI pe site-ul tău în timp real.
Importanța analizei fișierelor jurnal a crescut exponențial pe măsură ce peisajul digital a evoluat. Cu peste 51% din traficul global de internet generat acum de boți (ACS, 2025), iar crawler-ele AI precum GPTBot, ClaudeBot și PerplexityBot devenind vizitatori constanți ai site-urilor, înțelegerea comportamentului crawler-elor nu mai este opțională—este esențială pentru menținerea vizibilității atât în căutarea tradițională, cât și pe platformele emergente alimentate de AI. Analiza fișierelor jurnal acoperă diferența dintre ceea ce crezi că se întâmplă pe site-ul tău și ceea ce se întâmplă de fapt, permițând decizii bazate pe date care influențează direct poziționarea în căutări, viteza de indexare și performanța organică generală.
Analiza fișierelor jurnal a fost o piatră de temelie a SEO tehnic de decenii, dar relevanța sa a crescut dramatic în ultimii ani. Istoric, profesioniștii SEO s-au bazat în principal pe Google Search Console și crawler-e terțe pentru a înțelege comportamentul motoarelor de căutare. Totuși, aceste instrumente au limitări semnificative: Google Search Console oferă doar date agregate, sampleate de la crawler-ele Google; crawler-ele terțe simulează comportamentul crawler-elor, nu interacțiuni reale; iar niciunul dintre aceste instrumente nu urmărește eficient motoarele de căutare non-Google sau boții AI.
Apariția platformelor de căutare alimentate de AI a schimbat fundamental peisajul. Conform cercetării Cloudflare din 2024, Googlebot reprezintă 39% din tot traficul crawler-elor AI și de căutare, iar crawler-ele AI reprezintă acum segmentul cu cea mai rapidă creștere. Doar boții AI ai Meta generează 52% din traficul crawler-elor AI, de peste două ori mai mult decât Google (23%) sau OpenAI (20%). Această schimbare înseamnă că site-urile primesc acum vizite de la zeci de tipuri diferite de boți, mulți dintre aceștia neurmând protocoalele SEO tradiționale sau nerespectând regulile standard robots.txt. Analiza fișierelor jurnal este singura metodă care surprinde această imagine completă, făcând-o indispensabilă pentru strategia SEO modernă.
Piața globală de management al jurnalelor este estimată să crească de la 3.228,5 milioane de dolari în 2025 la evaluări semnificativ mai mari până în 2029, cu o rată anuală compusă de creștere (CAGR) de 14,6%. Această creștere reflectă recunoașterea tot mai mare la nivel de întreprindere că analiza jurnalelor este esențială pentru securitate, monitorizarea performanței și optimizarea SEO. Organizațiile investesc masiv în instrumente automate de analiză a jurnalelor și platforme alimentate de AI care pot procesa milioane de înregistrări de jurnal în timp real, transformând date brute în perspective acționabile care generează rezultate de business.
Când un utilizator sau un bot solicită o pagină de pe site-ul tău, serverul web procesează acea cerere și înregistrează informații detaliate despre interacțiune. Acest proces are loc automat și continuu, creând un traseu de audit cuprinzător al întregii activități pe server. Înțelegerea modului în care funcționează acest proces este esențială pentru a interpreta corect datele din fișierele jurnal.
Fluxul tipic începe atunci când un crawler (fie Googlebot, un bot AI sau browserul unui utilizator) trimite o cerere HTTP GET către serverul tău, incluzând un șir user-agent care identifică solicitantul. Serverul primește această cerere, o procesează și returnează un cod de stare HTTP (200 pentru succes, 404 pentru pagină inexistentă, 301 pentru redirectare permanentă etc.), împreună cu conținutul solicitat. Fiecare dintre aceste interacțiuni este înregistrată în fișierul de jurnal de acces al serverului, creând o intrare cu marcaj temporal ce surprinde adresa IP, URL-ul solicitat, metoda HTTP, codul de stare, dimensiunea răspunsului, referer-ul și șirul user-agent.
Codurile de stare HTTP sunt deosebit de importante pentru analiza SEO. Un cod 200 indică livrarea cu succes a paginii; codurile 3xx indică redirectări; codurile 4xx indică erori de client (precum 404 Not Found); iar codurile 5xx indică erori de server. Analizând distribuția acestor coduri de stare în jurnale, poți identifica probleme tehnice care împiedică crawler-ele să acceseze conținutul. De exemplu, dacă un crawler primește mai multe răspunsuri 404 când încearcă să acceseze pagini importante, indică o problemă de link defect sau conținut lipsă care necesită atenție imediată.
Șirurile user-agent sunt la fel de critice pentru identificarea boților care vizitează site-ul. Fiecare crawler are un șir user-agent unic care îl identifică. User-agent-ul Googlebot include “Googlebot/2.1”, GPTBot include “GPTBot/1.0”, iar ClaudeBot include “ClaudeBot”. Prin analizarea acestor șiruri, poți segmenta datele din jurnal pentru a analiza comportamentul pe tipuri specifice de crawler, dezvăluind ce boți prioritizează ce conținut și cum diferă modelele lor de accesare. Această analiză granulară permite strategii de optimizare țintite pentru diferite platforme de căutare și sisteme AI.
| Aspect | Analiza fișierelor jurnal | Google Search Console | Crawler-e terțe | Instrumente de analiză |
|---|---|---|---|---|
| Sursa datelor | Jurnale server (de primă mână) | Date de acces Google | Crawl-uri simulate | Monitorizare comportament utilizatori |
| Completitudine | 100% din toate cererile | Date agregate, sampleate | Doar simulate | Doar trafic uman |
| Acoperire boți | Toți crawler-ii (Google, Bing, boți AI) | Doar Google | Crawler-e simulate | Fără date despre boți |
| Date istorice | Istoric complet (variază retenția) | Interval limitat | Snap-shot unic | Disponibile istoric |
| Perspective în timp real | Da (automatizare) | Raportare întârziată | Nu | Raportare întârziată |
| Vizibilitate buget accesare | Modele exacte de crawl | Rezumat la nivel înalt | Estimat | Neaplicabil |
| Probleme tehnice | Detaliat (coduri stare, timpi răspuns) | Vizibilitate limitată | Probleme simulate | Neaplicabil |
| Monitorizare boți AI | Da (GPTBot, ClaudeBot etc.) | Nu | Nu | Nu |
| Cost | Gratuit (jurnale server) | Gratuit | Instrumente plătite | Gratuit/Plătit |
| Complexitate configurare | Medie - ridicată | Simplă | Simplă | Simplă |
Analiza fișierelor jurnal a devenit indispensabilă pentru a înțelege modul în care motoarele de căutare și sistemele AI interacționează cu site-ul tău. Spre deosebire de Google Search Console, care oferă doar perspectiva Google și date agregate, fișierele jurnal surprind imaginea completă a activității tuturor crawler-elor. Această vedere cuprinzătoare este esențială pentru identificarea risipei bugetului de accesare, adică atunci când motoarele de căutare consumă resurse pentru pagini fără valoare în detrimentul conținutului important. Studiile arată că site-urile mari irosesc adesea 30-50% din bugetul de crawl pe URL-uri neesențiale precum arhive paginate, navigare pe fațete sau conținut învechit.
Ascensiunea căutării alimentate de AI face ca analiza fișierelor jurnal să fie și mai critică. Pe măsură ce boții AI precum GPTBot, ClaudeBot și PerplexityBot devin vizitatori constanți ai site-urilor, înțelegerea comportamentului lor este esențială pentru optimizarea vizibilității în răspunsurile generate de AI. Acești boți se comportă adesea diferit față de crawler-ele tradiționale—pot ignora regulile robots.txt, pot accesa site-ul mai agresiv sau se pot concentra pe anumite tipuri de conținut. Analiza fișierelor jurnal este singura metodă care dezvăluie aceste modele, permițându-ți să optimizezi site-ul pentru descoperirea AI și să gestionezi accesul boților prin reguli țintite.
Problemele tehnice SEO care altfel ar trece neobservate pot fi identificate prin analiza jurnalelor. Lanțuri de redirectări, erori de server 5xx, timpi lenți de încărcare și probleme de randare JavaScript lasă toate urme în jurnalele serverului. Analizând aceste tipare, poți prioritiza remedierea problemelor care influențează direct accesibilitatea și viteza de indexare. De exemplu, dacă jurnalele arată că Googlebot primește constant erori 503 Service Unavailable pe o anumită secțiune din site, știi exact unde să îți concentrezi eforturile tehnice.
Obținerea jurnalelor serverului este primul pas în analiza fișierelor jurnal, însă procesul variază în funcție de mediul de hosting. Pentru servere autogăzduite care rulează Apache sau NGINX, jurnalele sunt de obicei stocate în /var/log/apache2/access.log sau /var/log/nginx/access.log. Poți accesa aceste fișiere direct prin SSH sau din managerul de fișiere al serverului. Pentru gazde WordPress administrate precum WP Engine sau Kinsta, jurnalele pot fi disponibile în dashboard-ul de hosting sau prin SFTP, deși unii furnizori restricționează accesul pentru a proteja performanța serverului.
Rețelele de livrare a conținutului (CDN) precum Cloudflare, AWS CloudFront și Akamai necesită configurare specială pentru a accesa jurnalele. Cloudflare oferă Logpush, care trimite jurnalele cererilor HTTP în bucket-uri de stocare desemnate (AWS S3, Google Cloud Storage, Azure Blob Storage) pentru recuperare și analiză. AWS CloudFront oferă jurnalizare standard ce poate fi configurată pentru a stoca jurnale în bucket-uri S3. Aceste jurnale CDN sunt esențiale pentru a înțelege cum interacționează boții cu site-ul atunci când conținutul este servit prin CDN, deoarece surprind cererile la marginea rețelei, nu la serverul de origine.
Mediile de hosting partajat oferă adesea acces limitat la jurnale. Furnizori precum Bluehost și GoDaddy pot oferi jurnale parțiale prin cPanel, dar acestea sunt de obicei rotite frecvent și pot exclude câmpuri critice. Dacă folosești hosting partajat și ai nevoie de o analiză completă a jurnalelor, ia în considerare upgrade-ul la un VPS sau o soluție de hosting administrat care oferă acces complet la jurnale.
După ce ai obținut jurnalele, pregătirea datelor este esențială. Fișierele jurnal brute conțin cereri de la toate sursele—utilizatori, boți, scrapers și actori rău intenționați. Pentru analiza SEO, va trebui să filtrezi traficul nerelevant și să te concentrezi pe activitatea crawler-elor motoarelor de căutare și a boților AI. Aceasta implică de obicei:
Analiza fișierelor jurnal descoperă perspective invizibile pentru alte instrumente SEO, oferind baza pentru decizii strategice de optimizare. Una dintre cele mai valoroase perspective este analiza modelelor de crawl, care arată exact ce pagini vizitează motoarele de căutare și cât de des. Urmărind frecvența de crawl în timp, poți identifica dacă Google își crește sau scade atenția asupra anumitor secțiuni ale site-ului. Scăderi bruște ale frecvenței pot indica probleme tehnice sau schimbări de importanță a paginilor, în timp ce creșterile sugerează un răspuns pozitiv la eforturile tale de optimizare.
Eficiența bugetului de accesare este o altă perspectivă critică. Analizând raportul dintre răspunsurile de succes (2xx) și cele de eroare (4xx, 5xx), poți identifica secțiuni ale site-ului unde crawler-ele întâmpină probleme. Dacă un anumit director returnează constant erori 404, se irosește buget de crawl pe linkuri defecte. Similar, dacă crawler-ele petrec timp disproporționat pe URL-uri paginate sau navigare pe fațete, bugetul este consumat pe conținut cu valoare scăzută. Analiza jurnalelor cuantifică această risipă, permițându-ți să calculezi impactul potențial al optimizărilor.
Descoperirea paginilor orfane este un avantaj unic al analizei fișierelor jurnal. Paginile orfane sunt URL-uri fără linkuri interne, care există în afara structurii site-ului. Crawler-ele tradiționale le ratează adesea, deoarece nu le pot descoperi prin interlinking. Totuși, jurnalele arată că motoarele de căutare le accesează totuși—adesea pentru că sunt legate extern sau există în sitemap-uri vechi. Identificând aceste pagini orfane, poți decide dacă să le reintegrezi în structură, să le redirecționezi sau să le elimini complet.
Analiza comportamentului boților AI devine din ce în ce mai importantă. Segmentând datele jurnalelor după user-agent-uri AI, poți vedea ce conținut prioritizează acești boți, cât de des vizitează și dacă întâlnesc bariere tehnice. De exemplu, dacă GPTBot accesează constant paginile FAQ, dar rareori blogul, înseamnă că sistemele AI consideră conținutul de tip FAQ mai valoros pentru datele de antrenament. Această perspectivă poate influența strategia ta de conținut și te ajută să optimizezi vizibilitatea pentru AI.
O analiză de succes a fișierelor jurnal necesită atât instrumente potrivite, cât și o abordare strategică. Log File Analyzer de la Screaming Frog este unul dintre cele mai populare instrumente dedicate, oferind interfețe prietenoase pentru procesarea volumelor mari de jurnale, identificarea tiparelor de boți și vizualizarea datelor de crawl. Botify furnizează analiză de jurnal la nivel enterprise integrată cu metrici SEO, permițând corelarea activității boților cu poziționarea și traficul. Bot Clarity de la seoClarity integrează analiza jurnalelor direct în platforma SEO, facilitând conectarea datelor de crawl cu alți indicatori SEO.
Pentru organizațiile cu trafic mare sau infrastructură complexă, platformele de analiză a jurnalelor alimentate de AI precum Splunk, Sumo Logic și Elastic Stack oferă capabilități avansate, inclusiv recunoaștere automată a tiparelor, detecție de anomalii și analiză predictivă. Aceste platforme pot procesa milioane de înregistrări în timp real, identificând automat noi tipuri de boți și semnalând activități neobișnuite care pot indica amenințări de securitate sau probleme tehnice.
Bune practici pentru analiza fișierelor jurnal includ:
Pe măsură ce căutarea alimentată de AI devine tot mai importantă, monitorizarea boților AI prin analiza fișierelor jurnal a devenit o funcție SEO critică. Urmărind ce boți AI vizitează site-ul, ce conținut accesează și cât de des, poți înțelege cum conținutul tău ajunge în instrumente de căutare AI și modele generative. Aceste date îți permit să iei decizii informate despre dacă permiți, blochezi sau limitezi accesul unor boți AI prin reguli robots.txt sau anteturi HTTP.
Optimizarea bugetului de crawl este probabil cea mai impactantă aplicație a analizei fișierelor jurnal. Pentru site-urile mari cu mii sau milioane de pagini, bugetul de crawl este o resursă finită. Analizând jurnalele, poți identifica pagini care sunt accesate excesiv în raport cu importanța lor și pagini care ar trebui accesate mai des, dar nu sunt. Scenarii comune de risipă a bugetului includ:
Rezolvând aceste probleme—prin reguli robots.txt, canonicale, tag-uri noindex sau optimizări tehnice—poți redirecționa bugetul de crawl către conținutul de valoare, îmbunătățind viteza de indexare și vizibilitatea pentru paginile care contează cel mai mult pentru afacerea ta.
Viitorul analizei fișierelor jurnal este modelat de evoluția rapidă a căutării alimentate de AI. Pe măsură ce tot mai mulți boți AI apar și comportamentul lor devine mai sofisticat, analiza jurnalelor va fi și mai critică pentru a înțelege modul în care conținutul tău este descoperit, accesat și folosit de sistemele AI. Tendințele emergente includ:
Analiza jurnalelor în timp real alimentată de machine learning va permite specialiștilor SEO să detecteze și să răspundă la probleme de crawl în câteva minute, nu zile. Sistemele automate vor identifica noi tipuri de boți, vor semnala modele neobișnuite și vor sugera acțiuni de optimizare fără intervenție manuală. Această trecere de la analiză reactivă la una proactivă va permite menținerea continuă a accesabilității și indexării optime.
Integrarea cu monitorizarea vizibilității AI va conecta datele din fișierele jurnal cu metrici de performanță în căutarea AI. În loc să analizezi jurnalele izolat, vei corela comportamentul crawler-elor cu vizibilitatea efectivă în răspunsurile generate de AI, înțelegând exact cum modelele de crawl influențează poziționarea în căutările AI. Această integrare va oferi o perspectivă fără precedent asupra modului în care conținutul ajunge din crawl, în date de antrenament AI, până la răspunsurile AI pentru utilizatori.
Managementul etic al boților va deveni tot mai important pe măsură ce organizațiile se confruntă cu întrebări privind ce boți AI ar trebui să aibă acces la conținut. Analiza fișierelor jurnal va permite control granular asupra accesului, permițând publisher-ilor să accepte crawler-ii AI benefici și să-i blocheze pe cei care nu oferă valoare sau atribuire. Standarde precum protocolul emergent LLMs.txt vor oferi modalități structurate de comunicare a politicilor de acces pentru boți, iar analiza fișierelor jurnal va verifica respectarea acestor politici.
Analiza cu respectarea confidențialității va evolua pentru a echilibra nevoia de perspective detaliate asupra crawl-ului cu reglementările precum GDPR. Tehnicile avansate de anonimizare și instrumentele de analiză orientate pe confidențialitate vor permite extragerea de perspective valoroase fără a stoca sau expune informații personale. Acest aspect va fi deosebit de important pe măsură ce analiza jurnalelor devine mai răspândită și reglementările privind protecția datelor devin mai stricte.
Convergența dintre SEO tradițional și optimizarea pentru căutarea AI înseamnă că analiza fișierelor jurnal va rămâne o piatră de temelie a strategiei SEO tehnice pentru mulți ani de acum înainte. Organizațiile care stăpânesc analiza fișierelor jurnal astăzi vor fi cele mai bine poziționate pentru a-și menține vizibilitatea și performanța pe măsură ce căutarea continuă să evolueze.
Analiza fișierelor jurnal oferă date complete, nesampleate, direct de pe serverul tău, capturând fiecare solicitare de la toți crawler-ii, în timp ce statisticile de acces din Google Search Console arată doar date agregate, sampleate de la crawler-ii Google. Fișierele jurnal oferă date istorice detaliate și perspective asupra comportamentului boților non-Google, inclusiv a crawler-ilor AI precum GPTBot și ClaudeBot, făcându-le mult mai cuprinzătoare pentru înțelegerea comportamentului real al crawler-elor și identificarea problemelor tehnice pe care GSC le poate rata.
Pentru site-urile cu trafic mare, se recomandă analiza săptămânală a fișierelor jurnal pentru a identifica rapid problemele și a monitoriza modificările în modelele de accesare. Site-urile mai mici beneficiază de revizuiri lunare pentru a stabili trenduri și a identifica activitate nouă a boților. Indiferent de dimensiunea site-ului, implementarea monitorizării continue prin instrumente automate ajută la detectarea anomaliilor în timp real, asigurând un răspuns rapid la risipa de buget de accesare sau la probleme tehnice care afectează vizibilitatea în căutări.
Da, analiza fișierelor jurnal este una dintre cele mai eficiente metode de a urmări traficul boților AI. Prin examinarea șirurilor user-agent și a adreselor IP din jurnalele serverului, poți identifica ce boți AI vizitează site-ul, ce conținut accesează și cât de des îl accesează. Aceste date sunt cruciale pentru a înțelege modul în care conținutul tău ajunge în instrumente de căutare AI și modele generative AI, permițându-ți să optimizezi vizibilitatea pentru AI și să gestionezi accesul boților prin reguli robots.txt.
Analiza fișierelor jurnal dezvăluie numeroase probleme tehnice SEO, inclusiv erori de accesare (coduri de stare 4xx și 5xx), lanțuri de redirectări, timpi lenți de încărcare a paginilor, pagini orfane care nu sunt legate intern, risipă de buget de accesare pe URL-uri cu valoare redusă, probleme de randare JavaScript și conținut duplicat. De asemenea, identifică activitatea boților falși și ajută la detectarea cazurilor când crawler-ele legitime întâmpină bariere de accesibilitate, astfel încât să poți prioritiza remedierea problemelor care afectează direct vizibilitatea și indexarea în motoarele de căutare.
Analiza fișierelor jurnal îți arată exact ce pagini accesează motoarele de căutare și cât de des, dezvăluind unde se irosește bugetul de accesare pe conținut cu valoare redusă precum arhivele paginilor, navigarea pe fațete sau URL-uri învechite. Identificând aceste ineficiențe, poți ajusta fișierul robots.txt, îmbunătăți legăturile interne către paginile prioritare și implementa canonicals pentru a redirecționa atenția crawler-elor către conținutul cu valoare ridicată, asigurând că motoarele de căutare se concentrează pe paginile care contează cel mai mult pentru afacerea ta.
Fișierele jurnal ale serverului captează de obicei adrese IP (identificând sursa solicitărilor), marcaje temporale (când au avut loc solicitările), metode HTTP (de obicei GET sau POST), URL-uri solicitate (paginile exacte accesate), coduri de stare HTTP (200, 404, 301 etc.), dimensiuni ale răspunsului în bytes, informații despre referrer și șiruri user-agent (identificând crawler-ul sau browserul). Aceste date cuprinzătoare permit specialiștilor SEO să reconstruiască exact ce s-a întâmplat la fiecare interacțiune cu serverul și să identifice tipare care afectează accesibilitatea și indexarea.
Boții falși pretind că sunt crawler-e legitime ale motoarelor de căutare, dar au adrese IP care nu corespund intervalelor publicate de motoarele de căutare. Pentru a-i identifica, compară șirurile user-agent (cum ar fi 'Googlebot') cu intervalele oficiale de IP publicate de Google, Bing și alte motoare de căutare. Instrumente precum Log File Analyzer de la Screaming Frog validează automat autenticitatea boților. Boții falși risipesc bugetul de accesare și pot solicita excesiv serverul, așa că blocarea lor prin robots.txt sau reguli de firewall este recomandată.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Află ce este analitica crawl AI și cum analiza jurnalelor de server monitorizează comportamentul crawler-elor AI, tiparele de acces la conținut și vizibilitatea...

Discuție în comunitate despre frecvența și comportamentul crawler-elor AI. Date reale de la webmasteri care urmăresc GPTBot, PerplexityBot și alți boți AI în ju...
Analiza SERP este procesul de examinare a paginilor de rezultate ale motoarelor de căutare pentru a înțelege dificultatea poziționării, intenția de căutare și s...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.