
Arhitectura Transformer
Arhitectura Transformer este un design de rețea neuronală care utilizează mecanisme de autoatenție pentru a procesa date secvențiale în paralel. Ea alimentează ...
14 min citire
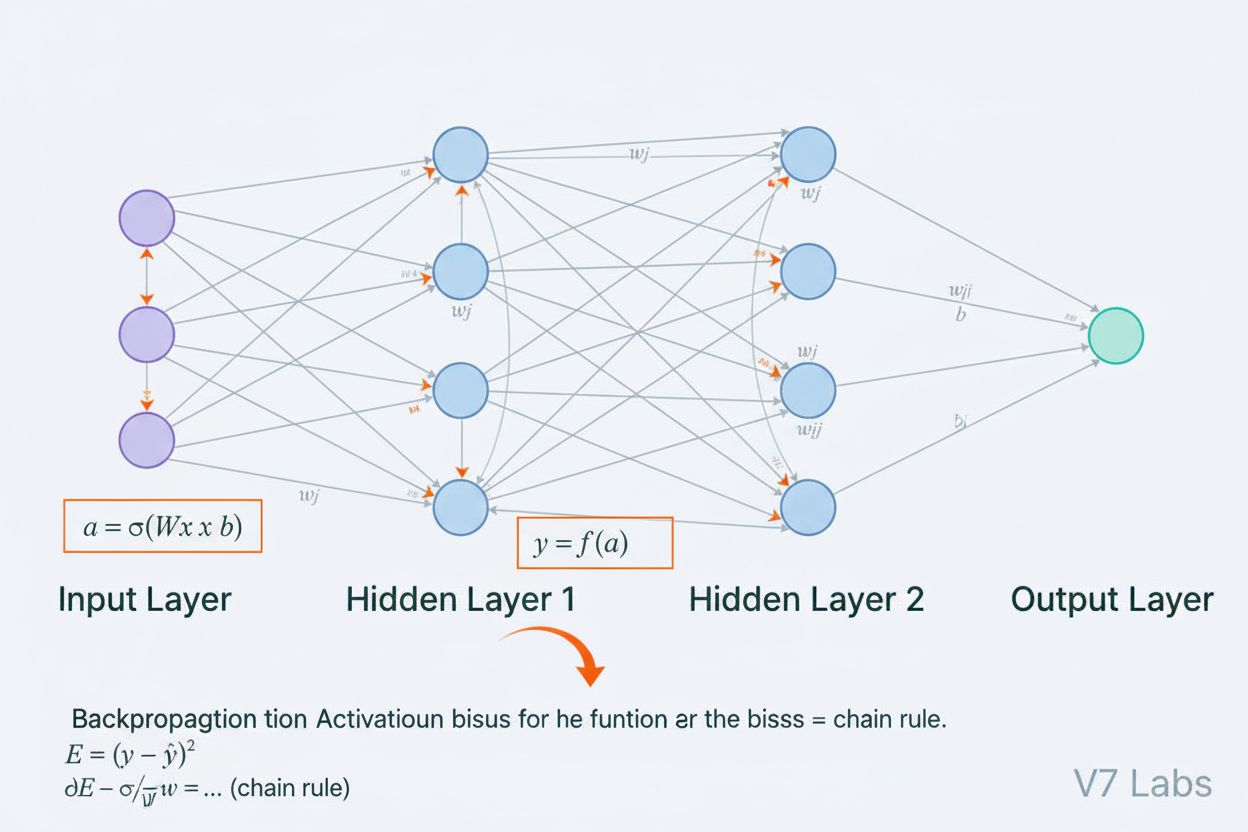
O rețea neurală este un sistem de calcul inspirat de rețelele neuronale biologice, format din neuroni artificiali interconectați, organizați în straturi, capabili să învețe tipare din date printr-un proces numit retropropagare. Aceste sisteme stau la baza inteligenței artificiale moderne și a învățării profunde, alimentând aplicații de la procesarea limbajului natural până la viziunea computerizată.
O rețea neurală este un sistem de calcul inspirat de rețelele neuronale biologice, format din neuroni artificiali interconectați, organizați în straturi, capabili să învețe tipare din date printr-un proces numit retropropagare. Aceste sisteme stau la baza inteligenței artificiale moderne și a învățării profunde, alimentând aplicații de la procesarea limbajului natural până la viziunea computerizată.
O rețea neurală este un sistem de calcul fundamental inspirat de structura și funcționarea rețelelor neuronale biologice întâlnite în creierele animalelor. Ea constă din neuroni artificiali interconectați, organizați în straturi—de obicei un strat de intrare, unul sau mai multe straturi ascunse și un strat de ieșire—care lucrează împreună pentru a procesa date, a recunoaște tipare și a face predicții. Fiecare neuron primește intrări, aplică transformări matematice prin greutăți și biasuri și transmite rezultatul printr-o funcție de activare pentru a produce o ieșire. Caracteristica definitorie a rețelelor neurale este abilitatea lor de a învăța din date printr-un proces iterativ numit retropropagare, în cadrul căruia rețeaua își ajustează parametrii interni pentru a minimiza erorile de predicție. Această capacitate de învățare, combinată cu abilitatea de a modela relații complexe nelineare, a făcut din rețelele neurale tehnologia fundamentală care alimentează sistemele moderne de inteligență artificială, de la modele mari de limbaj la aplicații de viziune computerizată.
Conceptul de rețele neurale artificiale a apărut din încercările timpurii de a modela matematic modul în care neuronii biologici comunică și procesează informația. În 1943, Warren McCulloch și Walter Pitts au propus primul model matematic al unui neuron, demonstrând că unități computaționale simple pot efectua operații logice. Această fundație teoretică a fost urmată de introducerea perceptronului de către Frank Rosenblatt în 1958, un algoritm conceput pentru recunoașterea tiparelor care a devenit strămoșul istoric al arhitecturilor sofisticate de rețele neurale de astăzi. Perceptronul era practic un model liniar cu ieșire constrânsă, capabil să învețe frontiere de decizie simple. Totuși, domeniul a suferit regres în anii 1970 când cercetătorii au descoperit că perceptronii cu un singur strat nu pot rezolva probleme nelineare precum funcția XOR, ducând la ceea ce s-a numit “iarna AI”. Progresul decisiv a venit în anii 1980 odată cu redescoperirea și perfecționarea retropropagării, un algoritm care a permis antrenarea rețelelor cu mai multe straturi. Această revenire a accelerat dramatic în anii 2010 odată cu disponibilitatea seturilor de date masive, a procesoarelor GPU puternice și a tehnicilor de antrenament rafinate, conducând la revoluția deep learning care a transformat inteligența artificială.
Arhitectura unei rețele neurale cuprinde mai multe componente esențiale care colaborează. Stratul de intrare primește caracteristicile brute ale datelor din surse externe, fiecare neuron din acest strat corespunde unei caracteristici. Straturile ascunse realizează procesarea calculată, transformând intrările în reprezentări tot mai abstracte prin combinații ponderate și funcții de activare nelineare. Numărul și dimensiunea straturilor ascunse determină capacitatea rețelei de a învăța tipare complexe—rețelele mai adânci pot surprinde relații mai sofisticate, dar necesită mai multe date și resurse computaționale. Stratul de ieșire produce predicțiile finale, structura lui depinzând de sarcină: un singur neuron pentru regresie, mai mulți neuroni pentru clasificare multi-clasă sau arhitecturi specializate pentru alte aplicații. Fiecare conexiune dintre neuroni are o greutate care determină forța influenței, iar fiecare neuron are un bias care modifică pragul de activare. Aceste greutăți și biasuri sunt parametrii învățați pe care rețeaua îi ajustează în timpul antrenamentului. Funcția de activare aplicată la fiecare neuron introduce nelinearitatea crucială, permițând rețelei să învețe frontiere de decizie complexe și tipare pe care modelele liniare nu le pot surprinde.
Rețelele neurale învață printr-un proces iterativ în două faze. În propagarea înainte, datele de intrare curg prin rețea de la stratul de intrare la cel de ieșire. La fiecare neuron, suma ponderată a intrărilor plus biasul este calculată (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), apoi trecută printr-o funcție de activare pentru a produce ieșirea neuronului. Acest proces se repetă prin fiecare strat ascuns până la stratul de ieșire, care produce predicția rețelei. Rețeaua calculează apoi eroarea dintre predicție și eticheta reală folosind o funcție de pierdere, care cuantifică cât de departe este predicția față de răspunsul corect. În retropropagare, această eroare este propagată înapoi prin rețea folosind regula lanțului din calculul diferențial. La fiecare neuron, algoritmul calculează gradientul funcției de pierdere față de fiecare greutate și bias, determinând cât a contribuit fiecare parametru la eroarea totală. Acești gradienți ghidează actualizările parametrilor: greutățile și biasurile sunt ajustate în direcția opusă gradientului, scalate cu o rată de învățare ce controlează pasul de actualizare. Acest proces se repetă pe parcursul multor iterații prin setul de antrenament, reducând treptat pierderea și îmbunătățind predicțiile rețelei. Combinația dintre propagarea înainte, calculul pierderii, retropropagare și actualizarea parametrilor formează ciclul complet de antrenament ce permite rețelelor neurale să învețe din date.
| Tip Arhitectură | Caz de Utilizare Principal | Caracteristică Cheie | Puncte Forte | Limitări |
|---|---|---|---|---|
| Rețele Feedforward | Clasificare, regresie pe date structurate | Informația circulă într-o singură direcție | Antrenare simplă, rapidă, interpretabilă | Nu gestionează bine date secvențiale sau spațiale |
| Rețele Neuronale Convoluționale (CNN) | Recunoaștere imagini, viziune computerizată | Straturi convoluționale detectează caracteristici spațiale | Excelează în captarea tiparelor locale, eficiente ca parametri | Necestită seturi mari de imagini etichetate |
| Rețele Neuronale Recurente (RNN) | Date secvențiale, serii de timp, NLP | Starea ascunsă menține memoria de-a lungul pașilor | Pot procesa secvențe de lungime variabilă | Suferă de probleme cu gradientul care dispare/explodează |
| Long Short-Term Memory (LSTM) | Dependențe pe termen lung în secvențe | Celule de memorie cu uși de intrare/uitare/ieșire | Gestionează eficient dependențele pe termen lung | Mai complexe, antrenare mai lentă decât RNN |
| Rețele Transformer | Procesare limbaj natural, modele mari de limbaj | Mecanism de atenție multi-head, procesare paralelă | Foarte paralelizabile, surprind dependențe pe termen lung | Necestită resurse computaționale masive |
| Rețele Generative Adversariale (GAN) | Generare imagini, creare date sintetice | Generator și discriminator concurenți | Pot genera date sintetice realiste | Dificil de antrenat, probleme de tip mode collapse |
Introducerea funcțiilor de activare reprezintă una dintre cele mai importante inovații în proiectarea rețelelor neurale. Fără funcții de activare, o rețea neurală ar fi matematic echivalentă cu o singură transformare liniară, indiferent de câte straturi conține. Aceasta deoarece compunerea funcțiilor liniare este tot liniară, ceea ce limitează sever capacitatea rețelei de a învăța tipare complexe. Funcțiile de activare rezolvă această problemă introducând nelinearitate la fiecare neuron. Funcția ReLU (Rectified Linear Unit), definită ca f(x) = max(0, x), a devenit alegerea predominantă în deep learning-ul modern datorită eficienței computaționale și eficacității în antrenarea rețelelor profunde. Funcția sigmoid, f(x) = 1/(1 + e^(-x)), restrânge ieșirile la un interval între 0 și 1, fiind utilă în clasificarea binară. Funcția tanh, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), produce ieșiri între -1 și 1 și adesea performează mai bine decât sigmoid în straturile ascunse. Alegerea funcției de activare influențează semnificativ dinamica de învățare a rețelei, viteza de convergență și performanța finală. Arhitecturile moderne folosesc adesea ReLU în straturile ascunse pentru eficiență computațională și sigmoid sau softmax în stratul de ieșire pentru estimarea probabilităților. Nelinearitatea introdusă de funcțiile de activare permite rețelelor neurale să aproximeze orice funcție continuă, proprietate cunoscută sub numele de teorema universală de aproximare, ceea ce explică versatilitatea lor remarcabilă în diverse aplicații.
Piața rețelelor neurale a cunoscut o creștere explozivă, reflectând rolul central al acestei tehnologii în inteligența artificială modernă. Potrivit cercetărilor de piață recente, piața globală de software pentru rețele neurale era evaluată la aproximativ 34,76 miliarde $ în 2025 și se estimează că va ajunge la 139,86 miliarde $ până în 2030, reprezentând o rată anuală compusă de creștere (CAGR) de 32,10%. Piața mai largă a rețelelor neurale arată o expansiune și mai dramatică, cu estimări ce indică o creștere de la 34,05 miliarde $ în 2024 la 385,29 miliarde $ până în 2033, cu un CAGR de 31,4%. Această creștere explozivă este determinată de mai mulți factori: disponibilitatea tot mai mare a seturilor mari de date, dezvoltarea algoritmilor de antrenament mai eficienți, proliferarea GPU-urilor și hardware-ului AI specializat, și adoptarea pe scară largă a rețelelor neurale în diverse industrii. Conform raportului AI Index Stanford 2025, 78% dintre organizații au raportat utilizarea AI în 2024, față de 55% cu un an înainte, rețelele neurale constituind coloana vertebrală a majorității implementărilor AI la nivel enterprise. Adoptarea acoperă sănătatea, finanțele, producția, retailul și practic orice alt sector, pe măsură ce organizațiile recunosc avantajul competitiv oferit de sistemele bazate pe rețele neurale pentru recunoașterea tiparelor, predicție și luarea deciziilor.
Rețelele neurale alimentează cele mai avansate sisteme AI actuale, inclusiv ChatGPT, Perplexity, Google AI Overviews și Claude. Aceste modele mari de limbaj sunt construite pe arhitecturi de rețele neurale de tip transformer, care folosesc mecanisme de atenție pentru a procesa și genera limbaj uman cu o sofisticare remarcabilă. Arhitectura transformer, introdusă în 2017, a revoluționat procesarea limbajului natural prin permiterea procesării paralele a întregii secvențe în loc de procesarea secvențială, îmbunătățind dramatic eficiența antrenamentului și performanța modelelor. În contextul monitorizării brandului și al urmăririi citărilor AI, înțelegerea rețelelor neurale este crucială deoarece aceste sisteme folosesc rețele neurale pentru a înțelege contextul, a regăsi informații relevante și a genera răspunsuri care pot face referire sau cita brandul, domeniul sau conținutul tău. AmICited folosește cunoașterea modului în care rețelele neurale procesează și regăsesc informația pentru a monitoriza unde apare brandul tău în răspunsurile generate de AI pe mai multe platforme. Pe măsură ce rețelele neurale devin tot mai bune în a înțelege sensul semantic și a regăsi informații relevante, importanța monitorizării prezenței brandului tău în răspunsurile AI devine din ce în ce mai critică pentru menținerea vizibilității și gestionarea reputației online în era căutării și generării de conținut bazate pe AI.
Antrenarea eficientă a rețelelor neurale prezintă mai multe provocări semnificative pe care cercetătorii și practicienii trebuie să le abordeze. Supraînvățarea apare când o rețea învață prea bine datele de antrenament, inclusiv zgomotul și particularitățile acestora, ducând la performanță slabă pe date noi, nevăzute. Aceasta este o problemă în special la rețelele profunde cu mulți parametri față de dimensiunea datelor de antrenament. Subînvățarea este problema opusă, când rețeaua nu are suficientă capacitate sau antrenament pentru a surprinde tiparele din date. Problema gradientului care dispare apare în rețele foarte profunde când gradientul devine exponențial mai mic pe măsură ce se propagă înapoi, determinând actualizări foarte lente sau inexistente ale greutăților din straturile timpurii. Problema gradientului care explodează este opusul, când gradientul devine exponențial mai mare, cauzând instabilitate la antrenament. Soluțiile moderne includ normalizarea pe batch, care normalizează intrările în straturi pentru a menține fluxul stabil al gradientului; conexiunile reziduale (skip connections), care permit gradientului să treacă direct prin straturi; și tăierea gradientului (gradient clipping), care limitează magnitudinea gradientului. Tehnicile de regularizare precum regularizarea L1 și L2 introduc penalizări pentru greutăți mari, încurajând modele mai simple, ce generalizează mai bine. Dropout dezactivează aleator neuroni în timpul antrenamentului, prevenind co-adaptarea și îmbunătățind generalizarea. Alegerea optimizatorului (precum Adam, SGD sau RMSprop) și a ratei de învățare influențează semnificativ eficiența antrenamentului și performanța finală a modelului. Practicienii trebuie să echilibreze cu atenție complexitatea modelului, dimensiunea datelor de antrenament, forța regularizării și parametrii de optimizare pentru a obține rețele care învață eficient fără supraînvățare.
Evoluția arhitecturilor de rețele neurale a urmat o traiectorie clară către mecanisme tot mai sofisticate de procesare a informației. Rețelele feedforward timpurii erau limitate la intrări de dimensiune fixă și nu puteau surprinde dependențe temporale sau secvențiale. Rețelele neuronale recurente (RNN) au introdus bucle de feedback permițând persistența informației de-a lungul pașilor de timp, facilitând procesarea secvențelor de lungime variabilă. Totuși, RNN-urile sufereau de probleme cu fluxul gradientului și erau inerent secvențiale, ceea ce împiedica paralelizarea pe hardware modern. Rețelele LSTM au rezolvat parțial aceste probleme prin celule de memorie și mecanisme de uși, dar au rămas fundamental secvențiale. Progresul decisiv a venit cu rețelele transformer, care au înlocuit recurența cu mecanisme de atenție. Mecanismul de atenție permite rețelei să se concentreze dinamic pe diferite părți ale intrării, calculând combinații ponderate ale tuturor elementelor de intrare în paralel. Astfel, transformer-ele pot surprinde eficient dependențe pe distanțe mari și pot fi complet paralelizate pe clustere GPU. Arhitectura transformer, combinată cu scalare masivă (modelele mari de limbaj moderne conțin miliarde până la trilioane de parametri), s-a dovedit extrem de eficientă pentru procesarea limbajului natural, viziune computerizată și sarcini multimodale. Succesul transformer-elor a condus la adoptarea acestora drept arhitectură standard pentru sistemele AI de ultimă generație, inclusiv toate modelele mari de limbaj. Această evoluție demonstrează cum inovațiile arhitecturale, combinate cu resurse computaționale tot mai mari și seturi de date extinse, continuă să împingă limitele a ceea ce pot realiza rețelele neurale.
Domeniul rețelelor neurale continuă să evolueze rapid, cu mai multe direcții promițătoare în curs de dezvoltare. Computarea neuromorfă își propune să creeze hardware care imită mai fidel rețelele neuronale biologice, obținând potențial o eficiență energetică și o putere de calcul superioare. Cercetarea în few-shot și zero-shot learning se concentrează pe abilitatea rețelelor neurale de a învăța din foarte puține exemple, apropiindu-se mai mult de modul de învățare uman. Explicabilitatea și interpretabilitatea devin tot mai importante, cercetătorii dezvoltând tehnici pentru a înțelege și vizualiza ce anume învață rețelele neurale, esențial pentru aplicații cu mize mari în sănătate, finanțe sau justiție. Învățarea federativă permite antrenarea rețelelor pe date distribuite fără centralizarea informațiilor sensibile, abordând preocupările legate de confidențialitate. Rețelele neurale cuantice reprezintă o frontieră unde principiile calculului cuantic sunt combinate cu arhitecturile de rețele neurale, promițând accelerări exponențiale pentru anumite probleme. Rețelele multimodale care integrează fără probleme text, imagini, audio și video devin tot mai sofisticate, permițând sisteme AI mai cuprinzătoare. Rețelele neurale eficiente energetic sunt dezvoltate pentru a reduce costurile computaționale și de mediu ale antrenării și implementării modelelor mari. Pe măsură ce rețelele neurale continuă să avanseze, integrarea lor în sisteme de monitorizare AI precum AmICited devine tot mai importantă pentru organizațiile care doresc să înțeleagă și să gestioneze prezența brandului în conținutul și răspunsurile generate de AI pe platforme precum ChatGPT, Perplexity, Google AI Overviews și Claude.
Rețelele neurale sunt inspirate de structura și funcția neuronilor biologici din creierul uman. În creier, neuronii comunică prin semnale electrice prin intermediul sinapselor, care pot fi întărite sau slăbite pe baza experienței. Rețelele neurale artificiale imită acest comportament folosind modele matematice de neuroni conectați prin legături ponderate, permițând sistemului să învețe și să se adapteze pe baza datelor într-un mod analog modului în care creierul biologic procesează informații și formează amintiri.
Retropropagarea este principalul algoritm care permite rețelelor neurale să învețe. În timpul propagării înainte, datele parcurg straturile rețelei, generând predicții. Rețeaua calculează apoi eroarea dintre ieșirile prezise și cele reale folosind o funcție de pierdere. În trecerea înapoi, această eroare este propagată înapoi prin rețea folosind regula lanțului din calculul diferențial, calculând cât de mult a contribuit fiecare greutate și bias la eroare. Greutățile sunt apoi ajustate în direcția care minimizează eroarea, de obicei folosind optimizarea cu coborârea gradientului.
Principalele arhitecturi de rețele neurale includ rețelele feedforward (datele circulă într-o singură direcție), rețelele neuronale convoluționale sau CNN (optimizate pentru procesarea imaginilor), rețelele neuronale recurente sau RNN (proiectate pentru date secvențiale), rețelele LSTM (RNN îmbunătățite cu celule de memorie) și rețelele transformer (folosesc mecanisme de atenție pentru procesare paralelă). Fiecare arhitectură este specializată pentru diferite tipuri de date și sarcini, de la recunoașterea imaginilor la procesarea limbajului natural.
Sistemele AI moderne precum ChatGPT, Perplexity și Claude sunt construite pe rețele neurale de tip transformer, care folosesc mecanisme de atenție pentru a procesa limbajul eficient. Aceste rețele neurale permit acestor sisteme să înțeleagă contextul, să genereze texte coerente și să realizeze sarcini complexe de raționament. Capacitatea rețelelor neurale de a învăța din seturi masive de date și de a surprinde tipare complexe în limbaj le face esențiale pentru construirea AI conversațional capabil să înțeleagă și să răspundă la întrebările oamenilor cu o acuratețe remarcabilă.
Greutățile din rețelele neurale controlează puterea conexiunilor dintre neuroni, determinând cât de mult influențează fiecare intrare ieșirea. Biasurile sunt parametri suplimentari care modifică pragul de activare al neuronilor, permițându-le să se activeze chiar și când intrările sunt slabe. Împreună, greutățile și biasurile formează parametrii învățați ai rețelei, care sunt ajustați în timpul antrenamentului pentru a minimiza erorile de predicție și pentru a permite rețelei să învețe tipare complexe din date.
Funcțiile de activare introduc nelinearitate în rețelele neurale, permițându-le să învețe relații complexe, nelineare din date. Fără funcții de activare, chiar și suprapunând mai multe straturi, transformările ar rămâne liniare, limitând sever capacitatea rețelei de a învăța. Funcții de activare comune includ ReLU (Rectified Linear Unit), sigmoid și tanh, fiecare introducând tipuri diferite de nelinearitate care ajută rețeaua să surprindă tipare complexe și să facă predicții sofisticate.
Straturile ascunse sunt straturi intermediare între stratul de intrare și cel de ieșire, unde rețeaua realizează cea mai mare parte a procesării computaționale. Aceste straturi extrag și transformă caracteristici din datele brute de intrare în reprezentări din ce în ce mai abstracte. Adâncimea și lățimea straturilor ascunse determină capacitatea rețelei de a învăța tipare complexe. Rețelele mai adânci, cu mai multe straturi ascunse, pot surprinde relații sofisticate în date, dar necesită mai multe resurse computaționale și antrenament atent pentru a evita supraînvățarea.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Arhitectura Transformer este un design de rețea neuronală care utilizează mecanisme de autoatenție pentru a procesa date secvențiale în paralel. Ea alimentează ...

Află cum identifică, extrag și înțeleg sistemele AI relațiile dintre entități în text. Descoperă tehnici de extracție a relațiilor dintre entități, metode NLP ș...
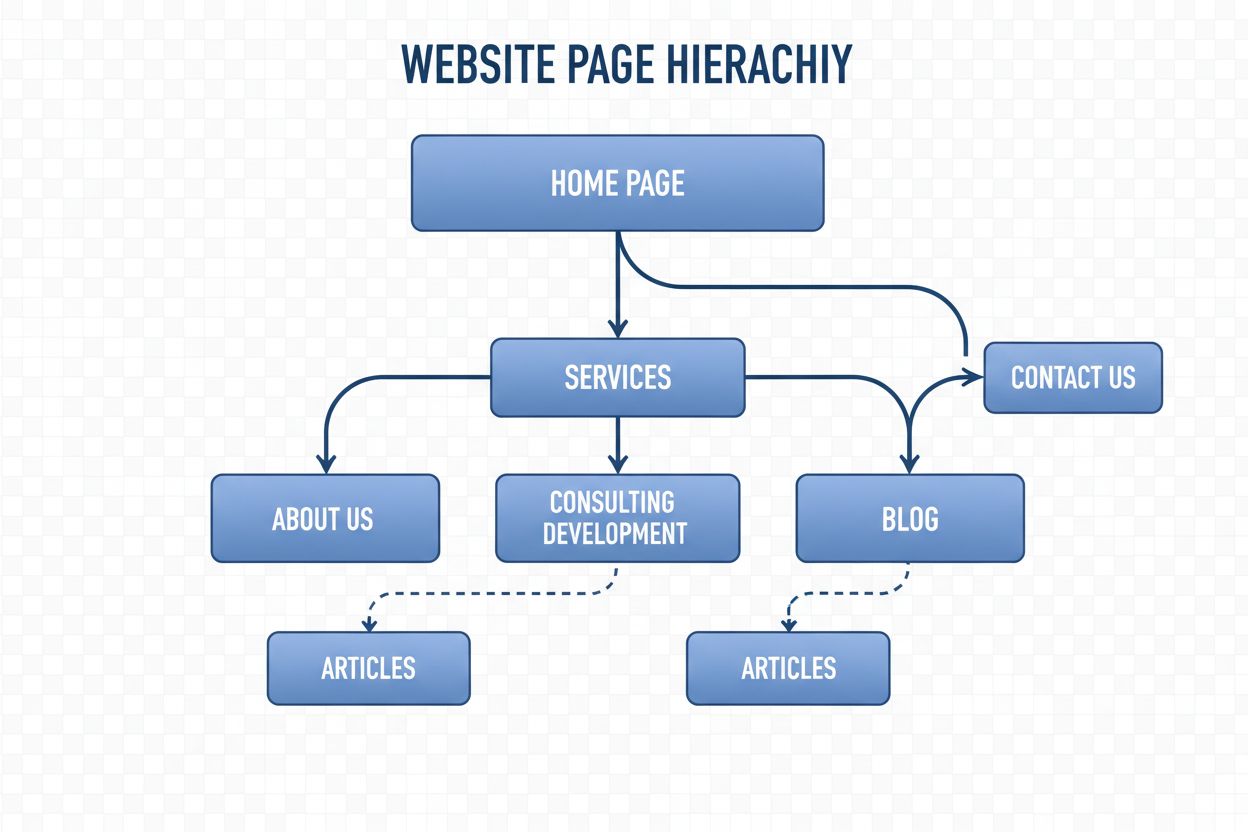
Structura de navigare este sistemul care organizează paginile și linkurile unui site web pentru a ghida utilizatorii și roboții AI. Află cum influențează SEO, e...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.