
Ce este meta tag-ul noai și cum îți protejează conținutul de AI?
Află despre meta tag-ul noai, cum funcționează pentru a preveni colectarea datelor pentru antrenarea AI, care sunt limitările sale și cum să îl implementezi pe ...
7 min citire

Un meta tag HTML care semnalează sistemelor de antrenare AI și crawler-elor web că conținutul site-ului nu trebuie folosit pentru antrenarea modelelor de învățare automată. Inițial introdus de DeviantArt, acesta servește ca mecanism de protecție a conținutului și semnal de opt-out pentru creatorii preocupați de colectarea neautorizată a datelor pentru AI.
Un meta tag HTML care semnalează sistemelor de antrenare AI și crawler-elor web că conținutul site-ului nu trebuie folosit pentru antrenarea modelelor de învățare automată. Inițial introdus de DeviantArt, acesta servește ca mecanism de protecție a conținutului și semnal de opt-out pentru creatorii preocupați de colectarea neautorizată a datelor pentru AI.
Tag-ul meta NoAI este un mecanism de protecție a conținutului implementat ca un meta tag HTML care semnalează sistemelor de antrenare AI și crawler-elor web că conținutul unui site nu trebuie folosit pentru antrenarea modelelor de învățare automată. Inițial introdus de DeviantArt în septembrie 2022, directiva NoAI a apărut ca un răspuns din partea comunității la îngrijorările privind folosirea fără consimțământ sau compensație a operelor artiștilor pentru antrenarea modelelor AI generative. Meta tag-ul funcționează prin adăugarea unei simple declarații HTML în antetul unei pagini web, comunicând clar sistemelor AI că acel conținut nu este permis pentru antrenare. Deși nu are valoare juridică în majoritatea jurisdicțiilor, tag-ul NoAI reprezintă un important mecanism de opt-out pentru creatorii care doresc să își protejeze proprietatea intelectuală într-o eră a colectării agresive de date pentru AI.
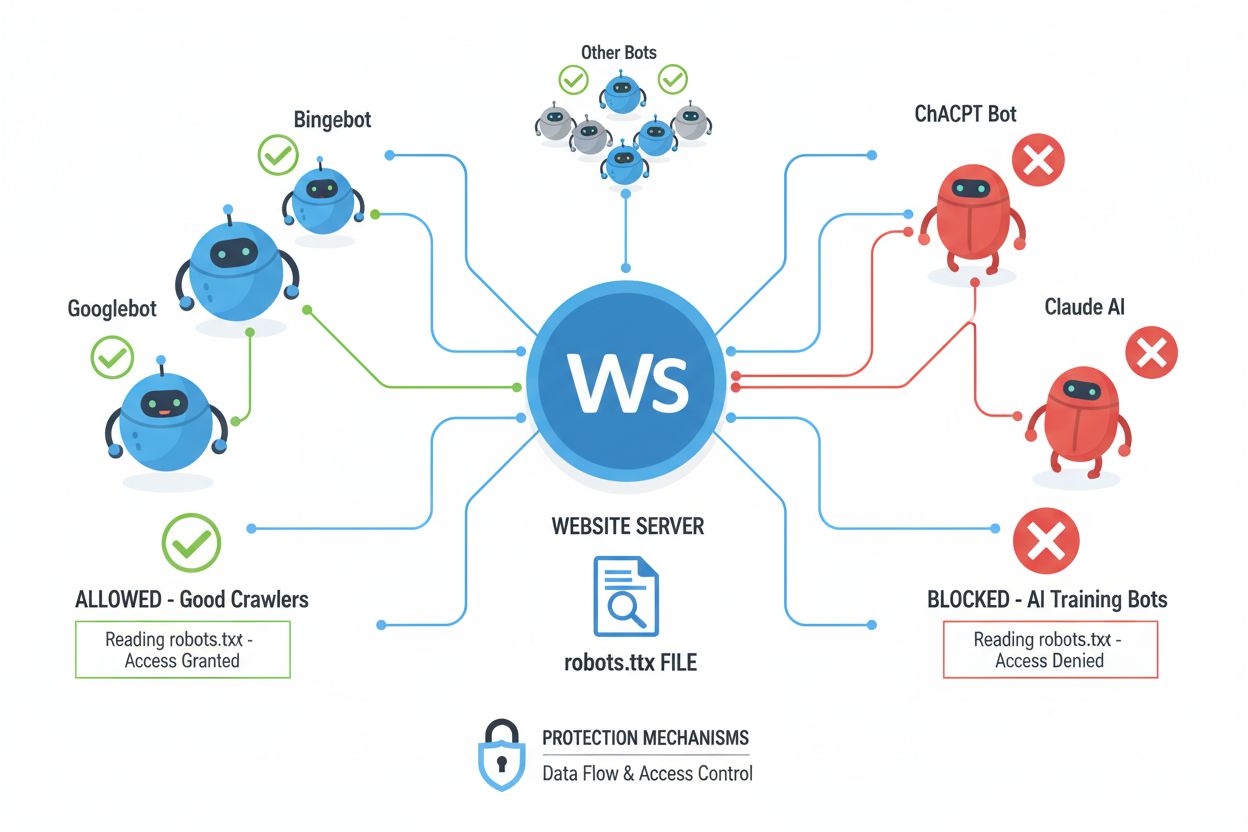
Crawlerele web (numite și boți, păianjeni sau scrapers) sunt programe software automatizate care navighează sistematic pe internet, urmărind linkuri și descărcând conținut pentru a-l indexa, analiza sau colecta în diverse scopuri. Aceste crawlere funcționează citind fișierul robots.txt aflat în directorul rădăcină al site-ului, care conține instrucțiuni despre ce zone ale site-ului pot sau nu pot fi accesate de vizitatori automatizați. Fișierul robots.txt folosește directive precum User-agent, Disallow și Allow pentru a comunica permisiuni, însă respectarea lor este complet voluntară și depinde dacă dezvoltatorul crawler-ului alege să țină cont de aceste indicații. Pe lângă robots.txt, site-urile pot comunica preferințe și prin headere HTTP și meta tag-uri, care oferă semnale suplimentare despre drepturile și restricțiile de utilizare a conținutului. Diferite tipuri de crawlere respectă aceste semnale în grade variate:
| Tip Crawler | Respectare robots.txt | Respectare Meta Tag | Folosire la Antrenare AI |
|---|---|---|---|
| Motoare de căutare | Ridicată | Ridicată | Limitată |
| Boți Antrenare AI | Medie | Medie | Da |
| Scraper-e Comerciale | Scăzută | Scăzută | Varibilă |
| Boți Academici | Ridicată | Medie | Doar Cercetare |
| Boți Malicioși | Niciuna | Niciuna | Fără Restricții |
Directivele noai și noimageai au scopuri similare, dar distincte în protecția conținutului, diferența cheie fiind domeniul și specificitatea. Directiva noai este un semnal mai larg, indicând că tot conținutul unei pagini—inclusiv text, imagini, cod și alte medii—nu trebuie folosit pentru antrenarea AI, fiind potrivită pentru site-uri cu conținut mixt sau care doresc protecție completă. Directiva noimageai, în schimb, vizează specific doar conținutul de tip imagine, permițând ca textul și alte materiale non-imagine să fie folosite la antrenare, dar protejând activele vizuale de modelele AI generative. Această distincție este importantă pentru site-urile ce doresc să permită indexarea textului de către AI (pentru motoare de căutare sau accesibilitate), dar să protejeze imaginile de folosirea în modele generative. Iată diferențele de implementare:
<!-- Protecție cuprinzătoare pentru tot conținutul -->
<meta name="robots" content="noai">
<!-- Protecție specifică doar pentru imagini -->
<meta name="robots" content="noimageai">
<!-- Abordare combinată pentru claritate maximă -->
<meta name="robots" content="noai, noimageai">
Tag-ul meta NoAI poate fi implementat prin mai multe metode, fiecare cu avantaje diferite în funcție de infrastructura tehnică și nevoile specifice. Cea mai simplă abordare este adăugarea meta tag-ului direct în secțiunea <head> a HTML-ului, aplicând directiva fiecărei pagini și putând fi personalizat individual. Pentru site-urile cu multe pagini sau cele care doresc o soluție generală, implementarea directivei prin headere HTTP oferă o abordare mai scalabilă ce se aplică uniform pe tot conținutul, fără modificări individuale. De asemenea, fișierul robots.txt poate include directive dedicate unor crawlere AI specifice, deși această metodă este mai puțin standardizată decât meta tag-urile sau headerele. Iată cele trei metode principale de implementare:
<!-- Metoda 1: Meta tag HTML (cea mai comună) -->
<head>
<meta name="robots" content="noai">
</head>
# Metoda 2: directivă robots.txt
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metoda 3: Header HTTP (prin .htaccess sau configurare server)
X-Robots-Tag: noai
Pentru servere Apache, adaugă în .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Pentru servere Nginx, adaugă în blocul de server:
add_header X-Robots-Tag "noai" always;
Deși tag-ul meta NoAI reprezintă un pas important spre protecția conținutului, el funcționează pe baza unui sistem de bună credință ce depinde complet de alegerea dezvoltatorilor AI și a scraper-elor de a respecta semnalul. Marile companii AI precum OpenAI, Google și Anthropic au început să respecte directivele NoAI în crawlerele lor, însă actorii rău intenționați și scraper-ele neautorizate ignoră frecvent aceste semnale, făcând tag-ul ineficient împotriva hoților determinați de date. Eficiența NoAI este limitată și de faptul că previne doar antrenarea viitoare pe conținut; nu poate elimina date deja colectate și folosite în modele existente și nici nu oferă protecție legală în caz de încălcare. Rata de conformare variază semnificativ între sistemele AI, unele respectând directiva, altele ignorând-o deliberat, ceea ce face din NoAI o soluție utilă, dar incompletă. Tag-ul nu oferă niciun fel de protecție împotriva descărcării directe, capturilor de ecran sau copierii manuale a conținutului și nu poate preveni folosirea de către competitori ce ignoră directiva. Din aceste motive, NoAI trebuie privit ca un strat dintr-o strategie mai largă de protecție a conținutului, nu ca o soluție completă.
Tag-ul meta NoAI a fost adoptat semnificativ de companii și platforme AI majore, cu OpenAI, Google și Stability AI angajându-se public să respecte directiva în procesele lor de antrenare. Implementarea de către DeviantArt a NoAI a influențat discuțiile din industrie despre dezvoltarea etică a AI și consimțământul creatorilor, ducând la o conștientizare crescută atât în rândul dezvoltatorilor AI, cât și al creatorilor de conținut. Totuși, adoptarea rămâne inconstantă în industrie, companiile AI mai mici, cercetătorii academici și scraper-ele comerciale având niveluri variabile de conformare. Apariția unor standarde precum C2PA (Coalition for Content Provenance and Authenticity) și discuțiile privind drepturile interpretate de mașini sugerează că industria se îndreaptă spre mecanisme de protecție mai sofisticate și cu acoperire legală, dincolo de meta tag-urile voluntare. Organizațiile de industrie și organismele de standardizare lucrează activ la formalizarea acestor protecții, cu așteptarea ca viitoarele reglementări AI să impună respectarea explicită a preferințelor creatorilor, ceea ce ar transforma NoAI dintr-un semnal voluntar într-o cerință legală.
Implementarea protecției NoAI trebuie să facă parte dintr-o abordare stratificată a securității conținutului, combinând strategii tehnice, legale și de monitorizare pentru protecție cuprinzătoare. Pentru eficiență maximă, ia în considerare aceste bune practici:
De asemenea, realizează audituri regulate ale implementării protecției conținutului pentru a te asigura că toate paginile includ directivele corespunzătoare și folosește instrumente automate pentru a scana apariția conținutului tău în seturi de date AI și depozite de antrenament. Documentează implementarea NoAI ca parte a politicii de guvernanță a conținutului și comunică aceste protecții audienței tale pentru a crește încrederea, mai ales dacă găzduiești conținut generat de utilizatori.
Directiva noai protejează toate tipurile de conținut (text, imagini, cod) de antrenarea AI, în timp ce noimageai protejează specific doar conținutul de tip imagine. Folosește noai pentru protecție cuprinzătoare și noimageai atunci când dorești să permiți indexarea textului, dar să protejezi elementele vizuale de modelele generative de imagini.
Nu, meta tag-ul NoAI funcționează pe bază de bună credință și depinde dacă dezvoltatorii AI aleg să îl respecte. Companii mari precum OpenAI și Google îl respectă, însă actorii rău intenționați și scraping-urile neautorizate ignoră frecvent aceste semnale, făcându-l doar un strat de protecție, nu o soluție completă.
Îl poți implementa în trei moduri: adăugând meta tag-ul HTML în antetul paginii, setând headerele HTTP la nivel de server sau incluzând directive în fișierul robots.txt. Metoda cu meta tag HTML este cea mai comună și directă pentru majoritatea proprietarilor de site-uri.
Companii AI majore, inclusiv OpenAI (ChatGPT), Google, Anthropic (Claude) și Stability AI s-au angajat public să respecte directivele NoAI în procesele lor de antrenare. Totuși, gradul de conformare variază la companiile AI mai mici, cercetătorii academici și scraper-ii comerciali.
Da, le poți folosi simultan pentru eficiență maximă. Meta tag-ul NoAI și directivele robots.txt funcționează împreună pentru a comunica preferințele tale de protecție a conținutului către diferite tipuri de crawlere și sisteme.
Combină NoAI cu alte metode de protecție, inclusiv headere HTTP, reguli robots.txt, watermarking, controale de acces și termeni legali de utilizare. Monitorizează-ți conținutul în seturi de date AI și ia în considerare folosirea unor instrumente pentru a urmări utilizarea neautorizată.
Deși este adoptat pe scară largă de companiile AI majore, NoAI nu este încă un standard W3C formal. Totuși, organizații din industrie lucrează la standarde mai sofisticate precum C2PA și expresii de drepturi interpretate de mașini, care ar putea oferi în viitor susținere legală.
NoAI este cel mai eficient când este combinat cu alte metode precum robots.txt, headere HTTP, watermarking, controale de acces și protecții legale. Nicio metodă individuală nu oferă protecție completă, așa că este recomandată o abordare stratificată pentru siguranța cuprinzătoare a conținutului.
Urmărește ce sisteme AI citează brandul și conținutul tău cu platforma de monitorizare AI de la AmICited. Știi exact cum este folosită munca ta de ChatGPT, Perplexity, Google AI Overviews și alte sisteme AI.
Află despre meta tag-ul noai, cum funcționează pentru a preveni colectarea datelor pentru antrenarea AI, care sunt limitările sale și cum să îl implementezi pe ...
Discuție în comunitate despre meta tag-ul noai și dacă acesta protejează eficient conținutul de antrenarea AI. Utilizatorii împărtășesc experiențe și limitele a...
Descoperă cum au evoluat meta tag-urile pentru căutarea bazată pe AI. Află care meta tag-uri contează cel mai mult pentru optimizarea AI, vizibilitatea în AI Ov...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.