
Generare augmentată prin recuperare (RAG)
Află ce este Generarea Augmentată prin Recuperare (RAG), cum funcționează și de ce este esențială pentru răspunsuri AI precise. Explorează arhitectura, benefici...
12 min citire

O pipeline de Generare Augmentată prin Recuperare (RAG) este un flux de lucru care permite sistemelor AI să găsească, să claseze și să citeze surse externe atunci când generează răspunsuri. Combină recuperarea de documente, clasificarea semantică și generarea LLM pentru a furniza răspunsuri exacte, relevante contextual, bazate pe date reale. Sistemele RAG reduc halucinațiile consultând baze de cunoștințe externe înainte de a produce răspunsuri, făcându-le esențiale pentru aplicațiile ce necesită acuratețe factuală și atribuirea sursei.
O pipeline de Generare Augmentată prin Recuperare (RAG) este un flux de lucru care permite sistemelor AI să găsească, să claseze și să citeze surse externe atunci când generează răspunsuri. Combină recuperarea de documente, clasificarea semantică și generarea LLM pentru a furniza răspunsuri exacte, relevante contextual, bazate pe date reale. Sistemele RAG reduc halucinațiile consultând baze de cunoștințe externe înainte de a produce răspunsuri, făcându-le esențiale pentru aplicațiile ce necesită acuratețe factuală și atribuirea sursei.
Un pipeline de Generare Augmentată prin Recuperare (RAG) este o arhitectură AI care combină recuperarea informațiilor cu generarea de modele lingvistice mari (LLM) pentru a produce răspunsuri mai exacte, relevante contextual și verificabile. În loc să se bazeze exclusiv pe datele de antrenament ale unui LLM, sistemele RAG preiau dinamic documente sau date relevante din baze de cunoștințe externe înainte de a genera răspunsuri, reducând semnificativ halucinațiile și îmbunătățind acuratețea factuală. Pipeline-ul acționează ca o punte între datele statice de antrenament și informațiile în timp real, permițând sistemelor AI să facă referire la conținut actual, specific domeniului sau proprietar. Această abordare a devenit esențială pentru organizațiile ce necesită răspunsuri cu citare, conformitate cu standardele de acuratețe și transparență în conținutul AI generat. Pipeline-urile RAG sunt deosebit de valoroase în monitorizarea sistemelor AI unde trasabilitatea și atribuirea sursei sunt cerințe critice.
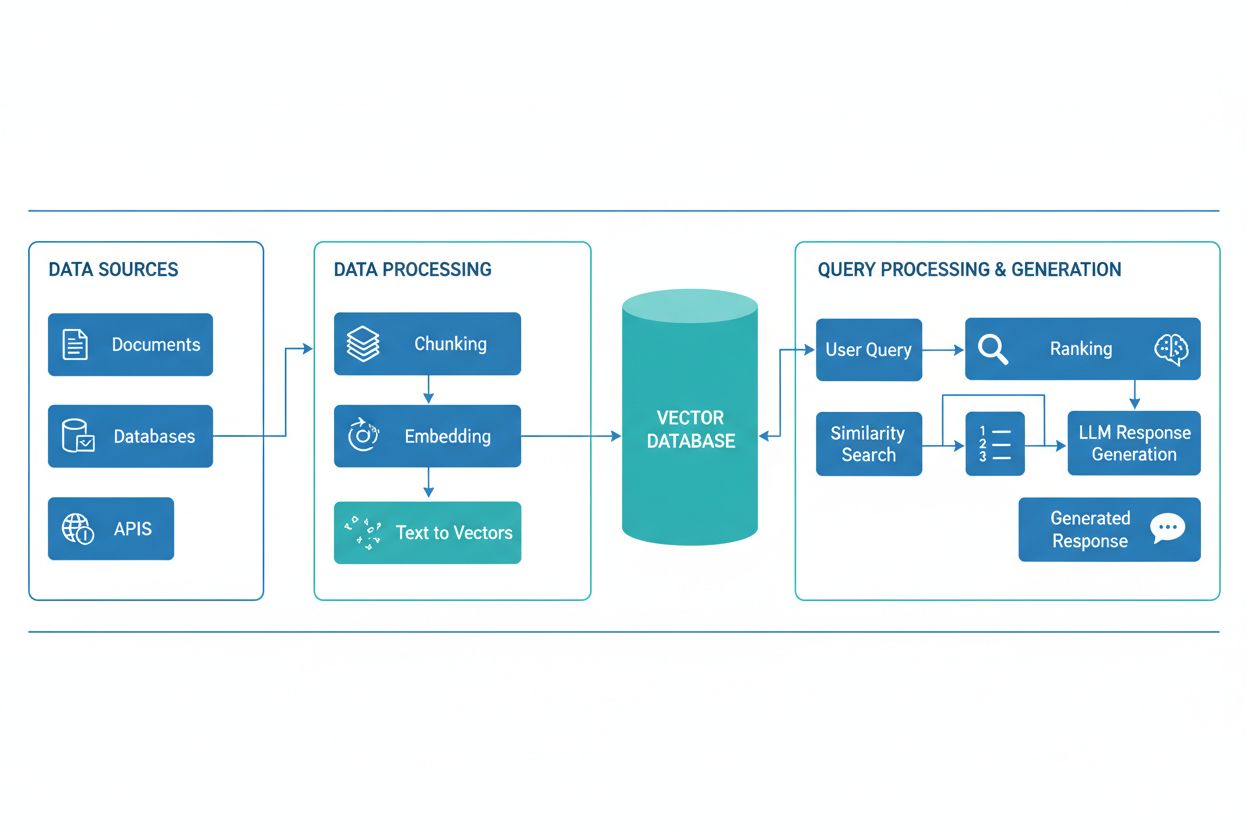
Un pipeline RAG constă din mai multe componente interconectate care lucrează împreună pentru a recupera informații relevante și a genera răspunsuri fundamentate. Arhitectura include de obicei un strat de ingestie a documentelor care procesează și pregătește datele brute, o bază de date vectorială sau bază de cunoștințe ce stochează embedding-uri și conținut indexat, un mecanism de recuperare ce identifică documentele relevante pe baza interogărilor utilizatorului, un sistem de clasificare care prioritizează cele mai relevante rezultate și un modul de generare alimentat de un LLM care sintetizează informațiile recuperate în răspunsuri coerente. Componente suplimentare includ module de procesare și preprocesare a interogărilor care normalizează inputul utilizatorului, modele de embedding care convertesc textul în reprezentări numerice și un circuit de feedback ce îmbunătățește continuu acuratețea recuperării. Orchestrarea acestor componente determină eficacitatea și eficiența generală a sistemului RAG.
| Componentă | Funcție | Tehnologii cheie |
|---|---|---|
| Ingestie Documente | Procesarea și pregătirea datelor brute | Apache Kafka, LangChain, Unstructured |
| Bază de date vectorială | Stocarea embedding-urilor și conținutului indexat | Pinecone, Weaviate, Milvus, Qdrant |
| Motor de recuperare | Identificarea documentelor relevante | BM25, Dense Passage Retrieval (DPR) |
| Sistem de clasificare | Prioritizarea rezultatelor căutării | Cross-encoders, reranking bazat pe LLM |
| Modul de generare | Sinteza răspunsurilor din context | GPT-4, Claude, Llama, Mistral |
| Procesor de interogări | Normalizarea și înțelegerea inputului utilizatorului | BERT, T5, pipeline-uri NLP custom |
Pipeline-ul RAG funcționează prin două faze distincte: faza de recuperare și faza de generare. În faza de recuperare, sistemul convertește interogarea utilizatorului într-un embedding folosind același model de embedding care a procesat documentele bazei de cunoștințe, apoi caută în baza de date vectorială pentru a identifica cele mai asemănătoare semantic documente sau pasaje. Această fază returnează de obicei o listă ordonată de documente candidate, care poate fi rafinată suplimentar prin algoritmi de reranking ce folosesc cross-encoders sau scorare bazată pe LLM pentru a asigura relevanța. În faza de generare, cele mai bine clasate documente recuperate sunt formate într-o fereastră de context și transmise LLM-ului împreună cu interogarea originală, permițând modelului să genereze răspunsuri fundamentate pe surse reale. Această abordare în două faze asigură că răspunsurile sunt atât potrivite contextului, cât și trasabile la surse specifice, fiind ideală pentru aplicații ce necesită citare și responsabilitate. Calitatea rezultatului final depinde critic atât de relevanța documentelor recuperate cât și de capacitatea LLM-ului de a sintetiza coerent informația.
Ecosistemul RAG cuprinde o gamă diversă de instrumente și cadre specializate menite să simplifice construcția și implementarea pipeline-urilor. Implementările moderne RAG folosesc mai multe categorii de tehnologii:
Aceste instrumente pot fi combinate modular, permițând organizațiilor să construiască sisteme RAG adaptate cerințelor și constrângerilor lor de infrastructură.
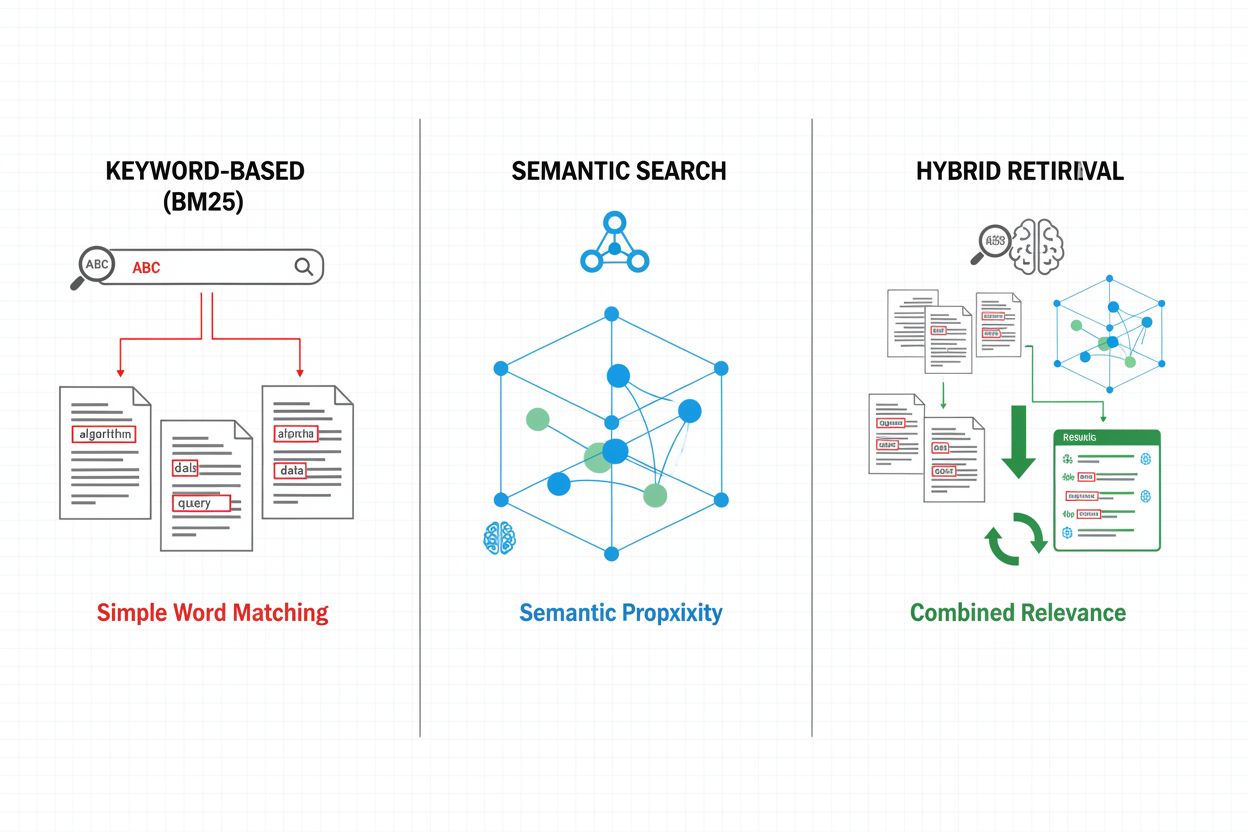
Mecanismele de recuperare formează fundația eficacității pipeline-ului RAG, evoluând de la abordări simple bazate pe cuvinte cheie la metode sofisticate de căutare semantică. Recuperarea tradițională bazată pe cuvinte cheie folosind algoritmi BM25 rămâne eficientă computațional și eficace pentru scenarii de potrivire exactă, dar întâmpină dificultăți la înțelegerea semantică și sinonimie. Dense Passage Retrieval (DPR) și alte metode de recuperare neuronală abordează aceste limitări prin codarea atât a interogărilor, cât și a documentelor în embedding-uri vectoriale dense, permițând potrivirea semantică ce surprinde sensul dincolo de cuvintele cheie. Abordările hibride de recuperare combină căutarea bazată pe cuvinte cheie cu cea semantică, valorificând punctele forte ale ambelor metode pentru a îmbunătăți atât recall-ul cât și precizia pentru diverse tipuri de interogări. Mecanismele avansate de recuperare includ expansiunea interogării, unde interogarea originală este extinsă cu termeni înrudiți sau reformulări pentru a acoperi mai multe documente relevante. Straturile de reranking rafinează suplimentar rezultatele prin aplicarea unor modele mai costisitoare computațional ce punctează documentele candidate pe baza unei înțelegeri semantice profunde sau a unor criterii de relevanță specifice sarcinii. Alegerea mecanismului de recuperare influențează semnificativ atât acuratețea contextului recuperat, cât și costul computațional al pipeline-ului RAG, necesitând o analiză atentă a compromisurilor între viteză și calitate.
Pipeline-urile RAG oferă avantaje substanțiale față de abordările tradiționale bazate doar pe LLM, în special pentru aplicații ce necesită acuratețe, actualitate și trasabilitate. Prin fundamentarea răspunsurilor în documente recuperate, sistemele RAG reduc dramatic halucinațiile—situații în care LLM-urile generează informații plauzibile, dar incorecte factual—făcându-le adecvate domeniilor cu miză ridicată precum sănătatea, juridicul și serviciile financiare. Capacitatea de a face referire la baze de cunoștințe externe permite sistemelor RAG să ofere informații actualizate fără reantrenarea modelelor, permițând organizațiilor să mențină răspunsuri la zi pe măsură ce apar informații noi. Pipeline-urile RAG suportă personalizare pe domeniu prin încorporarea documentelor proprietare, bazelor interne de cunoștințe și terminologiei specializate, generând răspunsuri mai relevante și adecvate contextului. Componenta de recuperare oferă transparență și auditabilitate prin indicarea explicită a surselor care au stat la baza fiecărui răspuns, esențial pentru cerințele de conformitate și încrederea utilizatorilor. Eficiența costurilor crește prin utilizarea unor LLM-uri mai mici și eficiente, care pot genera răspunsuri de calitate când primesc context relevant, reducând supraîncărcarea computațională comparativ cu modelele mari. Aceste beneficii fac RAG deosebit de valoros pentru organizațiile care implementează sisteme de monitorizare AI unde acuratețea citărilor și vizibilitatea conținutului sunt prioritare.
În ciuda avantajelor, pipeline-urile RAG se confruntă cu mai multe provocări tehnice și operaționale ce necesită gestionare atentă. Calitatea documentelor recuperate determină direct calitatea răspunsurilor, făcând erorile de recuperare dificil de corectat—un fenomen cunoscut drept „garbage in, garbage out”, unde documentele irelevante sau învechite din baza de cunoștințe se propagă până în răspunsurile finale. Modelele de embedding pot întâmpina dificultăți cu terminologia specifică domeniului, limbile rare sau conținutul foarte tehnic, ducând la potrivire semantică slabă și omisiuni de documente relevante. Costul computațional al recuperării, generării embedding-urilor și reranking-ului poate fi substanțial la scară, în special când se procesează baze de cunoștințe mari sau volume ridicate de interogări. Limitările ferestrei de context a LLM-urilor restricționează volumul de informație recuperată ce poate fi inclusă în prompturi, necesitând selecția atentă și sumarizarea pasajelor relevante. Menținerea actualității și consistenței bazei de cunoștințe prezintă provocări operaționale, mai ales în medii dinamice unde informațiile se schimbă frecvent sau provin din surse multiple. Evaluarea performanței sistemului RAG necesită metrici cuprinzătoare dincolo de acuratețea tradițională, incluzând precizia recuperării, relevanța răspunsurilor și corectitudinea citărilor, aspecte dificil de evaluat automat.
RAG reprezintă o abordare între mai multe strategii de îmbunătățire a acurateței și relevanței LLM, fiecare având compromisuri specifice. Fine-tuning presupune reantrenarea LLM-ului pe date specifice domeniului, oferind personalizare profundă, dar necesitând resurse computaționale substanțiale, date etichetate și întreținere continuă pe măsură ce informațiile se schimbă. Prompt engineering optimizează instrucțiunile și contextul oferit LLM-urilor fără a modifica greutățile modelului, oferind flexibilitate și cost redus, dar fiind limitat de datele de antrenament și dimensiunea ferestrei de context. Învățarea in-context valorifică exemple few-shot în prompturi pentru a ghida comportamentul modelului, asigurând adaptare rapidă, dar consumând tokeni valoroși de context și necesitând selecție atentă a exemplelor. Comparativ cu aceste abordări, RAG oferă o cale de mijloc: acces dinamic la informații actuale fără reantrenare, transparență prin atribuirea explicită a surselor și scalare eficientă pe domenii de cunoștințe diverse. Totuși, RAG introduce complexitate suplimentară prin infrastructura de recuperare și potențiale erori de recuperare, pe când fine-tuning asigură integrare strânsă a cunoștințelor de domeniu în comportamentul modelului. Soluția optimă implică adesea combinarea mai multor strategii—de exemplu, folosirea RAG cu modele fine-tunate și prompturi atent proiectate—pentru maximizarea acurateței și relevanței pentru cazuri de utilizare specifice.
Implementarea unui pipeline RAG de producție necesită planificare sistematică în ceea ce privește pregătirea datelor, proiectarea arhitecturii și considerentele operaționale. Procesul începe cu pregătirea bazei de cunoștințe: colectarea documentelor relevante, curățarea și standardizarea formatelor și fragmentarea conținutului în pasaje de dimensiuni potrivite care să echilibreze păstrarea contextului cu precizia recuperării. Urmează selecția modelelor de embedding și a bazelor de date vectoriale pe baza cerințelor de performanță, constrângerilor de latență și nevoilor de scalare, luând în calcul factori ca dimensiunea embedding-urilor, debitul interogărilor și capacitatea de stocare. Sistemul de recuperare este apoi configurat, incluzând decizii despre algoritmii de recuperare (pe cuvinte cheie, semantică sau hibrid), strategiile de reranking și criteriile de filtrare a rezultatelor. Integrarea cu furnizorii de LLM urmează, stabilind conexiuni cu modelele de generare și definind template-uri de prompturi care să incorporeze eficient contextul recuperat. Testarea și evaluarea sunt critice, necesitând metrici pentru calitatea recuperării (precizie, recall, MRR), calitatea generării (relevanță, coerență, factualitate) și performanța sistemului end-to-end. Considerentele de implementare includ setarea monitorizării pentru acuratețea recuperării și calitatea generării, implementarea circuitelor de feedback pentru identificarea și remedierea modurilor de eșec și stabilirea proceselor de actualizare și mentenanță a bazei de cunoștințe. În final, optimizarea continuă presupune analiza interacțiunilor utilizatorilor, identificarea tiparelor comune de eșec și îmbunătățirea iterativă a mecanismelor de recuperare, strategiilor de reranking și a prompt engineering-ului pentru creșterea performanței generale a sistemului.
Pipeline-urile RAG sunt fundamentale pentru platformele moderne de monitorizare AI precum AmICited.com, unde urmărirea surselor și acurateței conținutului generat de AI este esențială. Prin recuperarea și citarea explicită a documentelor sursă, sistemele RAG creează o pistă auditată care permite platformelor de monitorizare să verifice afirmațiile, să evalueze acuratețea factuală și să identifice potențiale halucinații sau atribuiri greșite. Această capacitate de citare abordează un gol critic în transparența AI: utilizatorii și auditorii pot urmări răspunsurile până la sursele originale, permițând verificarea independentă și construind încredere în conținutul AI generat. Pentru creatorii de conținut și organizațiile ce folosesc instrumente AI, monitorizarea bazată pe RAG oferă vizibilitate asupra surselor ce au stat la baza anumitor răspunsuri, susținând conformitatea cu cerințele de atribuire și politicile de guvernanță a conținutului. Componenta de recuperare a pipeline-urilor RAG generează metadate bogate—inclusiv scoruri de relevanță, clasamente ale documentelor și metrici de încredere în recuperare—ce pot fi analizate de sistemele de monitorizare pentru a evalua fiabilitatea răspunsurilor și a identifica când sistemele AI operează în afara domeniilor lor de cunoștințe. Integrarea RAG cu platformele de monitorizare permite detectarea driftului de citare, când sistemele AI se îndepărtează treptat de surse autoritare către unele mai puțin fiabile, și susține aplicarea politicilor de conținut privind calitatea și diversitatea surselor. Pe măsură ce sistemele AI devin tot mai integrate în fluxuri de lucru critice, combinația dintre pipeline-urile RAG și monitorizarea cuprinzătoare creează mecanisme de responsabilitate ce protejează utilizatorii, organizațiile și ecosistemul informațional mai larg de dezinformarea generată de AI.
RAG și fine-tuning sunt abordări complementare pentru îmbunătățirea performanței LLM. RAG recuperează documente externe la momentul interogării fără a modifica modelul, permițând acces la date în timp real și actualizări ușoare. Fine-tuning reantrenează modelul pe date specifice domeniului, oferind personalizare profundă, dar necesitând resurse computaționale semnificative și actualizări manuale când informațiile se schimbă. Multe organizații folosesc ambele tehnici împreună pentru rezultate optime.
RAG reduce halucinațiile prin ancorarea răspunsurilor LLM în documente factuale recuperate. În loc să se bazeze doar pe datele de antrenament, sistemul recuperează surse relevante înainte de generare, oferind modelului dovezi concrete de referință. Această abordare asigură că răspunsurile sunt bazate pe informații reale, nu doar pe tipare învățate de model, îmbunătățind semnificativ acuratețea factuală și reducând afirmațiile false sau înșelătoare.
Embedding-urile vectoriale sunt reprezentări numerice ale textului ce surprind semnificația semantică într-un spațiu multi-dimensional. Ele permit sistemelor RAG să facă căutări semantice, găsind documente cu sens similar chiar dacă folosesc cuvinte diferite. Embedding-urile sunt cruciale deoarece permit RAG să depășească potrivirea pe cuvinte cheie și să înțeleagă relațiile conceptuale, crescând relevanța recuperării și permițând generarea unor răspunsuri mai exacte.
Da, pipeline-urile RAG pot încorpora date în timp real prin procese continue de ingestie și indexare. Organizațiile pot implementa pipeline-uri automatizate care actualizează regulat baza de date vectorială cu documente noi, asigurând actualitatea bazei de cunoștințe. Această capacitate face RAG ideal pentru aplicații ce necesită informații la zi, precum analiza de știri, inteligență de prețuri sau monitorizarea pieței, fără a fi nevoie de reantrenarea modelului LLM.
Căutarea semantică este o tehnică de recuperare ce găsește documente pe baza similarității de sens folosind embedding-uri vectoriale. RAG este un pipeline complet ce combină căutarea semantică cu generarea LLM pentru a produce răspunsuri bazate pe documente recuperate. În timp ce căutarea semantică se concentrează pe găsirea informațiilor relevante, RAG adaugă componenta de generare care sintetizează conținutul într-un răspuns coerent cu citate.
Sistemele RAG folosesc multiple mecanisme pentru a selecta sursele citate. Folosesc algoritmi de recuperare pentru a găsi documente relevante, modele de reranking pentru a prioritiza rezultatele cele mai relevante și procese de verificare pentru a se asigura că citatele susțin afirmațiile făcute. Unele sisteme aplică abordări „cite-while-writing”, unde afirmațiile sunt făcute doar dacă sunt susținute de surse recuperate, iar altele verifică citatele după generare și elimină afirmațiile nesusținute.
Provocările cheie includ menținerea actualității și calității bazei de cunoștințe, optimizarea acurateței recuperării pentru conținuturi diverse, gestionarea costurilor computaționale la scară, gestionarea terminologiei de nișă pe care modelele de embedding pot să nu o înțeleagă bine și evaluarea performanței sistemului cu metrici cuprinzătoare. Organizațiile trebuie să abordeze și limitările ferestrei de context a LLM-urilor și să asigure relevanța documentelor recuperate pe măsură ce informațiile evoluează.
AmICited urmărește modul în care sistemele AI precum ChatGPT, Perplexity și Google AI Overviews recuperează și citează conținutul prin pipeline-uri RAG. Platforma monitorizează ce surse sunt selectate pentru citare, cât de des apare brandul tău în răspunsurile AI și dacă citatele sunt corecte. Această vizibilitate ajută organizațiile să înțeleagă prezența lor în căutarea mediată de AI și să asigure atribuirea corectă a conținutului lor.
Urmărește cum sistemele AI precum ChatGPT, Perplexity și Google AI Overviews fac referire la conținutul tău. Obține vizibilitate asupra citărilor RAG și monitorizării răspunsurilor AI.
Află ce este Generarea Augmentată prin Recuperare (RAG), cum funcționează și de ce este esențială pentru răspunsuri AI precise. Explorează arhitectura, benefici...

Află ce este RAG (Retrieval-Augmented Generation) în căutarea AI. Descoperă cum RAG îmbunătățește acuratețea, reduce halucinațiile și alimentează ChatGPT, Perpl...
Află cum RAG combină LLM-urile cu surse externe de date pentru a genera răspunsuri AI precise. Înțelege procesul în cinci etape, componentele și de ce contează ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.