
Licențierea conținutului pentru AI
Află despre acordurile de licențiere a conținutului AI care guvernează modul în care sistemele de inteligență artificială folosesc conținut protejat prin dreptu...
9 min citire
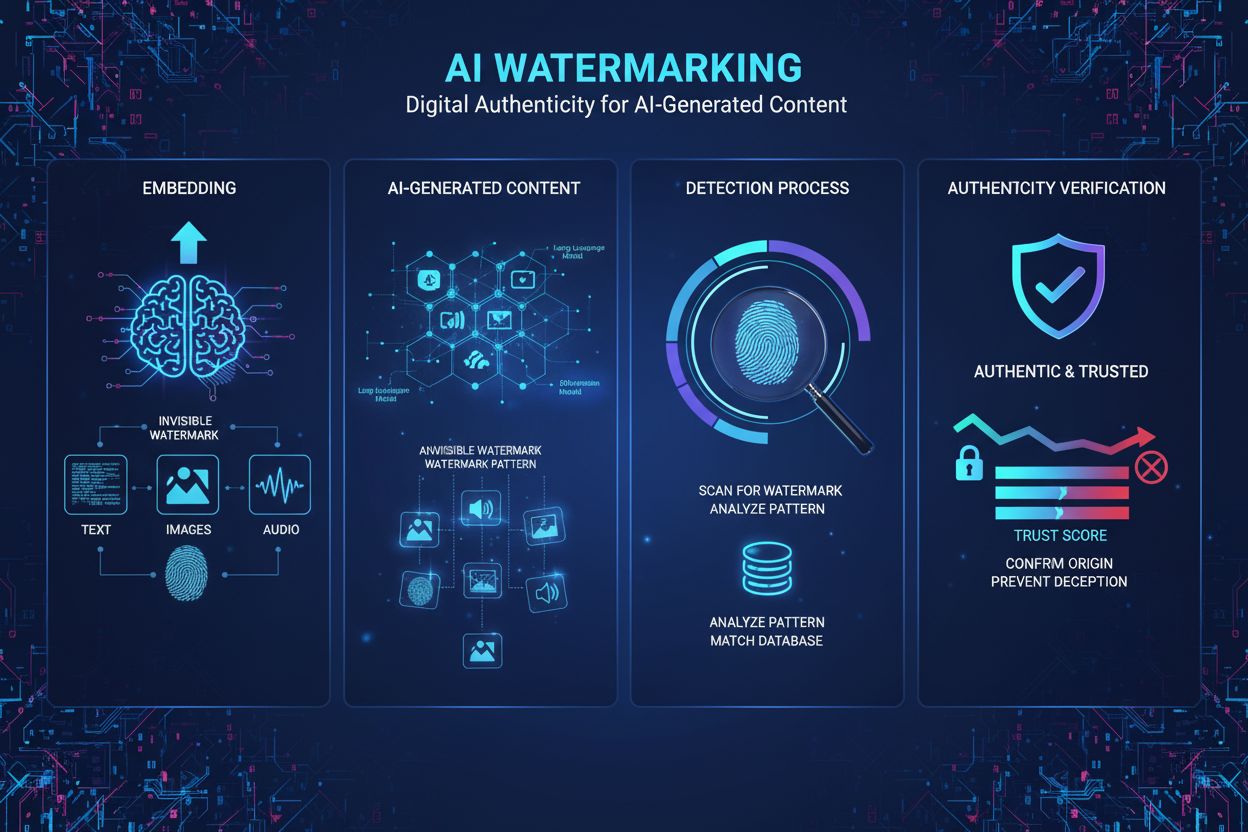
Marcarea conținutului AI este procesul de încorporare a unor markeri digitali invizibili sau vizibili în text, imagini, audio sau video generate de AI, pentru a identifica și autentifica acel conținut ca fiind generat de o mașină. Aceste marcaje servesc drept amprente digitale care permit detectarea, verificarea și urmărirea materialului generat de AI pe diverse platforme și aplicații.
Marcarea conținutului AI este procesul de încorporare a unor markeri digitali invizibili sau vizibili în text, imagini, audio sau video generate de AI, pentru a identifica și autentifica acel conținut ca fiind generat de o mașină. Aceste marcaje servesc drept amprente digitale care permit detectarea, verificarea și urmărirea materialului generat de AI pe diverse platforme și aplicații.
Marcarea conținutului AI se referă la procesul de încorporare a unor markeri, modele sau semnături digitale în materialul generat de AI pentru a-i identifica, autentifica și urmări originea. Aceste marcaje funcționează ca amprente digitale care disting conținutul generat de mașini de cel creat de oameni, indiferent dacă este vorba de text, imagini, audio sau video. Scopul principal al marcării conținutului AI este să ofere transparență privind proveniența conținutului, să combată dezinformarea, să protejeze proprietatea intelectuală și să asigure responsabilitatea în peisajul în continuă expansiune al inteligenței artificiale generative. Spre deosebire de marcajele tradiționale vizibile de pe documente sau imagini fizice, tehnicile moderne de marcare AI utilizează frecvent modele invizibile detectabile doar prin algoritmi specializați, menținând calitatea conținutului și oferind capabilități robuste de autentificare.
Conceptul de marcare își are originea în lumea fizică, unde semnele invizibile de pe bancnote și documente serveau ca măsuri anti-falsificare. Odată cu proliferarea mediilor digitale, cercetătorii au adaptat tehnici de marcare pentru imagini, audio și video de-a lungul anilor 1990 și 2000. Totuși, apariția unor modele AI generative sofisticate precum ChatGPT, DALL-E și Midjourney în 2022-2023 a creat o nevoie urgentă de metode standardizate pentru autentificarea conținutului AI. Progresul rapid al capacităților AI, care generează conținut sintetic din ce în ce mai realist, a determinat guvernele, companiile de tehnologie și organizațiile societății civile să prioritizeze marcarea ca măsură de protecție esențială. Potrivit cercetărilor instituției Brookings, peste 78% dintre întreprinderi recunosc importanța instrumentelor de monitorizare a conținutului generat de AI pentru gestionarea riscurilor asociate media sintetice. Legea AI a UE, adoptată oficial în martie 2024, a devenit primul cadru de reglementare major care impune marcarea conținutului AI, cerând furnizorilor de sisteme AI să își marcheze rezultatele ca fiind generate de AI. Această tendință de reglementare a accelerat cercetarea și dezvoltarea tehnologiilor de marcare, companii precum Google DeepMind, OpenAI și Meta investind semnificativ în soluții robuste de marcare.
Marcarea AI funcționează prin două abordări tehnice principale: marcarea vizibilă și marcarea invizibilă. Marcajele vizibile includ etichete evidente, logouri sau indicatori text adăugați conținutului—precum cele cinci pătrate colorate pe care DALL-E le plasează pe imaginile generate sau preambulul ChatGPT „ca model lingvistic antrenat de OpenAI”. Deși sunt simple de implementat, marcajele vizibile sunt extrem de ușor de eliminat prin editări de bază. Marcarea invizibilă, în schimb, încorporează modele subtile invizibile percepției umane, dar detectabile algoritmic. Pentru imaginile generate de AI, tehnici precum marcajele „tree-ring” dezvoltate la Universitatea Maryland inserează modele în zgomotul inițial înainte de procesul de difuzie, făcându-le rezistente la decupare, rotire și filtrare. Pentru textul generat de AI, marcarea statistică reprezintă abordarea cea mai promițătoare, modelul lingvistic favorizând subtil anumiți tokeni („tokeni verzi”) și evitând alții („tokeni roșii”) în funcție de context. Aceasta creează o aranjare statistic neobișnuită a cuvintelor, identificabilă cu mare încredere de algoritmii de detecție. Marcarea audio inserează modele imperceptibile în frecvențe dincolo de auzul uman (sub 20 Hz sau peste 20.000 Hz), similar cu marcarea imaginilor dar adaptată proprietăților acustice. Tehnologia SynthID de la Google DeepMind exemplifică marcarea modernă, antrenând simultan modele de generare și detecție pentru a asigura robustețe la transformări, menținând totodată calitatea conținutului.
| Metoda de marcare | Tip de conținut | Robustețe | Impact asupra calității | Necesită acces la model | Detectabilitate |
|---|---|---|---|---|---|
| Marcare vizibilă | Imagini, Video | Foarte scăzută | Niciuna | Nu | Mare (uman) |
| Marcare statistică | Text, Imagini | Ridicată | Minimal | Da | Mare (algoritmic) |
| Bazată pe învățare automată | Imagini, Audio | Ridicată | Minimal | Da | Mare (algoritmic) |
| Marcare „tree-ring” | Imagini | Foarte ridicată | Niciuna | Da | Mare (algoritmic) |
| Proveniență (C2PA) | Toate mediile | Medie | Niciuna | Nu | Medie (metadate) |
| Detectare post-hoc | Toate mediile | Scăzută | N/A | Nu | Scăzută (nesigură) |
Marcarea statistică este cea mai viabilă tehnică pentru autentificarea textului generat de AI, abordând provocarea unică a lipsei unui spațiu dimensional, comparabil cu cel din imagini sau audio, pentru inserarea de modele. În timpul generării, modelul lingvistic primește instrucțiuni să favorizeze anumiți tokeni pe baza unei chei criptografice cunoscută doar de dezvoltator. Aleatorietatea modelului este „încărcată” conform acestei scheme, determinând selecția preferențială a anumitor cuvinte sau expresii și evitarea altora. Protocoalele de detecție analizează textul generat și calculează probabilitatea de apariție a modelelor de tokeni detectate doar prin hazard; modelele statistic improbabile indică prezența unui marcaj. Cercetările Universității Maryland și OpenAI au demonstrat că această metodă poate atinge acuratețe ridicată a detecției menținând totodată calitatea textului. Totuși, marcarea statistică pentru text are limitări inerente: răspunsurile factuale cu flexibilitate redusă (de exemplu, soluții matematice sau fapte istorice) sunt mai greu de marcat eficient, iar rescrierea sau traducerea pot reduce semnificativ încrederea detecției. Implementarea SynthID Text, disponibilă în Hugging Face Transformers v4.46.0+, permite marcarea la nivel de producție folosind parametri configurabili precum chei criptografice și lungimea n-gramelor pentru echilibrarea robusteții și detectabilității.
Imaginile generate de AI beneficiază de abordări de marcare mai sofisticate datorită spațiului dimensional ridicat pentru inserarea de modele. Marcarea „tree-ring” inserează modele ascunse în imaginea inițială aleatorie înainte de difuzie, creând marcaje ce rezistă la decupare, estompare și rotire fără a afecta calitatea. Marcarea bazată pe învățare automată de la Meta și Google folosește rețele neuronale pentru a insera și detecta marcaje invizibile, atingând o acuratețe de peste 96% pe imagini nemodificate și rămânând rezistentă la atacuri la nivel de pixeli. Marcarea audio se bazează pe aceleași principii, inserând modele invizibile în frecvențe dincolo de percepția umană. AudioSeal, dezvoltat de Meta, antrenează simultan modele de generator și detector pentru a crea marcaje robuste la transformări naturale ale audio-ului, menținând în același timp o calitate audio indistinctă de original. Tehnologia folosește loss perceptual pentru ca sunetul marcat să fie identic cu cel original și loss de localizare pentru detectarea marcajului indiferent de perturbări. Aceste abordări demonstrează că marcarea invizibilă poate atinge robustețe și păstrarea calității când este implementată corect, deși necesită acces la modelul AI pentru inserarea marcajului.
Mediul de reglementare pentru marcarea conținutului AI a evoluat rapid, mai multe jurisdicții implementând sau propunând cerințe obligatorii de marcare. Legea AI a UE, adoptată oficial în martie 2024, reprezintă cel mai cuprinzător cadru legal, impunând furnizorilor de sisteme AI să marcheze ieșirea ca fiind conținut generat de AI. Această reglementare se aplică tuturor sistemelor AI generative implementate în Uniunea Europeană, stabilind o obligație legală de conformitate cu marcarea. Legea californiană privind transparența AI (SB 942), aplicabilă de la 1 ianuarie 2026, obligă furnizorii de AI acoperiți să pună la dispoziție gratuit instrumente publice pentru detectarea conținutului AI, necesitând astfel marcarea sau mecanisme echivalente de autentificare. Legea americană privind autorizarea apărării naționale (NDAA) pentru anul fiscal 2024 include prevederi pentru un concurs de premii pentru evaluarea tehnologiei de marcare și cere Departamentului Apărării să studieze și să piloteze implementarea „standardelor tehnice deschise din industrie” pentru încorporarea informațiilor de proveniență în metadate. Ordinul executiv al Casei Albe privind AI mandatează Departamentul Comerțului să identifice și să dezvolte standarde pentru etichetarea conținutului generat de AI. Aceste inițiative reflectă consensul crescând că marcarea AI este esențială pentru transparență, responsabilitate și protecția consumatorului. Totuși, implementarea rămâne o provocare, în special în contextul modelelor open-source, al coordonării internaționale și al fezabilității tehnice a unor standarde universale de marcare.
În ciuda progresului tehnic semnificativ, marcarea AI se confruntă cu limitări majore care îi restrâng eficiența practică. Eliminarea marcajului rămâne posibilă prin diverse tehnici de evitare: parafrazarea textului, decuparea sau filtrarea imaginilor, traducerea în alte limbi sau aplicarea de perturbări adversariale. Cercetările Universității Duke au demonstrat atacuri proof-of-concept împotriva detectorilor de marcaje bazate pe învățare automată, indicând vulnerabilitatea chiar și a abordărilor sofisticate în fața adversarilor determinați. Problema non-universalității reprezintă o altă limitare critică—detectorii sunt specifici fiecărui model, ceea ce înseamnă că utilizatorii trebuie să apeleze separat la serviciile de detecție ale fiecărei companii AI pentru a verifica originea conținutului. Fără un registru centralizat și protocoale standardizate, verificarea dacă un conținut este generat de AI devine un proces ineficient și ad-hoc. Ratele de fals pozitiv în detecția marcajului, în special pentru text, sunt încă problematice; algoritmii pot semnala eronat conținutul uman ca fiind generat de AI sau pot rata conținutul marcat după modificări minore. Compatibilitatea cu modelele open-source generează probleme de guvernanță, deoarece marcajele pot fi dezactivate la descărcarea modelului. Degradarea calității apare atunci când algoritmii de marcare constrâng artificial rezultatele modelului pentru a insera modele detectabile, reducând potențial calitatea sau flexibilitatea generării pentru sarcini factuale sau constrânse. Implicațiile privind confidențialitatea marcării—mai ales dacă aceasta include informații de identificare a utilizatorului—necesită politici atente. De asemenea, încrederea în detecție scade semnificativ odată cu lungimea conținutului; textele scurte sau conținutul puternic modificat conduc la o detecție mai puțin sigură, limitând utilitatea marcării în anumite aplicații.
Viitorul marcării AI depinde de inovare tehnică continuă, armonizare legislativă și stabilirea unei infrastructuri de încredere pentru detecția și verificarea marcajelor. Cercetătorii explorează marcaje public detectabile care să rămână robuste chiar și cu metodele de detecție dezvăluite, permițând verificare descentralizată fără a depinde de terți de încredere. Standardizarea prin organizații ca ICANN sau consorții industriale ar putea stabili protocoale universale de marcare, reducând fragmentarea și permițând detecție eficientă cross-platform. Integrarea cu standarde de proveniență precum C2PA ar putea crea abordări stratificate, combinând marcajele cu urmărirea provenienței bazate pe metadate. Dezvoltarea de marcaje robuste la traducere și parafrazare rămâne un domeniu activ de cercetare, cu potențial pentru autentificarea conținutului multilingv. Sistemele de verificare bazate pe blockchain ar putea oferi înregistrări imuabile ale detecției marcajului și provenienței conținutului, sporind încrederea în rezultate. Pe măsură ce capabilitățile AI generative evoluează, tehnicile de marcare trebuie să se adapteze pentru a rămâne eficiente în fața tentativelor sofisticate de evitare. Impulsul legislativ dat de Legea AI a UE și legislația Californiei va conduce probabil la adoptarea globală a standardelor de marcare, creând stimulente de piață pentru soluții tehnice robuste. Totuși, așteptările realiste recunosc că marcarea va gestiona în principal conținutul generat de modele comerciale populare, rămânând limitată în scenarii cu miză mare ce necesită detecție imediată. Integrarea platformelor de monitorizare a conținutului AI precum AmICited cu infrastructura de marcare va permite organizațiilor să urmărească atribuirea brandului pe sisteme AI, asigurând recunoașterea corectă a domeniilor în răspunsurile generate de AI. Dezvoltările viitoare vor pune accent pe colaborarea om-AI în autentificarea conținutului, combinând detecția automată a marcajelor cu verificarea umană pentru aplicații critice în jurnalism, justiție și integritatea academică.
Marcajele vizibile sunt ușor de detectat de către oameni, cum ar fi logouri sau etichete text adăugate pe imagini sau clipuri audio, dar sunt simple de eliminat sau falsificat. Marcajele invizibile încorporează modele subtile, imperceptibile percepției umane, dar detectabile de algoritmi specializați, ceea ce le face mult mai robuste împotriva manipulării și tentativelor de eliminare. Marcajele invizibile sunt în general preferate pentru autentificarea conținutului AI deoarece mențin calitatea conținutului oferind în același timp o securitate mai puternică împotriva evitării detectării.
Marcarea statistică pentru text funcționează prin influențarea subtilă a selecției de tokeni a modelului lingvistic în timpul generării. Dezvoltatorul modelului 'încarcă zarurile' folosind o schemă criptografică, determinând modelul să favorizeze anumiți 'tokeni verzi' și să evite 'tokenii roșii' în funcție de contextul anterior. Algoritmii de detecție analizează apoi textul pentru a identifica dacă tokenii favorizați apar cu o frecvență statistic neobișnuită, indicând prezența unui marcaj. Această abordare păstrează calitatea textului în timp ce încorporează o amprentă detectabilă.
Provocările cheie includ ușurința eliminării marcajului prin editări sau transformări minore, lipsa unei detecții universale între diferite modele AI și dificultatea marcării textului comparativ cu imagini sau audio. În plus, marcarea necesită cooperarea dezvoltatorilor de modele AI, este incompatibilă cu lansările de modele open-source și poate degrada calitatea conținutului dacă nu este implementată cu atenție. Ratele de fals pozitiv și fals negativ în detecție rămân de asemenea obstacole tehnice semnificative.
Legea privind AI a UE, adoptată oficial în martie 2024, impune furnizorilor de sisteme AI să marcheze ieșirea ca fiind conținut generat de AI. Legea privind transparența AI din California (SB 942), cu efect de la 1 ianuarie 2026, impune ca furnizorii de AI acoperiți să pună la dispoziție gratuit instrumente publice de detectare a conținutului. Legea americană privind autorizarea apărării naționale (NDAA) pentru anul fiscal 2024 include prevederi pentru evaluarea tehnologiei de marcare și dezvoltarea de standarde industriale pentru proveniența conținutului.
Marcarea încorporează modele de identificare direct în conținutul generat de AI, creând o amprentă digitală permanentă care persistă chiar dacă conținutul este copiat sau modificat. Proveniența conținutului, precum standardul C2PA, stochează separat metadate despre originea și istoricul modificărilor conținutului. Marcarea este mai robustă la evitarea detectării, dar necesită cooperarea dezvoltatorului modelului, în timp ce proveniența este mai ușor de implementat, dar poate fi eliminată prin copierea conținutului fără metadate.
SynthID este tehnologia Google DeepMind care marchează și identifică conținutul generat de AI prin încorporarea directă a marcajelor digitale în imagini, audio, text și video. Pentru text, SynthID utilizează un procesor de logit care extinde fluxul de generare al modelului pentru a codifica informația de marcare fără a afecta semnificativ calitatea. Tehnologia folosește modele de învățare automată atât pentru încorporarea, cât și pentru detectarea marcajelor, ceea ce o face rezistentă la atacuri comune, menținând fidelitatea conținutului.
Da, actorii motivați pot elimina sau ocoli marcajele prin diverse tehnici, inclusiv parafrazarea textului, decuparea sau filtrarea imaginilor sau traducerea conținutului în alte limbi. Totuși, eliminarea marcajelor sofisticate necesită expertiză tehnică și cunoașterea schemei de marcare. Marcajele statistice sunt mai robuste decât abordările tradiționale, dar cercetările au demonstrat atacuri de tip proof-of-concept chiar și împotriva metodelor avansate de marcare, ceea ce indică faptul că nicio tehnică de marcare nu este complet infailibilă.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Află despre acordurile de licențiere a conținutului AI care guvernează modul în care sistemele de inteligență artificială folosesc conținut protejat prin dreptu...

Află ce este detecția conținutului AI, cum funcționează instrumentele de detecție folosind învățarea automată și procesarea limbajului natural și de ce sunt imp...
Află ce este Marcajul de Entitate AI, cum ajută sistemele AI să înțeleagă și să citeze conținutul tău și cele mai bune practici pentru implementarea datelor str...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.