Kompletný zoznam AI crawlerov v roku 2025: Každý bot, ktorý by ste mali poznať
Komplexný sprievodca AI crawlermi v roku 2025. Identifikujte GPTBot, ClaudeBot, PerplexityBot a viac ako 20 ďalších AI botov. Naučte sa blokovať, povoľovať alebo monitorovať crawleri pomocou robots.txt a pokročilých techník.
Publikované dňa Jan 3, 2026.Naposledy upravené dňa Jan 3, 2026 o 3:24 am
AI crawleri sú automatizovaní boti navrhnutí na systematické prehliadanie a zber dát z webových stránok, no ich účel sa v posledných rokoch zásadne zmenil. Kým tradičné vyhľadávacie crawleri ako Googlebot sa zameriavali na indexovanie obsahu pre výsledky vyhľadávania, moderné AI crawleri dávajú prednosť zberu tréningových dát pre veľké jazykové modely a generatívne AI systémy. Podľa nedávnych údajov od Playwire tvoria AI crawleri približne 80 % všetkej AI bot návštevnosti, čo predstavuje dramatický nárast objemu a rozmanitosti automatizovaných návštevníkov webov. Tento posun odzrkadľuje širšiu transformáciu vo vývoji a trénovaní AI systémov, ktoré sa odkláňajú od verejne dostupných datasetov k zberu obsahu v reálnom čase z webu. Porozumenie týmto crawlerom sa stalo nevyhnutným pre vlastníkov webov, vydavateľov a tvorcov obsahu, ktorí potrebujú robiť informované rozhodnutia o svojej digitálnej prezentácii.
Tri kategórie AI crawlerov
AI crawleri sa dajú rozdeliť do troch odlišných kategórií podľa ich funkcie, správania a vplyvu na váš web. Tréningové crawleri predstavujú najväčší segment, tvoria približne 80 % AI bot trafficu, a sú určené na zber obsahu pre tréning strojového učenia; tieto crawleri zvyčajne operujú vo veľkých objemoch a s minimálnou návštevnosťou späť, čím sú náročné na šírku pásma, ale nevedú návštevníkov späť na váš web. Vyhľadávacie a citačné crawleri fungujú v stredných objemoch a sú špeciálne navrhnuté na vyhľadávanie a odkazovanie na obsah vo výsledkoch AI vyhľadávania a aplikáciách; na rozdiel od tréningových crawlerov môžu tieto boti skutočne posielať návštevnosť na váš web, ak užívatelia kliknú na AI-generované odpovede. Crawleri na požiadanie (User-Triggered Fetchers) predstavujú najmenšiu kategóriu a pracujú na požiadanie, keď používatelia explicitne vyžadujú načítanie obsahu cez AI aplikácie ako prehliadanie v ChatGPT; tieto crawleri majú nízky objem, ale vysokú relevanciu pre individuálne dopyty užívateľov.
Kategória
Účel
Príklady
Tréningové crawleri
Zber dát pre tréning AI modelov
GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider
Vyhľadávacie/citačné crawleri
Vyhľadávanie a odkazovanie na obsah v AI odpovediach
OpenAI prevádzkuje najrozmanitejší a najagresívnejší ekosystém crawlerov v oblasti AI s viacerými botmi slúžiacimi rôznym účelom naprieč ich produktmi. GPTBot je ich hlavný tréningový crawler, ktorý zbiera obsah na zlepšenie GPT-4 a budúcich modelov a podľa údajov Cloudflare zaznamenal ohromujúci 305 % nárast crawler trafficu; tento bot má 400:1 pomer crawl:referral, čo znamená, že stiahne obsah 400-krát na každého návštevníka, ktorého pošle späť na váš web. OAI-SearchBot plní úplne inú úlohu – zameriava sa na vyhľadávanie a citovanie obsahu pre vyhľadávaciu funkciu ChatGPT bez použitia obsahu na tréning modelu. ChatGPT-User predstavuje najvýraznejší rast, s pozoruhodným 2 825 % nárastom trafficu, a pracuje vždy, keď užívatelia zapnú funkciu „Prehliadať s Bingom“ na získanie aktuálneho obsahu na požiadanie. Tieto crawleri identifikujete podľa user-agent reťazcov: GPTBot/1.0, OAI-SearchBot/1.0, a ChatGPT-User/1.0, a OpenAI poskytuje metódy IP verifikácie na potvrdenie legitímnosti crawler trafficu z ich infraštruktúry.
AI crawleri Anthropic a Google
Anthropic, spoločnosť za Claude, prevádzkuje jeden z najselektívnejších, ale najintenzívnejších crawlerov v odvetví. ClaudeBot je ich hlavný tréningový crawler a funguje s mimoriadnym 38 000:1 pomerom crawl:referral, teda s oveľa agresívnejším sťahovaním obsahu než boty od OpenAI v pomere k poslanej návštevnosti; tento extrémny pomer odráža dôraz Anthropic na komplexný zber dát pre tréning modelov. Claude-Web a Claude-SearchBot plnia rôzne úlohy, prvý obsluhuje načítanie obsahu na požiadanie užívateľmi a druhý sa sústreďuje na vyhľadávanie a citovanie. Google prispôsobil svoju crawler stratégiu pre AI éru zavedením Google-Extended, špeciálneho tokenu umožňujúceho webom zapojiť sa do tréningu AI a pritom blokovať tradičné indexovanie Googlebotom, a Gemini-Deep-Research, ktorý vykonáva hĺbkové rešerše pre užívateľov AI produktov od Google. Mnohí vlastníci webov diskutujú, či blokovať Google-Extended, keďže pochádza od tej istej spoločnosti, ktorá ovláda vyhľadávaciu návštevnosť, čo robí rozhodovanie komplexnejším v porovnaní s AI crawlermi tretích strán.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon a Perplexity
Meta sa stala významným hráčom v oblasti AI crawlerov s Meta-ExternalAgent, ktorý tvorí približne 19 % AI crawler trafficu a používa sa na tréning AI modelov a funkcie naprieč Facebookom, Instagramom a WhatsAppom. Meta-WebIndexer dopĺňa jeho funkciu zameraním na indexovanie webu pre AI-poháňané odporúčania a funkcie. Apple predstavil Applebot-Extended pre podporu Apple Intelligence, svojich AI funkcií na zariadeniach, a tento crawler postupne rastie s rozširovaním AI funkcií naprieč iPhonmi, iPadmi a Macmi. Amazon prevádzkuje Amazonbot na pohon Alexa a Rufus, AI asistenta pre nakupovanie, čo je relevantné pre e-commerce weby a produktovo orientovaný obsah. PerplexityBot predstavuje jeden z najdramatickejších rastov v oblasti crawlerov, s ohromujúcim 157 490 % nárastom trafficu, čo odráža explozívny rast Perplexity AI ako alternatívy vyhľadávača; napriek tomuto masívnemu rastu stále predstavuje menší absolútny objem v porovnaní s OpenAI a Google, no trend naznačuje rýchlo rastúcu dôležitosť.
Novovznikajúce a špecializované crawleri
Okrem hlavných hráčov aktívne zbierajú dáta z webov po celom internete početné nové a špecializované AI crawleri. Bytespider od ByteDance (materská spoločnosť TikTok) zaznamenal dramatický 85 % pokles trafficu, čo naznačuje zmenu stratégie alebo nižšiu potrebu tréningových dát. Cohere, Diffbot a CCBot od Common Crawl sú špecializované crawleri zamerané na konkrétne prípady použitia – od tréningu jazykových modelov po extrakciu štruktúrovaných dát. You.com, Mistral a DuckDuckGo prevádzkujú vlastné crawleri na podporu AI-poháňaného vyhľadávania a asistenčných funkcií, čím zvyšujú komplexnosť prostredia crawlerov. Nové crawleri sa objavujú pravidelne, keď startupy aj etablované firmy spúšťajú AI produkty vyžadujúce zber webových dát. Udržiavať si prehľad o nových crawlroch je kľúčové, pretože ich blokovanie alebo povoľovanie môže zásadne ovplyvniť vašu viditeľnosť v nových AI objavovacích platformách a aplikáciách.
Ako identifikovať AI crawleri
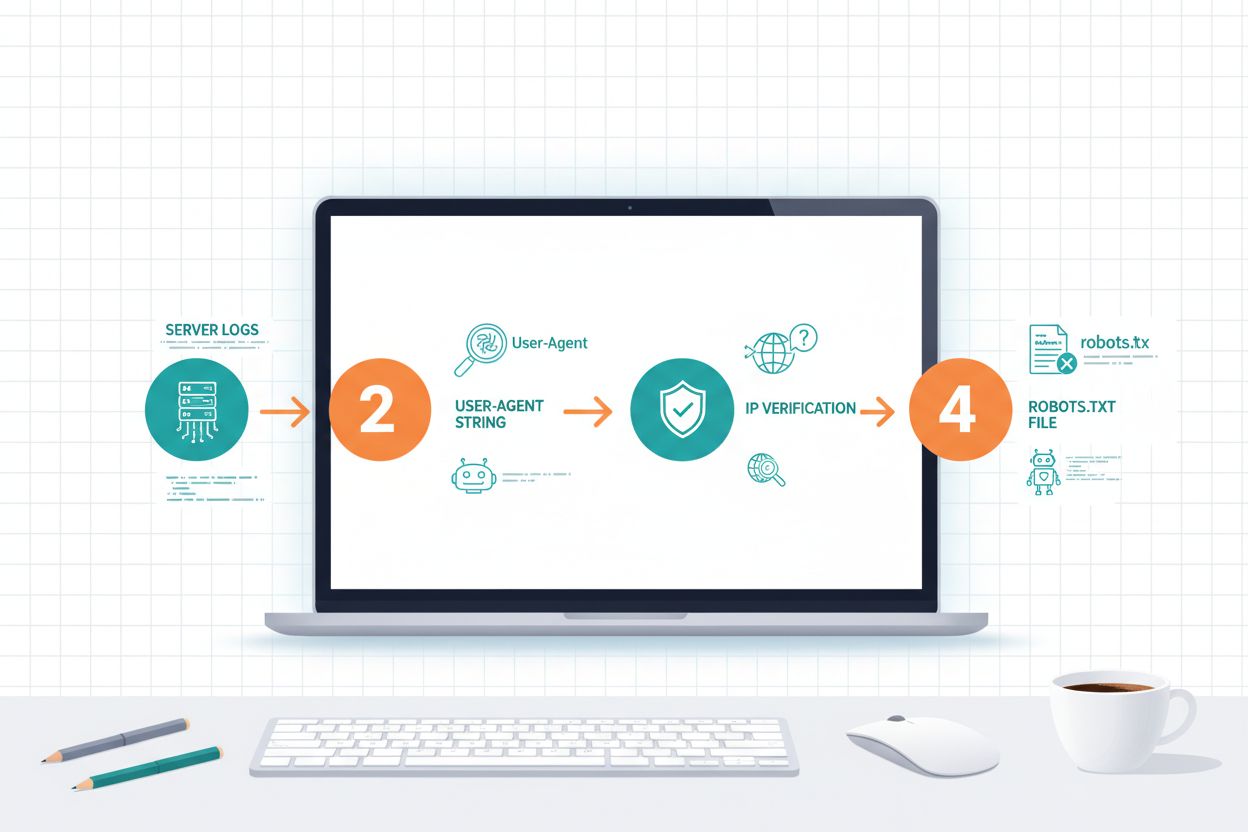
Identifikácia AI crawlerov vyžaduje pochopenie spôsobu ich označovania a analýzu vzorcov návštevnosti na vašom serveri. User-agent reťazce sú hlavným spôsobom identifikácie, keďže každý crawler sa v HTTP požiadavkách predstavuje špecifickým identifikátorom; napríklad GPTBot používa GPTBot/1.0, ClaudeBot používa Claude-Web/1.0 a PerplexityBot používa PerplexityBot/1.0. Analýza serverových logov (zvyčajne v /var/log/apache2/access.log na Linux serveroch alebo IIS logy na Windows) vám umožní vidieť, ktoré crawleri navštevujú váš web a ako často. Ďalšou dôležitou technikou je overenie IP, kde môžete overiť, že crawler, ktorý sa vydáva za OpenAI alebo Anthropic, skutočne prichádza z ich legitímnych IP rozsahov, ktoré tieto firmy zverejňujú pre bezpečnostné účely. Kontrola robots.txt súboru odhalí, ktoré crawleri ste explicitne povolili alebo blokovali, a porovnanie s reálnou návštevnosťou ukáže, či crawleri rešpektujú vaše pravidlá. Nástroje akoCloudflare Radar poskytujú prehľad o návštevnosti crawlerov v reálnom čase a pomáhajú identifikovať najaktívnejšie boty na vašom webe. Praktické kroky zahŕňajú: kontrolu analytickej platformy na bot traffic, prezeranie surových serverových logov pre vzorce user-agenta, porovnanie IP adries so zverejnenými rozsahmi crawlerov a využitie online nástrojov na overenie podozrivých zdrojov trafficu.
Kompromisy: blokovanie verzus povoľovanie
Rozhodnutie, či AI crawleri povoliť alebo blokovať, zahŕňa vyváženie viacerých obchodných aspektov bez univerzálneho riešenia. Hlavné kompromisy zahŕňajú:
Viditeľnosť v AI aplikáciách: Povolením crawlerov zabezpečíte, že váš obsah sa objaví vo výsledkoch AI vyhľadávania, objavovacích platformách a odpovediach AI asistentov, čo môže priniesť návštevnosť z nových zdrojov
Zaťaženie šírky pásma a servera: Tréningové crawleri spotrebúvajú významnú šírku pásma a serverové zdroje, niektoré weby zaznamenali 10–30 % nárast trafficu len od AI botov, čo môže zvýšiť náklady na hosting
Ochrana obsahu vs. traffic: Blokovaním crawlerov ochránite svoj obsah pred použitím na tréning AI, no vylúčite možnosť referral trafficu z AI objavovacích platforiem
Potenciál referral trafficu: Vyhľadávacie a citačné crawleri ako PerplexityBot a OAI-SearchBot môžu posielať návštevnosť späť na váš web, kým tréningové crawleri ako GPTBot a ClaudeBot spravidla nie
Konkurenčné postavenie: Konkurenti, ktorí crawleri povoľujú, môžu získať viditeľnosť v AI aplikáciách, zatiaľ čo vy zostanete neviditeľní, čo ovplyvní vaše postavenie v AI objavovaní
Keďže 80 % AI bot trafficu pochádza z tréningových crawlerov s minimálnym referral potenciálom, mnohí vydavatelia volia blokovanie tréningových crawlerov a zároveň povoľujú vyhľadávacie a citačné crawleri. Toto rozhodnutie závisí od vášho obchodného modelu, typu obsahu a strategických priorít medzi AI viditeľnosťou a spotrebou zdrojov.
Nastavenie robots.txt pre AI crawleri
robots.txt je vaším hlavným nástrojom na komunikáciu pravidiel pre crawleri, no treba si uvedomiť, že dodržiavanie je dobrovoľné a technicky nevynútiteľné. robots.txt používa user-agent matching na cielenie konkrétnych crawlerov, čo umožňuje vytvárať rôzne pravidlá pre rôzne boty; napríklad môžete blokovať GPTBot a zároveň povoľovať OAI-SearchBot alebo blokovať všetky tréningové crawleri a povoliť vyhľadávacie crawleri. Podľa výskumov má len 14 % z top 10 000 domén AI-špecifické pravidlá v robots.txt, čo znamená, že väčšina webov ešte neoptimalizovala svoju politiku pre AI crawleri. Súbor používa jednoduchú syntax, kde zadáte user-agent názov a nasledujú direktívy disallow alebo allow, pričom môžete použiť wildcardy na zacielenie viacerých crawlerov s podobnými názvami.
Tu sú tri praktické scenáre konfigurácie robots.txt:
Pamätajte, že robots.txt je len odporúčanie a škodlivé alebo nevyhovujúce crawleri môžu vaše direktívy úplne ignorovať. User-agent matching nerozlišuje veľké a malé písmená, teda gptbot, GPTBot a GPTBOT označujú rovnaký crawler a použitím User-agent: * vytvoríte pravidlá platné pre všetkých crawlerov.
Pokročilé metódy ochrany
Okrem robots.txt poskytuje silnejšiu ochranu proti nechceným AI crawlerom niekoľko pokročilých metód, každá s inou účinnosťou a zložitosťou implementácie. Overenie IP a firewall pravidlá umožňujú blokovať traffic z konkrétnych IP rozsahov pridelených AI crawlerom; tieto rozsahy získate z dokumentácie prevádzkovateľov crawlerov a nakonfigurujete firewall alebo Web Application Firewall (WAF) na odmietnutie požiadaviek z týchto IP, pričom je nutná pravidelná údržba, keďže IP sa menia. Blokovanie na úrovni servera cez .htaccess ponúka ochranu pre Apache server cez kontrolu user-agent reťazcov a IP adries pred poskytnutím obsahu, čo je spoľahlivejšie ako robots.txt, lebo funguje priamo na úrovni servera a nespolieha sa na „slušnosť“ crawlerov.
Tu je praktický príklad .htaccess pre pokročilé blokovanie crawlerov:
# Blokovať AI tréningové crawleri na úrovni servera<IfModulemod_rewrite.c> RewriteEngine On# Blokovanie podľa user-agent reťazca RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blokovanie podľa IP adresy (ukážkové IP – nahraďte skutočnými IP crawlerov) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Povoliť konkrétne crawleri pri blokovaní ostatných RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># Prístup cez HTML meta tag (pridať do hlavičky stránky)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
HTML meta tagy ako <meta name="robots" content="noarchive"> a <meta name="googlebot" content="noindex"> poskytujú kontrolu na úrovni stránky, sú však menej spoľahlivé ako blokovanie na úrovni servera, keďže crawleri musia HTML najprv spracovať, aby ich videli. Treba dodať, že IP spoofing je technicky možný, teda sofistikovaní aktéri môžu predstierať legitímne IP crawlerov, preto kombinácia viacerých metód poskytuje lepšiu ochranu než spoliehanie sa na jediný prístup. Každá metóda má iné výhody: robots.txt je jednoduchý na implementáciu, no nevymáhateľný, blokovanie IP je spoľahlivé, ale vyžaduje údržbu, .htaccess poskytuje serverovú vynútiteľnosť a meta tagy ponúkajú granuralitu na úrovni stránky.
Monitorovanie a overovanie
Zavedenie pravidiel pre crawleri je len polovica úspechu; musíte aktívne monitorovať, či crawleri vaše direktívy rešpektujú a prispôsobovať stratégiu podľa reálnych vzorcov trafficu. Serverové logy sú vaším hlavným zdrojom dát, zvyčajne v /var/log/apache2/access.log na Linux serveroch alebo v priečinku IIS logs na Windows serveroch, kde môžete vyhľadávať konkrétne user-agent reťazce a zistiť, ktoré crawleri a ako často navštevujú váš web. Analytické platformy ako Google Analytics, Matomo či Plausible možno nastaviť na samostatné sledovanie bot trafficu od ľudí, čo umožní vidieť objem a správanie rôznych crawlerov v čase. Cloudflare Radar poskytuje prehľad návštevnosti crawlerov v reálnom čase naprieč internetom a ukáže vám, ako si váš web vedie v porovnaní s priemerom odvetvia. Na overenie, že crawleri rešpektujú vaše bloky, môžete použiť online nástroje na kontrolu robots.txt, prehľadávať serverové logy na blokované user-agenty a porovnávať IP adresy s publikovanými rozsahmi crawlerov, aby ste potvrdili, že traffic skutočne pochádza z legitímnych zdrojov. Praktické monitorovacie kroky zahŕňajú: nastavenie týždennej analýzy logov na sledovanie objemu crawlerov, konfiguráciu upozornení na neobvyklú aktivitu crawlerov, mesačnú kontrolu analytického dashboardu na trendy bot trafficu a štvrťročné kontroly vašich pravidiel pre crawleri, aby ste sa uistili, že stále zodpovedajú vašim cieľom. Pravidelné monitorovanie vám pomôže identifikovať nové crawleri, zistiť porušenia politík a prijímať rozhodnutia o povolení či blokovaní na základe dát.
Budúcnosť AI crawlerov
Prostredie AI crawlerov sa rýchlo vyvíja, s novými hráčmi na trhu a existujúcimi crawlermi, ktorí rozširujú svoje schopnosti nečakaným smerom. Novovznikajúce crawleri od firiem ako xAI (Grok), Mistral a DeepSeek začínajú vo veľkom zbierať webové dáta a každá nová AI firma pravdepodobne zavedie vlastný crawler pre tréning modelov a produktové funkcie. Agentické prehliadače predstavujú novú hranicu v technológii crawlerov – systémy ako ChatGPT Operator a Comet dokážu interagovať s webmi ako ľudia, klikať na tlačidlá, vypĺňať formuláre a navigovať zložité rozhrania; tieto agenti založení na prehliadači sú ťažšie identifikovateľní a blokovateľní tradičnými metódami. Výzvou pri agentických prehliadačoch je, že sa nemusia jasne identifikovať v user-agent reťazci a môžu obchádzať IP blokovanie využitím rezidenčných proxy alebo distribuovanej infraštruktúry. Nové crawleri sa objavujú pravidelne, často bez varovania, preto je nevyhnutné sledovať vývoj v AI a flexibilne prispôsobovať politiku. Trendy naznačujú, že traffic crawlerov bude rásť, Cloudflare uvádza 18 % celkový nárast crawler trafficu od mája 2024 do mája 2025 a tento rast sa pravdepodobne zrýchli s masovým rozšírením AI aplikácií. Vlastníci webov a vydavatelia musia zostať ostražití a adaptabilní, pravidelne prehodnocovať svoje politiky a sledovať novinky, aby boli ich stratégie účinné v rýchlo sa meniacom prostredí.
Monitorovanie vašej značky v AI odpovediach
Popri správe prístupu crawlerov na váš web je rovnako dôležité pochopiť, ako je váš obsah využívaný a citovaný v AI-generovaných odpovediach. AmICited.com je špecializovaná platforma navrhnutá na riešenie tohto problému sledovaním, ako AI crawleri zbierajú váš obsah a monitorovaním, či je vaša značka a obsah správne citovaný v AI aplikáciách. Platforma vám pomôže zistiť, ktoré AI systémy využívajú váš obsah, ako často sa vaše informácie objavujú v AI odpovediach a či je poskytovaná správna atribúcia pôvodnému zdroju. Pre vydavateľov a tvorcov obsahu poskytuje AmICited.com cenné poznatky o vašej viditeľnosti v AI ekosystéme, pomáha vyhodnotiť vplyv vašich rozhodnutí o povolení či blokovaní crawlerov a pochopiť reálnu hodnotu, ktorú získavate z AI objavovania. Sledovaním citácií na viacerých AI platformách môžete robiť lepšie rozhodnutia o pravidlách pre crawleri, identifikovať príležitosti na zvýšenie viditeľnosti v AI odpovediach a zabezpečiť, že vaše duševné vlastníctvo je správne pripísané. Ak to s pochopením prítomnosti vašej značky v AI-poháňanom webe myslíte vážne, AmICited.com ponúka transparentnosť a monitoring, ktoré potrebujete na informované rozhodnutia a ochranu hodnoty vášho obsahu v novej ére AI objavovania.
Najčastejšie kladené otázky
Aký je rozdiel medzi tréningovými a vyhľadávacími crawlermi?
Tréningové crawleri ako GPTBot a ClaudeBot zbierajú obsah na vytvorenie datasetov pre vývoj veľkých jazykových modelov a stávajú sa súčasťou znalostnej bázy AI. Vyhľadávacie crawleri ako OAI-SearchBot a PerplexityBot indexujú obsah pre AI-poháňané vyhľadávacie služby a môžu posielať návštevnosť späť vydavateľom cez citácie.
Mám blokovať všetky AI crawleri alebo len tréningové crawleri?
Závisí to od vašich obchodných priorít. Blokovanie tréningových crawlerov chráni váš obsah pred zahrnutím do AI modelov. Blokovaním vyhľadávacích crawlerov môžete znížiť svoju viditeľnosť v AI-poháňaných platformách ako ChatGPT vyhľadávanie alebo Perplexity. Mnohí vydavatelia volia selektívne blokovanie, ktoré cieli na tréningové crawleri a zároveň povoľuje vyhľadávacie a citačné crawleri.
Ako overím, či je crawler legitímny alebo podvrhnutý?
Najspoľahlivejšia metóda overenia je porovnanie IP adresy požiadavky s oficiálne zverejnenými rozsahmi IP od prevádzkovateľov crawlerov. Veľké spoločnosti ako OpenAI, Anthropic a Amazon zverejňujú IP adresy svojich crawlerov. Môžete tiež použiť firewall na povolenie overených IP a blokovanie požiadaviek z neoverených zdrojov, ktoré sa vydávajú za AI crawleri.
Ovplyvní blokovanie Google-Extended moje pozície vo vyhľadávaní?
Google oficiálne uvádza, že blokovanie Google-Extended neovplyvňuje pozície vo vyhľadávaní ani zaradenie do AI Overviews. Niektorí webmasteri však hlásili obavy, preto sledujte svoj výkon vo vyhľadávaní po implementácii blokov. AI Overviews vo vyhľadávaní Google sa riadia štandardnými pravidlami pre Googlebot, nie Google-Extended.
Ako často by som mal aktualizovať svoj AI crawler blocklist?
Nové AI crawleri sa objavujú pravidelne, preto minimálne štvrťročne prehodnocujte a aktualizujte svoj blocklist. Sledujte zdroje ako projekt ai.robots.txt na GitHube pre komunitne spravované zoznamy. Každý mesiac kontrolujte serverové logy, aby ste identifikovali nové crawleri, ktoré navštevujú váš web a nie sú vo vašej aktuálnej konfigurácii.
Môžu AI crawleri ignorovať direktívy robots.txt?
Áno, robots.txt je len odporúčanie, nie vynútiteľné pravidlo. Dobre správané crawleri od veľkých spoločností zvyčajne rešpektujú direktívy robots.txt, no niektoré crawleri ich ignorujú. Pre silnejšiu ochranu implementujte blokovanie na úrovni servera cez .htaccess alebo firewall a overujte legitímnosť crawlerov pomocou zverejnených rozsahov IP adries.
Aký vplyv majú AI crawleri na šírku pásma môjho webu?
AI crawleri môžu generovať významné zaťaženie servera a spotrebu šírky pásma. Niektoré infraštruktúrne projekty uviedli, že blokovaním AI crawlerov znížili spotrebu šírky pásma z 800GB na 200GB denne, čo znamenalo úsporu približne 1 500 $ mesačne. Vysoko navštevované weby môžu selektívnym blokovaním výrazne znížiť náklady.
Ako môžem monitorovať, ktoré AI crawleri pristupujú na môj web?
Skontrolujte serverové logy (zvyčajne v /var/log/apache2/access.log na Linuxe) pre user-agent reťazce zodpovedajúce známym crawlerom. Použite analytické platformy ako Google Analytics alebo Cloudflare Radar na samostatné sledovanie bot trafficu. Nastavte upozornenia na neobvyklú aktivitu crawlerov a štvrťročne kontrolujte svoje pravidlá pre crawleri.
Sledujte svoju značku v AI odpovediach
Sledujte, ako AI platformy ako ChatGPT, Perplexity a Google AI Overviews odkazujú na váš obsah. Získajte upozornenia v reálnom čase, keď je vaša značka spomenutá v AI-generovaných odpovediach.
Ktorým AI crawlerom by ste mali povoliť prístup? Kompletný sprievodca pre rok 2025
Zistite, ktorým AI crawlerom povoliť alebo zablokovať prístup vo vašom robots.txt. Komplexný sprievodca pokrývajúci GPTBot, ClaudeBot, PerplexityBot a ďalších 2...
Kompletný sprievodca blokovaním (alebo povoľovaním) AI crawlerov
Naučte sa, ako blokovať alebo povoliť AI crawlery ako GPTBot a ClaudeBot pomocou robots.txt, serverového blokovania a pokročilých ochranných metód. Kompletný te...
Vplyv AI crawlerov na serverové zdroje: Čo očakávať
Zistite, ako AI crawlery ovplyvňujú serverové zdroje, šírku pásma a výkon. Objavte reálne štatistiky, stratégie zmiernenia a infraštruktúrne riešenia na efektív...
9 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.