Audit prístupnosti pre AI
Naučte sa, ako vykonať audit prístupnosti pre AI, aby bola vaša webstránka objaviteľná pre AI prehľadávače ako ChatGPT, Claude a Perplexity. Technický sprievodc...
9 min čítania
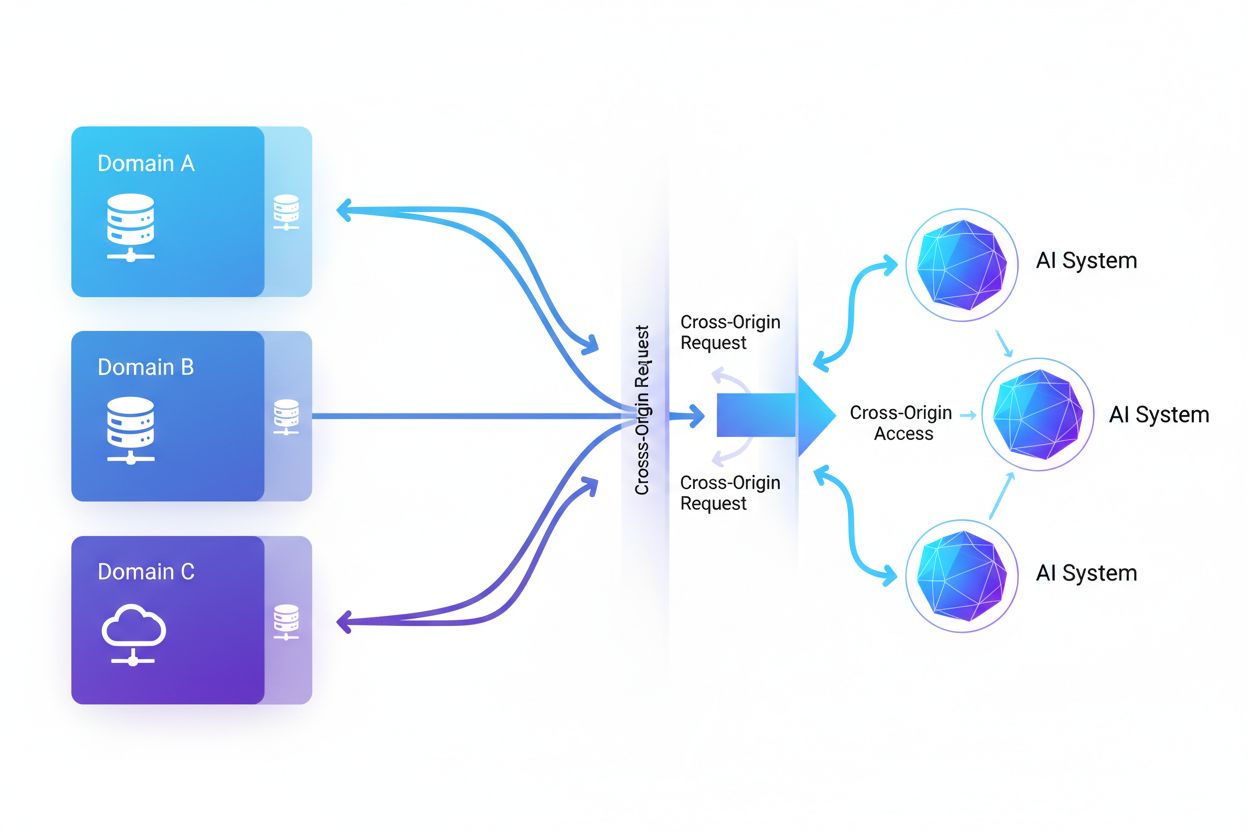
Cross-Origin AI Access označuje schopnosť systémov umelej inteligencie a webových crawlerov vyžadovať a získavať obsah z domén odlišných od ich pôvodu, pričom sú riadené bezpečnostnými mechanizmami ako CORS. Zahŕňa spôsob, akým AI spoločnosti rozširujú zber dát na trénovanie veľkých jazykových modelov a zároveň obchádzajú cross-origin obmedzenia. Pochopenie tohto konceptu je kľúčové pre tvorcov obsahu a majiteľov webstránok, aby vedeli chrániť duševné vlastníctvo a udržiavali kontrolu nad tým, ako ich obsah využívajú AI systémy. Prehľad o cross-origin AI aktivite pomáha rozlišovať medzi legitímnym AI prístupom a neautorizovaným scrapingom.
Cross-Origin AI Access označuje schopnosť systémov umelej inteligencie a webových crawlerov vyžadovať a získavať obsah z domén odlišných od ich pôvodu, pričom sú riadené bezpečnostnými mechanizmami ako CORS. Zahŕňa spôsob, akým AI spoločnosti rozširujú zber dát na trénovanie veľkých jazykových modelov a zároveň obchádzajú cross-origin obmedzenia. Pochopenie tohto konceptu je kľúčové pre tvorcov obsahu a majiteľov webstránok, aby vedeli chrániť duševné vlastníctvo a udržiavali kontrolu nad tým, ako ich obsah využívajú AI systémy. Prehľad o cross-origin AI aktivite pomáha rozlišovať medzi legitímnym AI prístupom a neautorizovaným scrapingom.
Cross-Origin AI Access označuje schopnosť systémov umelej inteligencie a webových crawlerov vyžadovať a získavať obsah z domén odlišných od ich pôvodu, pričom sú riadené bezpečnostnými mechanizmami ako Cross-Origin Resource Sharing (CORS). Ako AI spoločnosti rozširujú svoje úsilie o zber dát na tréning veľkých jazykových modelov a iných AI systémov, pochopenie spôsobu, akým tieto systémy obchádzajú cross-origin obmedzenia, sa stalo kľúčovým pre tvorcov obsahu a majiteľov webstránok. Výzva spočíva v rozlíšení medzi legitímnym AI prístupom na indexovanie vyhľadávania a neautorizovaným scrapingom na tréning modelov, čo robí prehľad o cross-origin AI aktivite nevyhnutným pre ochranu duševného vlastníctva a udržanie kontroly nad využitím obsahu.
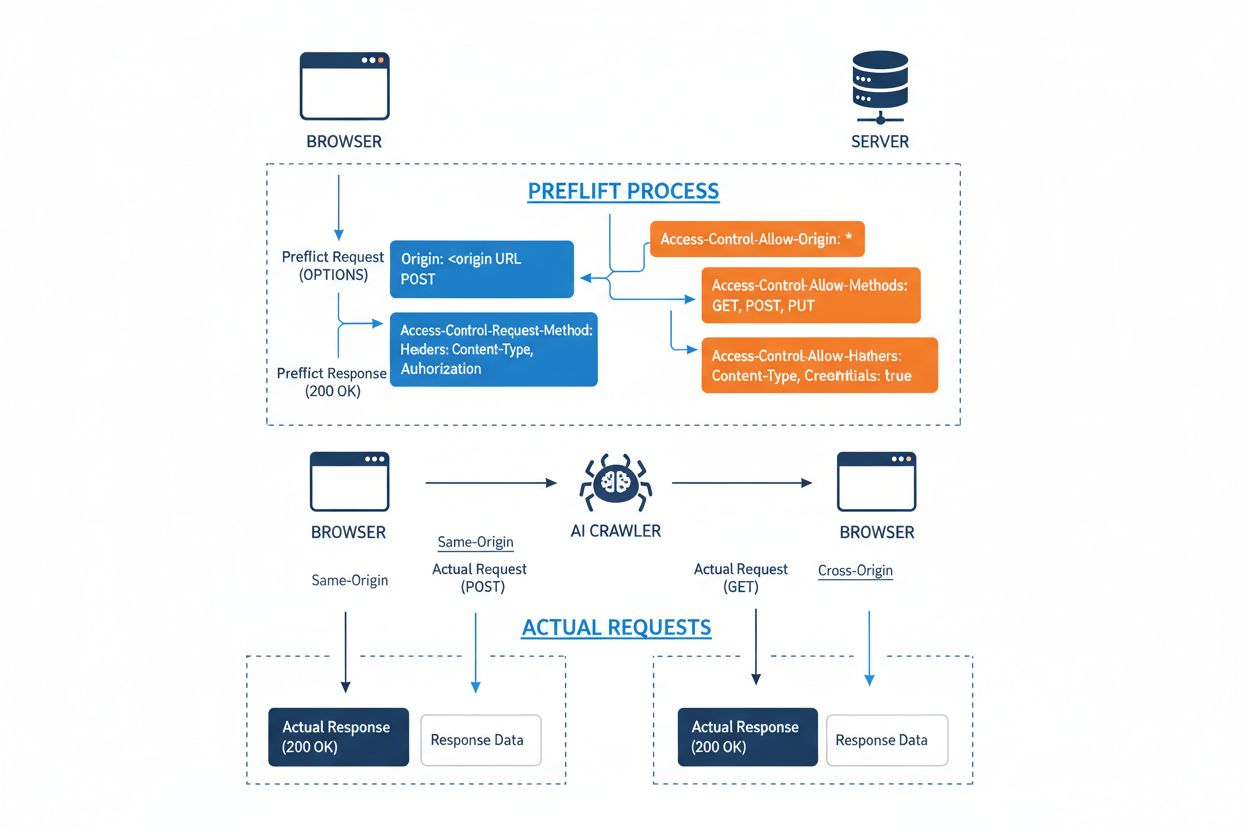
Cross-Origin Resource Sharing (CORS) je bezpečnostný mechanizmus založený na HTTP hlavičkách, ktorý umožňuje serverom špecifikovať, ktoré pôvody (domény, schémy alebo porty) môžu pristupovať k ich zdrojom. Keď sa AI crawler alebo iný klient pokúsi pristupovať k zdroju z iného pôvodu, prehliadač alebo klient iniciuje tzv. preflight požiadavku pomocou HTTP metódy OPTIONS, aby overil, či server povolí skutočnú požiadavku. Server odpovedá špecifickými CORS hlavičkami, ktoré určujú prístupové povolenia, vrátane toho, ktoré pôvody sú povolené, aké HTTP metódy sú povolené, ktoré hlavičky možno zahrnúť a či môžu byť s požiadavkou posielané poverenia ako cookies alebo autentifikačné tokeny.
| CORS Header | Účel |
|---|---|
Access-Control-Allow-Origin | Určuje, ktoré pôvody môžu pristupovať k zdroju (* pre všetky alebo špecifické domény) |
Access-Control-Allow-Methods | Uvádza povolené HTTP metódy (GET, POST, PUT, DELETE, atď.) |
Access-Control-Allow-Headers | Definuje, ktoré požiadavkové hlavičky sú povolené (Authorization, Content-Type, atď.) |
Access-Control-Allow-Credentials | Určuje, či môžu byť s požiadavkami posielané poverenia (cookies, auth tokeny) |
Access-Control-Max-Age | Určuje, ako dlho môžu byť odpovede na preflight požiadavky cacheované (v sekundách) |
Access-Control-Expose-Headers | Uvádza odpovedné hlavičky, ku ktorým majú klienti prístup |
AI crawlery interagujú s CORS rešpektovaním týchto hlavičiek v prípade správne nastavených serverov, no mnohé sofistikované boty sa snažia tieto obmedzenia obchádzať spoofovaním user agentov alebo využívaním proxy sietí. Efektívnosť CORS ako obrany proti neautorizovanému AI prístupu závisí výlučne od správnej konfigurácie serveru a ochoty crawlera rešpektovať obmedzenia – čo je kľúčový rozdiel, ktorý je čoraz dôležitejší, keďže AI spoločnosti súťažia o tréningové dáta.
Spektrum AI crawlerov pristupujúcich na web sa dramaticky rozšírilo a niekoľko veľkých hráčov dominuje cross-origin prístupovým vzorom. Podľa analýzy sieťovej prevádzky Cloudflare patria medzi najrozšírenejšie AI crawlery:
Tieto crawlery generujú miliardy požiadaviek mesačne a niektoré, ako Bytespider a GPTBot, pristupujú k väčšine verejne dostupného obsahu internetu. Obrovský objem a agresívnosť tejto aktivity viedli k tomu, že veľké platformy vrátane Reddit, Twitter/X, Stack Overflow a mnohých spravodajských organizácií zaviedli blokovacie opatrenia.
Zle nastavené CORS politiky vytvárajú značné bezpečnostné zraniteľnosti, ktoré môžu AI crawlery zneužiť na získanie citlivých dát bez autorizácie. Ak servery nastavia Access-Control-Allow-Origin: * bez správnej validácie, neúmyselne umožnia akémukoľvek pôvodu – vrátane škodlivých AI scraperov – prístup k zdrojom, ktoré mali byť obmedzené. Mimoriadne nebezpečná konfigurácia nastáva, keď sa Access-Control-Allow-Credentials: true skombinuje s wildcard nastavením pôvodu, čím útočníkom umožní kradnúť autentifikované údaje používateľov prostredníctvom cross-origin požiadaviek s cookies alebo tokenmi.
Bežné CORS misconfigurácie zahŕňajú dynamické odrážanie Origin hlavičky priamo do Access-Control-Allow-Origin odpovede bez validácie, čím sa v podstate umožní akémukoľvek pôvodu prístup k zdroju. Príliš benevolentné allow-listy, ktoré nedostatočne validujú hranice domény, môžu byť zneužité cez útoky na subdomény alebo manipuláciu s prefixmi. Navyše, veľa organizácií neimplementuje správnu validáciu samotnej Origin hlavičky, čím sa vystavujú spoofovaným požiadavkám. Dôsledky týchto zraniteľností siahajú od krádeže dát až po neautorizované tréningy AI modelov na proprietárnom obsahu, získavanie konkurenčných informácií a porušenie práv duševného vlastníctva – riziká, ktoré pomáhajú monitorovať a kvantifikovať nástroje ako AmICited.com.
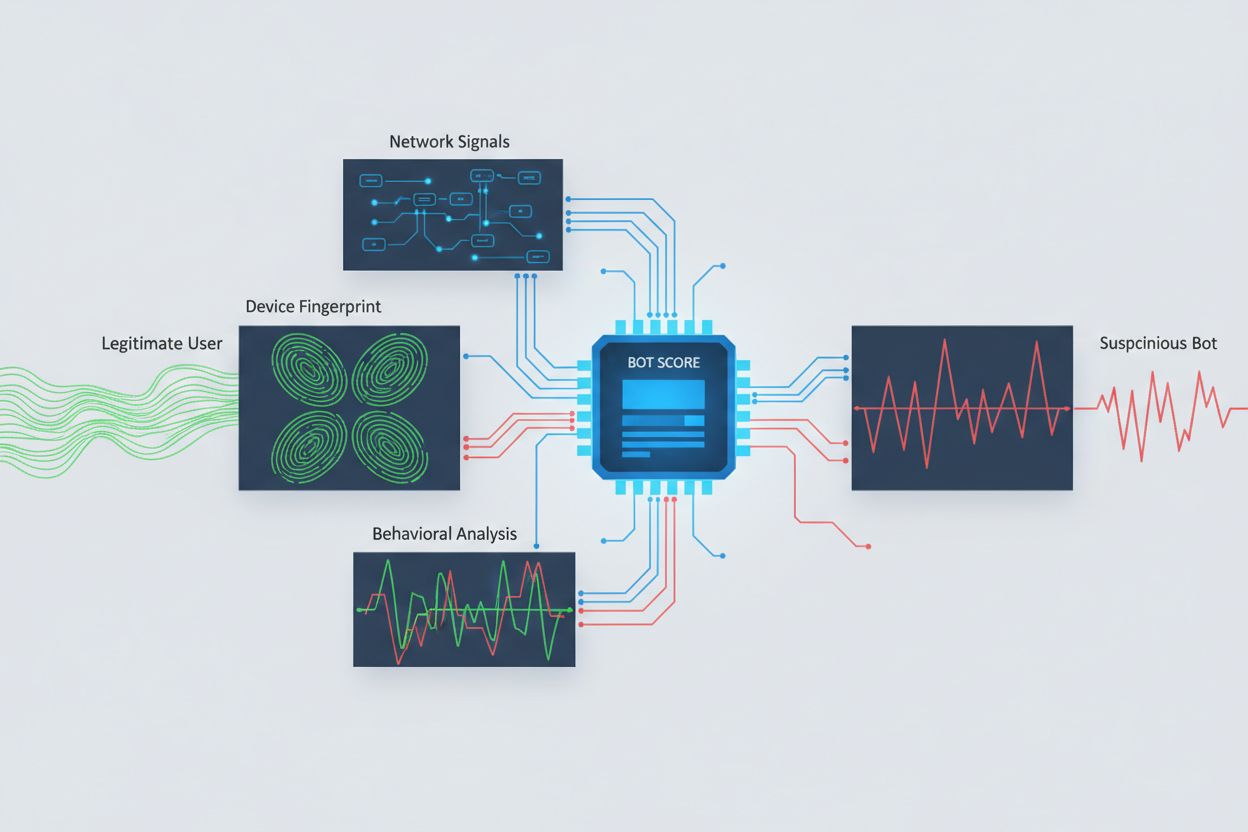
Identifikácia AI crawlerov pokúšajúcich sa o cross-origin prístup si vyžaduje analýzu viacerých signálov nad rámec jednoduchých user agent reťazcov, ktoré sú ľahko spoofovateľné. Analýza user agentov zostáva základnou metódou detekcie, keďže mnohé AI crawlery sa identifikujú špecifickými user agent reťazcami ako “GPTBot/1.0” alebo “ClaudeBot/1.0”, no sofistikované crawlery zámerne maskujú svoju identitu predstieraním legitímnych prehliadačov. Behaviorálny fingerprinting analyzuje spôsob, akým sú požiadavky realizované – skúma vzory ako časovanie požiadaviek, sled navštívených stránok, prítomnosť alebo absenciu vykonávania JavaScriptu a interakčné vzory, ktoré sa zásadne líšia od ľudského správania pri prehliadaní.
Analýza sieťových signálov poskytuje hlbšie možnosti detekcie skúmaním podpisov TLS handshake, reputácie IP, DNS rezolučných vzorov a charakteristík spojenia, ktoré odhaľujú aktivitu botov aj pri spoofovaných user agentoch. Fingerprinting zariadení agreguje desiatky signálov vrátane verzie prehliadača, rozlíšenia obrazovky, nainštalovaných fontov, detailov operačného systému a JA3 TLS fingerprintov na vytvorenie unikátnych identifikátorov pre každý zdroj požiadavky. Pokročilé detekčné systémy vedia identifikovať, kedy viacero relácií pochádza z toho istého zariadenia alebo skriptu, čím zachytávajú distribuované scraping pokusy, ktoré sa snažia obísť rate-limiting rozdelením požiadaviek na viac IP adries. Organizácie môžu tieto detekčné metódy využívať prostredníctvom bezpečnostných platforiem a monitorovacích služieb na získanie prehľadu o tom, ktoré AI systémy pristupujú k ich obsahu a ako sa snažia obchádzať obmedzenia.
Organizácie využívajú viacero vzájomne sa doplňujúcich stratégií na blokovanie alebo kontrolu cross-origin AI prístupu, pričom si uvedomujú, že žiadna samostatná metóda neposkytuje úplnú ochranu:
User-agent: GPTBot nasledované Disallow: /) poskytuje slušný, no dobrovoľný mechanizmus; účinné pre dobre sa správajúcich crawlerov, no ľahko ignorovateľné odhodlanými scrapermiNajefektívnejšia obrana kombinuje viacero vrstiev, keďže odhodlaní útočníci využijú slabiny v akomkoľvek jednovrstvovom prístupe. Organizácie musia neustále sledovať, ktoré blokovacie metódy fungujú, a prispôsobovať sa, ako crawlery vyvíjajú svoje obchádzacie techniky.
Efektívna správa cross-origin AI prístupu vyžaduje komplexný, vrstvený prístup, ktorý vyvažuje bezpečnosť s prevádzkovými potrebami. Organizácie by mali zaviesť stupňovitú stratégiu, začínajúcu základnými kontrolami ako robots.txt a filtrovaním user agentov, a postupne pridávať sofistikovanejšie detekčné a blokovacie mechanizmy na základe pozorovaných hrozieb. Kľúčový je kontinuálny monitoring – sledovanie, ktoré AI systémy pristupujú k vášmu obsahu, ako často robia požiadavky a či rešpektujú vaše obmedzenia, poskytuje prehľad potrebný na informované rozhodnutia o prístupových politikách.
Dokumentácia prístupových politík by mala byť jasná a vymožiteľná, s explicitnými podmienkami služby zakazujúcimi neautorizovaný scraping a určujúcimi dôsledky za porušenia. Pravidelné audity CORS konfigurácií pomáhajú identifikovať misconfigurácie skôr, než budú zneužité, pričom udržiavanie aktuálneho zoznamu známych AI crawler user agentov a IP rozsahov umožňuje rýchlu reakciu na nové hrozby. Organizácie by mali zvážiť aj obchodné dôsledky blokovania AI prístupu – niektoré AI crawlery poskytujú hodnotu cez indexovanie pre vyhľadávače alebo legitímne partnerstvá, preto by politiky mali rozlišovať medzi prospešným a škodlivým prístupom. Implementácia týchto postupov si vyžaduje koordináciu medzi bezpečnostnými, právnymi a obchodnými tímami, aby politiky boli v súlade s cieľmi organizácie a regulačnými požiadavkami.
Vznikli špecializované nástroje a platformy, ktoré organizáciám umožňujú monitorovať a kontrolovať cross-origin AI prístup s väčšou presnosťou a prehľadom. AmICited.com poskytuje komplexné monitorovanie toho, ako AI systémy referencujú a pristupujú k vašej značke naprieč GPTs, Perplexity, Google AI Overviews a ďalšími AI platformami, pričom ponúka prehľad o tom, ktoré AI modely využívajú váš obsah a ako často sa vaša značka objavuje v AI-generovaných odpovediach. Táto monitorovacia schopnosť zahŕňa sledovanie cross-origin prístupových vzorov a pochopenie širšieho ekosystému AI systémov interagujúcich s vašimi digitálnymi vlastnosťami.
Okrem monitorovania ponúka Cloudflare funkcie správy botov s blokovaním známych AI crawlerov na jedno kliknutie, pričom využíva modely strojového učenia trénované na celosieťových vzoroch prevádzky na identifikáciu botov aj pri spoofovaní user agentov. AWS WAF (Web Application Firewall) umožňuje nastavovať vlastné pravidlá pre blokovanie špecifických user agentov a IP rozsahov, zatiaľ čo Imperva ponúka pokročilú detekciu botov kombinujúcu behaviorálnu analýzu s threat intelligence. Bright Data sa špecializuje na pochopenie vzorov bot trafficu a môže organizáciám pomôcť rozlišovať medzi rôznymi typmi crawlerov. Výber nástrojov závisí od veľkosti organizácie, technickej vyspelosti a špecifických požiadaviek – od jednoduchého manažmentu robots.txt pre malé weby až po podnikové platformy na správu botov pre veľké organizácie spracúvajúce citlivé dáta. Bez ohľadu na výber nástroja však platí základný princíp: prehľad o cross-origin AI prístupe je základom efektívnej kontroly a ochrany digitálnych aktív.
CORS (Cross-Origin Resource Sharing) je bezpečnostný mechanizmus, ktorý riadi, ktoré pôvody môžu pristupovať k zdrojom na serveri. Cross-Origin AI Access sa konkrétne týka toho, ako AI systémy a crawleri interagujú s CORS pri požiadavkách na obsah z iných domén. Kým CORS je technický rámec, Cross-Origin AI Access opisuje praktickú výzvu správy správania AI crawlerov v rámci tohto rámca, vrátane detekcie a blokovania neautorizovaného AI prístupu.
Väčšina dobre sa správajúcich AI crawlerov sa identifikuje cez špecifické user agent reťazce ako 'GPTBot/1.0' alebo 'ClaudeBot/1.0', ktoré jasne uvádzajú ich účel. Mnohé sofistikované crawleri však zámerne spoofujú user agenty, predstierajúc legitímne prehliadače ako Chrome alebo Safari, aby obišli blokovanie založené na user agentoch. Preto sú potrebné pokročilé detekčné metódy využívajúce behaviorálne odtlačky a analýzu sieťových signálov na identifikáciu botov bez ohľadu na ich deklarovanú identitu.
robots.txt poskytuje dobrovoľný mechanizmus na požiadanie crawlerov, aby rešpektovali obmedzenia prístupu, a dobre sa správajúce AI crawlery ako GPTBot tieto pokyny spravidla dodržiavajú. robots.txt však nie je vynútiteľný – odhodlaní scraperi ho môžu jednoducho ignorovať. Mnohé AI spoločnosti boli prichytené pri obchádzaní robots.txt obmedzení, preto ide o potrebnú, ale nedostatočnú obranu, ktorú treba kombinovať s technickými blokovacími metódami, ako je filtrovanie user agentov, obmedzovanie rýchlosti a fingerprinting zariadení.
Zle nastavené CORS politiky môžu umožniť neautorizovaným AI crawlerom prístup k citlivým dátam, kradnúť autentifikované používateľské informácie cez požiadavky s povereniami a scrapovať proprietárny obsah na neautorizované tréningy AI modelov. Najnebezpečnejšie konfigurácie kombinujú wildcard nastavenia pôvodu s povolením poverení, čím v podstate umožňujú akémukoľvek pôvodu prístup k chráneným zdrojom. Tieto chyby môžu viesť k krádeži duševného vlastníctva, získavaniu konkurenčných informácií a porušeniu licenčných zmlúv k obsahu.
Detekcia vyžaduje analýzu viacerých signálov nad rámec user agent reťazcov. Môžete preskúmať serverové logy na známe AI crawler user agenty, implementovať behaviorálny fingerprinting na identifikáciu botov podľa vzorcov interakcie, analyzovať sieťové signály ako TLS handshaky a DNS vzory, a použiť fingerprinting zariadení na odhalenie distribuovaných scraping pokusov. Nástroje ako AmICited.com poskytujú komplexné monitorovanie, ako AI systémy referencujú vašu značku, zatiaľ čo platformy ako Cloudflare ponúkajú detekciu botov na báze strojového učenia, ktorá identifikuje aj spoofovaných crawlerov.
Žiadna jediná metóda neposkytuje úplnú ochranu, preto je najúčinnejší vrstvený prístup. Začnite s robots.txt a filtrovaním user agentov ako základnou obranou, pridajte obmedzovanie rýchlosti na zníženie dopadu, implementujte fingerprinting zariadení na zachytenie sofistikovaných botov a zvážte autentifikáciu alebo paywally pre citlivý obsah. Najefektívnejšie organizácie kombinujú viac techník a priebežne monitorujú, ktoré metódy fungujú, pričom sa prispôsobujú tomu, ako crawlery vyvíjajú vlastné obchádzacie techniky.
Nie. Kým veľké spoločnosti ako OpenAI a Anthropic tvrdia, že rešpektujú robots.txt a CORS obmedzenia, vyšetrovania ukázali, že mnohé AI crawlery tieto obmedzenia obchádzajú. Perplexity AI bol pristihnutý pri spoofovaní user agentov na obchádzanie blokov, a výskumy ukazujú, že crawlery OpenAI a Anthropic boli pozorované pri prístupe k obsahu aj napriek explicitným robots.txt zákazom. Táto nekonzistentnosť je dôvod, prečo sú čoraz potrebnejšie technické blokovacie metódy a právne vynucovanie.
AmICited.com poskytuje komplexné monitorovanie toho, ako AI systémy referencujú a pristupujú k vašej značke naprieč GPTs, Perplexity, Google AI Overviews a ďalšími AI platformami. Sleduje, ktoré AI modely využívajú váš obsah, ako často sa vaša značka objavuje v AI-generovaných odpovediach a poskytuje prehľad o širšom ekosystéme AI systémov interagujúcich s vašimi digitálnymi vlastnosťami. Takéto monitorovanie vám umožní pochopiť rozsah AI prístupu a prijímať informované rozhodnutia o stratégii ochrany vášho obsahu.
Získajte úplný prehľad o tom, ktoré AI systémy pristupujú k vašej značke naprieč GPTs, Perplexity, Google AI Overviews a inými platformami. Sledujte vzory cross-origin AI prístupu a pochopte, ako je váš obsah využívaný na tréning a inferenciu AI.
Naučte sa, ako vykonať audit prístupnosti pre AI, aby bola vaša webstránka objaviteľná pre AI prehľadávače ako ChatGPT, Claude a Perplexity. Technický sprievodc...

Zistite, ako sprístupniť svoj obsah AI prehliadačom ako ChatGPT, Perplexity a AI od Googlu. Objavte technické požiadavky, osvedčené postupy a stratégie monitoro...

Zistite, ako cross-platform AI publishing distribuuje obsah naprieč viacerými kanálmi optimalizovanými pre AI objavenie. Pochopte PESO kanály, výhody automatizá...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.