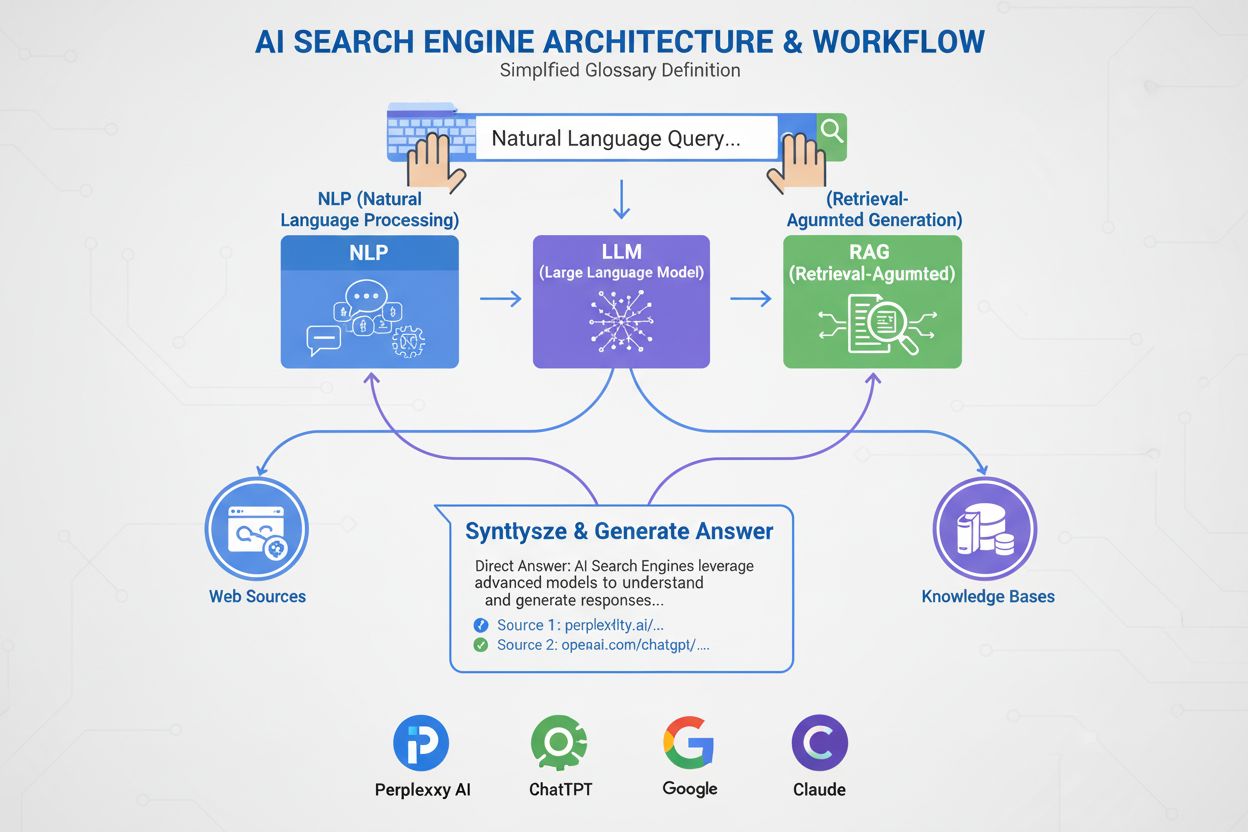
AI vyhľadávač
Zistite, čo sú AI vyhľadávače, ako sa líšia od tradičných vyhľadávačov a aký majú vplyv na viditeľnosť značky. Preskúmajte platformy ako Perplexity, ChatGPT, Go...
11 min čítania
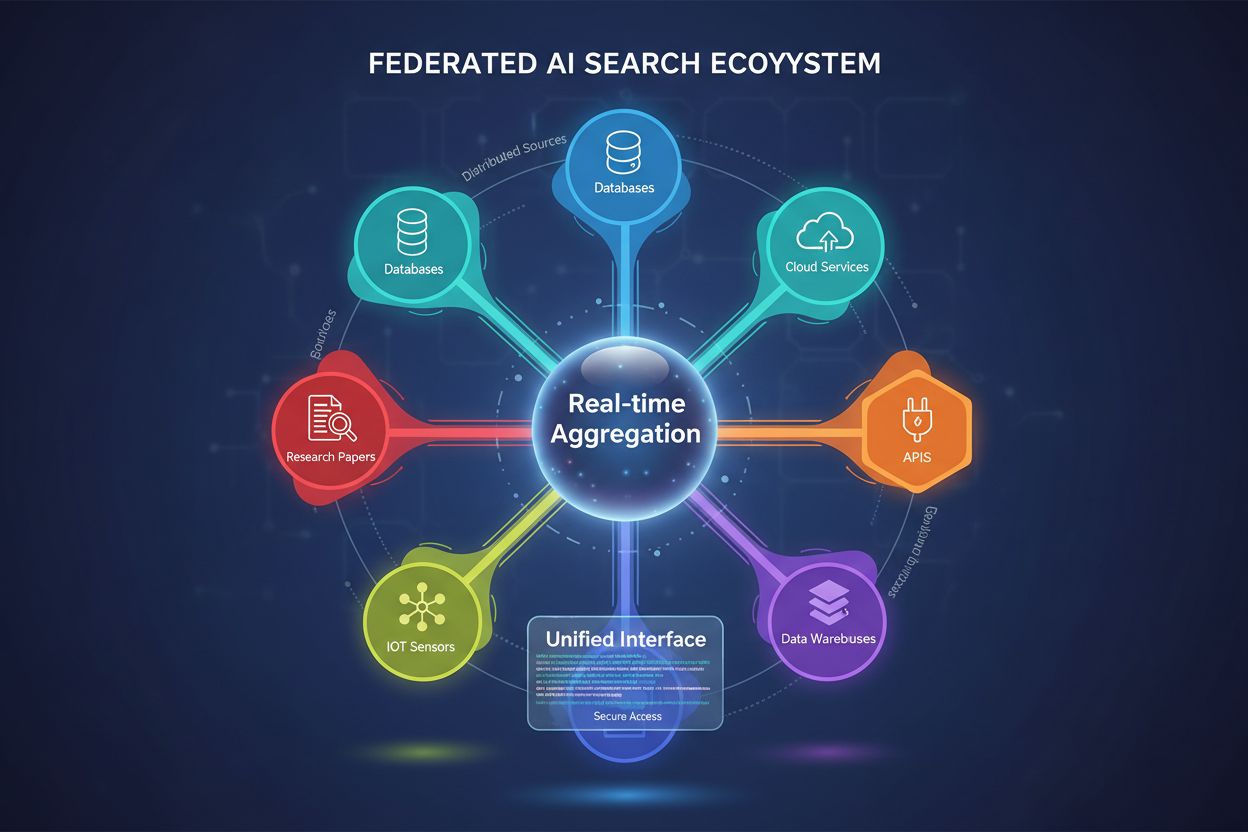
Federovaná AI vyhľadávanie je systém, ktorý súčasne dotazuje viacero nezávislých dátových zdrojov pomocou jedného vyhľadávacieho dotazu a agreguje výsledky v reálnom čase bez potreby presunu alebo duplikácie dát. Umožňuje organizáciám prístup k rozptýleným informáciám naprieč databázami, API a cloudovými službami pri zachovaní bezpečnosti a súladu s predpismi. Na rozdiel od tradičných centralizovaných vyhľadávačov federované systémy zachovávajú autonómiu dátových zdrojov a zároveň poskytujú jednotné objavovanie informácií. Tento prístup je obzvlášť hodnotný pre podniky, ktoré spravujú rôznorodé dátové zdroje naprieč rôznymi oddeleniami, geografickými lokalitami alebo organizáciami.
Federovaná AI vyhľadávanie je systém, ktorý súčasne dotazuje viacero nezávislých dátových zdrojov pomocou jedného vyhľadávacieho dotazu a agreguje výsledky v reálnom čase bez potreby presunu alebo duplikácie dát. Umožňuje organizáciám prístup k rozptýleným informáciám naprieč databázami, API a cloudovými službami pri zachovaní bezpečnosti a súladu s predpismi. Na rozdiel od tradičných centralizovaných vyhľadávačov federované systémy zachovávajú autonómiu dátových zdrojov a zároveň poskytujú jednotné objavovanie informácií. Tento prístup je obzvlášť hodnotný pre podniky, ktoré spravujú rôznorodé dátové zdroje naprieč rôznymi oddeleniami, geografickými lokalitami alebo organizáciami.
Federovaná AI vyhľadávanie je distribuovaný systém vyhľadávania informácií, ktorý súčasne dotazuje viacero heterogénnych dátových zdrojov a inteligentne agreguje výsledky pomocou techník umelej inteligencie. Na rozdiel od tradičných centralizovaných vyhľadávačov, ktoré udržiavajú jeden indexovaný repozitár, federovaná AI vyhľadávanie funguje naprieč decentralizovanými sieťami nezávislých databáz, znalostných báz a informačných systémov bez potreby konsolidácie dát alebo centralizovaného indexovania.
Základným princípom federovanej AI vyhľadávania je zdrojovo-agnostické dotazovanie, kde je jeden užívateľský dotaz inteligentne smerovaný na relevantné dátové zdroje, každý zdroj ho spracuje nezávisle a výsledky sú syntetizované do jednotnej sady výsledkov. Tento prístup zachováva autonómiu dát pri súčasnom umožnení komplexného objavovania informácií naprieč organizačnými a technickými hranicami.
Kľúčové charakteristiky federovaných AI vyhľadávacích systémov zahŕňajú:
Distribuovaná architektúra: Dáta zostávajú vo svojom pôvodnom umiestnení naprieč viacerými repozitármi, čím sa eliminuje potreba migrácie alebo centralizovaného ukladania. Každý zdroj si nezávisle spravuje vlastné indexovanie, prístupové práva aj aktualizačné mechanizmy.
Inteligentné smerovanie dotazov: AI algoritmy analyzujú prichádzajúce dotazy, aby určili, ktoré zdroje pravdepodobne obsahujú relevantné informácie, čím optimalizujú efektivitu vyhľadávania a znižujú zbytočné dotazy na irelevantné databázy.
Agregácia a radenie výsledkov: Modely strojového učenia syntetizujú výsledky z viacerých zdrojov a aplikujú sofistikované algoritmy na radenie podľa dôveryhodnosti zdroja, relevantnosti výsledku, aktuálnosti a užívateľského kontextu.
Podpora heterogénnych zdrojov: Federované systémy zvládajú rôznorodé dátové formáty, schémy, jazyky dotazov a prístupové protokoly vrátane relačných databáz, dokumentových úložísk, znalostných grafov, API a repozitárov neštruktúrovaného textu.
Integrácia v reálnom čase: Na rozdiel od dávkových prístupov pri dátovom skladovaní poskytuje federované vyhľadávanie takmer okamžitý prístup k aktuálnym informáciám zo všetkých pripojených zdrojov, čím zaručuje čerstvosť a presnosť výsledkov.
Sémantické porozumenie: Moderné federované AI vyhľadávače využívajú spracovanie prirodzeného jazyka a sémantickú analýzu na pochopenie zámeru dotazu nad rámec zhodných kľúčových slov, čo umožňuje presnejší výber zdrojov a interpretáciu výsledkov.
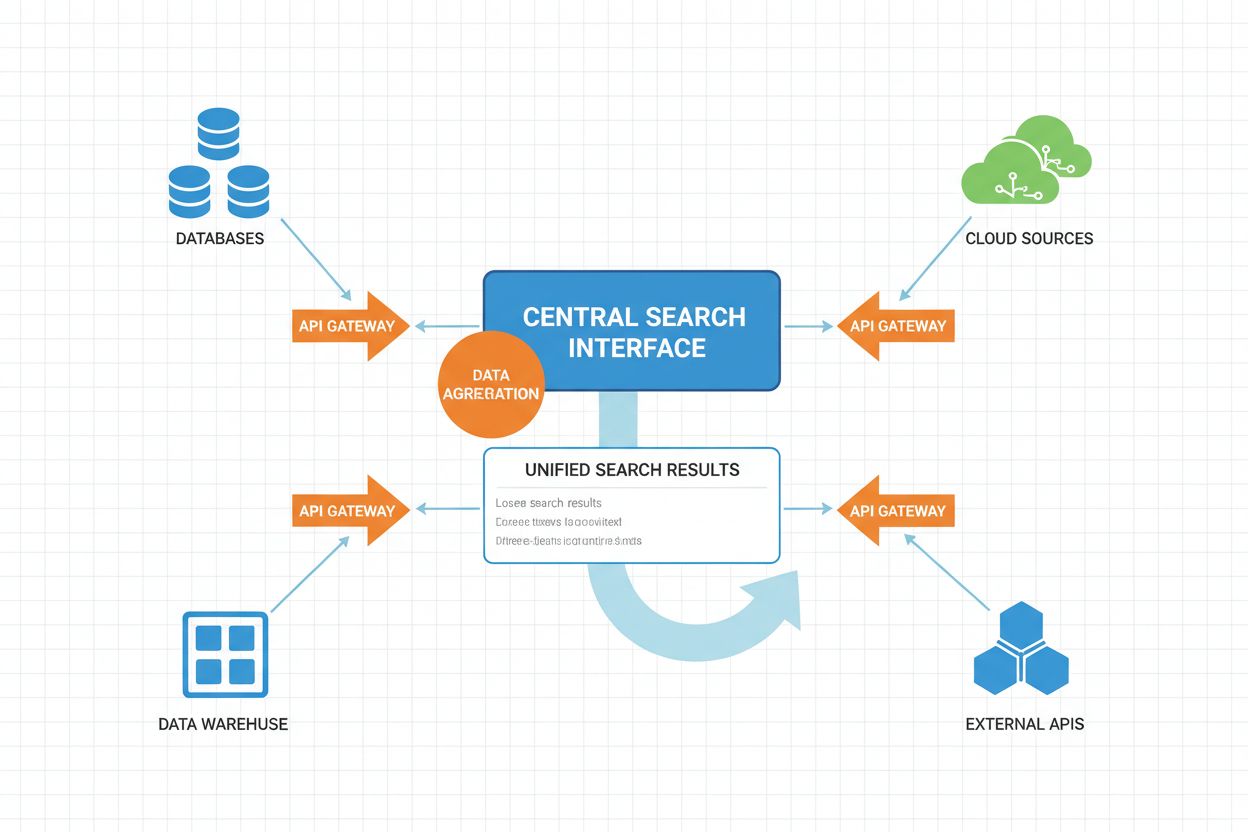
Prevádzkový pracovný tok federovaného AI vyhľadávania zahŕňa viacero koordinovaných fáz, z ktorých každá je vylepšená umelou inteligenciou pre optimalizáciu výkonu a kvality výsledkov.
| Fáza | Proces | AI Komponent | Výstup |
|---|---|---|---|
| Analýza dotazu | Užívateľský dotaz je rozparsovaný a analyzovaný na účel, entity a kontext | NLP, Rozpoznávanie pomenovaných entít, Klasifikácia zámeru | Štruktúrovaná reprezentácia dotazu, identifikované entity, signály zámeru |
| Výber zdrojov | Systém určí, ktoré dátové zdroje sú najrelevantnejšie pre dotaz | Modely strojového učenia na radenie, Klasifikátory relevantnosti zdrojov | Prioritizovaný zoznam cieľových zdrojov, skóre dôvery |
| Preklad dotazu | Dotaz je preložený do špecifických formátov a jazykov dotazov jednotlivých zdrojov | Mapovanie schém, Modely prekladu dotazov, Sémantické párovanie | Dotazy špecifické pre zdroj (SQL, SPARQL, API volania atď.) |
| Distribuované vykonávanie | Dotazy sa vykonávajú paralelne naprieč vybranými zdrojmi | Vyvažovanie záťaže, Správa timeoutov, Paralelné spracovanie | Surové výsledky z každého zdroja, metadáta o vykonaní |
| Normalizácia výsledkov | Výsledky z rôznych zdrojov sú prevedené do spoločného formátu | Zarovnanie schém, Konverzia dátových typov, Štandardizácia formátu | Normalizovaná množina výsledkov s konzistentnou štruktúrou |
| Sémantické obohatenie | Výsledky sú doplnené o ďalší kontext a metadáta | Prepojenie entít, Sémantické značkovanie, Integrácia znalostného grafu | Obohatené výsledky so sémantickými anotáciami |
| Radenie a deduplikácia | Výsledky sú radené podľa relevantnosti a duplicity odstránené | Modely učenia na radenie, Detekcia podobnosti, Skórovanie relevantnosti | Deduplikovaný, zoradený zoznam výsledkov |
| Personalizácia | Výsledky sú prispôsobené podľa profilu a preferencií užívateľa | Kolaboratívne filtrovanie, Modelovanie užívateľa, Kontextová citlivosť | Personalizované zoradenie výsledkov |
| Prezentácia | Výsledky sú naformátované pre užívateľa | Generovanie prirodzeného jazyka, Sumár výsledkov | Displej výsledkov pre užívateľa |
Pracovný tok funguje s paralelným vykonávaním ako základom, kde sa viaceré zdroje dotazujú súčasne namiesto sekvenčne. Táto paralelizácia dramaticky znižuje celkové oneskorenie dotazu napriek režijnej náročnosti koordinácie viacerých zdrojov. Pokročilé federované systémy implementujú adaptívne plánovanie dotazov, kde sa systém učí zo vzorcov historických dotazov optimalizovať výber zdrojov a stratégie vykonávania v čase.
Mechanizmy timeoutov a záložných riešení sú kľúčové pre zabezpečenie spoľahlivosti systému. Keď zdroj odpovedá pomaly alebo zlyhá, systém môže buď čakať s adaptívnym timeoutom, alebo pokračovať s výsledkami dostupných zdrojov, čím dôjde k čiastočnému, nie úplnému zlyhaniu.
Federované AI vyhľadávacie systémy je možné kategorizovať podľa viacerých dimenzií:
Podľa architektúry:
Podľa typu dátových zdrojov:
Podľa rozsahu a škály:
Podľa úrovne inteligencie:
Autonómia a správa dát: Organizácie si zachovávajú kontrolu nad svojimi dátami, nie je potrebné presúvať citlivé informácie do centralizovaných úložísk. Tým sa zachovávajú politiky správy dát, požiadavky na súlad a bezpečnostné opatrenia na úrovni zdroja.
Škálovateľnosť bez konsolidácie: Federované systémy sa škálujú pridávaním nových zdrojov bez potreby migrácie dát alebo reštrukturalizácie skladu. Organizácie môžu inkrementálne integrovať nové zdroje podľa potreby.
Prístup k informáciám v reálnom čase: Dotazovaním zdrojov priamo poskytuje federované vyhľadávanie prístup k aktuálnym dátam bez oneskorenia typického pre dávkové skladovanie. Ideálne pre časovo citlivé aplikácie.
Nákladová efektívnosť: Odstraňuje vysoké investičné a prevádzkové náklady spojené s budovaním a udržiavaním centralizovaných dátových skladov. Organizácie sa vyhnú duplicite dát, zbytočnému ukladaniu a zložitým ETL procesom.
Znížená redundancia dát: Na rozdiel od skladovania, ktoré duplikuje dáta, federované vyhľadávanie zachováva jediný zdroj pravdy, znižuje úložné nároky a zaručuje konzistentnosť.
Flexibilita a prispôsobivosť: Nové zdroje je možné integrovať bez zásahu do existujúcej infraštruktúry alebo reindexácie centrálnych repozitárov. Umožňuje rýchlu reakciu na meniace sa obchodné potreby.
Zlepšená kvalita dát: Priame dotazovanie autoritatívnych zdrojov minimalizuje zastaralosť a nekonzistentnosť dát, ku ktorým dochádza pri periodickej synchronizácii v skladoch.
Zvýšená bezpečnosť: Citlivé dáta nikdy neopúšťajú pôvodné umiestnenie, čo znižuje riziko neoprávneného prístupu alebo úniku. Prístupové práva zostávajú pod kontrolou zdrojov.
Podpora heterogénnych zdrojov: Federované systémy zvládnu rôzne technológie, formáty a protokoly bez nutnosti ich štandardizácie alebo migrácie na spoločnú platformu.
Inteligentná syntéza výsledkov: AI poháňané radenie a agregácia produkujú kvalitnejšie výsledky než jednoduché spájanie, pričom zohľadňujú dôveryhodnosť zdroja, relevantnosť a užívateľský kontext.
Moderné federované AI vyhľadávacie systémy pozostávajú z viacerých navzájom prepojených technických komponentov, ktoré spolupracujú na poskytovaní integrovaných vyhľadávacích schopností.
Engine na spracovanie dotazov: Centrálny komponent prijíma užívateľské dotazy a orchestruje federovaný pracovný tok. Zahŕňa parsovanie, sémantickú analýzu a rozpoznávanie zámeru. Pokročilé implementácie využívajú jazykové modely typu transformer na pochopenie komplexnej sémantiky a implicitného zámeru užívateľa.
Register zdrojov a správa metadát: Udržiava komplexné metadáta o dostupných dátových zdrojoch vrátane schém, charakteristík obsahu, frekvencie aktualizácií, vzorcov dostupnosti a výkonnostných metrík. Register umožňuje inteligentný výber zdrojov a optimalizáciu dotazov. Modely strojového učenia analyzujú historické dotazy na predikciu relevantnosti zdrojov pre nové dotazy.
Inteligentný výber zdrojov: Využíva klasifikátory strojového učenia na určenie, ktoré zdroje pravdepodobne obsahujú relevantné informácie pre daný dotaz. Zohľadňuje pokrytie obsahu, historickú úspešnosť, dostupnosť zdroja a odhadované časy odpovede. Pokročilé systémy využívajú reinforcement learning na neustálu optimalizáciu stratégií výberu zdrojov podľa výsledkov dotazov.
Vrstva prekladu a adaptácie dotazov: Konvertuje užívateľské dotazy do špecifických formátov a jazykov. Zahŕňa generovanie SQL pre relačné databázy, SPARQL pre znalostné grafy, REST API volania pre webové služby a prirodzený jazyk pre neštruktúrované textové systémy. Sémantické mapovanie zaisťuje zachovanie zámeru dotazu naprieč rozdielnymi jazykmi a modelmi dát.
Koordinátor distribuovaného vykonávania: Spravuje paralelné vykonávanie dotazov naprieč zdrojmi, vrátane manažmentu timeoutov, vyvažovania záťaže a zotavenia po zlyhaní. Zavádza adaptívne stratégie timeoutov prispôsobené vzorcom odpovedí a zaťaženia systému.
Engine na normalizáciu výsledkov: Prevod výsledkov z heterogénnych zdrojov do spoločného formátu pre agregáciu a radenie. Zahŕňa zarovnanie schém, konverziu dátových typov a štandardizáciu formátov. Zvláda chýbajúce polia, konfliktné typy a štrukturálne rozdiely medzi zdrojmi.
Sémantické obohatenie: Obohacuje výsledky o ďalší kontext a sémantické informácie. Zahŕňa prepojenie entít na znalostné bázy, sémantické značkovanie podľa ontológií a extrakciu vzťahov z neštruktúrovaného textu. Tieto obohatenia zlepšujú presnosť radenia i zrozumiteľnosť výsledkov.
Model učenia na radenie: Model strojového učenia trénovaný na historických pároch dotaz–výsledok na predikciu relevantnosti výsledkov. Zohľadňuje stovky faktorov vrátane dôveryhodnosti zdroja, aktuálnosti obsahu, súladu s profilom užívateľa a sémantickej podobnosti dotazu a výsledku. Moderné implementácie využívajú gradient boosting alebo neuronové siete.
Engine na deduplikáciu: Identifikuje a odstraňuje duplicitné alebo takmer duplicitné výsledky z rôznych zdrojov. Používa metriky podobnosti vrátane presného porovnávania, fuzzy matching a sémantickej podobnosti pomocou embeddingov.
Personalizačný engine: Prispôsobuje poradie výsledkov podľa užívateľských profilov, historických preferencií a kontextových informácií. Realizuje kolaboratívne filtrovanie a odporúčacie techniky pre zvýšenie relevantnosti výsledkov pre jednotlivých užívateľov.
Vrstva cacheovania a optimalizácie: Zavádza inteligentné caching stratégie na redukciu zbytočných dotazov na zdroje. Zahŕňa cacheovanie výsledkov dotazov, metadát zdrojov a naučených vzorcov dotazov na predikciu budúcich potrieb.
Monitoring a analytika: Sleduje výkonnosť systému, spoľahlivosť zdrojov, vzorce dotazov a metriky kvality výsledkov. Tieto dáta spätne optimalizujú komponenty systému.
Zdravotníctvo a medicínsky výskum: Federované vyhľadávanie integruje záznamy pacientov naprieč nemocnicami, výskumnými databázami, registrami klinických štúdií a repozitármi medicínskej literatúry. Lekári môžu vyhľadávať komplexné anamnézy naprieč poskytovateľmi bez centralizácie citlivých údajov, výskumníci získavajú prístup k distribuovaným klinickým dátam pri zachovaní súladu s HIPAA a ochranou súkromia.
Finančné služby: Banky a investičné firmy využívajú federované vyhľadávanie na dotazovanie obchodných dát, trhových informácií, regulačných databáz a interných transakčných záznamov súčasne. To umožňuje hodnotenie rizík, monitoring súladu a analýzu trhu v reálnom čase bez konsolidácie citlivých dát.
Právo a compliance: Právnické firmy a firemné právne oddelenia vyhľadávajú v databázach judikatúry, regulačných repozitároch, interných dokumentových systémoch a databázach zmlúv. Federované vyhľadávanie umožňuje komplexný právny výskum pri zachovaní dôvernosti dokumentov.
E-commerce a maloobchod: Online obchodníci integrujú katalógy produktov naprieč skladmi, systémami dodávateľov a trhoviskami. Federované vyhľadávanie poskytuje jednotné vyhľadávanie produktov, pričom dodávatelia si zachovávajú vlastné systémy aj cenotvorbu.
Štátna správa a verejná správa: Inštitúcie vyhľadávajú v distribovaných databázach vrátane sčítania ľudu, daňových záznamov, systémov povolení a verejných registrov bez centralizácie citlivých údajov. Umožňuje komplexné služby občanom so zachovaním bezpečnosti dát.
Výroba a dodávateľský reťazec: Výrobcovia integrujú databázy dodávateľov, skladové systémy, výrobné záznamy a logistické platformy. Federované vyhľadávanie poskytuje prehľad o reťazci pri zachovaní nezávislosti a dôvernosti partnerov.
Vzdelávanie a výskum: Univerzity vyhľadávajú v inštitucionálnych repozitároch, knižničných systémoch, výskumných databázach a open access publikáciách. Federované vyhľadávanie umožňuje komplexné akademické objavovanie pri rešpektovaní autonómie inštitúcií.
Telekomunikácie: Telekomunikační operátori vyhľadávajú v zákazníckych databázach, záznamoch infraštruktúry, fakturačných systémoch a katalógoch služieb. Federované vyhľadávanie umožňuje jednotné služby zákazníkom pri zachovaní oddelených systémov pre rôzne segmenty.
Energetika a utility: Energetické spoločnosti vyhľadávajú v dátach z výrobných zariadení, distribučných sietí, zákazníckych databáz a systémov compliance. Federované vyhľadávanie poskytuje prevádzkový prehľad, pričom regionálni operátori si zachovávajú vlastné systémy.
Médiá a vydavateľstvo: Mediálne organizácie vyhľadávajú v repozitároch obsahu, archívoch, systémoch správy práv a distribučných platformách. Federované vyhľadávanie umožňuje komplexné vyhľadávanie obsahu so zachovaním vlastníctva a licenčných obmedzení.
Heterogenita zdrojov a integračná zložitosť: Integrácia rôznorodých zdrojov s odlišnými schémami, jazykmi dotazov a protokolmi si vyžaduje značné inžinierske úsilie. Mapovanie schém a sémantické zarovnanie sú náročné, najmä pri rôznom reprezentovaní rovnakých pojmov.
Oneskorenie dotazov a výkon: Federované vyhľadávanie znamená dotazovanie viacerých zdrojov, čo je pomalšie než centralizované systémy. Pomalé alebo nedostupné zdroje môžu zhoršiť výkon. Správa timeoutov vyžaduje dobré nastavenie na vyváženie úplnosti a rýchlosti.
Spoľahlivosť a dostupnosť zdrojov: Závislosť od externých zdrojov znamená, že výpadky či výkonnostné problémy majú okamžitý dopad na výsledky. Potrebné je zvládnutie čiastočných výpadkov.
Kvalita výsledkov a presnosť radenia: Agregácia výsledkov z rôznych zdrojov s rôznou kvalitou, pokrytím a relevantnosťou je výzvou. Modely radenia musia zvládnuť variabilitu dôveryhodnosti a zabrániť uprednostňovaniu konkrétnych zdrojov.
Aktuálnosť a konzistentnosť dát: Federované systémy síce pristupujú k aktuálnym dátam, ale zdroje sa môžu aktualizovať s rôznou frekvenciou. Zmiernenie konfliktov medzi informáciami z rôznych zdrojov si vyžaduje pokročilé riešenia.
Škálovateľnosť: S rastúcim počtom zdrojov rastie režijná náročnosť koordinácie. Výber relevantných zdrojov z tisícov možností je výpočtovo náročný. Paralelizácia vo veľkom meradle vyžaduje robustnú infraštruktúru.
Bezpečnosť a prístupové práva: Federované systémy musia presadzovať prístupové práva na úrovni zdrojov pri poskytovaní jednotného rozhrania. Zabezpečenie, že užívateľ vidí len to, na čo má oprávnenie, je zložité najmä vo viacerých tenantoch.
Súkromie a ochrana dát: Federované vyhľadávanie musí spĺňať nariadenia ako GDPR, CCPA a odvetvové požiadavky. Zamedzenie úniku citlivých dát cez agregáciu alebo analýzu metadát je výzvou.
Objavovanie a správa zdrojov: Identifikácia, katalogizácia, aktualizácia a správa životného cyklu zdrojov si vyžaduje neustálu prevádzkovú starostlivosť.
Sémantická interoperabilita: Dosiahnutie skutočnej sémantickej interoperability medzi zdrojmi s odlišnými ontológiami a modelmi dát je náročné. Automatizované mapovanie schém a rozpoznávanie entít má svoje limity.
Náklady na koordináciu: Hoci federované vyhľadávanie šetrí náklady na konsolidáciu, zavádza režijné náklady na koordináciu. Správa distribuovaného vykon
Tradičné centralizované vyhľadávanie konsoliduje všetky dáta do jedného indexovaného úložiska, čo vyžaduje migráciu dát a spôsobuje oneskorenie. Federovaná AI vyhľadávanie sa dotazuje viacerých nezávislých zdrojov priamo v reálnom čase bez presunu alebo duplikácie dát, pričom zachováva autonómiu zdrojov a zároveň poskytuje jednotný prístup. To robí federované vyhľadávanie ideálnym pre organizácie s rozptýlenými dátovými zdrojmi a prísnymi požiadavkami na správu dát.
Federovaná AI vyhľadávanie ponecháva dáta v ich pôvodnom umiestnení a rešpektuje prístupové práva a bezpečnostné politiky každého zdroja. Používatelia majú prístup len k informáciám, na ktoré sú oprávnení, a citlivé dáta nikdy neopúšťajú svoj zdrojový systém. Tento prístup zjednodušuje dodržiavanie nariadení, ako sú GDPR a HIPAA, keďže odstraňuje riziká spojené s centralizáciou citlivých informácií.
Kľúčové výzvy zahŕňajú správu heterogénnych dátových zdrojov s rôznymi schémami a formátmi, zvládanie oneskorenia dotazov z viacerých zdrojov, zabezpečenie konzistentného radenia výsledkov naprieč zdrojmi a udržiavanie spoľahlivosti systému pri nedostupnosti niektorých zdrojov. Organizácie musia tiež investovať do robustného manažmentu metadát a inteligentných algoritmov na výber zdrojov pre optimalizáciu výkonu.
Áno, federovaná AI vyhľadávanie škáluje pridávaním nových zdrojov bez potreby migrácie dát alebo reštrukturalizácie dátového skladu. Avšak s rastúcim počtom zdrojov narastá aj režijná náročnosť koordinácie dotazov. Moderné systémy využívajú strojové učenie na inteligentný výber zdrojov a implementujú caching stratégie na udržanie výkonu vo veľkom meradle.
Dátové skladovanie konsoliduje dáta do centralizovaného úložiska, čo umožňuje rýchle dotazy, ale vyžaduje náročné ETL procesy a spôsobuje oneskorenie v dostupnosti dát. Federované vyhľadávanie sa dotazuje zdrojov priamo, poskytuje prístup v reálnom čase, avšak s vyšším oneskorením dotazov. Skladovanie je vhodné pre historickú analýzu a reporting, kým federované vyhľadávanie vyniká v objavovaní aktuálnych informácií naprieč rozptýlenými zdrojmi.
Z federovaného vyhľadávania výrazne profitujú zdravotníctvo, financie, e-commerce, štátna správa a výskumné organizácie. Zdravotníctvo ho využíva na integráciu záznamov pacientov naprieč poskytovateľmi, financie na dodržiavanie predpisov a hodnotenie rizík, e-commerce na jednotné vyhľadávanie produktov a výskumné organizácie na prehľadávanie rozptýlených akademických databáz.
AI zlepšuje federované vyhľadávanie prostredníctvom spracovania prirodzeného jazyka na pochopenie dotazov, strojového učenia pre inteligentný výber zdrojov, sémantickej analýzy pre lepšie radenie výsledkov a automatizované odstraňovanie duplicít. AI modely sa učia zo vzorcov dotazov a priebežne optimalizujú výber zdrojov a agregáciu výsledkov, čím časom zlepšujú výkon systému.
Sémantické porozumenie umožňuje federovaným systémom pochopiť zámer dotazu nad rámec zhodných kľúčových slov, presnejšie identifikovať relevantné zdroje a radiť výsledky na základe významu, nie len prekrytia kľúčových slov. Zahŕňa to rozpoznávanie entít, extrakciu vzťahov a integráciu znalostných grafov, čo vedie k relevantnejším a kontextuálne vhodným výsledkom vyhľadávania.
AmICited sleduje, ako AI systémy ako ChatGPT, Perplexity a Google AI Overviews citujú a odkazujú na vašu značku. Zistite svoju viditeľnosť v AI a optimalizujte svoju prítomnosť v AI-generovaných odpovediach.
Zistite, čo sú AI vyhľadávače, ako sa líšia od tradičných vyhľadávačov a aký majú vplyv na viditeľnosť značky. Preskúmajte platformy ako Perplexity, ChatGPT, Go...

Zistite, čo je SearchGPT, ako funguje a aký má vplyv na vyhľadávanie, SEO a digitálny marketing. Preskúmajte funkcie, obmedzenia a budúcnosť AI-vyhľadávania....

Stratégia podnikového AI vyhľadávania: integrácia, správa, metriky ROI. Zistite, ako veľké organizácie implementujú AI vyhľadávacie platformy pre ChatGPT, Perpl...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.