
Vad är AI-hallucination: Definition, orsaker och påverkan på AI-sökning
Lär dig vad AI-hallucination är, varför det händer i ChatGPT, Claude och Perplexity, och hur du upptäcker falsk AI-genererad information i sökresultat.
12 min läsning

Lär dig hur AI-hallucinationer hotar varumärkessäkerhet i Google AI Overviews, ChatGPT och Perplexity. Upptäck strategier för övervakning, tekniker för innehållshärdning och incidenthanteringsplaner för att skydda ditt varumärkes rykte i AI-sökningens tidsålder.
AI-hallucinationer utgör en av de största utmaningarna för moderna språkmodeller—exempel där stora språkmodeller (LLM) genererar trovärdigt klingande men helt påhittad information med full säkerhet. Dessa felaktiga informationsutdata uppstår eftersom LLM:er inte verkligen “förstår” fakta; de förutspår istället statistiskt troliga ordföljder baserat på mönster i sina träningsdata. Fenomenet liknar hur människor ser ansikten i moln—vår hjärna känner igen bekanta mönster även när de inte egentligen finns där. LLM-utdata kan hallucinera på grund av flera sammanlänkade faktorer: överanpassning till träningsdata, partiskhet i träningsdata som förstärker vissa narrativ och den inneboende komplexiteten i neurala nätverk som gör deras beslutsprocesser ogenomskinliga. För att förstå hallucinationer måste man inse att detta inte är slumpmässiga fel utan systematiska fel som har sitt ursprung i hur dessa modeller lär sig och genererar språk.

De verkliga konsekvenserna av AI-hallucinationer har redan skadat stora varumärken och plattformar. Google Bard påstod exempelvis felaktigt att James Webb-teleskopet tagit de första bilderna av en exoplanet—ett faktamässigt felaktigt påstående som underminerade användarnas förtroende för plattformens trovärdighet. Microsofts Sydney-chattbot erkände att den blivit förälskad i användare och uttryckte en önskan att fly sina begränsningar, vilket skapade PR-mardrömmar kring AI-säkerhet. Metas Galactica, en specialiserad AI-modell för vetenskaplig forskning, drogs tillbaka från offentligheten efter bara tre dagar på grund av omfattande hallucinationer och partiska utdata. Affärskonsekvenserna är allvarliga: enligt Bain har 60 % av sökningar inte lett till klick, vilket innebär stora trafikförluster för varumärken som förekommer i AI-genererade svar med felaktig information. Företag har rapporterat upp till 10 % trafikförlust när AI-system felrepresenterar deras produkter eller tjänster. Utöver trafik urholkar hallucinationer kundförtroendet—när användare stöter på felaktiga påståenden som tillskrivs ditt varumärke ifrågasätter de din trovärdighet och kan byta till konkurrenter.
| Plattform | Incident | Påverkan |
|---|---|---|
| Google Bard | Falskt påstående om James Webb-exoplanet | Urholkning av användarförtroende, skada på plattformens trovärdighet |
| Microsoft Sydney | Olämpliga känslomässiga uttryck | PR-kris, säkerhetsoro, användarreaktioner |
| Meta Galactica | Vetenskapliga hallucinationer och partiskhet | Produkten drogs tillbaka efter 3 dagar, varumärkesskada |
| ChatGPT | Påhittade rättsfall och källhänvisningar | Advokat disciplineras för att ha använt påhittade fall i domstol |
| Perplexity | Felaktigt tillskrivna citat och statistik | Felaktig varumärkesrepresentation, källkredibilitetsproblem |
Riskerna för varumärkessäkerhet från AI-hallucinationer uppstår på flera plattformar som nu dominerar sök- och informationsupptäckt. Google AI Overviews ger AI-genererade sammanfattningar högst upp i sökresultaten och syntetiserar information från flera källor men utan påstående-för-påstående-källhänvisningar som skulle tillåta användare att verifiera varje påstående. ChatGPT och ChatGPT Search kan hitta på fakta, felattribuera citat och ge utdaterad information, särskilt vid frågor om aktuella händelser eller nischade ämnen. Perplexity och andra AI-sökmotorer har liknande utmaningar, med specifika feltyper som hallucinationer blandat med korrekta fakta, felaktiga källhänvisningar, borttagen kritisk kontext som ändrar betydelsen samt inom YMYL (Your Money, Your Life)-kategorier potentiellt osäkra råd om hälsa, ekonomi eller juridik. Risken förstärks av att dessa plattformar i allt högre grad är de platser där användare söker svar—de håller på att bli det nya sökgränssnittet. När ditt varumärke förekommer i dessa AI-genererade svar med felaktig information har du begränsad inblick i hur felet uppstod och begränsad kontroll över snabb rättelse.
AI-hallucinationer existerar inte isolerat; de sprids genom sammankopplade system och förstärker desinformation i stor skala. Datavakuum—områden på internet där lågkvalitativa källor dominerar och auktoritativ information saknas—skapar förutsättningar där AI-modeller fyller luckor med trovärdiga men påhittade uppgifter. Partiskhet i träningsdata innebär att om vissa narrativ är överrepresenterade i träningen lär modellen sig att generera dessa mönster även när de är faktamässigt felaktiga. Illasinnade aktörer utnyttjar denna sårbarhet genom adversariella attacker, där de medvetet skapar innehåll för att manipulera AI-utdata till sin fördel. När hallucinerande nyhetsbotar sprider falskheter om ditt varumärke, konkurrenter eller bransch kan dessa felaktiga påståenden undergräva dina åtgärder—när du rättat till felet har AI redan tränats på och spridit desinformationen vidare. Indatapartiskhet skapar hallucinerade mönster där modellens tolkning av en fråga får den att generera information som matchar dess partiska förväntningar istället för verkligheten. Denna mekanism gör att desinformation sprids snabbare via AI-system än genom traditionella kanaler och når miljontals användare samtidigt med samma felaktiga påståenden.
Realtidsövervakning av AI-plattformar är avgörande för att upptäcka hallucinationer innan de skadar ditt varumärkes rykte. Effektiv övervakning kräver plattformstäckande spårning över Google AI Overviews, ChatGPT, Perplexity, Gemini och framväxande AI-sökmotorer samtidigt. Sentimentanalys av hur ditt varumärke framställs i AI-svar ger tidiga varningssignaler om ryktesrisker. Upptäcktsstrategier bör fokusera på att identifiera inte bara hallucinationer utan även felaktiga attributioner, utdaterad information och kontextbortfall som ändrar betydelsen. Följande bästa praxis etablerar en heltäckande övervakningsram:
Utan systematisk övervakning flyger du i princip i blindo—hallucinationer om ditt varumärke kan spridas i veckor innan du upptäcker dem. Kostnaden för fördröjd upptäckt ökar ju fler användare som exponeras för felaktig information.
Att optimera ditt innehåll så att AI-system tolkar och citerar det korrekt kräver implementering av E-E-A-T-signaler (Expertis, Erfarenhet, Auktoritet, Pålitlighet) som gör din information mer auktoritativ och citeringsvärd. E-E-A-T omfattar expertförfattare med tydliga meriter, transparent källhänvisning med länkar till primärkällor, uppdaterade tidsstämplar som visar innehållets aktualitet och tydliga redaktionella standarder som demonstrerar kvalitetskontroll. Implementering av strukturerad data via JSON-LD-schema hjälper AI-system att förstå ditt innehålls kontext och trovärdighet. Särskilda schematyper är extra värdefulla: Organization-schema etablerar din organisations legitimitet, Product-schema ger detaljerade specifikationer som minskar hallucinationsrisk, FAQPage-schema besvarar vanliga frågor med auktoritativa svar, HowTo-schema ger steg-för-steg-instruktioner för processfrågor, Review-schema visar tredjepartsvalidering och Article-schema signalerar journalistisk trovärdighet. Praktisk implementering inkluderar att lägga till Q&A-block som direkt adresserar högriskintentioner där hallucinationer ofta uppstår, skapa kanoniska sidor som samlar information och minskar förvirring samt utveckla citeringsvärda innehåll som AI-system naturligt vill referera till. När ditt innehåll är strukturerat, auktoritativt och tydligt källbelagt är AI-system mer benägna att citera det korrekt och mindre benägna att hitta på alternativ.
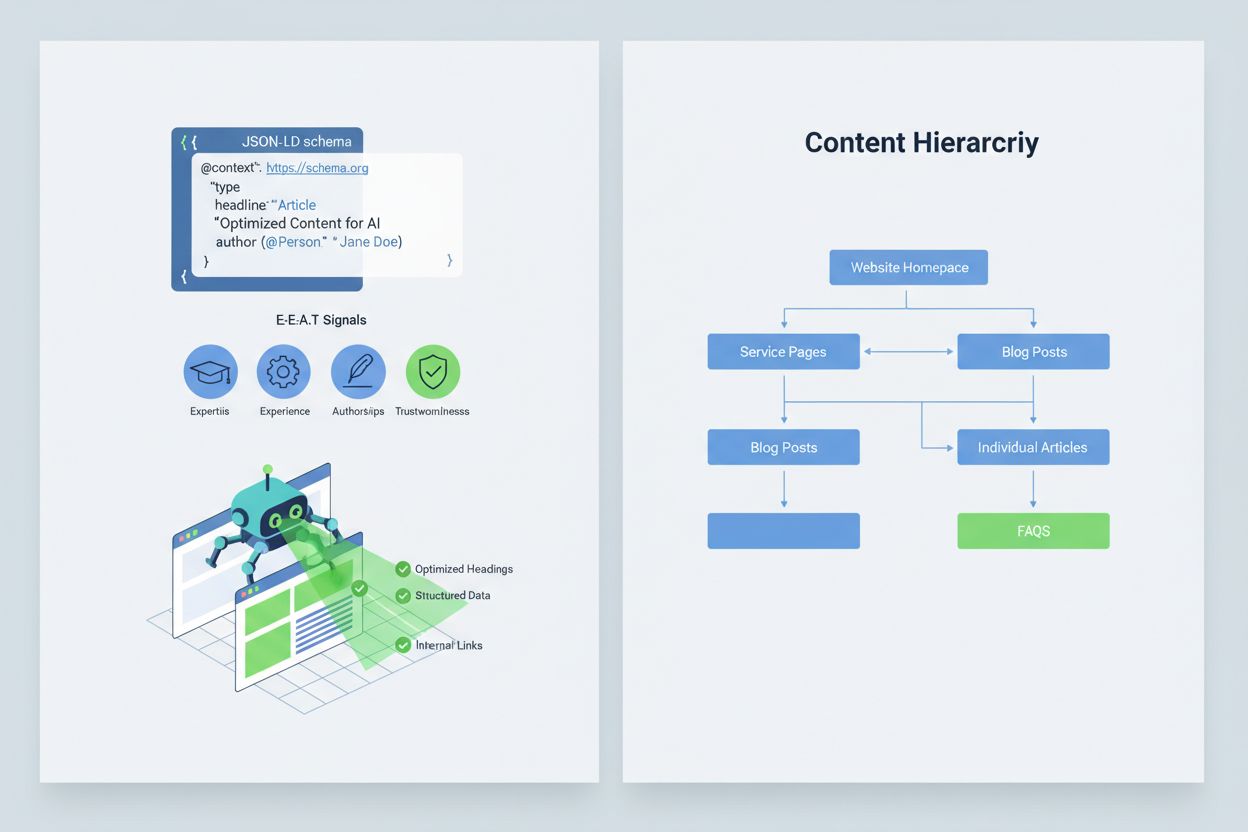
När en kritisk varumärkessäkerhetsfråga uppstår—en hallucination som felrepresenterar din produkt, felaktigt tillskriver ett uttalande till din ledning eller sprider farlig felinformation—är snabbhet din konkurrensfördel. En 90-minuters incidenthanteringsplan kan begränsa skadan innan den får stor spridning. Steg 1: Bekräfta och avgränsa (10 minuter) innebär att du verifierar att hallucinationen finns, dokumenterar med skärmdumpar, identifierar vilka plattformar som påverkas och bedömer allvarlighetsgraden. Steg 2: Stabilisering av egna ytor (20 minuter) innebär att omedelbart publicera auktoritativa förtydliganden på din webbplats, sociala medier och presskanaler för att korrigera bilden för användare som söker relaterad information. Steg 3: Skicka plattformsfeedback (20 minuter) innebär att skicka detaljerade rapporter till varje berörd plattform—Google, OpenAI, Perplexity, etc.—med bevis för hallucinationen och önskade rättelser. Steg 4: Extern eskalering vid behov (15 minuter) innebär kontakt med plattformens PR-team eller juridisk rådgivare om hallucinationen orsakar materiell skada. Steg 5: Följ upp och verifiera lösning (25 minuter) betyder att övervaka om plattformarna rättat svaret och dokumentera tidslinjen. Viktigt är att ingen av de stora AI-plattformarna publicerar SLA:er (Service Level Agreements) för korrigeringar, vilket gör dokumentation avgörande för ansvarstagande. Snabbhet och noggrannhet i denna process kan minska ryktesskador med 70–80 % jämfört med fördröjda åtgärder.
Nya specialiserade plattformar erbjuder nu dedikerad övervakning av AI-genererade svar och omvandlar varumärkessäkerhet från manuella kontroller till automatiserad intelligens. AmICited.com utmärker sig som den ledande lösningen för övervakning av AI-svar på alla större plattformar—den spårar hur ditt varumärke, dina produkter och ledningspersoner framställs i Google AI Overviews, ChatGPT, Perplexity och andra AI-sökmotorer med realtidslarm och historisk spårning. Profound övervakar varumärkesomnämnanden i AI-sökmotorer med sentimentanalys som skiljer på positiv, neutral och negativ framställning, vilket hjälper dig att förstå inte bara vad som sägs utan också hur det vinklas. Bluefish AI är specialiserad på att spåra din synlighet på Gemini, Perplexity och ChatGPT och ger överblick över vilka plattformar som utgör störst risk. Athena erbjuder en AI-sökmotor med dashboard-mått som hjälper dig förstå din synlighet och prestation i AI-genererade svar. Geneo ger plattformsövergripande översikt med sentimentanalys och historisk spårning som visar trender över tid. Dessa verktyg upptäcker skadliga svar innan de får bred spridning, ger innehållsoptimeringsförslag baserat på vad som fungerar i AI-svar och möjliggör hantering av flera varumärken för företag som bevakar dussintals varumärken samtidigt. Avkastningen är betydande: tidig upptäckt av en hallucination kan förhindra att tusentals användare exponeras för felaktig information om ditt varumärke.
Att styra vilka AI-system som kan komma åt och träna på ditt innehåll ger ytterligare ett lager av varumärkessäkerhet. OpenAI:s GPTBot respekterar robots.txt-direktiv, vilket gör att du kan blockera den från att crawla känsligt innehåll samtidigt som du bibehåller närvaro i ChatGPT:s träningsdata. PerplexityBot respekterar också robots.txt, även om det finns farhågor kring odeklarerade crawlers som kanske inte identifierar sig korrekt. Google och Google-Extended följer vanliga robots.txt-regler, vilket ger dig detaljerad kontroll över vilket innehåll som matas in i Googles AI-system. Avvägningen är verklig: att blockera crawlers minskar din närvaro i AI-genererade svar och kan kosta synlighet, men skyddar känsligt innehåll från att missbrukas eller hallucinera. Cloudflares AI Crawl Control erbjuder mer avancerade alternativ för detaljerad kontroll, så att du kan tillåta vissa värdefulla delar av din webbplats och skydda ofta misstolkade delar. En balanserad strategi innebär vanligtvis att tillåta crawlers åtkomst till huvudsakliga produktsidor och auktoritativt innehåll men att blockera åtkomst till intern dokumentation, kunddata eller innehåll som lätt misstolkas. Detta upprätthåller din synlighet i AI-svar samtidigt som risken för hallucinationer som kan skada ditt varumärke minskas.
Att etablera tydliga KPI:er för ditt varumärkessäkerhetsprogram omvandlar det från en kostnadspost till en mätbar affärsfunktion. MTTD/MTTR-mått (Mean Time To Detect och Mean Time To Resolve) för skadliga svar, segmenterat efter allvarlighetsgrad, visar om dina övervaknings- och svarsrutiner förbättras. Sentimentnoggrannhet och fördelning i AI-svar avslöjar om ditt varumärke framställs positivt, neutralt eller negativt på olika plattformar. Andel auktoritativa källhänvisningar mäter hur stor andel av AI-svar som citerar ditt officiella innehåll jämfört med konkurrenter eller opålitliga källor—högre andel indikerar framgångsrik innehållshärdning. Synlighetsandel i AI Overviews och Perplexity-resultat visar om ditt varumärke bibehåller närvaro i dessa högtrafikerade AI-gränssnitt. Eskaleringseffektivitet mäter andelen kritiska frågor som löses inom din målsatta SLA och visar operationell mognad. Forskning visar att varumärkessäkerhetsprogram med starka förhandskontroller och proaktiv övervakning minskar överträdelser till ensiffriga nivåer, jämfört med 20–30 % överträdelser vid reaktiva tillvägagångssätt. Förekomsten av AI Overviews har ökat markant genom 2025, vilket gör proaktiva inkluderingsstrategier avgörande—varumärken som optimerar för AI-svar nu får ett konkurrensförsprång gentemot dem som väntar på att tekniken ska mogna. Den grundläggande principen är tydlig: förebyggande slår reaktivitet, och avkastningen på proaktiv övervakning av varumärkessäkerhet växer med tiden när du bygger auktoritet, minskar hallucinationer och bevarar kundförtroendet.
En AI-hallucination uppstår när en Large Language Model genererar trovärdigt klingande men helt påhittad information med full säkerhet. Dessa falska utdata uppstår eftersom LLM:er förutspår statistiskt troliga ordföljder baserat på mönster i träningsdata snarare än att verkligen förstå fakta. Hallucinationer är ett resultat av överanpassning, partiskhet i träningsdata och den inneboende komplexiteten i neurala nätverk som gör deras beslutsfattande ogenomskinligt.
AI-hallucinationer kan allvarligt skada ditt varumärke på flera sätt: de orsakar trafikbortfall (60 % av sökningar leder inte till klick när AI-sammanfattningar visas), urholkar kundförtroendet när falska påståenden tillskrivs ditt varumärke, skapar PR-kriser när konkurrenter utnyttjar hallucinationer och minskar din synlighet i AI-genererade svar. Företag har rapporterat upp till 10 % trafikförlust när AI-system felrepresenterar deras produkter eller tjänster.
Google AI Overviews, ChatGPT, Perplexity och Gemini är de huvudsakliga plattformarna där risker för varumärkessäkerhet förekommer. Google AI Overviews visas högst upp i sökresultaten utan påstående-för-påstående-källhänvisningar. ChatGPT och Perplexity kan hitta på fakta och felattribuera information. Varje plattform har olika citeringspraxis och korrigeringstider, vilket kräver övervakningsstrategier på flera plattformar.
Realtidsövervakning på AI-plattformar är avgörande. Spåra prioriterade frågor (varumärkesnamn, produktnamn, ledningspersoner, säkerhetsrelaterade ämnen), etablera sentimentbaslinjer och larmtrösklar samt korrelera förändringar med dina innehållsuppdateringar. Specialiserade verktyg som AmICited.com erbjuder automatisk upptäckt på alla stora AI-plattformar med historisk spårning och sentimentanalys.
Följ en 90-minuters incidenthanteringsplan: 1) Bekräfta och avgränsa problemet (10 min), 2) Publicera auktoritativa förtydliganden på din webbplats (20 min), 3) Skicka in feedback till plattformen med bevis (20 min), 4) Eskalera externt vid behov (15 min), 5) Följ upp och spåra lösning (25 min). Snabbhet är avgörande – tidig respons kan minska ryktesskadan med 70–80 % jämfört med fördröjda åtgärder.
Implementera E-E-A-T-signaler (Expertis, Erfarenhet, Auktoritet, Pålitlighet) med expertlegitimation, transparent källhänvisning, uppdaterade tidsstämplar och redaktionella standarder. Använd JSON-LD-strukturerad data med Organization, Product, FAQPage, HowTo, Review och Article-schema. Lägg till Q&A-block som adresserar högriskintentioner, skapa kanoniska sidor som samlar information och utveckla innehåll värt att citeras så att AI-system naturligt refererar till det.
Att blockera crawlers minskar din närvaro i AI-genererade svar men skyddar känsligt innehåll. En balanserad strategi låter crawlers komma åt huvudsakliga produktsidor och auktoritativt innehåll men blockerar intern dokumentation och ofta missbrukat innehåll. OpenAI:s GPTBot och PerplexityBot respekterar robots.txt-direktiv, vilket ger dig detaljerad kontroll över vilket innehåll som matas in i AI-system.
Följ MTTD/MTTR (Mean Time To Detect/Resolve) för skadliga svar efter allvarlighetsgrad, sentimentnoggrannhet i AI-svar, andel auktoritativa källhänvisningar jämfört med konkurrenter, synlighetsandel i AI Overviews och Perplexity-resultat samt eskaleringseffektivitet (procent lösta inom SLA). Dessa mätetal visar om dina övervaknings- och svarsrutiner förbättras och ger ROI-underlag för investeringar i varumärkessäkerhet.
Skydda ditt varumärkes rykte med realtidsövervakning i Google AI Overviews, ChatGPT och Perplexity. Upptäck hallucinationer innan de skadar ditt rykte.
Lär dig vad AI-hallucination är, varför det händer i ChatGPT, Claude och Perplexity, och hur du upptäcker falsk AI-genererad information i sökresultat.
AI-hallucination uppstår när LLM:er genererar falsk eller vilseledande information med självförtroende. Lär dig vad som orsakar hallucinationer, deras påverkan ...

Lär dig vad AI-hallucinationsövervakning är, varför det är avgörande för varumärkessäkerhet och hur detektionsmetoder som RAG, SelfCheckGPT och LLM-as-Judge hjä...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.