
Datadriven PR: Skapa forskning som AI vill citera
Lär dig hur du skapar originalforskning och datadrivet PR-innehåll som AI-system aktivt citerar. Upptäck de 5 egenskaperna hos innehåll värt att citera och stra...
8 min läsning
Lär dig hur du skapar originaldata och forskning som AI-system aktivt citerar. Upptäck strategier för att göra din data upptäckbar för ChatGPT, Perplexity, Google Gemini och Claude samtidigt som du bygger hållbar AI-synlighet.
I artificiell intelligens tidsålder har originaldata blivit det nya konkurrensmedlet för varumärken som vill synas bortom traditionella sökresultat. När AI-plattformar som ChatGPT, Perplexity, Google Gemini och Claude alltmer styr hur målgrupper hittar information har synlighetsreglerna förändrats i grunden. Istället för att konkurrera om position noll hos Google måste organisationer nu skapa data som AI-system aktivt vill citera och referera till. Denna omvandling speglar ett bredare skifte från innehållsdriven SEO till det experter kallar “Generative Engine Optimization” (GEO), där AI-citering har ersatt traditionell ranking som det primära synlighetsmåttet. Plattformarna som syntetiserar information till direkta svar—oavsett om det sker via retrieval-augmented generation (RAG) eller modell-nativ syntes—gynnar källor som erbjuder tydlig, extraherbar och auktoritativ originalforskning. Organisationer som förstår detta skifte och satsar på att skapa originaldata, egen forskning och unika insikter positionerar sig för att bli citerade på flera AI-plattformar samtidigt, vilket ger medvetenhet och trovärdighet hos publiker som kanske aldrig ser traditionella sökresultat.

Olika AI-plattformar använder fundamentalt olika arkitekturer för att hitta och citera källor, vilket direkt påverkar hur din originaldata lyfts fram och krediteras. Att förstå dessa mekanismer är avgörande för att optimera synligheten över AI-landskapet. Skillnaden mellan modell-nativ syntes (där AI genererar svar utifrån träningsdatamönster) och retrieval-augmented generation (där AI söker i realtidskällor och syntetiserar från hämtade resultat) förklarar varför vissa plattformar ger tydliga citat och andra svarar utan attribution. Plattformar som använder RAG-system kan spåra sina svar tillbaka till specifika källor, vilket gör citering enkel och spårbar. Modell-nativa system däremot förlitar sig på sannolikhetsbaserad kunskap från träningen, vilket gör källattribution svår eller omöjlig utan tillägg eller integrationer.
| AI-plattform | Citeringsmetod | Datakällprioritet | Synlighetseffekt |
|---|---|---|---|
| ChatGPT | Modell-nativ (standard); länkade citat med plugins/surfning aktiverad | Träningsdata + realtidswebb när aktiverad; prioriterar aktuella, auktoritativa källor vid retrieval | Låg utan plugins; medel med sök aktiverad; citat visas i svaret vid tillgänglighet |
| Perplexity | Retrieval-först med inlinade numrerade citat | Webbresultat i realtid; prioriterar färska, direkt relevanta källor; betonar källors framträdande | Hög; numrerade citat med tydliga käll-länkar; förstapositionens källor får oproportionerligt mycket trafik |
| Google Gemini | Integrerat med Google Sök och Knowledge Graph | Indexerade sidor + Knowledge Graph-entiteter; prioriterar sidor med strukturerad data och E-E-A-T-signaler | Hög; citat visas som käll-länkar i AI Overviews; strukturerad data ökar citeringschans |
| Claude | Modell-nativ (standard); webbsökfunktion rullas ut under 2025 | Träningsdata + selektiv webbsök; prioriterar säkra, auktoritativa källor | Medel; citat visas vid webbsök; fokus på noggrannhet och källtrovärdighet |
De praktiska konsekvenserna är stora: plattformar som Perplexity och Google Gemini, som aktivt söker igenom webben i realtid, kan citera ditt innehåll direkt vid publicering om det uppfyller deras kvalitets- och relevanskrav. ChatGPT och Claude, som är mer beroende av träningsdata, kan ta längre tid att inkludera din originalforskning men ger andra möjligheter via plugins och integrationer. För innehållsskapare innebär detta att förstå vilka plattformar din målgrupp använder och optimera din data därefter—antingen genom att säkerställa extraherbart, välstrukturerat innehåll för Perplexitys live retrieval, eller bygga auktoritetssignaler som påverkar inclusion i modell-nativa systemens träningsdata.
Strukturerad data har utvecklats från en trevlig SEO-taktik till ett strategiskt måste för AI-synlighet. När du implementerar schema markup med Schema.org-vokabulär hjälper du inte bara Google att förstå ditt innehåll—du skapar ett maskinläsbart lager som AI-system kan grunda sina svar på. Detta lager, ofta kallat “content knowledge graph”, definierar explicit entiteter (personer, produkter, tjänster, platser, organisationer) och relationer mellan dem, vilket kraftigt förenklar för AI att förstå vad ditt varumärke är, vad det erbjuder och hur det ska tolkas. Enligt aktuell forskning från BrightEdge hade sidor med robust schema markup högre citeringsfrekvens i Googles AI Overviews, vilket tyder på att strukturerad data direkt påverkar citeringschansen. Den framväxande Model Context Protocol (MCP), antagen av både OpenAI och Google DeepMind, representerar nästa steg—i princip ett standardiserat API för att koppla AI-modeller till strukturerade datakällor. Genom att implementera schema markup i stor skala lägger företag grunden för att minska hallucinationer i AI-svar, förbättra faktagrundning och göra sin data mer upptäckbar i retrieval-system. Detta är särskilt viktigt eftersom AI-system tränade på ostrukturerad text ofta har svårt med exakthet; strukturerad data ger den kontext AI-modeller behöver för att generera mer tillförlitliga, attribuerbara svar som tryggt citerar din originalforskning.

Den mest effektiva strategin för att få AI-citat är att skapa originaldata som är extraherbar, auktoritativ och anpassad efter hur AI-system hämtar och syntetiserar information. Istället för att hoppas att befintligt innehåll blir citerat måste du medvetet utforma dataprodukter som AI-plattformar lätt kan hitta, förstå och referera till. Här är kärnstrategierna för att skapa citeringsvärd originaldata:
Genomför originalforskning med transparent metodik: AI-system prioriterar källor som visar upp rigorösa forskningsmetoder. Publicera studier, enkäter och analyser med tydligt dokumenterade metoder, urvalsstorlekar och begränsningar. När du visar hur du gått till väga kan AI-plattformar tryggt citera dina fynd som auktoritativa. Exempel är branschstandarder, kundbeteendestudier, marknadsundersökningar och egen dataanalys som konkurrenter inte kan kopiera.
Gör data extraherbar via strukturerade format: AI-system föredrar innehåll organiserat som tabeller, listor, jämförelsematriser och FAQ-liknande frågor och svar framför kompakta stycken. En jämförelsetabell med konkurrenters funktioner citeras oftare än samma information gömd i löpande text. Använd rubriker, punktlistor och visuella hierarkier så att nyckelinsikter snabbt kan skannas och hämtas av AI-system.
Säkerställ dataaktualitet och synliga uppdateringssignaler: AI-plattformar, särskilt de med live web retrieval, prioriterar aktuell information. Inkludera synliga publiceringsdatum, uppdateringstidsstämplar och regelbundna uppdateringar. När du visar att din data är aktuell och underhållen, betraktar AI-system den som mer tillförlitlig än föråldrade källor. Detta är särskilt viktigt för tidskänslig data som priser, statistik och marknadstrender.
Bygg författar- och varumärkesauktoritet: AI-system utvärderar källtrovärdighet innan de citerar. Bygg tydliga författarmeriter (inkludera presentationer med relevant expertis), organisatorisk auktoritet (backlänkar, medierapporter, branschutmärkelser) och signaler om domänexpertis. När ditt varumärke erkänns som auktoritet inom sitt område citeras du oftare och mer framträdande.
Använd tydliga entitetsdefinitioner och relationer: Definiera nyckelentiteter explicit—ditt företag, produkter, tjänster, teammedlemmar och branschbegrepp. Använd strukturerad data för att etablera relationer mellan dessa entiteter. När ett AI-system förstår exakt vad du är och hur du relaterar till branschbegrepp kan det citera dig mer exakt och kontextuellt.
Tillämpa korrekt attribution och källhänvisning: Om din originaldata bygger på andra källor, citera dem öppet. AI-system uppmärksammar och belönar källor som själva anger sina ursprung. Detta skapar en attribueringskedja som ökar förtroendet och citeringsmöjligheten i hela ekosystemet.
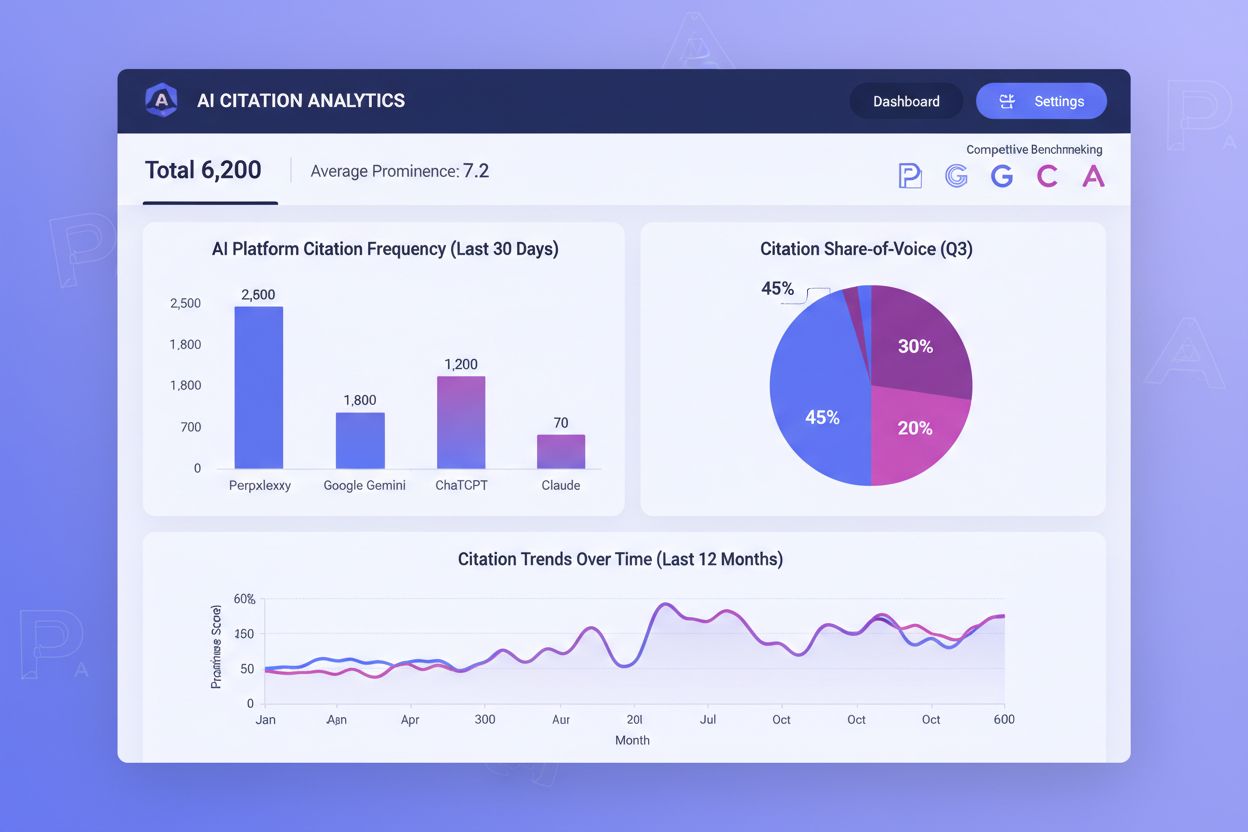
Att följa AI-citat har blivit lika viktigt som att bevaka traditionella sökrankningar, men de flesta organisationer saknar insyn i hur ofta deras innehåll citeras över AI-plattformar. Citeringsfrekvens, citeringsframhävning och share-of-voice är de tre centrala måtten som avgör din framgång i AI-märkt upptäckt. Citeringsfrekvens mäter hur ofta ditt innehåll syns i AI-svar för dina målfrågor—om du citeras i 40 % av relevanta prompts medan konkurrenter citeras i 60 %, finns ett tydligt optimeringsgap. Citeringsframhävning är ännu viktigare: en förstaposition i Perplexitys numrerade lista ger oproportionerligt mycket synlighet jämfört med till exempel en femte plats. Share-of-voice visar din konkurrensposition—om ditt varumärke får citat i 25 % av kategoridefinierande frågor medan din största konkurrent får 50 %, tappar du betydande synlighet.
Verktyg som AmICited.com har blivit oumbärliga lösningar för att bevaka AI-citat över plattformar. Dessa plattformar följer vilka av dina sidor som får citat på Perplexity, Google AI Overviews, ChatGPT med sök och andra AI-system och visar vilket innehåll som faktiskt driver AI-märkt synlighet. Genom att övervaka citeringsmönster över tid kan du identifiera vilka innehållstyper, ämnen och format som genererar flest citat och sedan upprepa dessa framgångsstrategier. Konkurrensjämförelse via dessa verktyg visar exakt var du förlorar citat till konkurrenter och möjliggör riktad optimering. Datan visar om dina citeringsutmaningar är generella för alla AI-plattformar eller specifika för vissa system—om du ofta citeras på Perplexity men sällan på Google AI Overviews, bör din optimeringsstrategi anpassas. Positionsviktade mått erkänner att tidiga citat ger oproportionerligt mycket värde; verktyg som väger förstapositionens citat högre än lägre positioner ger mer användbara insikter än bara råa citatantal. Genom att se AI-citeringsspårning som en kärndel av din innehållsstrategi kan du kontinuerligt optimera din originaldata för att öka både citeringsfrekvens och -framhävning och därigenom direkt förbättra din synlighet i ett AI-drivet söklandskap.
Att skapa originaldata som får AI-citat kan inte vara ett engångsprojekt—det kräver en hållbar, tvärfunktionell datastrategi där data ses som en strategisk tillgång värd löpande investering och styrning. Organisationer som lyckas med AI-synlighet implementerar strukturerade processer för kontinuerliga datauppdateringar, så att originalforskningen förblir aktuell och relevant. Detta innebär att etablera regelbundna uppdateringscykler för viktiga datamängder, uppdatera statistik när ny information kommer och upprätthålla aktualitetssignaler som AI-system använder för att bedöma källtrovärdighet. Utöver innehållsuppdateringar samordnar framgångsrika organisationer sin datastrategi över marknad, SEO, innehåll, produkt och datateam via entitetsstyrning—gemensamma definitioner och taxonomier som säkerställer konsekvent, korrekt representation av varumärke, produkter och branschbegrepp över alla kontaktpunkter.
Det mest avancerade tillvägagångssättet behandlar strukturerad data och content knowledge graphs som företagsgemensam infrastruktur. Istället för att implementera schema markup sida för sida bygger ledande organisationer omfattande content knowledge graphs som kopplar samman alla entiteter, ämnen och relationer över deras digitala tillgångar. Detta kräver teknisk kapacitet—verktyg och processer för att hantera schema markup i stor skala—och organisatorisk samsyn kring datakvalitetsstandarder. När det görs rätt fyller denna infrastruktur dubbla syften: den förbättrar extern AI-synlighet och möjliggör samtidigt interna AI-initiativ. Enligt Gartners “2024 AI Mandates for the Enterprise Survey” är datatillgänglighet och datakvalitet det största hindret för framgångsrik AI-implementering; genom att investera i strukturerad data och entitetsstyrning löser du samtidigt externa synlighetsutmaningar och intern AI-aktivering. Organisationer som vinner i AI-synlighet ser skapandet av originaldata inte som en marknadsföringstaktik utan som en grundläggande affärsförmåga, med dedikerade resurser, tydligt ansvar och löpande optimering baserat på citeringsspårning och konkurrensjämförelser.
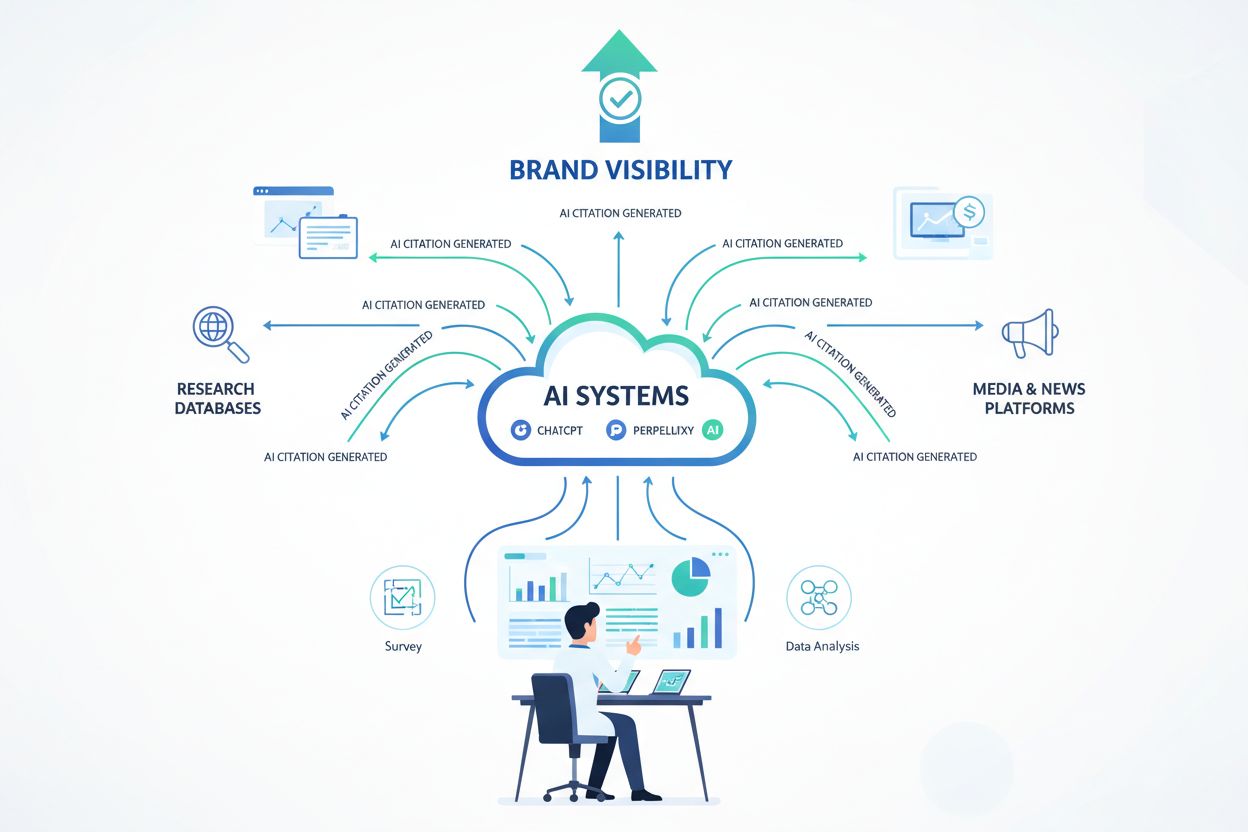
Originaldata syftar på egen forskning, unika datamängder och primära fynd som du själv har skapat eller upptäckt. AI-system prioriterar originaldata eftersom det ger auktoritativ och extraherbar information de kan citera med säkerhet. Vanligt innehåll sammanfattar ofta existerande information, vilket gör det mindre värdefullt för AI-citering. Originaldata blir grunden för AI-synlighet eftersom plattformar som Perplexity och Google Gemini aktivt söker och citerar källor som tillhandahåller unika insikter och forskning.
Olika AI-plattformar använder olika upptäcktsmekanismer. Perplexity och Google Gemini använder retrieval-augmented generation (RAG), vilket innebär att de söker på webben i realtid och kan citera ditt innehåll direkt vid publicering. ChatGPT och Claude förlitar sig mer på träningsdata, så ditt innehåll kan ta längre tid att inkluderas men ger andra synlighetsmöjligheter. Alla plattformar gynnas av strukturerad data (schema markup) som gör din data maskinläsbar och lättare att förstå, vilket ökar sannolikheten för citering på alla system.
Strukturerad data med Schema.org-vokabulär skapar ett maskinläsbart lager som AI-system kan grunda sina svar på. När du implementerar schema markup definierar du explicit entiteter (ditt företag, produkter, tjänster) och deras relationer, vilket gör det mycket enklare för AI-system att förstå och korrekt citera ditt innehåll. Forskning visar att sidor med robust schema markup får högre citeringsfrekvens i AI Overviews. Strukturerad data minskar också hallucinationer genom att ge AI-systemen tydlig, faktabaserad information att referera till.
AI-system citerar oftast originalforskning med transparent metodik, egna datamängder, branschstandarder, kundbeteendestudier, marknadsanalyser och unika insikter som konkurrenter inte kan replikera. Data i extraherbara format—tabeller, jämförelsematriser, listor och FAQ-liknande frågor och svar—får fler citat än samma information i kompakta stycken. Färsk, aktuell data med synliga publiceringsdatum och regelbundna uppdateringar prioriteras framför föråldrad information. Auktoritetssignaler som författarmeriter och organisatoriskt erkännande ökar också sannolikheten för citering.
Verktyg som AmICited.com spårar AI-citat över plattformar och visar hur ofta ditt innehåll förekommer i svar från ChatGPT, Perplexity, Google AI Overviews och Claude. Dessa verktyg mäter citeringsfrekvens (hur ofta du citeras), citeringsframhävning (position i svaret) och share-of-voice (dina citat jämfört med konkurrenter). Genom att övervaka dessa mätvärden kan du identifiera vilka innehållstyper och ämnen som genererar flest citat och sedan optimera din datastrategi därefter. Positionsviktade mätvärden erkänner att förstapositionens citat ger mer värde än lägre positioner.
Citeringsfrekvens mäter hur ofta ditt innehåll citeras i AI-svar för dina målfrågor—om du citeras i 40 % av relevanta frågor är det din citeringsfrekvens. Citeringsframhävning mäter var din citering syns i svaret—en förstaposition i Perplexitys numrerade lista ger mycket högre synlighet än en femte position. Båda mätvärdena är viktiga för AI-synlighet, men framhävning väger ofta tyngre eftersom användare oftare klickar på eller engagerar sig med tidiga citat. Effektiv optimering kräver att båda förbättras samtidigt.
Originaldata bör uppdateras regelbundet utifrån din branschs förändringstakt. För snabbt föränderliga områden som teknik eller finans kan månatliga eller kvartalsvisa uppdateringar krävas. För långsammare branscher kan årliga uppdateringar räcka. Nyckeln är att upprätthålla synliga aktualitetssignaler—publiceringsdatum, uppdateringstidsstämplar och uppdateringsindikatorer—som signalerar för AI-system att din data är aktuell och tillförlitlig. Regelbundna uppdateringar ökar också chansen att bli citerad av retrieval-baserade system som Perplexity som prioriterar färsk information. Behandla datavård som en löpande operativ uppgift, inte ett engångsprojekt.
Ja, AmICited.com innehåller konkurrensjämförelsefunktioner som visar din citeringsprestanda i förhållande till definierade konkurrenter. Du kan se vilka konkurrenter som citeras oftare, på mer framträdande positioner och på vilka AI-plattformar. Denna konkurrensinformation visar exakt var du tappar citat och vilka optimeringsstrategier som kan hjälpa dig ta igen. Genom att förstå ditt konkurrenskraftiga citeringslandskap kan du prioritera dina insatser för dataskapande och optimering mot de mest effektfulla möjligheterna, så att din originaldata får den synlighet den förtjänar.
Följ hur ofta din originaldata citeras i ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar. Få konkreta insikter för att optimera ditt innehåll för maximal AI-synlighet.
Lär dig hur du skapar originalforskning och datadrivet PR-innehåll som AI-system aktivt citerar. Upptäck de 5 egenskaperna hos innehåll värt att citera och stra...
Upptäck hur originalforskning och förstapartsdata ger 30–40 % synlighetsökning i AI-citeringar hos ChatGPT, Perplexity och Google AI Overviews.

Komplett GEO-optimeringschecklista för AI-övervakning. Utskrivbar guide för att optimera ditt innehåll för Google AI Overviews, ChatGPT och Perplexity-citat....
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.