Query Fanout
Lär dig hur Query Fanout fungerar i AI-söksystem. Upptäck hur AI utökar enskilda frågor till flera underfrågor för att förbättra svarens noggrannhet och förståe...
10 min läsning
Upptäck hur moderna AI-system som Google AI Mode och ChatGPT delar upp enskilda frågor i flera sökningar. Lär dig om query fanout-mekanismer, betydelsen för AI-synlighet och optimering av innehållsstrategi.
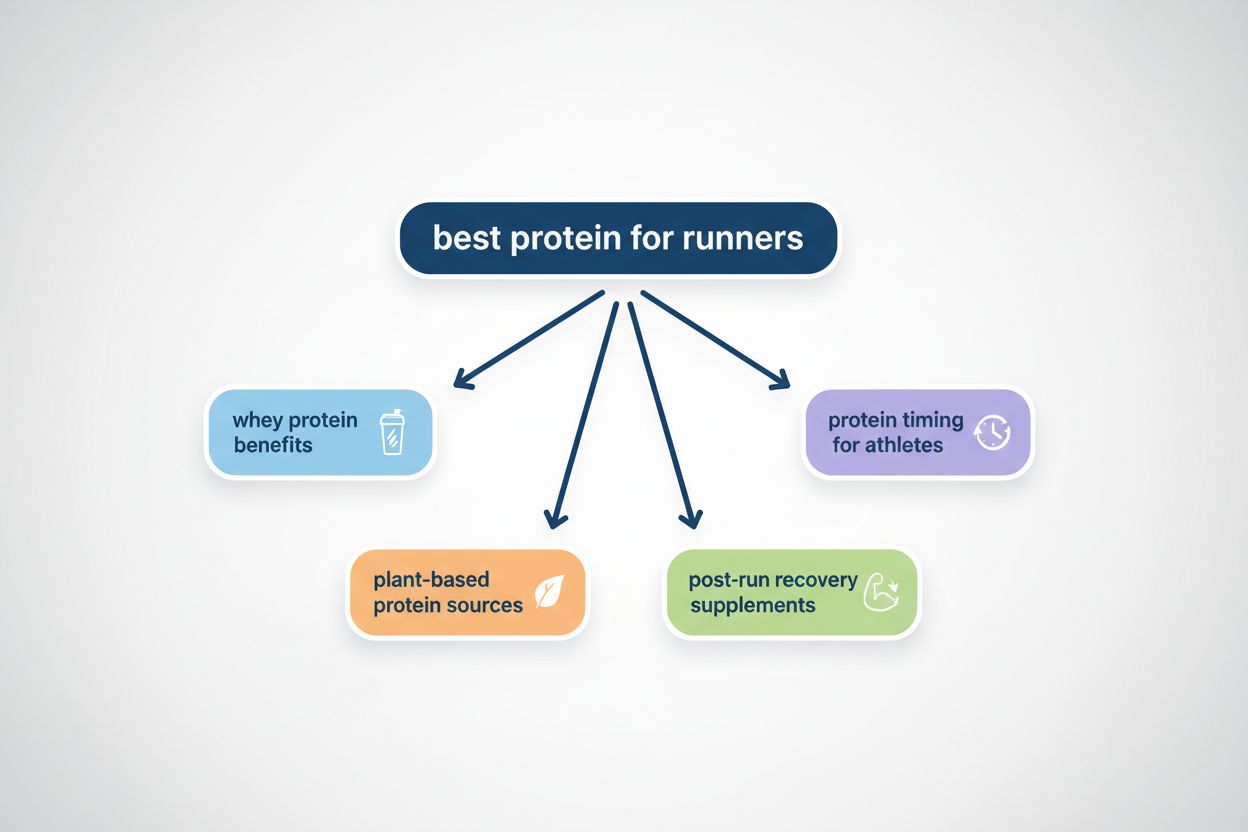
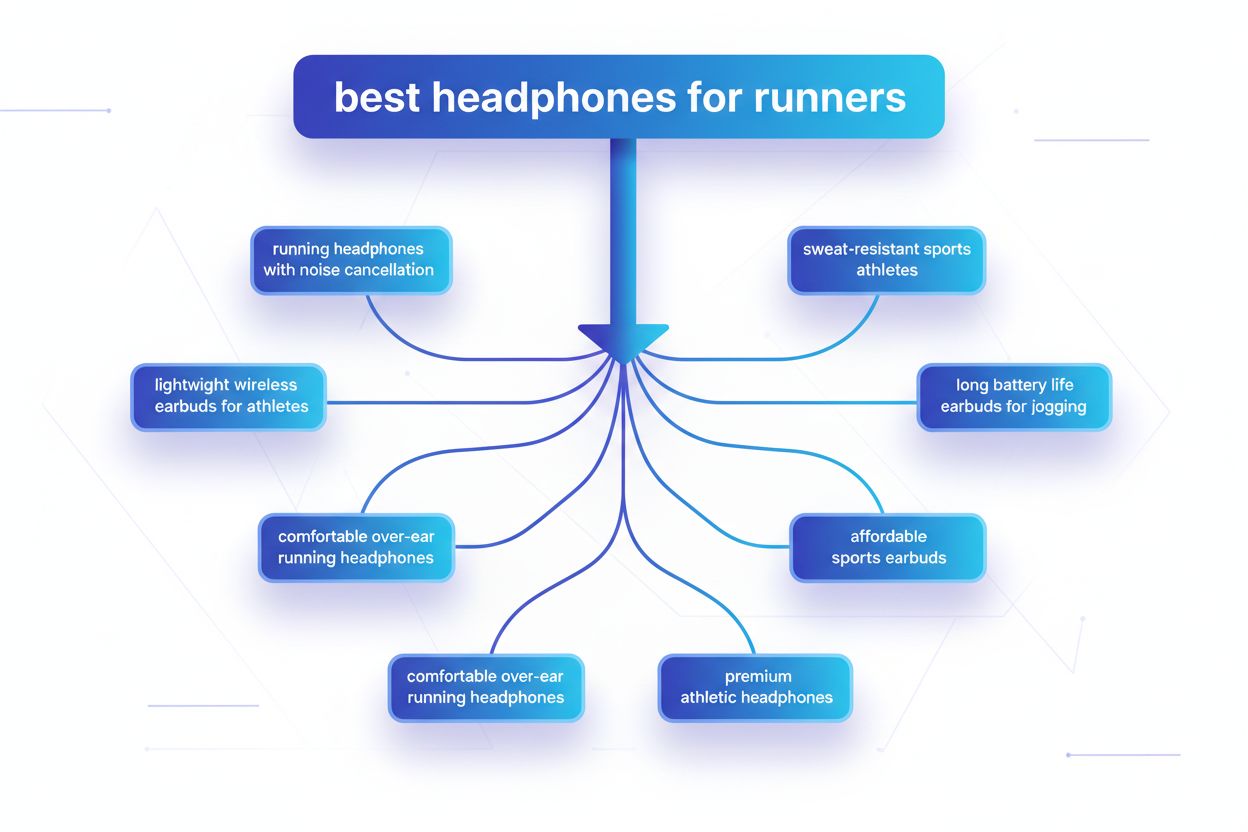
Query fanout är processen där stora språkmodeller automatiskt delar upp en enskild användarfråga i flera underfrågor för att samla in mer heltäckande information från olika källor. Istället för att utföra en enda sökning, delar moderna AI-system upp användarens avsikt i 5–15 relaterade frågor som fångar olika vinklar, tolkningar och aspekter av den ursprungliga begäran. Till exempel, när en användare söker “bästa hörlurar för löpare” i Googles AI Mode, genererar systemet cirka 8 olika sökningar med variationer som “löparhörlurar med brusreducering”, “lätta trådlösa öronsnäckor för idrottare”, “svettåliga sporthörlurar” och “öronsnäckor med lång batteritid för jogging”. Detta innebär en grundläggande skillnad från traditionell sökning, där en enda frågesträng matchas mot ett index. Nyckelelement i query fanout inkluderar:
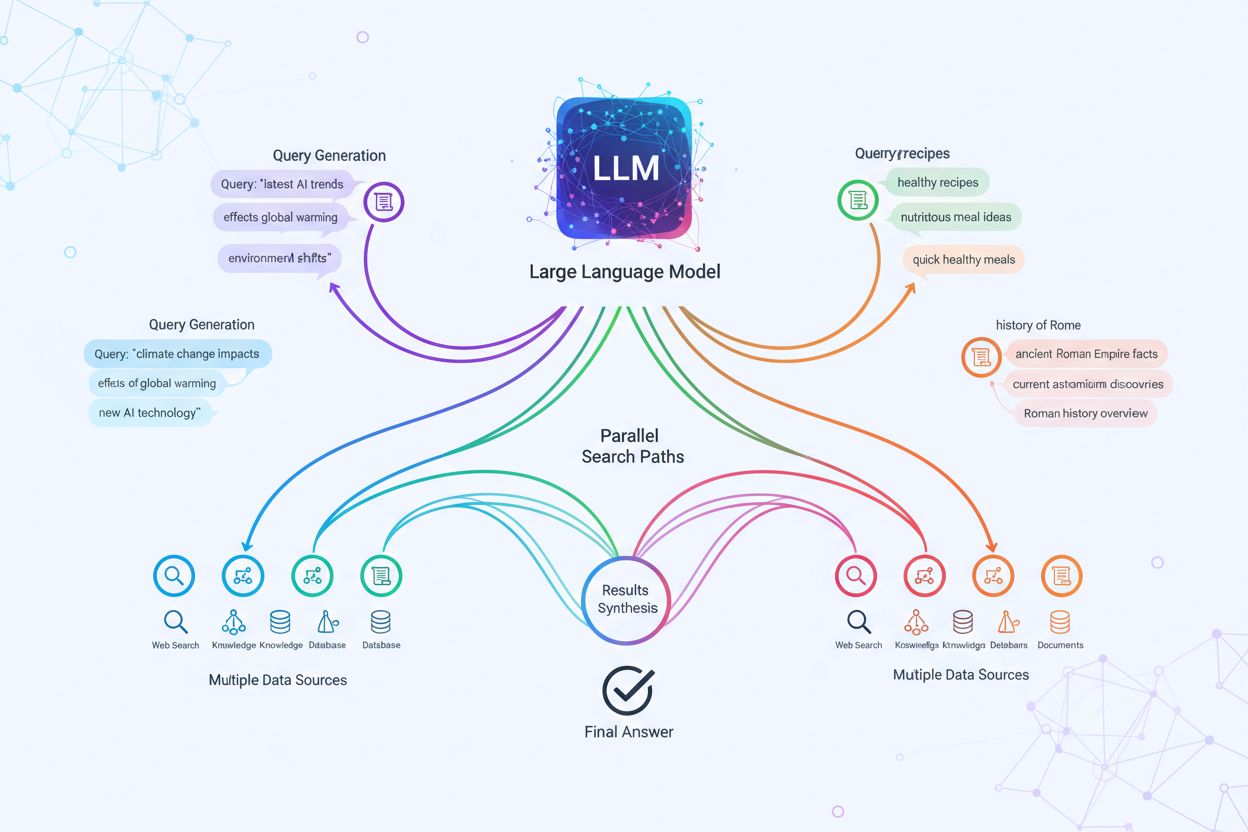
Den tekniska implementeringen av query fanout bygger på avancerade NLP-algoritmer som analyserar frågekomplexitet och genererar semantiskt meningsfulla varianter. LLM:er producerar åtta huvudsakliga typer av frågevarianter: ekvivalenta frågor (omformulering med identisk betydelse), uppföljningsfrågor (utforska relaterade ämnen), generaliseringsfrågor (bredda omfånget), specificeringsfrågor (smalna av fokus), kanoniseringsfrågor (standardisera terminologi), översättningsfrågor (översätta mellan domäner), implikationsfrågor (utforska logiska följder) och klargörandefrågor (tydliggöra tvetydiga termer). Systemet använder neurala språkmodeller för att bedöma frågekomplexitet—mäter faktorer som antal entiteter, relationsdensitet och semantisk tvetydighet—för att avgöra hur många underfrågor som ska genereras. När de genererats, körs dessa frågor parallellt över flera återhämtningssystem inklusive webbcrawlers, kunskapsgrafer (som Googles Knowledge Graph), strukturerade databaser och vektorsimilaritetsindex. Olika plattformar implementerar denna arkitektur med varierande transparens och sofistikation:
| Plattform | Mekanism | Transparens | Antal frågor | Rankningsmetod |
|---|---|---|---|---|
| Google AI Mode | Explicit fanout med synliga frågor | Hög | 8–12 frågor | Flerstegs-rankning |
| Microsoft Copilot | Iterativ Bing Orchestrator | Medel | 5–8 frågor | Relevanspoäng |
| Perplexity | Hybridåterhämtning med flerstegs-rankning | Hög | 6–10 frågor | Citeringsbaserad |
| ChatGPT | Implicit frågegenerering | Låg | Okänt | Intern viktning |
Komplexa frågor genomgår avancerad dekomposition där systemet bryter ner dem i beståndsdelar: entiteter, attribut och relationer innan varianter genereras. Vid bearbetning av en fråga som “Bluetooth-hörlurar med bekväm over-ear-design och lång batteritid för löpare”, gör systemet en entitetscentrerad analys genom att identifiera nyckelentiteter (Bluetooth-hörlurar, löpare) och extrahera viktiga attribut (bekväm, over-ear, lång batteritid). Dekompositionsprocessen utnyttjar kunskapsgrafer för att förstå hur dessa entiteter relaterar till varandra och vilka semantiska variationer som finns—till exempel att “over-ear-hörlurar” och “circumaurala hörlurar” är ekvivalenta, eller att “lång batteritid” kan betyda 8+ timmar, 24+ timmar eller flera dagars batteritid beroende på kontext. Systemet identifierar relaterade begrepp genom semantiska likhetsmått och förstår att frågor om “svettålighet” och “vattenresistens” är relaterade men distinkta, och att “löpare” även kan vara intresserade av “cyklister”, “gymbesökare” eller “utomhusidrottare”. Denna dekomposition möjliggör generering av riktade underfrågor som fångar olika aspekter av användarens avsikt istället för att bara omformulera ursprungsfrågan.
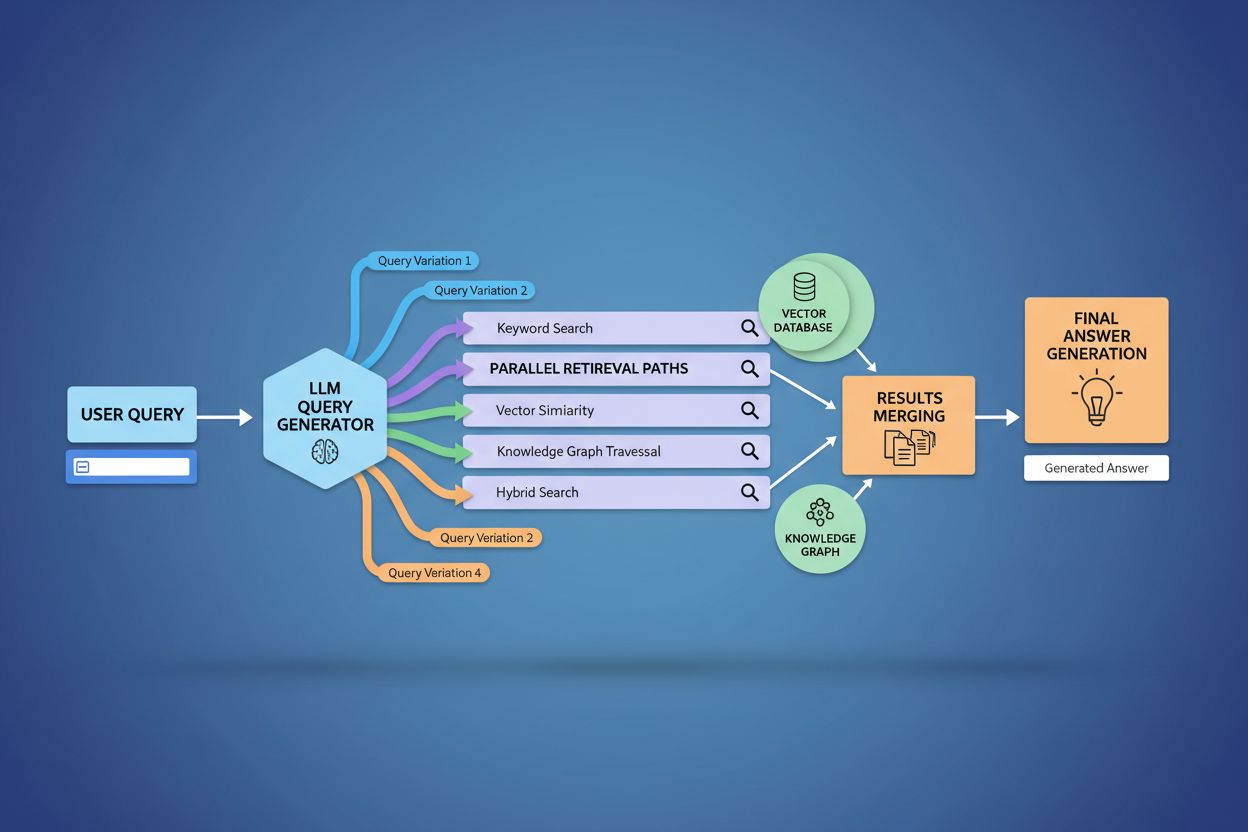
Query fanout stärker grundläggande återhämtningskomponenten i Retrieval-Augmented Generation (RAG)-ramverk genom att möjliggöra rikare och mer varierad evidensinsamling före genereringsfasen. I traditionella RAG-flöden bäddas en fråga in och matchas mot en vektordatabas, vilket riskerar att missa relevant information med annan terminologi eller konceptuell inramning. Query fanout hanterar denna begränsning genom att utföra flera återhämtningsoperationer parallellt, optimerade för specifika frågevarianter, och samlar därmed bevis från olika vinklar och källor. Denna parallella återhämtningsstrategi minskar risken för hallucinationer genom att förankra LLM-svar i flera oberoende källor—när systemet hämtar information om “over-ear-hörlurar”, “circumaurala designer” och “fullstora hörlurar” separat, kan det korskontrollera och validera påståenden över dessa olika återhämtningsresultat. Arkitekturen inkluderar semantisk chunking och passagebaserad återhämtning, där dokument delas upp i meningsfulla semantiska enheter istället för fasta längder, vilket låter systemet hämta de mest relevanta passagerna oavsett dokumentstruktur. Genom att kombinera bevis från flera underfrågeåterhämtningar genererar RAG-system svar som är mer heltäckande, bättre källbelagda och mindre benägna till de självsäkra men felaktiga svar som plågar enfrågeåterhämtning.
Användarkontext och personaliseringssignaler formar dynamiskt hur query fanout expanderar individuella förfrågningar, vilket skapar personliga återhämtningsvägar som kan skilja sig avsevärt mellan olika användare. Systemet tar hänsyn till flera personaliseringsdimensioner, inklusive användarattribut (geografisk plats, demografisk profil, yrkesroll), sökhistorikmönster (tidigare frågor och klickade resultat), tidsmässiga signaler (tid på dygnet, säsong, aktuella händelser) och uppgiftskontext (om användaren forskar, handlar eller lär sig). Till exempel expanderas en fråga om “bästa hörlurar för löpare” olika för en 22-årig ultramaratonlöpare i Kenya jämfört med en 45-årig motionslöpare i Minnesota—den första användarens expansion kan betona hållbarhet och värmetålighet medan den andra betonar komfort och tillgänglighet. Denna personalisering introducerar dock “tvåpunkts-transformationsproblemet” där systemet behandlar nuvarande frågor som varianter av historiska mönster, vilket potentiellt begränsar utforskning och förstärker befintliga preferenser. Personalisering kan oavsiktligt skapa filterbubblor där frågeexpansion systematiskt gynnar källor och perspektiv i linje med användarens tidigare beteende, vilket begränsar exponeringen för alternativa synsätt eller ny information. Att förstå dessa personaliseringsmekanismer är avgörande för innehållsskapare, eftersom samma innehåll kan eller inte kan hämtas beroende på användarens profil och historia.
Stora AI-plattformar implementerar query fanout med tydligt olika arkitekturer, transparensnivåer och strategiska angreppssätt som speglar deras underliggande infrastruktur och designfilosofier. Googles AI Mode använder explicit, synlig query fanout där användare kan se de 8–12 genererade underfrågorna som visas tillsammans med resultaten, och avfyrar hundratals individuella sökningar mot Googles index för att samla in omfattande bevis. Microsoft Copilot använder en iterativ metod via Bing Orchestrator, som genererar 5–8 frågor sekventiellt och förfinar frågesetet baserat på mellanresultat innan den slutliga återhämtningsfasen utförs. Perplexity implementerar en hybridåterhämtningsstrategi med flerstegs-rankning, genererar 6–10 frågor och kör dem mot både webbkällor och sitt eget index, och tillämpar därefter avancerade rankningsalgoritmer för att lyfta fram de mest relevanta passagerna. ChatGPT:s tillvägagångssätt är till stor del ogenomskinligt för användaren, med frågegenerering som sker implicit inom modellens interna bearbetning, vilket gör det svårt att avgöra exakt hur många frågor som genereras eller hur de körs. Dessa arkitektoniska skillnader har stor betydelse för transparens, reproducerbarhet och möjligheten för innehållsskapare att optimera för varje plattform:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Frågesynlighet | Helt synlig för användare | Delvis synlig | Synlig i citeringar | Dold |
| Körningsmodell | Parallell batch | Iterativ sekventiell | Parallell med rankning | Intern/implicit |
| Källdiversitet | Endast Google-index | Bing + eget | Webb + eget index | Träningsdata + plugins |
| Citeringstransparens | Hög | Medel | Mycket hög | Låg |
| Anpassningsmöjligheter | Begränsad | Medel | Hög | Medel |
Query fanout introducerar flera tekniska och semantiska utmaningar som kan göra att systemet avviker från användarens faktiska avsikt och hämtar tekniskt relaterad men i slutändan oanvändbar information. Semantisk drift uppstår genom generativ expansion när LLM:en skapar frågevarianter som, även om de är semantiskt relaterade till den ursprungliga, gradvis förskjuter betydelsen—en fråga om “bästa hörlurar för löpare” kan expandera till “atletiska hörlurar”, sedan “sportutrustning”, sedan “träningsprylar” och därmed gradvis röra sig bort från ursprungsavsikten. Systemet måste skilja mellan latent avsikt (vad användaren kanske vill om de visste mer) och explicit avsikt (vad de faktiskt frågade efter), och aggressiv frågeexpansion kan blanda ihop dessa kategorier och hämta information om produkter användaren aldrig tänkt på. Iterativ expansionsavvikelse uppstår när varje genererad fråga ger upphov till fler underfrågor, vilket skapar ett förgrenat träd av alltmer perifera sökningar som tillsammans hämtar information långt ifrån den ursprungliga frågan. Filterbubblor och personaliseringsbias gör att två användare som ställer identiska frågor får systematiskt olika frågeexpansioner baserat på sina profiler, vilket kan skapa ekokammare där expansionen förstärker befintliga preferenser. I verkliga scenarier syns dessa fallgropar: en användare som söker “prisvärda hörlurar” kan få sin fråga expanderad till att omfatta lyxmärken baserat på sin webbhistorik, eller en fråga om “hörlurar för hörselskadade” kan expanderas till att gälla allmänna tillgänglighetsprodukter, vilket urvattnar ursprungsavsiktens specifika karaktär.
Framväxten av query fanout innebär en grundläggande förskjutning i innehållsstrategi från nyckelordsoptimering mot citeringsbaserad synlighet, vilket kräver att innehållsskapare omprövar hur de strukturerar och presenterar information. Traditionell SEO fokuserade på att ranka för specifika nyckelord; AI-driven sökning prioriterar att bli citerad som auktoritativ källa över flera frågevarianter och kontext. Innehållsskapare bör använda atomära, entitetsrika innehållsstrategier där information struktureras kring specifika entiteter (produkter, begrepp, personer) med rik semantisk markup som gör det möjligt för AI-system att extrahera och citera relevanta passager. Ämnesklustring och tematisk auktoritet blir allt viktigare—istället för isolerade artiklar om enskilda nyckelord, etablerar framgångsrikt innehåll heltäckande täckning av ämnesområden, vilket ökar chansen att bli hämtad över de olika frågevarianter som fanout genererar. Schema-markup och strukturerad data gör att AI-system kan förstå innehållsstruktur och extrahera relevant information mer effektivt, vilket ökar sannolikheten för citering. Framgångsmått skiftar från att följa nyckelordsrankningar till att övervaka citeringsfrekvens via verktyg som AmICited.com, som spårar hur ofta varumärken och innehåll förekommer i AI-genererade svar. Praktiska rekommendationer innefattar: skapa heltäckande, välunderbyggt innehåll som täcker flera vinklar av ett ämne; implementera rik schema-markup (Organization, Product, Article-scheman); bygg tematisk auktoritet genom sammanlänkat innehåll; och granska regelbundet hur ditt innehåll syns i AI-svar över olika plattformar och användarsegment.
Query fanout är den mest betydelsefulla arkitektoniska förändringen inom sök sedan mobil-först-indexering, och omstrukturerar i grunden hur information upptäcks och presenteras för användare. Utvecklingen mot semantisk infrastruktur innebär att söksystem alltmer kommer att arbeta med betydelse snarare än nyckelord, med query fanout som standardmekanism för informationshämtning snarare än en valfri förbättring. Citeringsmått blir lika viktiga som bakåtlänkar för att avgöra innehållets synlighet och auktoritet—ett innehåll som citeras i 50 olika AI-svar väger tyngre än innehåll som rankar etta på ett enskilt nyckelord. Denna förändring skapar både utmaningar och möjligheter: traditionella SEO-verktyg som följer nyckelordsrankningar blir mindre relevanta, vilket kräver nya mätmetoder fokuserade på citeringsfrekvens, källdiversitet och synlighet över olika frågevarianter. Men utvecklingen skapar också möjligheter för varumärken att optimera specifikt för AI-sök genom att bygga auktoritativt, välstrukturerat innehåll som fungerar som en pålitlig källa över flera frågeinterpretationer. Framtiden innebär sannolikt ökad transparens kring query fanout-mekanismer, där plattformar konkurrerar om hur tydligt de visar användaren resonemanget bakom sitt multi-query-tillvägagångssätt, och innehållsskapare utvecklar specialiserade strategier för att maximera synligheten över de olika återhämtningsvägar som fanout skapar.
Query fanout är den automatiserade processen där AI-system delar upp en enskild användarfråga i flera underfrågor och utför dem parallellt, medan query expansion traditionellt syftar till att lägga till relaterade termer till en fråga. Query fanout är mer sofistikerad och genererar semantiskt varierade varianter som fångar olika vinklar och tolkningar av den ursprungliga avsikten.
Query fanout påverkar synligheten avsevärt eftersom ditt innehåll måste vara upptäckbart över flera frågevarianter, inte bara den exakta användarfrågan. Innehåll som tar upp olika vinklar, använder varierad terminologi och är välstrukturerat med schema-markup har större chans att bli hämtat och citerat över de olika underfrågor som genereras av fanout.
Alla stora AI-sökplattformar använder query fanout-mekanismer: Google AI Mode använder explicit, synlig fanout (8–12 frågor); Microsoft Copilot använder iterativ fanout via Bing Orchestrator; Perplexity implementerar hybridåterhämtning med flerstegs-rankning; och ChatGPT använder implicit frågegenerering. Varje plattform implementerar det på olika sätt men alla delar upp komplexa frågor i flera sökningar.
Ja. Optimera genom att skapa atomärt, entitetsrikt innehåll strukturerat kring specifika begrepp; implementera omfattande schema-markup; bygga tematisk auktoritet genom sammankopplat innehåll; använda tydlig, varierad terminologi; och ta upp flera vinklar av ett ämne. Verktyg som AmICited.com hjälper dig att övervaka hur ditt innehåll visas över olika frågedekompositioner.
Query fanout ökar fördröjningen eftersom flera frågor körs parallellt, men moderna system mildrar detta genom parallell bearbetning. Medan en enskild fråga kan ta 200 ms, lägger utförandet av 8 frågor parallellt vanligtvis bara till 300–500 ms total fördröjning tack vare samtidig körning. Avvägningen är värd det för förbättrad svarskvalitet.
Query fanout stärker Retrieval-Augmented Generation (RAG) genom att möjliggöra rikare evidensinsamling. Istället för att hämta dokument för en fråga, hämtar fanout bevis för flera frågevarianter parallellt och ger LLM:en mer varierad, omfattande kontext för att generera korrekta svar samt minskar risken för hallucinationer.
Personalisering formar hur frågor delas upp baserat på användarattribut (plats, historik, demografi), tidsmässiga signaler och uppgiftskontext. Samma fråga expanderas olika för olika användare och skapar personliga återhämtningsvägar. Detta kan förbättra relevansen men skapar också filterbubblor där användare systematiskt ser olika resultat baserat på sina profiler.
Query fanout är den största förändringen inom sök sedan mobil-först-indexering. Traditionella nyckelordsrankningsmått blir mindre relevanta då samma fråga expanderas olika för olika användare. SEO-proffs måste flytta fokus från nyckelordsrankningar till citeringsbaserad synlighet, innehållsstruktur och entitetsoptimering för att lyckas i AI-driven sökning.
Förstå hur ditt varumärke syns över AI-sökplattformar när frågor expanderas och delas upp. Spåra citeringar och omnämnanden i AI-genererade svar.
Lär dig hur Query Fanout fungerar i AI-söksystem. Upptäck hur AI utökar enskilda frågor till flera underfrågor för att förbättra svarens noggrannhet och förståe...
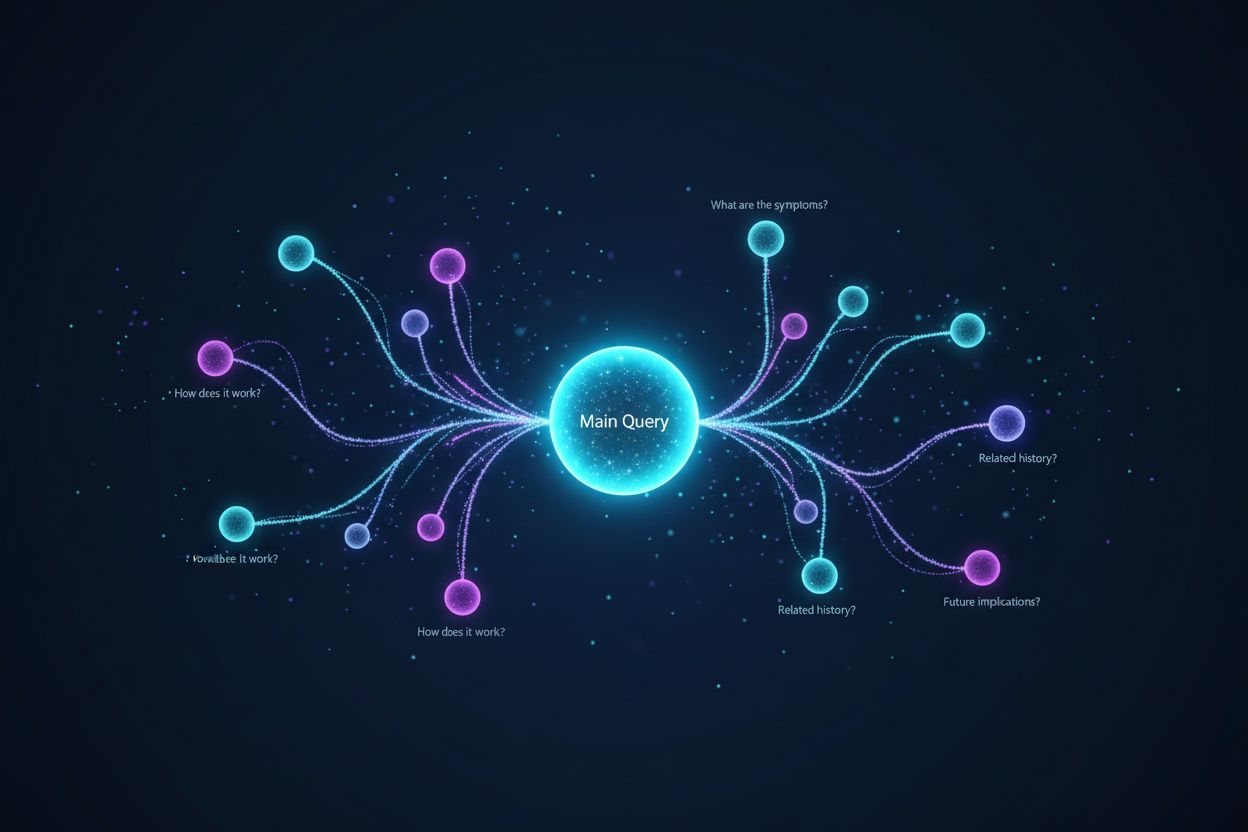
Lär dig hur Förutseende av Frågor hjälper ditt innehåll att fånga utökade AI-konversationer genom att ta upp uppföljande frågor. Upptäck strategier för att iden...
Frågebaserad sökning är naturliga språkfrågor formulerade som frågor. Lär dig hur detta skifte påverkar AI-övervakning, varumärkesexponering och modern SEO-stra...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.