Hur får jag produkter rekommenderade av AI?
Lär dig hur AI-produktrekommendationer fungerar, algoritmerna bakom dem och hur du optimerar din synlighet i AI-drivna rekommendationssystem över ChatGPT, Perpl...
8 min läsning
Maskininlärningssystem som analyserar användarbeteende och preferenser för att leverera personliga produkt- och innehållsförslag. Dessa system använder algoritmer som kollaborativ filtrering och innehållsbaserad filtrering för att förutse vad användare kan vara intresserade av, vilket gör det möjligt för företag att öka engagemang, försäljning och kundnöjdhet genom skräddarsydda rekommendationer.
Maskininlärningssystem som analyserar användarbeteende och preferenser för att leverera personliga produkt- och innehållsförslag. Dessa system använder algoritmer som kollaborativ filtrering och innehållsbaserad filtrering för att förutse vad användare kan vara intresserade av, vilket gör det möjligt för företag att öka engagemang, försäljning och kundnöjdhet genom skräddarsydda rekommendationer.
AI-drivna rekommendationer representerar en avancerad teknik som använder maskininlärningsalgoritmer för att analysera användarbeteende och preferenser, vilket ger personliga förslag anpassade efter individuella behov och intressen. En rekommendationsmotor är kärnkomponenten i detta system och fungerar som en intelligent mellanhand mellan stora produktkataloger och enskilda användare, vilket möjliggör enastående nivåer av personalisering i stor skala. Den globala marknaden för rekommendationsmotorer har haft explosiv tillväxt, värderad till cirka 2,8 miljarder dollar 2023 och beräknas nå 8,5 miljarder dollar till 2030, vilket speglar denna tekniks avgörande betydelse i den digitala ekonomin. Dessa AI-drivna rekommendationer har blivit oumbärliga inom många branscher, med framträdande användning i e-handelsplattformar som Amazon och eBay, streamingtjänster som Netflix och Spotify, sociala medienätverk och innehållsplattformar. Den grundläggande principen bakom dessa system är att maskininlärningsalgoritmer kan identifiera mönster i användarbeteende som människor inte enkelt kan upptäcka, vilket gör det möjligt för företag att förutse kundbehov innan användarna själva inser dem. Genom att utnyttja stora datamängder och beräkningskraft har rekommendationssystem förändrat hur konsumenter upptäcker produkter, innehåll och tjänster och grundläggande omformat strategier för kundengagemang inom olika branscher.

AI-drivna rekommendationssystem arbetar genom en sofistikerad femstegsprocess som omvandlar rå användardata till handlingsbara personliga förslag. Den första fasen innebär omfattande datainsamling där system samlar in information från flera kontaktpunkter, inklusive användarinteraktioner, surfhistorik, köphistorik och explicita feedbackmekanismer. Under analysfasen bearbetar systemet den insamlade datan för att identifiera meningsfulla mönster och samband, och använder maskininlärningsalgoritmer som kollaborativ filtrering, innehållsbaserad filtrering och neurala nätverk för att extrahera insikter ur komplexa datamängder. Mönsterigenkänningsfasen utgör den beräkningsmässiga kärnan i systemet, där algoritmer identifierar likheter mellan användare, objekt eller båda, och skapar matematiska representationer av preferenser och objektegenskaper. I förutsägelsefasen används dessa identifierade mönster för att förutspå vilka objekt en användare sannolikt kommer att interagera med, och tilldela förtroendepoäng till potentiella rekommendationer. Slutligen presenteras dessa förutsägelser för användarna genom personliga gränssnitt, vilket säkerställer att rekommendationerna visas vid optimala tillfällen under användarresan. Realtidsbehandling har blivit allt viktigare, och moderna system uppdaterar rekommendationer omedelbart när ny användardata kommer in, vilket möjliggör dynamisk personalisering som anpassas till förändrade preferenser. Avancerade rekommendationssystem använder ensemblemetoder som kombinerar flera algoritmer samtidigt, där varje algoritm bidrar med sina förutsägelser för att skapa robustare och mer exakta rekommendationer än någon enskild metod skulle kunna åstadkomma på egen hand.
Rekommendationssystem förlitar sig på två distinkta kategorier av användardata, som var och en ger unika insikter om preferenser och beteendemönster:
Explicit data:
Implicit data:
Explicit data ger direkta och otvetydiga signaler om användarpreferenser men är ofta gles, då de flesta användare endast betygsätter en liten andel av alla tillgängliga objekt. Implicit data är däremot riklig och genereras kontinuerligt genom normala användarinteraktioner, men kräver sofistikerad tolkning eftersom exempelvis att titta på en produkt inte nödvändigtvis indikerar preferens. De mest effektiva rekommendationssystemen integrerar båda datatyperna och använder explicit feedback för att validera och kalibrera implicita signaler, vilket skapar omfattande användarprofiler som fångar både uttalade och uppvisade preferenser.
Kollaborativ filtrering är en av de grundläggande metoderna inom rekommendationssystem och bygger på principen att användare med liknande preferenser historiskt sannolikt kommer att uppskatta liknande objekt i framtiden. Denna metod analyserar mönster i hela användarpopulationen för att identifiera gemensamheter och skiljer sig därmed från metoder som undersöker enskilda objekts egenskaper. Användarbaserad kollaborativ filtrering identifierar användare med liknande preferenshistorik som målanvändaren och rekommenderar sedan objekt som dessa liknande användare har uppskattat men som målanvändaren ännu inte har stött på, vilket i praktiken utnyttjar visdomen från likasinnade. Objektbaserad kollaborativ filtrering fokuserar istället på objektslikheter och rekommenderar produkter som liknar sådana användaren tidigare har gett höga betyg, baserat på hur andra användare har betygsatt dessa objekt i relation till varandra. Båda metoderna använder sofistikerade likhetsmått såsom kosinuslikhet, Pearson-korrelation eller Euklidiskt avstånd för att kvantifiera hur nära användare eller objekt påminner om varandra i preferensrymden. Kollaborativ filtrering erbjuder stora fördelar, bland annat möjligheten att rekommendera objekt utan innehållsmetadata och att upptäcka oväntade rekommendationer som användaren inte själv hade förväntat sig. Dock har metoden begränsningar, särskilt “cold start-problemet” där nya användare eller objekt saknar tillräcklig historisk data för exakta likhetsberäkningar, samt glesa data i domäner med miljontals objekt där de flesta användar-objekt-interaktioner är okända.
Innehållsbaserad filtrering gör rekommendationer genom att analysera objektens inneboende egenskaper och rekommenderar produkter som liknar de användaren tidigare har uppskattat, baserat på mätbara attribut. Istället för att förlita sig på kollektiva användarmönster, bygger innehållsbaserade system detaljerade objektprofiler som omfattar relevanta egenskaper såsom genre, regissör och skådespelare för filmer; författare, ämne och publiceringsdatum för böcker; eller produktkategori, varumärke och specifikationer för e-handelsprodukter. Systemet beräknar likhet mellan objekt genom att jämföra deras featurevektorer med matematiska tekniker såsom kosinuslikhet eller Euklidiskt avstånd, vilket ger ett kvantitativt mått på hur nära objekt liknar varandra i feature-rymden. När en användare betygsätter eller interagerar med ett objekt identifierar systemet andra objekt med liknande egenskapsprofiler och rekommenderar dessa alternativ, vilket effektivt personaliserar förslag baserat på visade preferenser för specifika objektegenskaper. Innehållsbaserad filtrering är utmärkt när objektmetadata är riklig och välstrukturerad, och systemet hanterar naturligt kallstart-problemet för nya objekt eftersom rekommendationer baseras på objektens egenskaper, inte på historiska användarinteraktioner. Dock har denna metod begränsningar vad gäller oväntade upptäckter, då den tenderar att rekommendera objekt som är mycket lika tidigare preferenser, vilket kan skapa filterbubblor som begränsar användaren till smala kategorier. Jämfört med kollaborativ filtrering kräver innehållsbaserade system explicit feature engineering och har svårt med objekt utan tydliga kategorigränser, men de ger överlägsen transparens eftersom rekommendationer kan förklaras med hänvisning till specifika objektegenskaper.
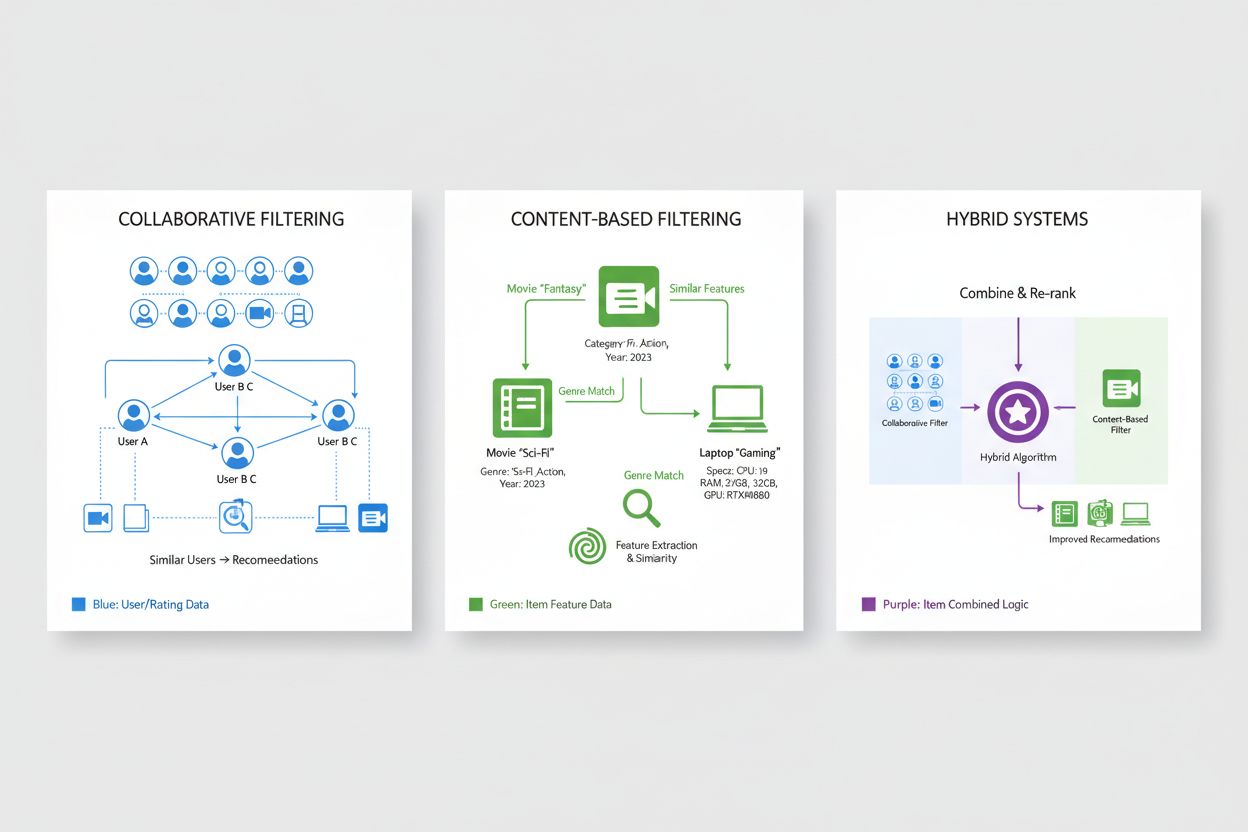
Hybrida rekommendationssystem kombinerar strategiskt kollaborativ filtrering och innehållsbaserad filtrering och utnyttjar de kompletterande styrkorna hos varje metod för att övervinna individuella begränsningar och leverera överlägsen rekommendationsnoggrannhet. Dessa system använder olika integrationsstrategier, inklusive viktningskombinationer där förutsägelser från flera algoritmer slås samman med förutbestämda eller inlärda vikter, omkopplingsmekanismer som väljer den mest lämpliga algoritmen baserat på kontextuella faktorer, eller kaskadmetoder där en algoritms utdata används som indata till en annan. Genom att integrera kollaborativ filtrerings förmåga att identifiera oväntade rekommendationer och fånga komplexa preferensmönster med innehållsbaserad filtrerings kapacitet att hantera nya objekt och ge förklaringsbara rekommendationer, uppnår hybrida system mer robust prestanda i olika scenarier. Stora teknikföretag har antagit hybrida metoder som branschstandard; Netflix kombinerar kollaborativ filtrering med innehållsbaserade metoder och kontextuell information för att leverera rekommendationer som balanserar popularitet, personalisering och nyhet. Spotifys rekommendationsmotor använder på liknande sätt hybrida tekniker, där kollaborativ filtrering baserat på lyssningsmönster kombineras med innehållsbaserad analys av ljudegenskaper och metadata, kompletterat med NLP av användargenererade spellistor och recensioner. Fördelarna med hybrida system sträcker sig bortom förbättrad noggrannhet och omfattar ökad täckning av produktkatalogen, bättre hantering av gles data och förbättrad motståndskraft mot vanliga utmaningar inom rekommendationer. Dessa system utgör det nuvarande spetskompetensen inom personaliseringsteknik, och de flesta rekommendationsplattformar i företagsklass använder hybrida arkitekturer som kontinuerligt utvecklas i takt med att nya algoritmiska innovationer introduceras.
AI-drivna rekommendationer har blivit centrala i affärsmodellerna för stora teknik- och detaljhandelsföretag och har grundläggande förändrat hur kunder upptäcker och köper produkter. Amazon, pionjären inom e-handel, genererar cirka 35 % av sin totala omsättning via rekommendationsdrivna köp, där deras sofistikerade system analyserar surfhistorik, köpmönster, produktbetyg och liknande kundbeteenden för att föreslå objekt vid avgörande beslutsögonblick under shoppingresan. Netflix bearbetar visningshistorik, betyg, sökbeteende och tidsmönster för att föreslå innehåll, och företaget rapporterar att personliga rekommendationer står för cirka 80 % av timmarna som ses på plattformen, vilket visar den djupa påverkan effektiv personalisering har på användarengagemang och lojalitet. Spotify använder AI-drivna rekommendationer på flera ytor, inklusive funktionen “Discover Weekly”-spellista, som kombinerar kollaborativ filtrering med analys av ljudegenskaper och kontextuell information för att skapa mycket personliga musiktips som är avgörande för användarengagemang och abonnemangslojalitet. Temu, den snabbt växande e-handelsplattformen, använder avancerade rekommendationssystem som analyserar användarbeteendemönster, sökningar och köphistorik för att lyfta fram produkter som matchar individuella preferenser, vilket bidrar kraftigt till dess snabba tillväxt och höga användarengagemang. Dessa exempel visar att rekommendationssystem har direkt påverkan på nyckeltal som kundlivstidsvärde, återköpsfrekvens och användarengagemang, och företag satsar stort på rekommendationsteknik som en kärndifferentiering i alltmer konkurrensutsatta digitala marknader.
AI-drivna rekommendationer ger betydande värde för både företag och användare och skapar ett ömsesidigt fördelaktigt ekosystem som ökar engagemang och nöjdhet:
Affärsfördelar:
Användarfördelar:
Den sammantagna effekten av dessa fördelar har gjort rekommendationssystem till en oumbärlig infrastruktur för digital handel och innehållsplattformar, och användare förväntar sig i allt högre grad personliga upplevelser som en grundläggande funktion snarare än ett premiuminslag.
Trots sin utbredda framgång står AI-drivna rekommendationssystem inför betydande utmaningar som forskare och branschaktörer kontinuerligt arbetar med att lösa. Integritetsfrågor har blivit allt mer centrala i takt med att regelverk som GDPR och CCPA ställer hårda krav på datainsamling och användning, vilket tvingar företag att balansera effektiv personalisering med användarnas rätt till integritet och dataskydd. Cold start-problemet är särskilt påtagligt för nya användare och objekt, där otillräcklig historik förhindrar exakta rekommendationer och kräver hybrida metoder eller alternativa strategier för att starta personaliseringen. Algoritmisk partiskhet är en kritisk utmaning, då rekommendationssystem kan förstärka befintliga snedvridningar i träningsdatan, vilket kan leda till diskriminering mot vissa grupper eller skapa filterbubblor som begränsar exponering för olika perspektiv och innehåll.
Framväxande trender omformar rekommendationslandskapet, där realtidsanpassning blir alltmer sofistikerad tack vare edge computing och strömmande databehandling som möjliggör omedelbar anpassning till användarbeteende. Multimodal dataintegration utvidgas bortom traditionella beteendesignaler till att inkludera visuella egenskaper, ljudkaraktäristik, textinnehåll och kontextuell information, vilket ger en rikare och mer nyanserad förståelse av användarpreferenser. Känslostyrda rekommendationer är ett nytt område inom personalisering, där systemen börjar inkludera känslomässig kontext och sentimentanalys för att ge rekommendationer som är anpassade inte bara till historiska preferenser utan även till aktuella känslolägen och behov. Framtida utveckling kommer sannolikt att betona förklaringsbarhet och transparens, så att användaren kan förstå varför vissa rekommendationer visas och ges möjlighet att själva påverka sin rekommendationsprofil. Sammantaget antyder dessa trender att nästa generations rekommendationssystem blir mer integritetsmedvetna, transparenta, känslomässigt intelligenta och kapabla att leverera verkligt transformerande personaliseringsupplevelser samtidigt som de respekterar användarens självbestämmande och datarättigheter.
AI-drivna rekommendationer föreslår proaktivt objekt baserat på användarbeteende och preferenser utan att kräva explicita sökningar, medan traditionell sökning kräver att användaren aktivt söker efter produkter. Rekommendationer använder maskininlärning för att förutse intressen, medan sökning förlitar sig på nyckelords-matchning. Rekommendationer är personligt anpassade för individuella användare, medan sökresultaten vanligtvis är mer generella. Moderna system kombinerar ofta båda metoderna för optimal användarupplevelse.
Nya användare stöter på 'cold start-problemet' där systemen saknar historisk data för exakta rekommendationer. Lösningar inkluderar att använda demografisk information, visa populära objekt, använda innehållsbaserad filtrering baserat på objektens egenskaper eller begära explicita preferenser. Hybrida system kombinerar flera metoder för att starta rekommendationer för nya användare. Vissa plattformar använder kollaborativ filtrering med liknande användarprofiler eller kontextuell information såsom enhetstyp och plats för att göra initiala förslag.
Rekommendationssystem samlar in explicit data som betygsättningar, recensioner och användarfeedback, samt implicit data som surfhistorik, köphistorik, tid spenderad på objekt, sökningar och klickmönster. De kan även samla in kontextuell information såsom enhetstyp, plats, tid på dygnet och säsongsfaktorer. Avancerade system integrerar demografisk data, sociala kopplingar och beteendesignaler. All datainsamling måste följa integritetslagar som GDPR och CCPA, vilket kräver användarens samtycke och tydliga riktlinjer för dataanvändning.
Ja, rekommendationssystem kan upprätthålla och förstärka partiskheter som finns i träningsdatan, vilket kan leda till diskriminering mot vissa användargrupper eller begränsa exponering för varierat innehåll. Algoritmisk partiskhet kan uppstå av snedvriden historisk data, underrepresentation av minoritetsgrupper eller återkopplingsslingor som förstärker befintliga mönster. För att motverka partiskhet krävs diversifierad träningsdata, regelbundna granskningar, rättvisemått och transparens i algoritmdesignen. Företag måste aktivt övervaka och implementera åtgärder för att säkerställa rättvisa rekommendationer för alla användargrupper.
Hybrida system kombinerar kollaborativ filtrerings förmåga att identifiera oväntade rekommendationer med innehållsbaserad filtrerings kapacitet att hantera nya objekt och ge förklaringsbara förslag. Denna kombination övervinner individuella begränsningar: kollaborativ filtrering har svårt med nya objekt medan innehållsbaserad filtrering saknar oväntade upptäckter. Hybrida metoder använder viktningskombinationer, omkopplingsmekanismer eller kaskadmetoder för att utnyttja varje algoritms styrkor. Resultatet blir ökad noggrannhet, bättre täckning av produktkatalogen, förbättrad hantering av gles data och mer robust prestanda i olika scenarier.
Integritetsproblem inkluderar omfattande datainsamling som krävs för noggranna rekommendationer, potentiell otillåten användning av data, risk för dataintrång och utmaningar med att följa lagar som GDPR, CCPA och liknande. Användare kan känna obehag med den omfattande beteendespårning som krävs för personalisering. Företag måste implementera stark datasäkerhet, inhämta explicit samtycke, vara transparenta om dataanvändning och ge användare kontroll över sin data. Att balansera effektiv personalisering med integritetsskydd är en ständigt pågående utmaning i branschen.
Realtidsrekommendationer bearbetar användarbeteendedata omedelbart när det uppstår, och uppdaterar förslag baserat på aktuella interaktioner. Systemen använder strömmande databehandling och edge computing för att analysera handlingar som klick, visningar eller köp inom millisekunder. Detta möjliggör dynamisk personalisering som anpassas till förändrade preferenser under en användarsession. Realtidssystem kräver robust infrastruktur, effektiva algoritmer och datakanaler med låg fördröjning. Exempel inkluderar att Netflix uppdaterar rekommendationer medan du bläddrar, eller att Amazon visar nya förslag när du lägger till varor i kundvagnen.
Framtida trender inkluderar känslostyrda rekommendationer som tar hänsyn till användarens emotionella tillstånd, multimodal dataintegration som kombinerar visuella, ljud- och textbaserade data, förbättrade integritetsskyddstekniker, ökad förklaringsbarhet och transparens samt realtidsanpassning i stor skala. Framväxande tekniker som federerad inlärning möjliggör rekommendationer utan centraliserad användardata. Systemen blir mer kontextmedvetna och inkluderar tidsmässiga och situationsbaserade faktorer. Sammantaget kommer dessa trender leda till mer sofistikerad, transparent och integritetsmedveten personalisering som respekterar användarens självbestämmande och datarättigheter.
AmICited spårar hur AI-system som ChatGPT, Perplexity och Google AI Overviews nämner ditt varumärke i personliga rekommendationer och AI-genererat innehåll. Håll dig informerad om ditt varumärkes synlighet i AI-drivna system.
Lär dig hur AI-produktrekommendationer fungerar, algoritmerna bakom dem och hur du optimerar din synlighet i AI-drivna rekommendationssystem över ChatGPT, Perpl...
Upptäck hur prisomnämnanden påverkar AI-rekommendationer hos ChatGPT, Perplexity, Google AI Overviews och Claude. Lär dig citeringsmönster och optimeringsstrate...
Diskussion i communityn om sponsrat innehåll och annonsering i AI-sök. Användare och marknadsförare diskuterar mönster i ChatGPT, Perplexity och Google AI Overv...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.