AI-innehållspoäng
Lär dig vad en AI-innehållspoäng är, hur den utvärderar innehållets kvalitet för AI-system och varför det är viktigt för synlighet i ChatGPT, Perplexity och and...
10 min läsning

AI-hämtningens poängsättning är processen att kvantifiera relevans och kvalitet för hämtade dokument eller avsnitt i förhållande till en användarfråga. Den använder sofistikerade algoritmer för att utvärdera semantisk innebörd, kontextuell lämplighet och informationskvalitet, och avgör vilka källor som skickas vidare till språkmodeller för svarsgenerering i RAG-system.
AI-hämtningens poängsättning är processen att kvantifiera relevans och kvalitet för hämtade dokument eller avsnitt i förhållande till en användarfråga. Den använder sofistikerade algoritmer för att utvärdera semantisk innebörd, kontextuell lämplighet och informationskvalitet, och avgör vilka källor som skickas vidare till språkmodeller för svarsgenerering i RAG-system.
AI-hämtningens poängsättning är processen att kvantifiera relevans och kvalitet för hämtade dokument eller avsnitt i förhållande till en användarfråga eller uppgift. Till skillnad från enkel nyckelordsmatchning, som endast identifierar överlappning på ytnivå, använder poängsättningen sofistikerade algoritmer för att utvärdera semantisk innebörd, kontextuell lämplighet och informationskvalitet. Denna poängsättningsmekanism är grundläggande för Retrieval-Augmented Generation (RAG)-system, där den avgör vilka källor som skickas vidare till språkmodeller för svarsgenerering. I moderna LLM-applikationer påverkar hämtningens poängsättning direkt svarens noggrannhet, minskar hallucinationer och ökar användarnöjdheten genom att säkerställa att endast den mest relevanta informationen når genereringssteget. Kvaliteten på poängsättningen är därför en avgörande komponent för systemets övergripande prestanda och tillförlitlighet.
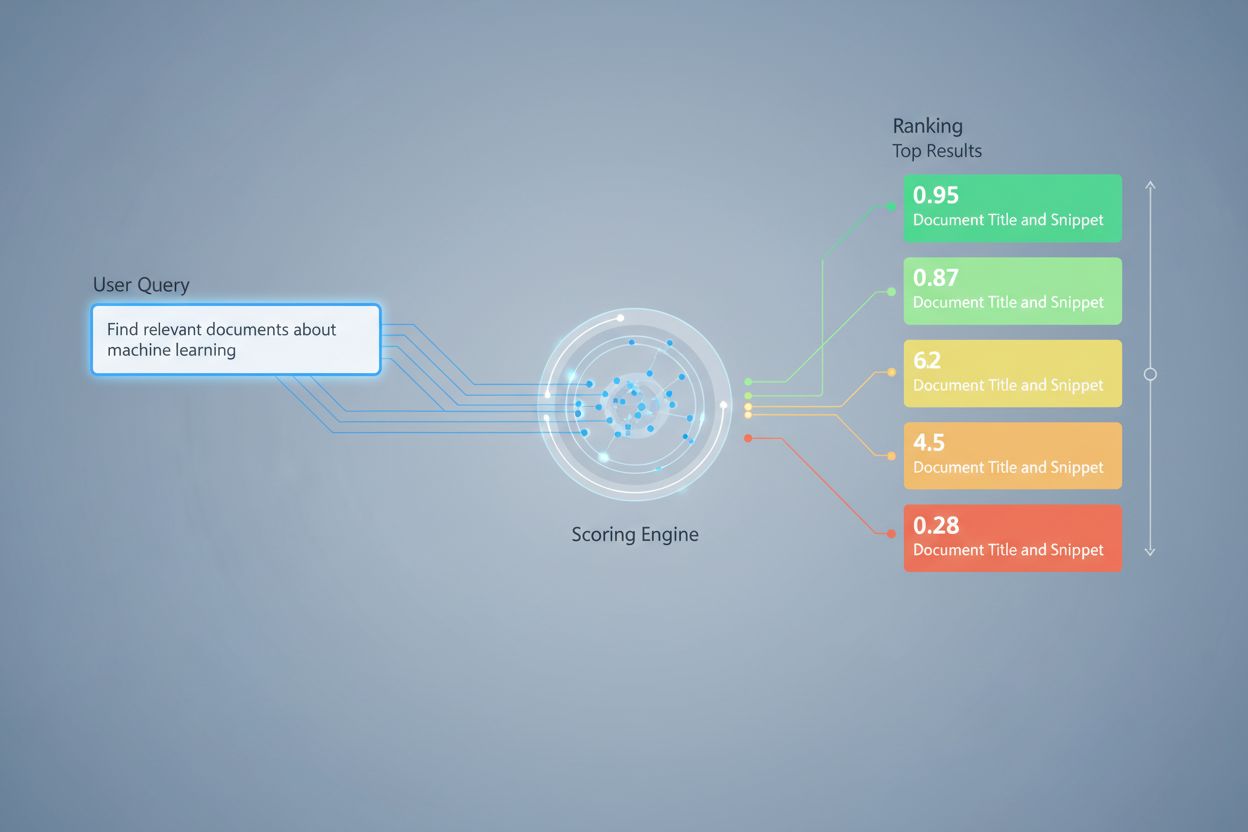
Poängsättning vid hämtning använder flera algoritmiska tillvägagångssätt, alla med olika styrkor för olika användningsområden. Semantisk likhetspoängsättning använder inbäddningsmodeller för att mäta den konceptuella överensstämmelsen mellan frågor och dokument i vektorrum, vilket fångar innebörd bortom ytliga nyckelord. BM25 (Best Matching 25) är en probabilistisk rangordningsfunktion som tar hänsyn till termfrekvens, inverterad dokumentfrekvens och normalisering av dokumentlängd, vilket gör den mycket effektiv för traditionell texthämtning. TF-IDF (Term Frequency-Inverse Document Frequency) viktar termer utifrån deras betydelse inom dokument och samlingar, men saknar semantisk förståelse. Hybrida tillvägagångssätt kombinerar flera metoder—som att slå samman BM25- och semantiska poäng—för att utnyttja både lexikala och semantiska signaler. Utöver poängsättningsmetoder finns utvärderingsmått som Precision@k (andel relevanta resultat bland de k bästa), Recall@k (andel av alla relevanta dokument i topp-k), NDCG (Normalized Discounted Cumulative Gain, som tar hänsyn till rankingposition) och MRR (Mean Reciprocal Rank) som ger kvantitativa mått på hämtningens kvalitet. Att förstå för- och nackdelar med varje metod—t.ex. BM25:s effektivitet jämfört med semantisk poängsättnings djupare förståelse—är avgörande för att välja rätt metod för specifika applikationer.
| Poängsättningsmetod | Hur den fungerar | Bäst för | Viktig fördel |
|---|---|---|---|
| Semantisk likhet | Jämför inbäddningar med cosinuslikhet eller andra avståndsmått | Konceptuell innebörd, synonymer, omformuleringar | Fångar semantiska relationer bortom nyckelord |
| BM25 | Probabilistisk rangordning som beaktar termfrekvens och dokumentlängd | Exakta frasmatchningar, nyckelordsbaserade frågor | Snabb, effektiv, beprövad i produktion |
| TF-IDF | Viktar termer efter frekvens i dokument och sällsynthet i samling | Traditionell informationshämtning | Enkel, tolkbar, resurseffektiv |
| Hybridpoängsättning | Kombinerar semantiska och nyckelordsbaserade metoder med viktad fusion | Allmän hämtning, komplexa frågor | Utnyttjar styrkor från flera metoder |
| LLM-baserad poängsättning | Använder språkmodeller för att avgöra relevans med anpassade prompts | Komplex kontextutvärdering, domänspecifika uppgifter | Fångar nyanserade semantiska relationer |
I RAG-system arbetar poängsättning på flera nivåer för att säkerställa kvalitet i genereringen. Systemet poängsätter vanligtvis individuella chunks eller avsnitt inom dokument, vilket möjliggör detaljerad relevansbedömning istället för att behandla hela dokument som enhetliga enheter. Denna per-chunk-relevanspoängsättning gör att systemet kan extrahera endast de mest relevanta informationsdelarna, vilket minskar brus och irrelevant kontext som kan förvirra språkmodellen. RAG-system implementerar ofta poängtrösklar eller avskärningsmekanismer som filtrerar bort lågt poängsatta resultat innan de når genereringssteget, vilket förhindrar att källor av låg kvalitet påverkar det slutliga svaret. Kvaliteten på den hämtade kontexten korrelerar direkt med genereringskvaliteten—högt poängsatta, relevanta avsnitt leder till mer korrekta, förankrade svar, medan lågkvalitativa hämtningar leder till hallucinationer och faktafel. Övervakning av hämtningspoäng ger tidiga varningssignaler för systemförsämring och är därmed ett nyckelmått för AI-svarsövervakning och kvalitetssäkring i produktionssystem.
Omrangering fungerar som en andra filtreringsfas som förfinar de initiala hämtningsresultaten och förbättrar ofta rangordningsnoggrannheten avsevärt. Efter att en initial hämtare genererat kandidatresulat med preliminära poäng, applicerar en omrangerare mer avancerad poänglogik för att omordna eller filtrera kandidaterna, ofta med mer beräkningsintensiva modeller som kan analysera djupare. Reciprocal Rank Fusion (RRF) är en populär teknik som kombinerar rangordningar från flera hämtare genom att tilldela poäng utifrån positionen och sedan slår samman dessa poäng för att producera en enhetlig ranking som ofta överträffar enskilda hämtare. Poängnormalisering blir kritisk när resultat från olika hämtningsmetoder kombineras, eftersom råpoäng från BM25, semantisk likhet och andra tillvägagångssätt opererar på olika skalor och måste kalibreras till jämförbara nivåer. Ensemble-hämtningsmetoder använder flera strategier samtidigt, där omrangering avgör slutordningen baserat på samlad evidens. Detta flerstegsförfarande förbättrar rangordningsnoggrannheten och robustheten betydligt jämfört med enfas-hämtning, särskilt i komplexa domäner där olika metoder fångar kompletterande relevanssignaler.
Precision@k: Mäter andelen relevanta dokument bland de k bästa resultaten; användbart för att bedöma om hämtade resultat är tillförlitliga (t.ex. Precision@5 = 4/5 betyder att 80 % av topp 5-resultaten är relevanta)
Recall@k: Beräknar andelen av alla relevanta dokument som återfinns bland de k bästa resultaten; viktigt för att säkerställa heltäckande täckning av relevant information
Hit Rate: Binärt mått som visar om minst ett relevant dokument finns bland topp k-resultaten; användbart för snabba kvalitetskontroller i produktion
NDCG (Normalized Discounted Cumulative Gain): Tar hänsyn till rankingposition genom att ge högre värde till relevanta dokument tidigare i listan; varierar mellan 0–1 och är idealiskt för utvärdering av rangordningskvalitet
MRR (Mean Reciprocal Rank): Mäter genomsnittlig position för det första relevanta resultatet över flera frågor; särskilt användbart för att bedöma om det mest relevanta dokumentet rankas högt
F1-score: Harmoniskt medelvärde av precision och recall; ger balanserad utvärdering när både falska positiva och negativa är lika viktiga
MAP (Mean Average Precision): Medelvärde av precision vid varje position där ett relevant dokument återfinns; omfattande mått på rangordningskvalitet över flera frågor
LLM-baserad relevanspoängsättning använder språkmodeller själva som domare av dokumentrelevans och erbjuder ett flexibelt alternativ till traditionella algoritmiska tillvägagångssätt. I detta paradigm instruerar noggrant utformade prompts en LLM att utvärdera om ett hämtat avsnitt besvarar en given fråga, och producerar antingen binära relevanspoäng (relevant/ej relevant) eller numeriska poäng (t.ex. 1–5-skala för relevansstyrka). Detta fångar nyanserade semantiska relationer och domänspecifik relevans som traditionella algoritmer kan missa, särskilt för komplexa frågor som kräver djup förståelse. Dock innebär LLM-baserad poängsättning utmaningar såsom beräkningskostnad (LLM-inferens är dyrare än inbäddningslikhet), potentiell inkonsekvens mellan olika prompts och modeller, och behov av kalibrering mot mänskliga etiketter för att säkerställa att poängen speglar faktisk relevans. Trots dessa begränsningar är LLM-baserad poängsättning värdefull både för att utvärdera RAG-systemkvalitet och skapa träningsdata för specialiserade modeller, vilket gör det till ett viktigt verktyg för AI-övervakning av svarskvalitet.
Att implementera effektiv poängsättning vid hämtning kräver noggrann hänsyn till flera praktiska faktorer. Val av metod beror på användningskraven: semantisk poängsättning är bäst på att fånga innebörd men kräver inbäddningsmodeller, medan BM25 erbjuder snabbhet och effektivitet för lexikal matchning. Avvägningen mellan hastighet och noggrannhet är avgörande—poängsättning baserad på inbäddningar ger bättre förståelse men innebär latenstidskostnader, medan BM25 och TF-IDF är snabbare men mindre semantiskt sofistikerade. Beräkningskostnader inkluderar inferenstid för modeller, minneskrav och skalbarhetsbehov för infrastrukturen, särskilt viktigt för system med höga volymer. Parameterjustering innebär att trimma trösklar, vikter i hybridmetoder och omrangeringsgränser för att optimera prestanda för specifika domäner och användningsfall. Kontinuerlig övervakning av poängsättningsprestanda med mått som NDCG och Precision@k hjälper till att upptäcka försämring över tid, möjliggör proaktiva förbättringar och säkerställer konsekvent svarskvalitet i produktions-RAG-system.
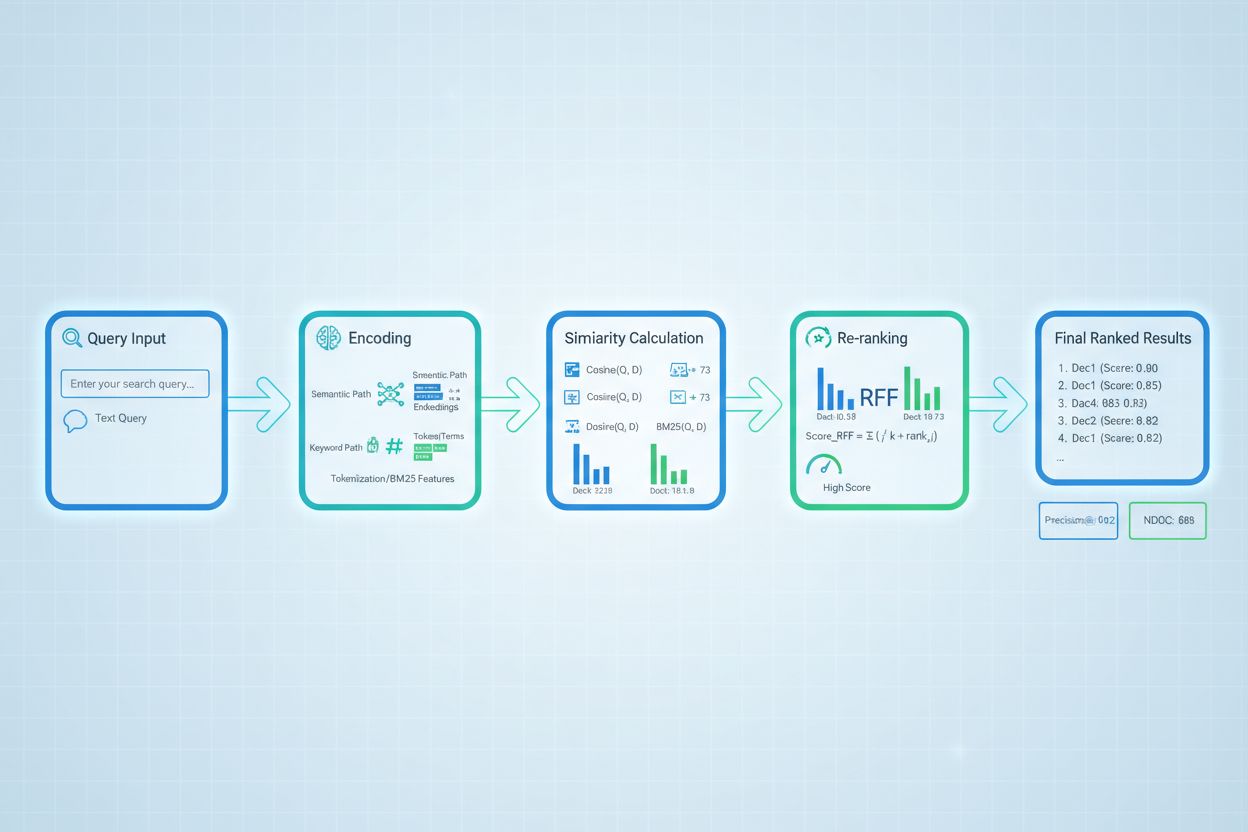
Avancerade tekniker för poängsättning vid hämtning går bortom grundläggande relevansbedömning för att fånga komplexa kontextuella relationer. Omformulering av frågor kan förbättra poängsättning genom att omvandla användarfrågor till flera semantiskt likvärdiga former, så att hämtaren kan hitta relevanta dokument som annars skulle missas vid bokstavlig matchning. Hypothetical Document Embeddings (HyDE) skapar syntetiska relevanta dokument från frågor och använder dessa hypotetiska dokument för att förbättra poängsättningen genom att hitta verkliga dokument som liknar det idealiserade innehållet. Multi-query-metoder skickar flera variantfrågor till hämtare och aggregerar deras poäng, vilket förbättrar robusthet och täckning jämfört med enkel fråga-hämtning. Domänspecifika poängmodeller tränade på etiketterad data från särskilda branscher eller kunskapsområden kan ge överlägsen prestanda jämfört med generella modeller, särskilt värdefullt för specialiserade applikationer såsom medicinska eller juridiska AI-system. Kontextuella poängjusteringar tar hänsyn till faktorer som dokumentens aktualitet, källans auktoritet och användarens kontext, vilket möjliggör mer sofistikerad relevansbedömning som går bortom ren semantisk likhet och istället inkluderar verkliga relevansfaktorer avgörande för produktions-AI-system.
Hämtningens poängsättning tilldelar numeriska relevansvärden till dokument baserat på deras förhållande till en fråga, medan rangordning ordnar dokumenten utifrån dessa poäng. Poängsättning är utvärderingsprocessen, rangordning är resultatet av sorteringen. Båda är avgörande för att RAG-system ska leverera korrekta svar.
Poängsättningen avgör vilka källor som når språkmodellen för svarsgenerering. Kvalitativ poängsättning säkerställer att relevant information väljs, vilket minskar hallucinationer och förbättrar svarens noggrannhet. Dålig poängsättning leder till irrelevant kontext och opålitliga AI-svar.
Semantisk poängsättning använder inbäddningar för att förstå konceptuell innebörd och fånga synonymer och relaterade begrepp. Nyckelordsbaserad poängsättning (som BM25) matchar exakta termer och fraser. Semantisk poängsättning är bättre för att förstå avsikt, medan nyckelordspoängsättning är bäst för att hitta specifik information.
Viktiga mått inkluderar Precision@k (noggrannhet bland toppresultat), Recall@k (täcker relevanta dokument), NDCG (kvalitet på rangordning) och MRR (position för första relevanta resultat). Välj mått utifrån ditt användningsfall: Precision@k för kvalitet, Recall@k för täckning.
Ja, LLM-baserad poängsättning använder språkmodeller som domare för att utvärdera relevans. Detta fångar nyanserade semantiska relationer men är beräkningsmässigt kostsamt. Det är värdefullt för att utvärdera kvaliteten på RAG och skapa träningsdata, men kräver kalibrering mot mänskliga etiketter.
Omrangering tillämpar en andra filtrering med mer avancerade modeller för att förbättra initiala resultat. Tekniker som Reciprocal Rank Fusion kombinerar flera hämtningar, vilket förbättrar noggrannhet och robusthet. Omrangering överträffar avsevärt enkelfas-hämtning i komplexa domäner.
BM25 och TF-IDF är snabba och resurseffektiva, lämpliga för realtidssystem. Semantisk poängsättning kräver inbäddningsmodell, vilket ökar latenstiden. LLM-baserad poängsättning är dyrast. Välj utifrån dina latenskrav och tillgängliga resurser.
Tänk på dina prioriteringar: semantisk poängsättning för meningsfokuserade uppgifter, BM25 för snabbhet och effektivitet, hybrida lösningar för balanserad prestanda. Utvärdera inom din domän med mått som NDCG och Precision@k. Testa flera metoder och mät effekten på slutkvaliteten.
Följ hur AI-system som ChatGPT, Perplexity och Google AI refererar till ditt varumärke och utvärderar kvaliteten på deras hämtning och rangordning av källor. Säkerställ att ditt innehåll citeras och rankas korrekt av AI-system.
Lär dig vad en AI-innehållspoäng är, hur den utvärderar innehållets kvalitet för AI-system och varför det är viktigt för synlighet i ChatGPT, Perplexity och and...

Lär dig vad Multi-Plattform AI-poäng är och hur det mäter ditt varumärkes synlighet över ChatGPT, Perplexity, Claude och andra AI-plattformar. Förstå nyckelmått...

Lär dig hur bedömningspoäng för innehållsrelevans använder AI-algoritmer för att mäta hur väl innehåll matchar användarfrågor och avsikt. Förstå BM25, TF-IDF oc...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.