Upphovsrättsliga konsekvenser av AI-sökmotorer och generativ AI
Förstå de upphovsrättsliga utmaningar som AI-sökmotorer står inför, begränsningar i fair use, aktuella stämningar och rättsliga konsekvenser för AI-genererade s...
8 min läsning
Tekniska och juridiska mekanismer som gör det möjligt för innehållsskapare och upphovsrättsinnehavare att förhindra att deras verk används i träningsdatamängder för stora språkmodeller. Dessa inkluderar robots.txt-direktiv, juridiska avböjandeuttalanden och avtalsmässiga skydd enligt förordningar som EU:s AI-förordning.
Tekniska och juridiska mekanismer som gör det möjligt för innehållsskapare och upphovsrättsinnehavare att förhindra att deras verk används i träningsdatamängder för stora språkmodeller. Dessa inkluderar robots.txt-direktiv, juridiska avböjandeuttalanden och avtalsmässiga skydd enligt förordningar som EU:s AI-förordning.
AI-träningsavböjande syftar på de tekniska och juridiska mekanismer som gör det möjligt för innehållsskapare, upphovsrättsinnehavare och webbplatsägare att förhindra att deras verk används i träningsdatamängder för stora språkmodeller (LLM). I takt med att AI-företag samlar in enorma mängder data från internet för att träna allt mer sofistikerade modeller har möjligheten att kontrollera om ditt innehåll deltar i denna process blivit avgörande för att skydda immateriella rättigheter och behålla kreativ kontroll. Dessa avböjandemekanismer verkar på två nivåer: tekniska direktiv som instruerar AI-crawlers att hoppa över ditt innehåll, och juridiska ramverk som fastställer avtalsrättigheter att utesluta ditt verk från träningsdatamängder. Att förstå båda dimensionerna är avgörande för alla som är oroliga för hur deras innehåll används i AI-eran.

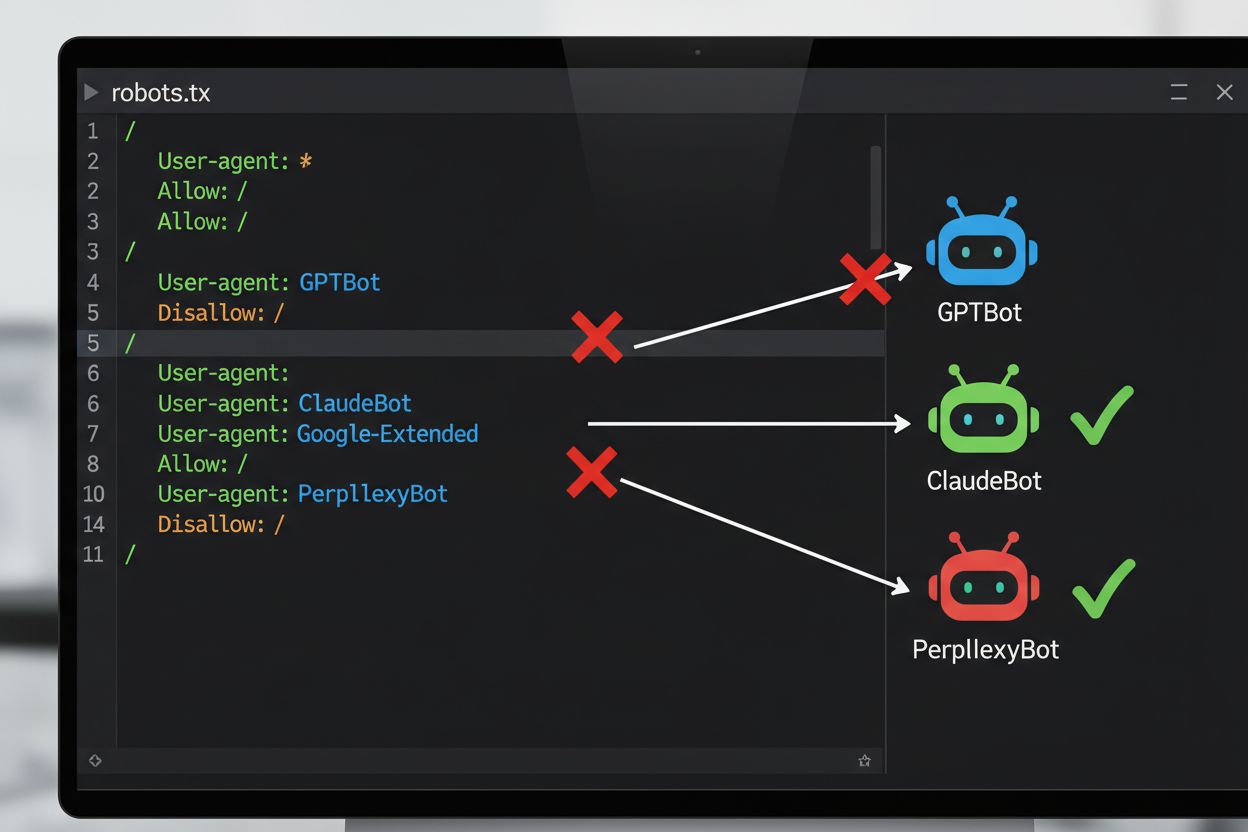
Den vanligaste tekniska metoden för att avböja AI-träning är genom robots.txt-filen, en enkel textfil placerad i webbplatsens rotkatalog som kommunicerar crawler-behörigheter till automatiserade botar. När en AI-crawler besöker din webbplats kontrollerar den först robots.txt för att se om den får tillgång till ditt innehåll. Genom att lägga till specifika disallow-direktiv för särskilda crawler user agents kan du instruera AI-botar att hoppa över din webbplats helt. Varje AI-företag driver flera crawlers med unika user agent-identifierare—dessa är i princip de “namn” som botar använder för att identifiera sig själva när de gör förfrågningar. Till exempel identifierar OpenAIs GPTBot sig med user agent-strängen “GPTBot”, medan Anthropics Claude använder “ClaudeBot”. Syntaxen är enkel: du anger user agent-namnet och deklarerar sedan vilka sökvägar som inte är tillåtna, såsom “Disallow: /” för att blockera hela webbplatsen.
| AI-företag | Crawler-namn | User agent-token | Syfte |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Insamling av modellträningsdata |
| OpenAI | OAI-SearchBot | OAI-SearchBot | ChatGPT-sökindexering |
| Anthropic | ClaudeBot | ClaudeBot | Hämtning av chatreferenser |
| Google-Extended | Google-Extended | Gemini AI-träningsdata | |
| Perplexity | PerplexityBot | PerplexityBot | AI-sökindexering |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | AI-modellträning |
| Common Crawl | CCBot | CCBot | Öppen datamängd för LLM-träning |
Den juridiska miljön för AI-träningsavböjande har utvecklats avsevärt med införandet av EU:s AI-förordning, som trädde i kraft 2024 och innehåller bestämmelser från Text- och datautvinningsdirektivet (TDM). Enligt dessa regler får AI-utvecklare endast använda upphovsrättsskyddade verk för maskininlärningsändamål om de har laglig tillgång till innehållet och upphovsrättsinnehavaren inte uttryckligen har reserverat rätten att exkludera sitt verk från text- och datautvinning. Detta skapar en formell juridisk mekanism för avböjande: upphovsrättsinnehavare kan lämna in avböjandeförbehåll tillsammans med sina verk, vilket effektivt förhindrar att de används i AI-träning utan uttryckligt tillstånd. EU:s AI-förordning innebär ett betydande skifte från det tidigare “move fast and break things”-tänket och slår fast att företag som tränar AI-modeller måste kontrollera om rättsinnehavare har reserverat sitt innehåll och införa tekniska och organisatoriska skydd för att förhindra oavsiktlig användning av avböjda verk. Detta juridiska ramverk gäller i hela Europeiska unionen och påverkar hur globala AI-företag hanterar datainsamling och träningspraxis.
Att implementera en avböjandemekanism innebär både teknisk konfiguration och juridisk dokumentation. På den tekniska sidan lägger webbplatsägare till disallow-direktiv i sin robots.txt-fil för specifika AI-crawler user agents, vilket kompatibla crawlers respekterar när de besöker webbplatsen. På den juridiska sidan kan upphovsrättsinnehavare lämna in avböjandeuttalanden till upphovsrättsorganisationer och rättighetssällskap—till exempel har det nederländska sällskapet Pictoright och franska musikorganisationen SACEM infört formella avböjandeprocedurer som gör det möjligt för skapare att reservera sina rättigheter mot AI-träningsanvändning. Många webbplatser och innehållsskapare inkluderar nu uttryckliga avböjandeuttalanden i sina användarvillkor eller metadata, där de deklarerar att deras innehåll inte får användas för AI-modellträning. Dock beror effektiviteten på dessa mekanismer på crawler-kompatibilitet: även om stora företag som OpenAI, Google och Anthropic offentligt deklarerat att de respekterar robots.txt-direktiv och avböjandeförbehåll, innebär avsaknaden av en centraliserad verkställighet att det krävs kontinuerlig övervakning och verifiering för att avgöra om en avböjandebegäran verkligen efterlevs.
Trots tillgången på avböjandemekanismer finns det betydande utmaningar som begränsar deras effektivitet:
För organisationer som kräver starkare skydd än vad robots.txt ensam ger kan flera ytterligare tekniska metoder implementeras. User agent-filtrering på server- eller brandväggsnivå kan blockera förfrågningar från specifika crawler-identifierare innan de når din applikation, men detta är fortfarande sårbart för förfalskning. IP-adressblockering kan rikta in sig på kända crawler-IP-intervall som publiceras av stora AI-företag, även om beslutsamma scrapers kan undvika detta genom proxy-nätverk. Begränsning av förfrågningsfrekvens (rate limiting) och throttling kan sakta ner scrapers genom att begränsa antalet tillåtna förfrågningar per sekund, vilket gör scraping ekonomiskt ohållbart, även om sofistikerade botar kan fördela förfrågningar över flera IP-adresser för att kringgå dessa begränsningar. Autentiseringskrav och betalväggar ger starkt skydd genom att begränsa tillgången till inloggade användare eller betalande kunder, vilket effektivt förhindrar automatiserad scraping. Enhetsfingeravtryck och beteendeanalys kan identifiera botar genom att analysera mönster som browser-API:er, TLS-handshakes och interaktionsmönster som skiljer sig från mänskliga användare. Vissa organisationer har till och med implementerat honeypots och tarpits—dolda länkar eller oändliga länk-labyrinter som bara botar skulle följa—för att slösa crawler-resurser och potentiellt förorena deras träningsdata med skräpdata.
Spänningen mellan AI-företag och innehållsskapare har lett till flera uppmärksammade konfrontationer som illustrerar de praktiska utmaningarna med att upprätthålla avböjande. Reddit vidtog aggressiva åtgärder 2023 genom att dramatiskt höja API-priserna, särskilt för att ta betalt av AI-företag för data, vilket effektivt prisade ut obehöriga scrapers och tvingade företag som OpenAI och Anthropic att förhandla om licensavtal. Twitter/X införde ännu mer extrema åtgärder, genom att tillfälligt blockera all oautentiserad åtkomst till tweets och begränsa hur många tweets inloggade användare kunde läsa, med explicit syfte att stoppa datainsamlare som förbrukade resurser. Stack Overflow blockerade initialt OpenAIs GPTBot i sin robots.txt-fil på grund av licensbekymmer kring användargenererad kod, men tog senare bort blockeringen—möjligen efter förhandlingar med OpenAI. Nyhetsmedieorganisationer svarade gemensamt: över 50 % av stora nyhetssajter blockerade AI-crawlers redan 2023, med aktörer som The New York Times, CNN, Reuters och The Guardian som alla lade till GPTBot på sina disallow-listor. Vissa nyhetsorganisationer valde istället rättsliga åtgärder, som The New York Times som stämde OpenAI för upphovsrättsintrång, medan andra som Associated Press förhandlade fram licensavtal för att tjäna pengar på sitt innehåll. Dessa exempel visar att även om avböjandemekanismer existerar, beror deras effektivitet både på teknisk implementering och på viljan att vidta rättsliga åtgärder vid överträdelser.
Att implementera avböjandemekanismer är bara halva arbetet; att verifiera att de faktiskt fungerar kräver kontinuerlig övervakning och testning. Flera verktyg kan hjälpa dig att validera din konfiguration: Google Search Console innehåller en robots.txt-tester för validering specifikt för Googlebot, medan Merkles Robots.txt Tester och TechnicalSEO.coms verktyg testar enskilt crawler-beteende mot specifika user agents. För övergripande övervakning av om AI-företag faktiskt respekterar dina avböjandeförbehåll erbjuder plattformar som AmICited.com specialiserad övervakning som spårar hur AI-system refererar till ditt varumärke och innehåll i GPTs, Perplexity, Google AI Overviews och andra AI-plattformar. Denna typ av övervakning är särskilt värdefull eftersom den avslöjar inte bara om crawlers försöker komma åt din webbplats, utan även om ditt innehåll faktiskt förekommer i AI-genererade svar—vilket indikerar om ditt avböjande är effektivt i praktiken. Regelbunden analys av serverloggar kan också visa vilka crawlers som försöker komma åt din webbplats och om de respekterar dina robots.txt-direktiv, även om detta kräver teknisk expertis för att tolka korrekt.
För att effektivt skydda ditt innehåll mot obehörig AI-träningsanvändning, använd en lager-på-lager-strategi som kombinerar tekniska och juridiska åtgärder. För det första, implementera robots.txt-direktiv för alla större AI-träningscrawlers (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot och andra), med förståelse för att detta ger ett grundskydd mot kompatibla företag. För det andra, lägg till uttryckliga avböjandeuttalanden i din webbplats användarvillkor och metadata, där du tydligt deklarerar att ditt innehåll inte får användas för AI-modellträning—detta stärker din juridiska position vid överträdelser. För det tredje, övervaka din konfiguration regelbundet med testverktyg och serverloggar för att verifiera att crawlers respekterar dina direktiv, och uppdatera din robots.txt kvartalsvis eftersom nya AI-crawlers ständigt dyker upp. För det fjärde, överväg ytterligare tekniska åtgärder såsom user agent-filtrering eller begränsning av förfrågningsfrekvens om du har tekniska resurser, med insikten att dessa ger inkrementellt skydd mot mer sofistikerade scrapers. Slutligen, dokumentera dina avböjandeförsök noggrant, eftersom denna dokumentation blir avgörande om du behöver vidta rättsliga åtgärder mot företag som ignorerar dina direktiv. Kom ihåg att avböjande inte är en engångskonfiguration utan en pågående process som kräver vaksamhet och anpassning i takt med att AI-landskapet fortsätter att utvecklas.
robots.txt är en teknisk, frivillig standard som instruerar crawlers att hoppa över ditt innehåll, medan juridiskt avböjande innebär att man lämnar in formella förbehåll till upphovsrättsorganisationer eller inkluderar avtalsklausuler i dina användarvillkor. robots.txt är enklare att implementera men saknar verkställighet, medan juridiskt avböjande ger starkare juridiskt skydd men kräver mer formella procedurer.
Stora AI-företag som OpenAI, Google, Anthropic och Perplexity har offentligt deklarerat att de respekterar robots.txt-direktiv. Dock är robots.txt en frivillig standard utan någon verkställighetsmekanism, så icke-kompatibla crawlers och illvilliga scrapers kan ignorera dina direktiv helt.
Nej. Att blockera AI-träningscrawlers som GPTBot och ClaudeBot påverkar inte din Google- eller Bing-sökrankning eftersom traditionella sökmotorer använder andra crawlers (Googlebot, Bingbot) som arbetar oberoende. Blockera endast dessa om du vill försvinna helt från sökresultaten.
EU:s AI-förordning kräver att AI-utvecklare har laglig tillgång till innehåll och måste respektera upphovsrättsinnehavares avböjandeförbehåll. Upphovsrättsinnehavare kan lämna in avböjandeuttalanden tillsammans med sina verk, vilket effektivt förhindrar deras användning i AI-träning utan uttryckligt tillstånd. Detta skapar en formell juridisk mekanism för att skydda innehåll mot obehörig träningsanvändning.
Det beror på den specifika mekanismen. Att blockera alla AI-crawlers förhindrar att ditt innehåll visas i AI-sökresultat, men detta tar dig också bort från AI-drivna sökplattformar helt. Vissa publicister föredrar selektiv blockering—tillåter sökfokuserade crawlers men blockerar träningsfokuserade för att behålla synlighet i AI-sökning samtidigt som innehållet skyddas från modellträning.
Om ett AI-företag ignorerar dina avböjandedirektiv har du juridiska åtgärder genom upphovsrättsintrång eller avtalsbrott, beroende på din jurisdiktion och de specifika omständigheterna. Dock är rättsliga åtgärder kostsamma och långsamma, med osäkra utfall. Därför är övervakning och dokumentation av dina avböjandeförsök avgörande.
Granska och uppdatera din robots.txt-konfiguration minst kvartalsvis. Nya AI-crawlers dyker ständigt upp, och företag introducerar ofta nya crawler user agents. Till exempel slog Anthropic ihop sina 'anthropic-ai' och 'Claude-Web'-botar till 'ClaudeBot', vilket gav den nya boten tillfällig obegränsad åtkomst till webbplatser som inte hade uppdaterat sina regler.
Avböjande är effektivt mot kompatibla, respekterade AI-företag som följer robots.txt och juridiska ramverk. Men det är mindre effektivt mot illvilliga crawlers och icke-kompatibla scrapers som verkar i juridiska gråzoner. robots.txt stoppar cirka 40–60 % av AI-botar, vilket är anledningen till att en lager-på-lager-strategi med flera tekniska och juridiska åtgärder rekommenderas.
Spåra om ditt innehåll förekommer i AI-genererade svar på ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar med AmICited.
Förstå de upphovsrättsliga utmaningar som AI-sökmotorer står inför, begränsningar i fair use, aktuella stämningar och rättsliga konsekvenser för AI-genererade s...
Komplett guide för att avanmäla dig från AI-träning och datainsamling på ChatGPT, Perplexity, LinkedIn och andra plattformar. Lär dig steg-för-steg hur du skydd...
Diskussion i communityn om att påverka AI:s träningsdata om ditt varumärke. Äkta insikter om hur innehållsskapande påverkar vad AI-system lär sig och minns om f...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.