
Vad är meta-taggen noai och hur skyddar den ditt innehåll mot AI?
Lär dig om meta-taggen noai, hur den fungerar för att förhindra AI-träningsdatainsamling, dess begränsningar och hur du implementerar den på din webbplats för a...
6 min läsning

En HTML-meta-tagg som signalerar till AI-träningssystem och webbcrawlers att webbplatsens innehåll inte ska användas för träning av maskininlärningsmodeller. Ursprungligen introducerad av DeviantArt, fungerar den som en mekanism för innehållsskydd och ett opt-out-signal för skapare som oroar sig för obehörig AI-datainsamling.
En HTML-meta-tagg som signalerar till AI-träningssystem och webbcrawlers att webbplatsens innehåll inte ska användas för träning av maskininlärningsmodeller. Ursprungligen introducerad av DeviantArt, fungerar den som en mekanism för innehållsskydd och ett opt-out-signal för skapare som oroar sig för obehörig AI-datainsamling.
NoAI-meta-taggen är en mekanism för innehållsskydd som implementeras som en HTML-meta-tagg och signalerar till AI-träningssystem och webbcrawlers att en webbplats innehåll inte ska användas för träning av maskininlärningsmodeller. Taggen introducerades ursprungligen av DeviantArt i september 2022 och blev ett gräsrotsinitiativ som svar på oro över att konstnärers verk skrapades och användes för att träna generativa AI-modeller utan samtycke eller kompensation. Meta-taggen verkar genom att lägga till en enkel HTML-deklaration i en webbsidas header, vilket kommunicerar en tydlig önskan till AI-system att innehållet inte får användas för träningsändamål. Även om taggen inte är juridiskt bindande i de flesta jurisdiktioner, utgör NoAI-taggen en viktig opt-out-mekanism för skapare som vill skydda sin immateriella egendom i en tid av alltmer aggressiv AI-datainsamling.
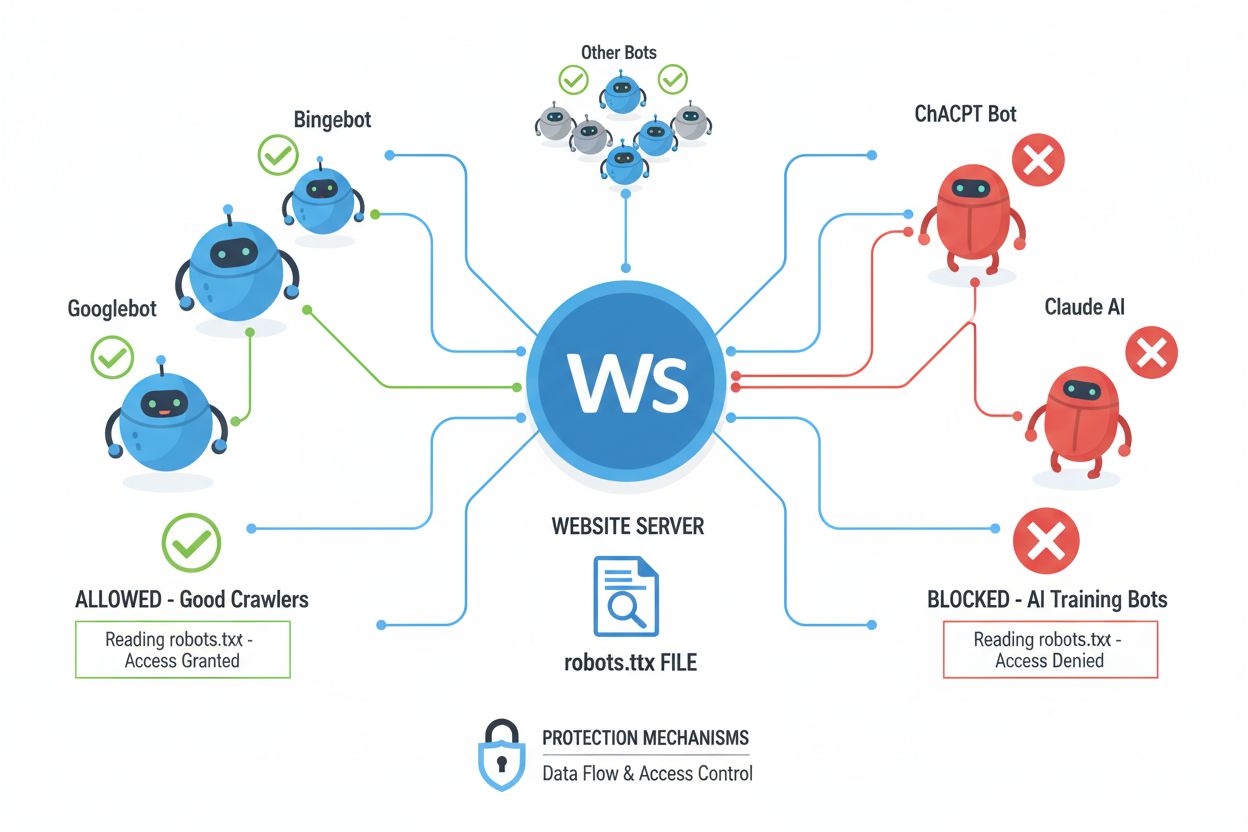
Webbcrawlers (även kallade bots, spindlar eller scrapers) är automatiserade programvaror som systematiskt surfar på internet, följer länkar och laddar ner innehåll för att indexera, analysera eller samla in data för olika syften. Dessa crawlers fungerar genom att läsa filen robots.txt som finns i webbplatsens rotkatalog och innehåller instruktioner om vilka delar av sajten som får eller inte får nås av automatiska besökare. Filen robots.txt använder specifika direktiv som User-agent, Disallow och Allow för att kommunicera crawlerbehörigheter, men efterlevnaden är helt frivillig och bygger på om crawlerns utvecklare väljer att följa riktlinjerna. Utöver robots.txt kan webbplatser kommunicera preferenser via HTTP-huvuden och meta-taggar, vilka ger ytterligare signaler om användningsrättigheter och begränsningar för innehåll. Olika typer av crawlers respekterar dessa signaler i varierande grad:
| Crawlertyp | robots.txt-efterlevnad | Respekt för meta-tagg | Användning för AI-träning |
|---|---|---|---|
| Sökmotorer | Hög | Hög | Begränsad |
| AI-träningsbotar | Medel | Medel | Ja |
| Kommersiella scrapers | Låg | Låg | Varierar |
| Akademiska botar | Hög | Medel | Endast forskning |
| Illvilliga botar | Ingen | Ingen | Obegränsad |
Direktiven noai och noimageai har närliggande men distinkta syften i innehållsskydd, där den avgörande skillnaden ligger i deras omfattning och specificitet. Direktivet noai är en bredare signal som indikerar att allt innehåll på en sida—inklusive text, bilder, kod och annat media—inte får användas för AI-träning, vilket gör det lämpligt för webbplatser med blandat innehåll eller de som önskar heltäckande skydd. Direktivet noimageai riktar sig däremot specifikt mot bildinnehåll och tillåter att text och annat icke-bildmaterial potentiellt används för träning, samtidigt som visuella tillgångar skyddas mot AI-modellträning. Denna skillnad är särskilt viktig för webbplatser som vill tillåta textbaserad AI-indexering (t.ex. för sökmotorer eller tillgänglighet) men skydda sitt visuella innehåll mot generativa bildmodeller. Här är implementeringsskillnaderna:
<!-- Heltäckande skydd för allt innehåll -->
<meta name="robots" content="noai">
<!-- Specifikt skydd endast för bilder -->
<meta name="robots" content="noimageai">
<!-- Kombinerad strategi för maximal tydlighet -->
<meta name="robots" content="noai, noimageai">
NoAI-meta-taggen kan implementeras på flera sätt, med olika fördelar beroende på din tekniska infrastruktur och specifika behov. Det enklaste sättet är att lägga till meta-taggen direkt i din HTML-
-sektion, vilket tillämpar direktivet på enskilda sidor och kan anpassas sida för sida vid behov. För webbplatser med många sidor eller de som vill ha en lösning som gäller hela sajten, ger implementering via HTTP-svarshuvuden en mer skalbar metod som gäller för allt innehåll utan att behöva ändra varje sida individuellt. Dessutom kan filenrobots.txt inkludera direktiv som riktar sig till specifika AI-crawlers, även om denna metod är mindre standardiserad än meta-taggar eller huvuden. Här är de tre huvudsakliga implementeringsmetoderna:<!-- Metod 1: HTML-meta-tagg (vanligast) -->
<head>
<meta name="robots" content="noai">
</head>
# Metod 2: robots.txt-direktiv
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metod 3: HTTP-header (via .htaccess eller serverkonfiguration)
X-Robots-Tag: noai
För Apache-servrar, lägg till i .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
För Nginx-servrar, lägg till i din serverblock:
add_header X-Robots-Tag "noai" always;
Även om NoAI-meta-taggen utgör ett viktigt steg mot innehållsskydd bygger den på ett hederssystem som helt beror på om AI-utvecklare och datascrapers väljer att respektera signalen. Stora AI-företag som OpenAI, Google och Anthropic har börjat respektera NoAI-direktiv i sina crawlers, men illvilliga aktörer och oseriösa scrapers ignorerar ofta signalerna, vilket gör taggen ineffektiv mot målmedvetna datatjuvar. NoAI:s effektivitet begränsas ytterligare av att den endast förhindrar framtida träning på innehåll; den kan inte ta bort data som redan samlats in och används i befintliga modeller, och erbjuder ingen juridisk möjlighet om den bryts. Efterlevnaden varierar kraftigt mellan olika AI-system, där vissa respekterar direktivet medan andra medvetet kringgår det, vilket gör NoAI till en användbar men ofullständig lösning. Taggen ger heller inget skydd mot direktnedladdningar, skärmdumpar eller manuell kopiering av innehåll, och den kan inte hindra användning av ditt innehåll av konkurrenter som väljer att ignorera direktivet. Av dessa skäl bör NoAI ses som ett lager i en heltäckande strategi för innehållsskydd snarare än en komplett lösning.
NoAI-meta-taggen har fått stort genomslag bland stora AI-företag och plattformar, där bland annat OpenAI, Google och Stability AI offentligt har åtagit sig att respektera direktivet i sina träningsprocesser. DeviantArts implementering av NoAI har påverkat branschdiskussioner om etisk AI-utveckling och skaparsamtycke och ökat medvetenheten bland både AI-utvecklare och innehållsskapare. Men adoptionen är ojämn i branschen, där mindre AI-företag, akademiska forskare och kommersiella scrapers uppvisar varierande nivåer av efterlevnad. Framväxten av konkurrerande standarder som C2PA (Coalition for Content Provenance and Authenticity) och diskussioner om maskinläsbara rättighetsuttryck tyder på att branschen rör sig mot mer sofistikerade, juridiskt förankrade mekanismer för innehållsskydd utöver frivilliga meta-taggar. Branschorganisationer och standardiseringsorgan arbetar aktivt för att formalisera dessa skydd, med förväntan att framtida AI-reglering kan kräva explicit efterlevnad av skaparnas preferenser, vilket potentiellt kan göra NoAI från en frivillig signal till ett juridiskt krav.
Att implementera NoAI-skydd bör vara en del av en lagerbaserad strategi för innehållssäkerhet snarare än en fristående lösning, där tekniska, juridiska och övervakande åtgärder kombineras för ett heltäckande skydd. För att maximera effekten, överväg följande bästa praxis:
Utför dessutom regelbundna granskningar av din implementation för innehållsskydd för att säkerställa att alla sidor inkluderar lämpliga direktiv, och överväg att använda automatiska verktyg för att söka efter ditt innehåll i offentliga AI-dataset och träningsarkiv. Dokumentera din NoAI-implementation som en del av din policy för innehållsstyrning och kommunicera dessa skydd till din publik så att de förstår vilka åtgärder du vidtar för att skydda deras verk om du är en plattform som är värd för användargenererat innehåll.
Direktivet noai skyddar alla typer av innehåll (text, bilder, kod) från AI-träning, medan noimageai specifikt skyddar endast bildinnehåll. Använd noai för heltäckande skydd och noimageai när du vill tillåta textindexering men skydda visuella tillgångar från generativa bildmodeller.
Nej, NoAI-meta-taggen bygger på hederssystemet och beror på om AI-utvecklare väljer att respektera den. Stora företag som OpenAI och Google respekterar den, men illvilliga aktörer och oseriösa scrapers ignorerar ofta dessa signaler, vilket gör det till ett lager av skydd snarare än en komplett lösning.
Du kan implementera den på tre sätt: lägg till HTML-meta-taggen i sidhuvudet, sätt HTTP-svarshuvuden på din server, eller inkludera direktiv i din robots.txt-fil. HTML-meta-taggen är den vanligaste och enklaste metoden för de flesta webbplatsägare.
Stora AI-företag inklusive OpenAI (ChatGPT), Google, Anthropic (Claude) och Stability AI har offentligt åtagit sig att respektera NoAI-direktiv i sina träningsprocesser. Efterlevnaden varierar dock bland mindre AI-företag, akademiska forskare och kommersiella scrapers.
Ja, du kan använda båda samtidigt för maximal effekt. NoAI-meta-taggen och direktiv i robots.txt samarbetar för att kommunicera dina preferenser för innehållsskydd till olika typer av crawlers och system.
Kombinera NoAI med andra skyddsmetoder som HTTP-huvuden, robots.txt-regler, vattenmärkning, åtkomstkontroller och juridiska användarvillkor. Övervaka ditt innehåll i AI-dataset och överväg att använda verktyg för att spåra obehörig användning.
Även om den används brett av stora AI-företag är NoAI ännu inte en formell W3C-standard. Dock arbetar branschorganisationer på mer sofistikerade standarder som C2PA och maskinläsbara rättighetsuttryck som så småningom kan ge juridiskt stöd.
NoAI är mest effektiv när den kombineras med andra metoder som robots.txt, HTTP-huvuden, vattenmärkning, åtkomstkontroller och juridiskt skydd. Ingen enskild metod ger fullständigt skydd, så en lagerbaserad strategi rekommenderas för heltäckande innehållssäkerhet.
Spåra vilka AI-system som citerar ditt varumärke och innehåll med AmICiteds AI-övervakningsplattform. Vet exakt hur ditt arbete används av ChatGPT, Perplexity, Google AI Overviews och andra AI-system.
Lär dig om meta-taggen noai, hur den fungerar för att förhindra AI-träningsdatainsamling, dess begränsningar och hur du implementerar den på din webbplats för a...
Diskussion i communityt om noai-meta-taggen och om den faktiskt skyddar innehåll från AI-träning. Användare delar erfarenheter och begränsningar med detta tillv...
Meta AI är Metas AI-assistent integrerad i Facebook, Instagram, WhatsApp och Messenger. Lär dig hur den fungerar, dess kapabiliteter och dess roll i AI-övervakn...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.