
如何应对 AI 搜索引擎的重复内容问题
了解在使用 AI 工具时如何管理和防止重复内容。发现规范标签、重定向、检测工具及维护网站内容唯一性的最佳实践。
2 分钟阅读
大型语言模型和AI搜索系统采用复杂的聚类算法,识别并分组近似重复的URL,将同一内容的多个版本视为一个实体进行排名和引用。当AI系统遇到重复内容时,必须选择优先展示的版本——这一决策直接影响哪个URL获得可见性、权威信号和用户归属。如果AI选择了错误的版本,问题就出现了:即使您的规范化URL指向首选页面,但AI系统却将低质量的重复页面聚类并排名,您的内容就会失去可见性和引用权。意图信号会在重复版本间被稀释,原本可在单一URL上集中的权威性被分散,导致每个重复页面获得的排名信号都比整合到规范化版本时更弱。
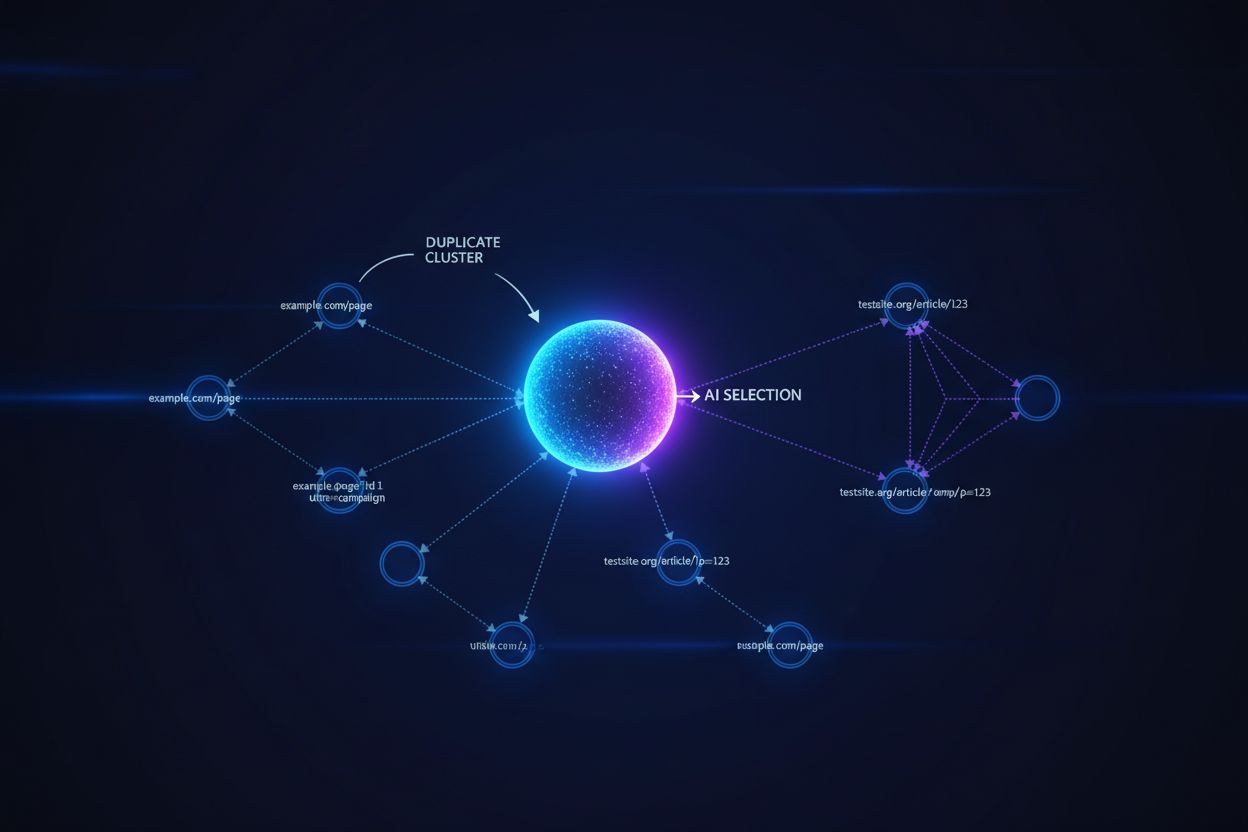
规范标签作为明确信号,告知AI系统哪一个版本的重复内容应被视为权威,这直接影响您的首选URL是否会出现在AI生成的答案中并获得正确归属。如果没有规范标签,AI系统只能根据内容相似度、链接模式和新鲜度等信号自主聚类——这常常导致错误版本被选为规范源。当缺乏规范化实施时,AI答案可能会引用转载版本、缓存副本或质量较低的变体,而不是您的原始内容,使您的可见性在多个URL之间被分散。规范化URL可确保当AI系统在不同域名、参数或版本中遇到您的内容时,能够理解哪个URL应获得归属并在结果中被优先展示。
| 场景 | 无规范化 | 有规范化 |
|---|---|---|
| 对AI影响 | AI独立聚类重复内容,可能选错版本排名 | AI识别单一权威来源,所有信号集中于规范化URL |
| 引用归属 | 归属分散到多个URL,每个URL权威较弱 | 所有引用和权威归入规范化URL,可见性更强 |
| 结果 | 内容出现在AI答案中但错误URL获得归属,曝光分散 | 首选URL出现在AI答案中,权威信号集中 |
规范标签和重定向在AI系统中管理重复内容的用途不同:规范标签告知搜索引擎和AI系统首选版本,但保留两个URL均可访问;而重定向则永久将用户和爬虫从一个URL导向另一个。重定向(301为永久,302为临时)信号更强,因为它们将所有权威完全合并到单一URL,并完全消除网络上的重复,非常适用于永久淘汰URL或合并域名的场景。规范标签更适合需要因业务需求保留多个URL时使用——如为分析而跟踪参数、为用户书签保留遗留URL、或为不同受众提供不同版本——同时仍向AI系统传达权威版本。迁移合并域名、删除过时版本、或消除无意义参数变体时应使用重定向。必须保留多个URL但又要防止重复内容惩罚并让AI系统理解首选版本时,应使用规范标签。
规范化与重定向的主要区别:
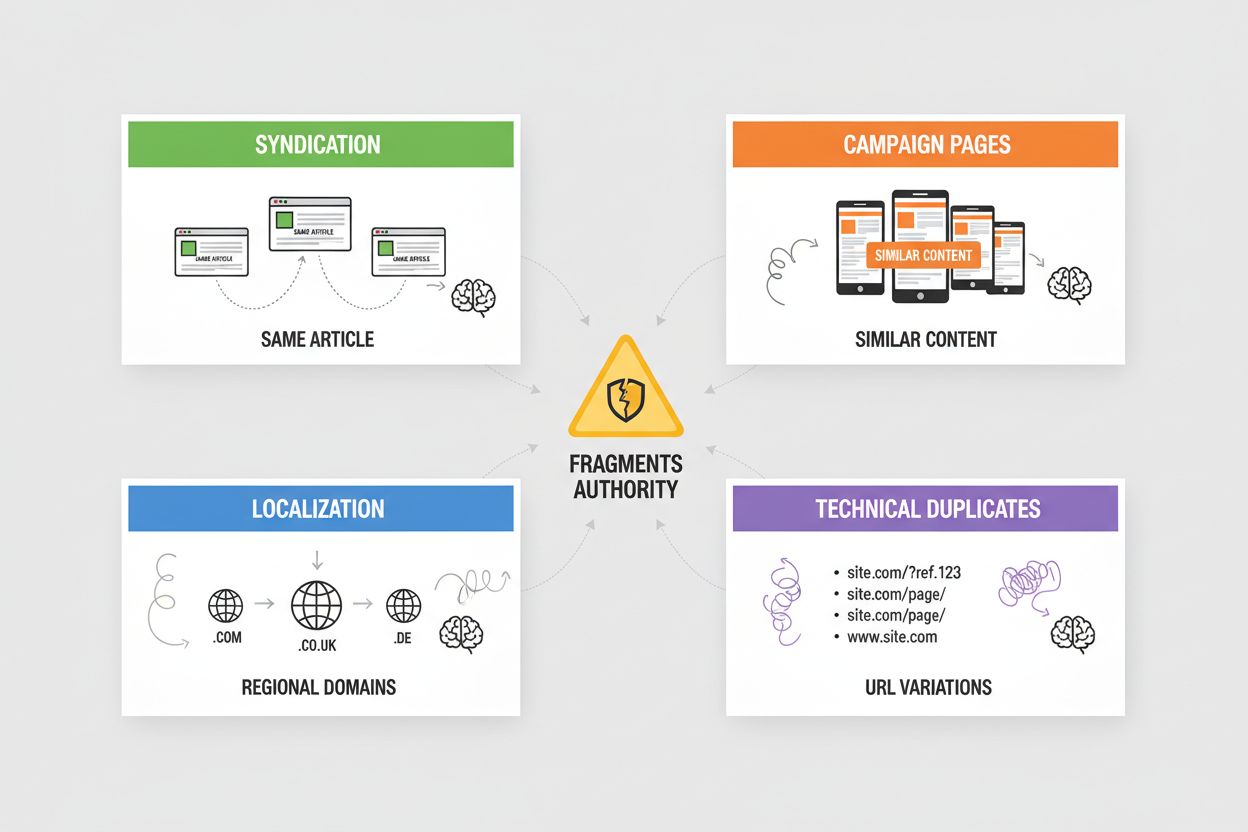
转载:当您的文章在合作伙伴网站、新闻聚合器或内容网络被再次发布时,会大量产生重复内容——AI系统必须判断归属原始来源还是转载版本,通常会默认选择首次被抓取到的版本。活动页面:为不同营销渠道、UTM参数或A/B测试创建多个内容相同或近似的着陆页时,AI系统会将权威性分散在原应整合的各个变体之间。本地化与国际化:在区域域名(如example.com、example.co.uk、example.de)或多语言版本中提供相似内容时,会产生重复内容,需要hreflang标签和规范化处理,防止AI系统将这些视为重复而非有意为之的差异。技术重复:如会话ID、跟踪参数、打印版、URL变体(www与非www、http与https、尾部斜杠差异)等都会导致多个URL指向同一内容——AI系统视为重复并需决定优先版本。上述场景都会分散原本应集中在首选URL上的权威,降低在AI答案中的可见性,引用归属也会分散到多个版本。
在规范标签中始终使用绝对URL而非相对URL,确保AI系统和搜索引擎无论标签出现在何处都能明确识别目标URL。在首选页面上包括自引用规范——即使没有重复的页面也要自指规范,防止AI系统根据链接或内容相似性自行推断规范。将规范标签放在HTML文档的<head>部分,对于非HTML内容(如PDF、图片)通过HTTP头实现规范,确保AI爬虫无论内容类型都能识别您的偏好。
<!-- HTML头部的正确规范化实现 -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
在XML网站地图中包含规范化URL以强化权威版本,并在国际化或本地化内容管理时与hreflang标签配合,防止AI系统将区域变体视为重复内容。避免常见错误:切勿形成规范化链(A→B→C),切勿指向noindex页面,切勿通过规范化指向无关内容以操控排名。使用Google Search Console、Bing Webmaster Tools和AmICited.com等工具监控您的规范化实施,确保AI系统识别您的首选URL并正确归属内容。
<!-- 国际化内容的规范化与hreflang正确实现 -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
通过Screaming Frog、SEMrush或Ahrefs全站爬行审查规范URL,查找缺失规范、规范链断裂、规范指向noindex页面等问题——这些问题会阻碍AI系统正确合并权威。使用Google Search Console覆盖率报告识别重复内容问题页面,并验证Google是否识别您的规范偏好,同时用Bing Webmaster Tools交叉检查确保AI搜索系统一致。实施IndexNow,在添加、更新或移除规范标签时立即通知搜索引擎与AI爬虫,加快规范偏好的发现,不必等待自然抓取。用AmICited.com及在ChatGPT、Claude、Perplexity中的人工搜索监控AI引用,验证您的首选URL在AI答案中是否获得归属——如果被引用的是重复版本,需重查规范实现确保标签格式正确并位于正确位置。定期审查因转载合作、活动发布或技术变更产生的新重复内容,主动实施规范化而非事后补救,确保AI可见性持续一致。
规范化URL是您希望搜索引擎和AI系统认定为权威的页面首选版本。它对AI搜索很重要,因为大语言模型会将近似重复的URL聚类,并选择一个版本作为该组的代表。如果未正确实施规范化,AI系统可能会引用您内容的错误版本,导致您的可见性和归属在多个URL之间被分散。
AI系统使用聚类算法将近似重复的URL分组为单一实体,然后选择一个版本代表整个集群。这与传统搜索引擎不同,因为AI答案需要一个来源URL进行归属。如果您的规范化未正确实施,AI可能会选择转载版本、缓存副本或质量较低的变体,而不是您首选的URL。
当您因业务需要(如跟踪参数、遗留URL、面向不同受众)必须保留多个URL时,应使用规范标签,同时向AI系统指明首选版本。当永久淘汰URL、合并域名或消除无意义参数变体时,应使用重定向。重定向信号更强,因为它们完全合并权威性,而规范标签则分散权威但传达偏好。
最常见的问题包括:转载(合作伙伴网站再次发布的文章)、活动页面(多个着陆页内容相同)、本地化(区域域名内容相似)、技术重复(URL参数、会话ID、斜杠差异)。这些问题都会使权威性分散到多个URL,降低AI答案中的可见性。
始终使用绝对URL(如https://example.com/page,不要用/page),将规范标签放在HTML头部,在所有页面上包含自引用规范,并避免形成规范链(A→B→C)。对于非HTML内容如PDF,使用HTTP头实现规范化。在XML网站地图中包含规范URL,并与hreflang标签配合用于国际化内容。
使用Google Search Console和Bing Webmaster Tools验证规范化识别情况,通过AmICited.com和在ChatGPT/Claude/Perplexity中的人工搜索监控AI引用,使用Screaming Frog或SEMrush等爬虫工具对网站进行审计。如果被引用的是重复版本而不是您的规范化URL,请重新检查实现方式,确保标签格式正确且位于HTML头部。
IndexNow是一项协议,可在您添加、更新或移除规范标签时立即通知搜索引擎和AI爬虫,无需等待自然抓取周期。这加快了规范化偏好的发现,有助于AI系统更快识别您的首选URL,减少重复内容在AI答案中出现的时间。
会的,规范标签是强烈信号,但不是指令。如果AI系统根据内容质量、链接模式、新鲜度或其他信号判断其他版本更具权威性,可能会覆盖您的规范偏好。因此,规范化实施要与强内容和权威信号结合,提高AI系统尊重您的规范偏好的概率。
了解在使用 AI 工具时如何管理和防止重复内容。发现规范标签、重定向、检测工具及维护网站内容唯一性的最佳实践。
社区讨论规范标签如何影响 AI 可见性。防止 ChatGPT、Perplexity 和 Google AI Overviews 中引用内耗的策略。
了解什么是规范 URL,它如何防止重复内容问题,以及为何对 SEO 至关重要。理解 rel=canonical 标签和规范实施最佳实践。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.