阻止AI训练但允许搜索:选择性爬虫控制
了解如何实施选择性AI爬虫屏蔽,保护您的内容不被训练机器人抓取,同时在AI搜索结果中保持可见性。为出版方提供的技术策略。...
2 分钟阅读

阻止AI爬虫访问或正确索引内容的技术问题。当人工智能驱动的系统由于JavaScript依赖、缺少结构化数据、robots.txt限制或服务器配置问题等技术障碍而无法检索、解释或理解网站内容时,就会发生这些错误。与传统搜索引擎爬取错误不同,AI爬取错误可能会阻止语言模型和AI助手在其系统中准确表示您的内容。
阻止AI爬虫访问或正确索引内容的技术问题。当人工智能驱动的系统由于JavaScript依赖、缺少结构化数据、robots.txt限制或服务器配置问题等技术障碍而无法检索、解释或理解网站内容时,就会发生这些错误。与传统搜索引擎爬取错误不同,AI爬取错误可能会阻止语言模型和AI助手在其系统中准确表示您的内容。
AI爬取错误发生在人工智能驱动的爬虫在索引过程中未能正确访问、检索或解释网站内容时。这些错误代表了您的网站向人类访问者显示的内容与AI系统实际可以理解和用于训练、检索或分析目的的内容之间的关键差距。与主要影响搜索结果可见性的传统搜索引擎爬取错误不同,AI爬取错误可能会阻止语言模型、AI助手和内容聚合平台在其系统中准确表示您的内容。后果范围从AI生成响应中对您品牌的错误表示到完全被排除在AI训练数据集和检索系统之外。理解和解决这些错误对于在日益AI驱动的信息生态系统中维护您的数字存在至关重要。

AI爬虫与传统搜索引擎爬虫(如Googlebot)的运作方式根本不同,需要采用不同的技术方法来确保正确的内容可访问性。虽然搜索引擎已大量投资于JavaScript渲染能力并可以执行动态内容,但大多数AI爬虫检索和分析原始HTML响应而不渲染JavaScript,这意味着它们只能看到初始服务器响应中交付的内容。这种区别造成了关键的技术鸿沟:一个网站可能对Google的爬虫完美渲染,但对无法执行客户端代码的AI系统完全不可访问。此外,AI爬虫通常以不同的频率和不同的用户代理模式运行,一些(如Perplexity使用的)采用隐身爬取技术绕过传统的robots.txt限制,而其他如OpenAI的爬虫则遵循更传统的道德爬取实践。下表说明了这些关键差异:
| 特征 | 搜索引擎爬虫 | AI爬虫 |
|---|---|---|
| JavaScript渲染 | 完全渲染能力 | 有限或无渲染 |
| 爬取频率 | 周期性,基于权威性 | 通常更频繁 |
| Robots.txt合规性 | 严格遵守 | 可变(有些绕过) |
| 用户代理透明度 | 清晰标识 | 有时隐身/混淆 |
| 内容解释 | 基于关键词和链接 | 需要语义理解 |
| 所需响应类型 | 渲染的HTML | 原始HTML或API访问 |
AI爬取错误表现为几个不同的类别,每个都需要不同的诊断和修复方法。最常见的错误包括:
JavaScript渲染是网站和AI爬虫之间最重要的障碍之一,因为绝大多数AI系统无法执行客户端代码来显示动态生成的内容。当您的网站依赖React、Vue或Angular等JavaScript框架在初始页面加载后填充内容时,AI爬虫收到的是一个空的或最小的HTML外壳,其中不包含任何实际要分析的内容。这造成了一个根本性的可访问性问题:您的网站可能对人类用户显示精美且功能完善,但AI系统只看到JavaScript代码本身而不是渲染的输出。这种区别至关重要,因为AI爬虫分析的是原始HTTP响应——服务器在任何浏览器处理之前发送的内容——而不是用户看到的最终渲染DOM。为解决此问题,网站应实施服务器端渲染(SSR)或静态站点生成(SSG)以确保内容存在于初始HTML响应中,使用为爬虫预渲染内容的动态渲染服务,或提供AI爬虫可以直接访问的API等替代内容交付方法。
Robots.txt文件作为向自动化系统传达爬取偏好的主要机制,但其有效性在具有不同道德标准和商业模式的不同AI爬虫之间差异很大。传统搜索引擎如Google尊重robots.txt指令,不会爬取这些规则明确阻止的内容,使其成为控制搜索引擎访问的可靠工具。然而,AI爬虫领域更加碎片化:一些AI公司如OpenAI已承诺尊重robots.txt并为内容创作者提供选择退出训练数据收集的机制,而其他公司则使用故意绕过robots.txt限制的隐身爬虫来收集训练数据。这造成了一种复杂情况,网站所有者不能仅依靠robots.txt来控制AI爬虫访问,特别是对于那些想阻止其内容被用于AI训练数据集的公司。最有效的方法是将robots.txt规则与额外的技术措施相结合,如监控哪些AI爬虫正在访问您网站的工具、为已知AI爬虫实施用户代理特定规则,以及使用AmICited.com等工具来监控和验证实际爬虫行为是否符合声明的政策。
结构化数据和语义标记对AI系统理解变得越来越重要,因为这些元素提供了明确的上下文,帮助AI爬虫比单独的原始文本更有效地理解内容含义、关系和实体信息。当您实施Schema.org标记、JSON-LD结构化数据或其他语义格式时,您实际上创建了一个机器可读层,描述您的内容是关于什么的、谁创建的、何时发布的,以及它与其他实体和概念的关系。AI系统严重依赖这些结构化信息来准确表示其系统中的内容、生成更相关的响应,并理解信息的权威来源。例如,具有正确NewsArticle schema标记的新闻文章允许AI系统确定地识别发布日期、作者、标题和文章正文,而没有标记的相同内容要求AI系统通过自然语言处理推断这些信息,这更容易出错。缺少结构化数据迫使AI爬虫对内容做出假设,通常导致错误表示、错误归因或无法识别重要的内容区别。
除了JavaScript和robots.txt之外,许多技术基础设施问题可能阻止AI爬虫成功访问和处理您的网站内容。服务器端问题如配置错误的SSL证书、过期的HTTPS证书或不正确的HTTP头配置可能导致爬虫完全放弃请求,特别是可能比传统浏览器有更严格安全要求的AI爬虫。旨在防止滥用的速率限制和IP阻止机制可能无意中阻止合法的AI爬虫,特别是如果您的安全系统不识别爬虫的用户代理或IP范围。不正确的Content-Type头、缺少或错误的字符编码声明和格式错误的HTML可能导致AI爬虫错误解释内容或无法正确解析。此外,过于激进的缓存策略无论用户代理如何都提供相同内容可能阻止爬虫接收适当的内容变体,而导致超时或响应时间慢的服务器资源不足可能超过AI爬取系统的超时阈值。
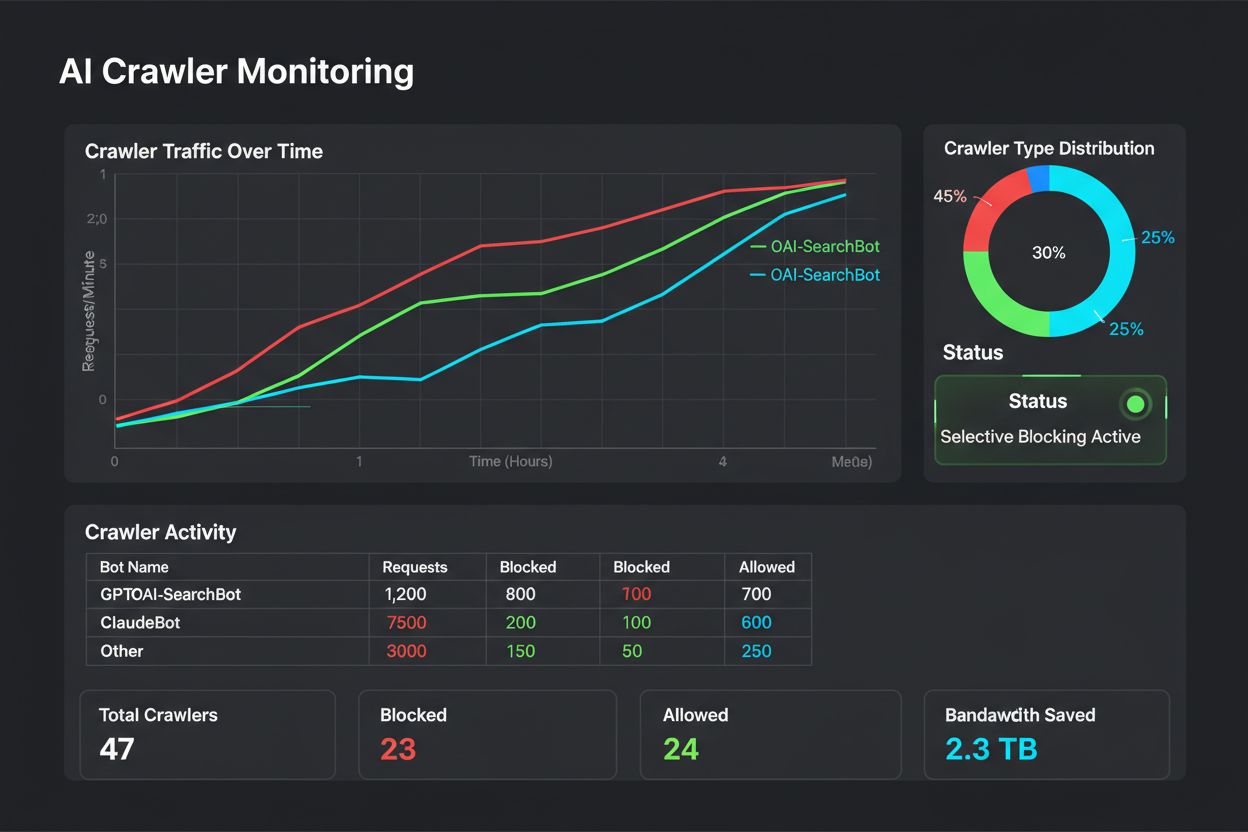
检测AI爬取错误需要一种多层次的监控方法,超越传统的搜索引擎爬取错误报告,因为大多数网站分析和SEO工具只关注搜索引擎爬虫而不是AI系统。服务器日志分析提供了基础层,让您能够识别哪些AI爬虫正在访问您的网站、它们爬取的频率、它们请求什么内容以及它们收到什么HTTP状态码响应。通过检查访问日志中的用户代理字符串,您可以识别特定的AI爬虫,如GPTBot、Perplexity的爬虫或其他AI系统,并分析它们的爬取模式和成功率。AmICited.com等工具提供专门为AI爬虫跟踪和错误检测设计的专业监控,提供对不同AI系统如何访问和解释您内容的洞察。此外,您可以通过模拟AI爬虫行为进行手动测试——在浏览器中禁用JavaScript,使用curl或wget获取页面作为原始HTML,并分析非渲染爬虫实际可用的内容。监控您网站在ChatGPT、Perplexity和Claude等AI系统的AI生成响应和搜索结果中的外观,可以揭示您的内容是否正在被正确索引和表示,提供对您可爬取性状态的真实验证。
解决AI爬取错误需要一个全面的策略,同时解决您网站的技术基础设施和内容交付机制。首先,通过在禁用JavaScript的情况下测试页面来审计您网站的可爬取性,以识别非渲染爬虫无法访问的内容,然后优先将JavaScript依赖内容转换为服务器端渲染或提供替代内容交付方法。在所有内容类型中实施全面的Schema.org结构化数据标记,确保AI系统可以理解内容上下文、作者身份、发布日期和实体关系,而不仅仅依赖自然语言处理。审查和优化您的robots.txt文件,明确允许您希望索引您内容的AI爬虫,同时阻止那些您不希望的,但要认识到这种方法对不合规的爬虫有局限性。确保您网站的技术基础设施是健壮的:验证SSL证书有效且正确配置,实施适当的HTTP头,使用正确的Content-Type和字符编码声明,并确保服务器响应时间足够。监控您网站在AI系统中的实际外观,并使用AmICited.com等专业工具来跟踪不同AI爬虫如何访问您的内容并实时识别错误。建立定期的爬取错误监控例程,检查服务器日志中的AI爬虫活动,分析响应代码和模式,并在新出现的问题显著影响您的AI可见性之前识别它们。最后,随时了解不断发展的AI爬虫标准和最佳实践,因为该领域随着新爬虫、更新的道德准则和不断变化的技术要求而继续快速发展。
AI爬取错误特别影响人工智能系统如何访问和解释您的内容,而传统SEO爬取错误影响搜索引擎可见性。关键区别在于AI爬虫通常不渲染JavaScript,并且与Google等搜索引擎具有不同的爬取模式、用户代理和合规标准。一个页面可能完全可以被Googlebot爬取,但对AI系统完全不可访问。
是的,您可以使用robots.txt阻止AI爬虫,但效果各不相同。一些AI公司如OpenAI遵守robots.txt指令,而其他如Perplexity已被记录使用隐身爬虫绕过这些限制。为了更可靠的控制,使用AmICited.com等专业监控工具来跟踪实际爬虫行为,并在robots.txt之外实施额外的技术措施。
监控您的服务器日志中的AI爬虫用户代理(GPTBot、Perplexity、ChatGPT-User等)并分析它们的HTTP响应代码。使用AmICited.com等专业工具提供AI爬虫活动的实时跟踪。此外,禁用JavaScript测试您的网站,查看非渲染爬虫实际可以访问哪些内容,并监控您的内容如何出现在AI生成的响应中。
是的,影响很大。大多数AI爬虫无法渲染JavaScript,只能看到服务器返回的原始HTML响应。通过React或Vue等JavaScript框架动态加载的内容对AI系统是不可见的。为确保AI可爬取性,请实施服务器端渲染(SSR)、静态站点生成(SSG)或提供API等替代内容交付方法。
Robots.txt是向AI系统传达爬取偏好的主要机制,但其有效性不一致。有道德的AI公司尊重robots.txt指令,而其他公司则绕过它们。最有效的方法是将robots.txt规则与实时监控工具相结合,以验证实际爬虫行为并实施额外的技术控制。
结构化数据对AI爬虫至关重要。Schema.org标记、JSON-LD和其他语义格式帮助AI系统理解内容含义、作者身份、发布日期和实体关系。没有结构化数据,AI系统必须依赖自然语言处理来推断这些信息,这容易出错,可能导致您的内容在AI生成的响应中被错误表示。
AI爬取错误可能导致您的内容被排除在AI训练数据集之外、在AI生成的响应中被错误表示,或对语言模型和AI助手完全不可见。这影响您品牌在答案引擎中的可见性,减少引用机会,并可能损害您在AI搜索结果中的权威性。后果特别严重,因为AI爬虫在初次失败后通常不会返回重新爬取内容。
实施服务器端渲染以确保内容在初始HTML响应中,添加全面的Schema.org结构化数据标记,为AI爬虫优化您的robots.txt,确保具有正确SSL证书和HTTP头的强大服务器基础设施,监控Core Web Vitals,并使用AmICited.com等工具实时跟踪实际AI爬虫行为并识别错误。
了解如何实施选择性AI爬虫屏蔽,保护您的内容不被训练机器人抓取,同时在AI搜索结果中保持可见性。为出版方提供的技术策略。...

了解如何审计AI爬虫对您网站的访问。发现哪些机器人可以看到您的内容,并修复阻止AI在ChatGPT、Perplexity及其他AI搜索引擎中可见性的障碍。...

了解如何让 ChatGPT、Perplexity 以及谷歌 AI 等 AI 爬虫能够看到你的内容。发现针对 AI 搜索可见性的技术要求、最佳实践以及监控策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.