
Jak si ChatGPT vybírá, které zdroje citovat? Kompletní průvodce
Zjistěte, jak ChatGPT vybírá a cituje zdroje při procházení webu. Seznamte se s faktory důvěryhodnosti, vyhledávacími algoritmy a tím, jak optimalizovat svůj ob...
7 min čtení

Zjistěte, odkud ChatGPT získává svá tréninková data, jak cituje zdroje, data uzávěrky znalostí a proč je důležité sledovat AI citace pro vaši značku.
Základ znalostí ChatGPT je postaven na rozmanité sbírce veřejně dostupných internetových dat, kombinovaných s licencovanými datasety a zpětnou vazbou od lidí. Model byl trénován na třech hlavních zdrojích: veřejně dostupných internetových datech (webové stránky, články a online obsah), licencovaných datasetech (včetně knih a akademických publikací) a lidské zpětné vazbě od trenérů, kteří pomáhali s vyladěním odpovědí. Tato tréninková data zahrnují mimořádně široké spektrum zdrojů včetně zpravodajských webů, akademických časopisů, knih, technické dokumentace, fór jako Reddit a Stack Overflow, článků z Wikipedie a nespočet dalších veřejně přístupných webových stránek. Obrovské množství a rozmanitost těchto zdrojů—napříč mnoha jazyky, obory i pohledy—vytváří komplexní znalostní základnu, která ChatGPT umožňuje diskutovat témata od kvantové fyziky přes středověké dějiny až po současnou popkulturu. Je však důležité si uvědomit, že ChatGPT nemá přístup k informacím v reálném čase ani k proprietárním databázím; čerpá pouze z toho, co bylo dostupné během jeho tréninkového období.
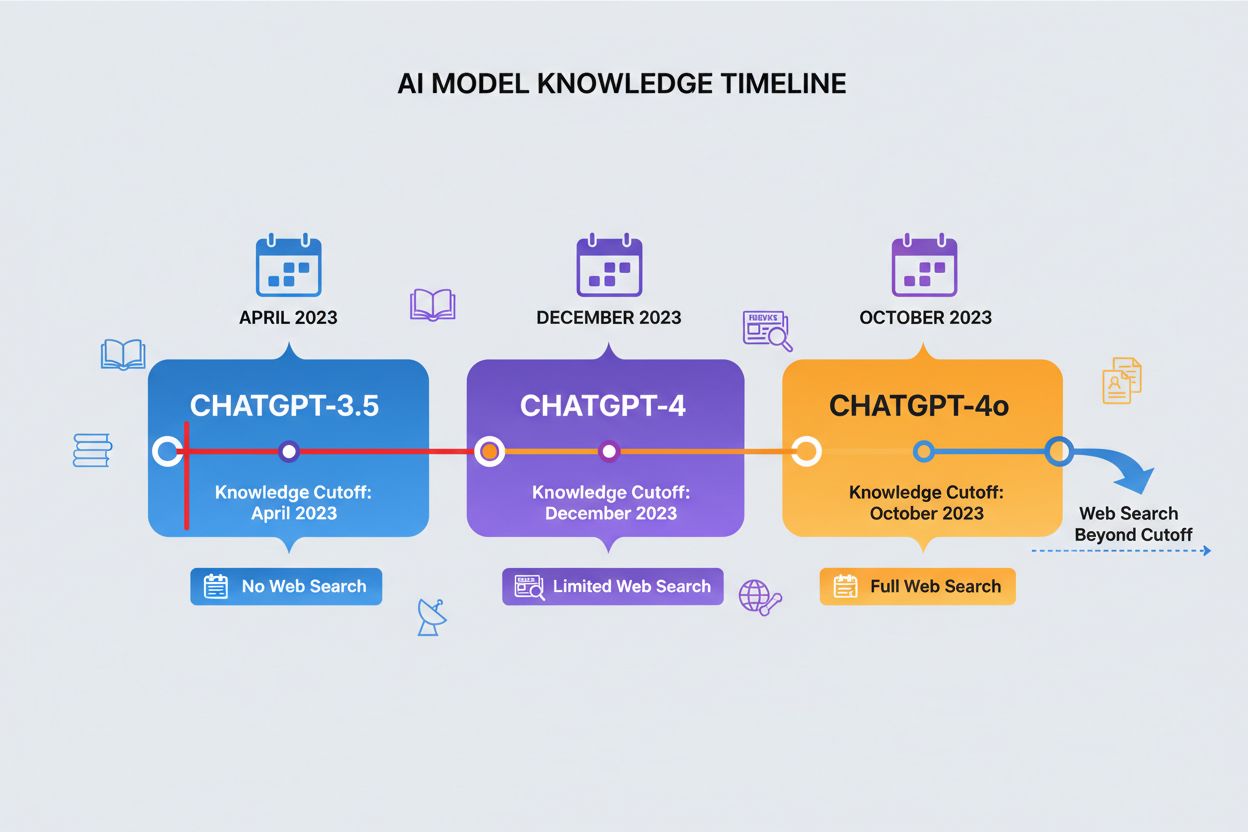
Datum uzávěrky znalostí představuje časový bod, po kterém ChatGPT nemá žádná tréninková data, což vytváří ostrou hranici pro informace, ke kterým má přístup. Různé verze ChatGPT mají různá data uzávěrky: ChatGPT-4 byl trénován na datech do prosince 2023, zatímco ChatGPT-4o (optimalizovaná verze) má uzávěrku říjen 2023. Tato data uzávěrky výrazně ovlivňují přesnost a aktuálnost odpovědí, zejména u nedávných událostí, nově publikovaného výzkumu nebo aktuálních statistik, které se mohly od sběru dat změnit. Některé novější verze ChatGPT umí provádět webové vyhledávání, aby získaly aktuální informace nad rámec data uzávěrky, tato funkce však není dostupná ve všech verzích či prostředích. Znalost data uzávěrky modelu je zásadní pro uživatele, kteří potřebují aktuální informace, protože ChatGPT nemůže poskytnout přesné odpovědi na události či vývoj, které nastaly až po skončení jeho tréninkového období. Toto omezení patří mezi nejdůležitější faktory při hodnocení spolehlivosti ChatGPT u časově citlivých dotazů.
| Verze ChatGPT | Datum uzávěrky znalostí | Schopnost webového vyhledávání | Hlavní použití |
|---|---|---|---|
| ChatGPT-4 | Prosinec 2023 | Omezená | Obecné znalosti, analýzy, uvažování |
| ChatGPT-4o | Říjen 2023 | Dostupná | Optimalizovaný výkon, multimodální úlohy |
| ChatGPT-3.5 | Duben 2023 | Ne | Základní dotazy, úsporná varianta |
| ChatGPT s prohlížením | Reálný čas | Ano | Aktuální události, nedávný výzkum |
Na rozdíl od vyhledávačů, které vyhledávají konkrétní dokumenty nebo webové stránky na základě dotazů, ChatGPT generuje odpovědi syntetizováním vzorců naučených během tréninku—což je zásadně odlišný proces. Když se ChatGPT na něco zeptáte, neprohledává databázi ani index; místo toho využívá statistické vzorce ze svých tréninkových dat k předpovědi nejpravděpodobnější posloupnosti slov, která by tvořila užitečnou odpověď. Tento generativní přístup znamená, že ChatGPT kombinuje informace z více zdrojů svých tréninkových dat a vytváří nové odpovědi, které nemusí nikde ve zdrojových materiálech existovat doslova. Model se v podstatě učí vztahy mezi pojmy, fakty a myšlenkami a poté tyto znalosti rekonstruuje podle konkrétního dotazu. Tento proces má však zásadní nevýhodu: pokud si model není informacemi jistý nebo jsou vzorce v tréninkových datech rozporné či řídké, může generovat věrohodně znějící, ale nepravdivé informace, což se označuje jako “halucinace”. Novější verze ChatGPT, které integrují funkci webového vyhledávání, mohou tento generativní proces doplnit získáváním aktuálních informací z internetu, tato možnost však vyžaduje explicitní aktivaci a není dostupná ve všech prostředích.
Tréninková data ChatGPT pocházejí z několika hlavních kategorií zdrojů, z nichž každá přináší do znalostní základny unikátní hodnotu:
Význam těchto různorodých zdrojů spočívá v jejich vzájemně se doplňujících přednostech: akademické práce přinášejí důslednost, zpravodajské články aktuálnost, knihy hloubku a fóra praktickou aplikaci. Kvalita zdrojů se však liší—recenzovaná akademická práce má větší váhu než náhodný blog, přesto proces tréninku ChatGPT mezi nimi explicitně nerozlišuje. To znamená, že znalosti ChatGPT odrážejí jak vysoce kvalitní autoritativní zdroje, tak i méně kvalitní nebo potenciálně zavádějící obsah, a proto je při používání modelu pro důležitá rozhodnutí nezbytné ověřovat informace.
Po úvodním tréninku na obrovském množství textových dat použila společnost OpenAI techniku zvanou Reinforcement Learning from Human Feedback (RLHF) k vyladění odpovědí ChatGPT. V tomto procesu lidskí trenéři hodnotili výstupy modelu a poskytovali zpětnou vazbu, která systému pomohla naučit se, které odpovědi jsou užitečnější, přesnější a lépe odpovídají lidským hodnotám. Tito trenéři však neověřovali pravdivost každého tvrzení, ale hodnotili celkovou kvalitu odpovědi, užitečnost a bezpečnost, což nepřímo ovlivnilo, jak model informace upřednostňuje a prezentuje. Proces RLHF významně ovlivňuje, jaké informace jsou v odpovědích zdůrazňovány a jak jsou různá témata rámována, čímž se do čistě statistického modelu vnáší lidský úsudek. Tento proces však má svá omezení: trenéři mají své vlastní předsudky, mezery ve znalostech a omezení a nemohou posoudit správnost všech tvrzení napříč obory. Navíc je tento proces časově náročný a lze jej aplikovat jen na zlomek možných odpovědí modelu, takže chování ChatGPT stále do značné míry odráží surové vzorce v tréninkových datech spíš než explicitní lidskou kuraci.
Citování ChatGPT je důležité pro akademickou integritu a transparentnost, protože umožňuje čtenářům zjistit, odkud informace pocházejí a případně vaše zjištění ověřit nebo reprodukovat. Formát citace závisí na požadovaném citačním stylu, zde jsou nejběžnější postupy:
Příklad formátu MLA:
OpenAI. "ChatGPT." Přístup dne [Datum], https://chat.openai.com.
V MLA stylu citujete ChatGPT jako webovou stránku, včetně data přístupu, protože obsah je dynamický a může se měnit. Pokud citujete konkrétní odpověď, měli byste uvést datum přístupu a ideálně i prompt nebo otázku, kterou jste zadali.
Příklad formátu APA:
OpenAI. (2024). ChatGPT (verze 4) [velký jazykový model].
Získáno z https://chat.openai.com
APA formát považuje ChatGPT za softwarový nástroj nebo aplikaci, včetně čísla verze a data získání. Některé pokyny APA doporučují uvést v citaci i konkrétní prompt nebo jej připojit jako dodatek.
Kdy citovat ChatGPT: Nástroj byste měli citovat vždy, když jeho výstup použijete v akademické práci, odborné zprávě či v jakémkoli kontextu, kde záleží na uvedení zdroje. Zaznamenejte přesný prompt, datum přístupu a ideálně i verzi ChatGPT, protože tyto údaje ovlivňují reprodukovatelnost. Klíčovým rozdílem mezi citací ChatGPT a tradičních zdrojů je, že odpovědi ChatGPT jsou dynamicky generované—stejný prompt může při různých příležitostech vést k mírně odlišným výstupům—takže součástí správné citace se stává i samotný prompt. Mnohé instituce stále vytvářejí formální pokyny pro citace AI, proto si ověřte preferovaný formát u konkrétní organizace či vydavatele.
Ačkoliv je ChatGPT pozoruhodně schopný, má významná omezení, která ovlivňují spolehlivost jeho informací. ChatGPT může sebevědomě uvádět nepravdivé informace, což je problém známý jako halucinace, zejména při dotazech na méně známá témata, nedávné události po datu uzávěrky znalostí nebo v případě rozporuplných informací ve svých datech. Tréninková data modelu obsahují přirozené předsudky odrážející perspektivy, demografii a názory přítomné ve zdrojových materiálech, což může vést k tomu, že odpovědi upřednostňují určité pohledy nebo obsahují stereotypy. Informace v tréninkových datech ChatGPT postupem času zastarávají, takže nejsou spolehlivé pro aktuální statistiky, nejnovější výzkumy nebo dynamické situace. Proto je ověřování tvrzení ChatGPT zásadní, zvláště při důležitých rozhodnutích—klíčová fakta si ověřujte v primárních zdrojích, nedávných publikacích a autoritativních databázích. Pro ověření tvrzení ChatGPT porovnejte jeho výroky s nezávislými zdroji, zkontrolujte data a statistiky vůči aktuálním údajům a buďte obzvlášť opatrní u konkrétních čísel, jmen nebo nedávných událostí. Nakonec mějte na paměti, že ChatGPT není primární zdroj; jde o sekundární zdroj, který syntetizuje informace z jiných zdrojů, takže pro akademickou či odbornou práci citujte raději původní zdroje, ke kterým ChatGPT odkazuje, nikoliv ChatGPT samotný.
Jak se ChatGPT a další AI systémy stávají stále důležitějšími v procesu objevování informací, sledování, jak tyto systémy citují a zmiňují vaši značku nebo organizaci, se stává zásadním. AmICited je platforma pro monitoring AI odpovědí navržená speciálně ke sledování toho, jak ChatGPT, Claude a další velké jazykové modely zmiňují, citují nebo odkazují na vaši společnost, produkty či značku ve svých odpovědích. Platforma vám pomáhá zjistit, kdy a jak se vaše značka objevuje v odpovědích generovaných AI, a poskytuje přehled o novém a rostoucím kanálu objevování informací, který tradiční nástroje pro monitoring webu často přehlížejí. Tato schopnost sledování je zásadní, protože AI citace fungují jinak než tradiční webové citace—jsou součástí konverzačních odpovědí, se kterými denně interagují miliony uživatelů, a přesto většina značek nemá přehled o tom, jak jsou prezentovány. Pomocí AmICited ke sledování zmínek a citací AI získáte přehled o vnímání značky v AI systémech, můžete identifikovat nepřesnosti či zastaralé informace, které je potřeba opravit, a pochopit, jak si vaše značka stojí vůči konkurenci v AI odpovědích. V době, kdy se AI systémy stávají pro mnoho uživatelů primárním zdrojem informací, je sledování vaší přítomnosti v těchto systémech stejně důležité jako monitoring tradičních výsledků vyhledávání, takže nástroje jako AmICited jsou klíčové pro moderní správu značky a transparentnost AI.
ChatGPT byl trénován na třech hlavních zdrojích: veřejně dostupných datech z internetu (webové stránky, články, fóra), licencovaných datasetech (knihy a akademické publikace) a lidské zpětné vazbě od trenérů. Tréninková data zahrnují zpravodajské weby, akademické časopisy, technickou dokumentaci, Wikipedii, Reddit, Stack Overflow a nespočet dalších veřejně přístupných webových stránek shromážděných do data uzávěrky znalostí.
Datum uzávěrky znalostí je okamžik, po kterém ChatGPT nemá žádná tréninková data. ChatGPT-4 má uzávěrku prosinec 2023, zatímco ChatGPT-4o má uzávěrku říjen 2023. To je důležité, protože ChatGPT nemůže poskytovat přesné informace o událostech, výzkumu nebo novinkách, které nastaly po skončení jeho tréninkového období, což jej činí nespolehlivým pro časově citlivé dotazy.
ChatGPT nemůže přistupovat k informacím v reálném čase pouze ze svých tréninkových dat. Novější verze ChatGPT však mohou provádět webové vyhledávání a získat aktuální informace nad rámec data uzávěrky znalostí, tato funkce ale není dostupná ve všech verzích nebo kontextech a vyžaduje explicitní aktivaci.
V MLA formátu citujte ChatGPT jako webovou stránku s datem přístupu. V APA formátu jej uvádějte jako software a přidejte číslo verze. Obě formy vyžadují zaznamenání přesného zadaného promptu, data přístupu a ideálně i verze ChatGPT, protože stejný prompt může při různých příležitostech přinést různé výstupy.
Ne. ChatGPT může sebevědomě sdělovat nepravdivé informace (halucinace), zejména o méně známých tématech, nedávných událostech po datu uzávěrky znalostí nebo v případě rozporných informací. Jeho tréninková data obsahují určité přirozené předsudky a informace postupně zastarávají. Vždy si důležité tvrzení ověřujte u primárních zdrojů a autoritativních databází.
Tréninková data ChatGPT nejsou průběžně aktualizována. Nové verze jsou vydávány periodicky s aktualizovaným datem uzávěrky znalostí, ale základní model není aktualizován v reálném čase. OpenAI vydává nové verze (například GPT-4o) s novějšími tréninkovými daty, ale přesný harmonogram aktualizací není veřejně znám.
ChatGPT necituje konkrétní zdroje jednotlivých tvrzení, protože informace syntetizuje ze vzorců ve svých tréninkových datech a nevyhledává konkrétní dokumenty. Nemůže tedy ukázat přesný původ faktu. Pro akademickou práci byste měli tvrzení ověřit a citovat původní zdroje, které naleznete, nikoliv samotný ChatGPT.
AmICited sleduje, jak ChatGPT, Claude a další AI systémy zmiňují, citují nebo odkazují na vaši značku ve svých odpovědích. Poskytuje přehled o tom, jak se vaše firma objevuje v odpovědích generovaných AI, pomáhá odhalit nepřesnosti a ukazuje, jak si vaše značka vede v porovnání s konkurencí v AI systémech—což je zásadní pro moderní správu značky v éře AI.
Sledujte citace ChatGPT a zmínky AI v reálném čase pomocí AmICited. Porozumějte tomu, jak AI systémy odkazují na vaši značku a buďte o krok napřed v objevování informací pomocí AI.
Zjistěte, jak ChatGPT vybírá a cituje zdroje při procházení webu. Seznamte se s faktory důvěryhodnosti, vyhledávacími algoritmy a tím, jak optimalizovat svůj ob...
Zjistěte, jak optimalizovat svou přítomnost na Redditu pro AI citace. Ovládněte strategie seedování Reddit LLM, abyste zvýšili viditelnost značky v ChatGPT, Per...
Diskuze komunity o rozdílech mezi ChatGPT a ChatGPT Search. Reálné zkušenosti marketérů s optimalizací obsahu pro oba systémy – na základě trénovacích dat i živ...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.