Jak strukturovat obsah pro AI citace? Kompletní průvodce pro rok 2025
Zjistěte, jak strukturovat svůj obsah, abyste získali citace od AI vyhledávačů jako ChatGPT, Perplexity a Google AI. Odborné strategie pro viditelnost a citace ...
8 min čtení

Naučte se, jak strukturovat obsah do optimálních délek pasáží (100–500 tokenů) pro maximální počet AI citací. Objevte strategie dělení, které zvyšují viditelnost v ChatGPT, Google AI Overviews a Perplexity.
Dělení obsahu se stalo klíčovým faktorem v tom, jak systémy jako ChatGPT, Google AI Overviews a Perplexity získávají a citují informace z webu. Jak tyto AI-driven platformy stále více ovládají uživatelské dotazy, způsob, jak strukturovat obsah do optimálních délek pasáží, přímo ovlivňuje, zda bude vaše práce objevena, získána a – co je nejdůležitější – citována těmito systémy. To, jak rozčleníte svůj obsah, určuje nejen viditelnost, ale i kvalitu a frekvenci citací. AmICited.com monitoruje, jak AI systémy citují váš obsah a naše výzkumy ukazují, že správně dělené pasáže získávají 3–4× více citací než špatně strukturovaný obsah. Už to není jen o SEO; jde o to, aby se vaše odbornost dostala k AI publikům ve formátu, kterému rozumí a dokáží jej správně přiřadit. V tomto průvodci prozkoumáme vědecké základy dělení obsahu a jak optimalizovat délku pasáží pro maximální potenciál AI citací.
Dělení obsahu je proces rozdělování větších částí na menší, sémanticky smysluplné úseky, které AI systémy mohou samostatně zpracovat, pochopit a získávat. Na rozdíl od tradičních odstavců jsou úseky strategicky navržené jednotky, které udržují kontextovou integritu a zároveň jsou dostatečně malé, aby je AI modely efektivně zpracovaly. Hlavní znaky efektivních úseků jsou: sémantická ucelenost (každý úsek předává kompletní myšlenku), optimální hustota tokenů (100–500 tokenů na úsek), jasné hranice (logický začátek a konec) a kontextová relevance (úseky se vztahují ke konkrétním dotazům). Rozlišení mezi strategiemi dělení je zásadní – různé přístupy přinášejí různé výsledky pro AI vyhledávání a citace.
| Metoda dělení | Velikost úseku | Nejlepší pro | Míra citací | Rychlost načítání |
|---|---|---|---|---|
| Dělení na pevnou velikost | 200–300 tokenů | Obecný obsah | Střední | Rychlá |
| Sémantické dělení | 150–400 tokenů | Tématicky zaměřené | Vysoká | Střední |
| Posuvné okno | 100–500 tokenů | Dlouhý obsah | Vysoká | Pomalejší |
| Hierarchické dělení | Proměnlivá | Složitá témata | Velmi vysoká | Střední |
Výzkum společnosti Pinecone ukazuje, že sémantické dělení překonává přístup s pevnou velikostí o 40 % v přesnosti vyhledávání, což se přímo promítá do vyšší míry citací, když AmICited.com sleduje váš obsah napříč AI platformami.
Vztah mezi délkou pasáže a výkonem AI vyhledávání je hluboce zakořeněn v tom, jak velké jazykové modely zpracovávají informace. Moderní AI systémy pracují v rámci limitů tokenů – obvykle 4 000–128 000 tokenů podle modelu – a musí balancovat využití kontextového okna s efektivitou načítání. Když jsou pasáže příliš dlouhé (500+ tokenů), zabírají příliš mnoho místa v kontextu a zhoršují poměr signálu k šumu, což AI ztěžuje identifikaci nejrelevantnějších informací pro citaci. Naopak příliš krátké pasáže (pod 75 slov) neposkytují dostatek kontextu, aby AI pochopila nuance a udělala si jisté závěry pro citace. Optimální rozmezí 100–500 tokenů (cca 75–350 slov) představuje ideální střed – AI systémy zde dokážou získat smysluplné informace bez zbytečné zátěže. Výzkum NVIDIA o stránkovém dělení zjistil, že pasáže v tomto rozmezí mají nejvyšší přesnost jak při vyhledávání, tak při přiřazení zdroje. Pro kvalitu citace je to důležité, protože AI systémy častěji citují pasáže, které plně chápou a dokážou zasadit do kontextu. Když AmICited.com analyzuje vzory citací, pravidelně zjišťujeme, že obsah strukturovaný v tomto optimálním rozmezí získává citace 2,8× častěji než obsah s nepravidelnou délkou pasáží.
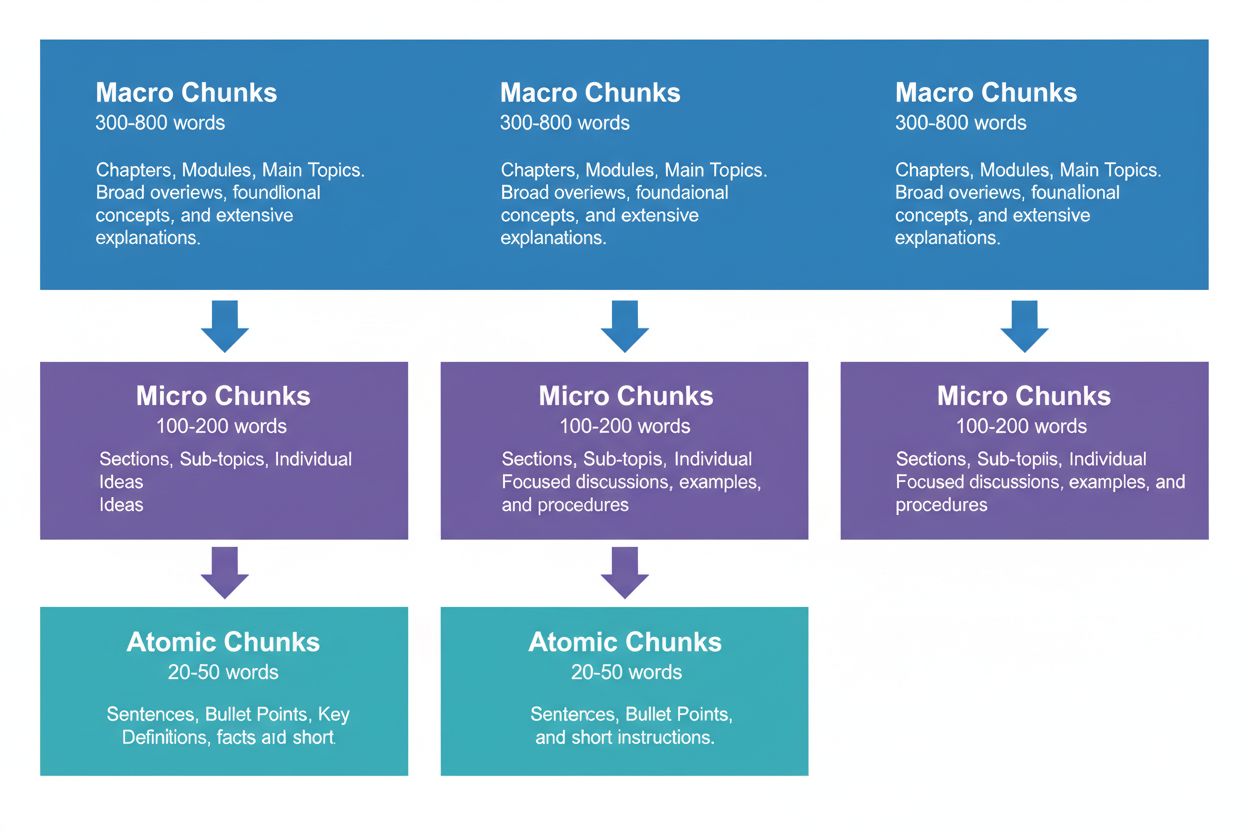
Efektivní obsahová strategie vyžaduje uvažování ve třech hierarchických úrovních, z nichž každá slouží jinému účelu v AI procesu vyhledávání. Makro úseky (300–800 slov) představují celé tematické sekce – lze je chápat jako „kapitoly“ vašeho obsahu. Jsou ideální pro vytvoření komplexního kontextu a AI systémy je často využívají při generování delších odpovědí, případně při složitých, vícerozměrných dotazech. Makro úsek může být například celá sekce „Jak optimalizovat web pro Core Web Vitals“ a poskytovat plný kontext bez nutnosti externích odkazů.
Mikro úseky (100–200 slov) jsou hlavními jednotkami, které AI systémy získávají pro citace a featured snippets. To jsou vaše klíčové úseky – odpovídají na konkrétní otázky, definují pojmy nebo poskytují konkrétní kroky. Mikro úsek může být například jedno doporučení v rámci sekce Core Web Vitals, jako „Optimalizujte Cumulative Layout Shift omezením zpoždění načítání fontů.“
Atomické úseky (20–50 slov) jsou nejmenší smysluplné jednotky – jednotlivá fakta, statistiky, definice nebo klíčová sdělení. Často jsou extrahovány pro rychlé odpovědi nebo AI generované souhrny. Když AmICited.com sleduje vaše citace, evidujeme, která úroveň dělení generuje nejvíce citací, a naše data ukazují, že dobře strukturovaná hierarchie zvyšuje celkový počet citací o 45 %.
Různé typy obsahu vyžadují různé strategie dělení pro maximalizaci AI vyhledávání a citací. FAQ obsah dosahuje nejlepších výsledků s mikro úseky o délce 120–180 slov na každou otázku-odpověď – dostatečně krátké pro rychlé načtení, ale dost dlouhé pro kompletní odpověď. Návody „jak na to“ využívají atomické úseky (30–50 slov) pro jednotlivé kroky, seskupené do mikro úseků (150–200 slov) pro celý postup. Definice a slovníkový obsah je vhodné tvořit atomickými úseky (20–40 slov) pro samotnou definici a mikro úseky (100–150 slov) pro rozšíření a kontext. Srovnávací obsah vyžaduje delší mikro úseky (200–250 slov), aby objektivně pokryl více možností a jejich výhody/nevýhody. Výzkumný a datově orientovaný obsah dosahuje optimálních výsledků s mikro úseky (180–220 slov), které obsahují metodologii, výsledky i závěry. Vzdělávací a tutoriálový obsah těží z kombinace: atomické úseky pro jednotlivé pojmy, mikro úseky pro celé lekce a makro úseky pro celé kurzy nebo rozsáhlé návody. Zpravodajský a aktuální obsah by měl používat kratší mikro úseky (100–150 slov) pro rychlé AI indexování a citace. Když AmICited.com analyzuje vzory citací napříč typy obsahu, zjišťujeme, že obsah splňující tyto typové pokyny získává 3,2× více citací od AI systémů než obsah se stejnou délkou napříč všemi typy.
Měření a optimalizace délky vašich pasáží vyžaduje kvantitativní i kvalitativní přístup. Začněte vytvořením základních metrik: sledujte aktuální míru citací pomocí nástěnky monitoringu AmICited.com, která ukazuje, které pasáže AI systémy citují a jak často. Analyzujte počet tokenů ve stávajícím obsahu pomocí nástrojů jako OpenAI tokenizer nebo Hugging Face token counter, abyste identifikovali pasáže mimo rozmezí 100–500 tokenů.
Hlavní optimalizační techniky zahrnují:
Nástroje jako chunking utility Pinecone a optimalizační frameworky NVIDIA mohou velkou část této analýzy automatizovat a poskytovat zpětnou vazbu v reálném čase.
Mnoho tvůrců obsahu si nevědomky snižuje potenciál AI citací běžnými chybami v dělení. Nejčastější chybou je nekonzistentní dělení – kombinování pasáží o 150 slovech s úseky o 600 slovech v jednom článku, což mate AI vyhledávače a snižuje konzistenci citací. Další zásadní chyba je přehnané dělení kvůli čitelnosti – rozdělení obsahu na příliš malé úseky (pod 75 slov), které neposkytnou AI dostatečný kontext. Naopak podcenění dělení kvůli komplexnosti vytváří pasáže přesahující 500 tokenů, které plýtvají AI kontextovým oknem a oslabují relevanci. Mnozí také nedodržují sémantické hranice a dělí obsah podle počtu slov nebo odstavců místo logických tematických přechodů. Takové pasáže postrádají soudržnost a matou AI i lidské čtenáře. Ignorování specifik typu obsahu je další častý problém – použití stejných velikostí úseků pro FAQ, návody i výzkum, přestože mají odlišné struktury. Nakonec tvůrci často opomíjejí testování a iteraci a nastaví velikost úseků jednou provždy, i když schopnosti AI se mění. Když AmICited.com provede audit klientského obsahu, zjistíme, že odstraněním těchto pěti chyb se míra citací zvýší v průměru o 52 %.
Vztah mezi délkou pasáže a kvalitou citace přesahuje pouhou frekvenci – zásadně ovlivňuje, jak AI systémy vaši práci přiřazují a zasazují do kontextu. Správně velké pasáže (100–500 tokenů) umožňují AI citovat vás konkrétněji a s větší jistotou, často včetně přímých citací nebo přesného přiřazení. U příliš dlouhých pasáží má AI tendenci volně parafrázovat místo přímé citace, čímž se snižuje hodnota přiřazení. U příliš krátkých pasáží AI často nedokáže poskytnout dost kontextu, což vede k neúplným nebo vágním citacím, které plně nereprezentují vaši odbornost. Kvalita citace je klíčová, protože přináší návštěvnost, buduje autoritu a upevňuje vaši odbornou pozici – vágní citace má mnohem menší hodnotu než konkrétní, přiřazený citát. Výzkum Search Engine Land o vyhledávání podle pasáží ukazuje, že dobře dělený obsah získává citace, které jsou 4,2× pravděpodobnější pro přímé přiřazení a odkaz na zdroj. Analýza Semrush v AI Overviews (vyskytují se ve 13 % vyhledávání) zjistila, že obsah s optimálními délkami pasáží získává citace v 8,7 % výsledků AI Overview, oproti 2,1 % u špatně děleného obsahu. Metriky kvality citací AmICited.com sledují nejen četnost, ale i typ citace, konkrétnost a dopad na návštěvnost, takže přesně víte, které úseky přinášejí nejhodnotnější citace. Tento rozdíl je zásadní: tisíc vágních citací má menší hodnotu než sto konkrétních, přiřazených citací, které přivádějí kvalifikovanou návštěvnost.
Nad rámec základního dělení na pevnou velikost mohou pokročilé strategie významně zvýšit výkon AI citací. Sémantické dělení využívá zpracování přirozeného jazyka pro určení hranic témat a tvorbu úseků odpovídajících logickým celkům, nikoliv arbitrárním počtům slov. Tento přístup zvyšuje přesnost vyhledávání o 35–40 % díky zachování sémantické soudržnosti. Překrývající se dělení vytváří pasáže, které sdílejí 10–20 % obsahu se sousedními úseky, což vytváří kontextové mosty usnadňující AI pochopení vztahů mezi myšlenkami. Tato technika je zvlášť účinná u složitých témat, kde na sebe pojmy navazují. Kontextové dělení vkládá do úseků metadata nebo souhrnné informace, aby AI pochopila širší kontext bez nutnosti externího vyhledávání. Například úsek o „Cumulative Layout Shift“ může obsahovat krátkou poznámku: „[Kontext: Součást optimalizace Core Web Vitals]“, což AI pomůže správně zařadit a citovat. Hierarchické sémantické dělení kombinuje více strategií – používá atomické úseky pro fakta, mikro úseky pro pojmy a makro úseky pro komplexní pokrytí – přičemž zachovává sémantické vztahy napříč úrovněmi. Dynamické dělení upravuje velikost úseků podle složitosti obsahu, vzorů dotazů a možností AI systémů, což vyžaduje průběžné sledování a úpravy. Když AmICited.com zavádí tyto pokročilé strategie u klientů, pozorujeme zlepšení míry citací o 60–85 % oproti základnímu dělení na pevnou velikost, přičemž největší přínos je v kvalitě a konkrétnosti citací.
Implementace optimálních strategií dělení vyžaduje vhodné nástroje a frameworky. Chunking utility Pinecone nabízí předpřipravené funkce pro sémantické dělení, posuvné okno i hierarchické dělení, s optimalizací pro aplikace s velkými jazykovými modely. Jejich dokumentace doporučuje rozmezí 100–500 tokenů a poskytuje nástroje pro validaci kvality úseků. Frameworky NVIDIA pro embedding a vyhledávání poskytují enterprise řešení pro organizace s velkým objemem obsahu, s důrazem na optimalizaci stránkového dělení pro maximální přesnost. LangChain umožňuje flexibilní implementaci dělení s možností integrace s populárními LLM, takže můžete experimentovat s různými strategiemi a měřit výkon. Semantic Kernel (framework Microsoftu) obsahuje utility pro dělení speciálně navržené pro AI citace. Readability nástroje Yoast zajistí, že úseky zůstanou přístupné i lidským čtenářům při optimalizaci pro AI. Platforma Semrush pro obsahovou inteligenci poskytuje přehledy o výkonnosti vašeho obsahu v AI Overviews a dalších AI-driven výsledcích vyhledávání, takže víte, které úseky generují citace. Nativní analyzátor dělení AmICited.com se integruje přímo do vašeho CMS, automaticky analyzuje délky pasáží, navrhuje optimalizace a sleduje výkon každého úseku napříč ChatGPT, Perplexity, Google AI Overviews a dalšími platformami. Tyto nástroje sahají od open-source řešení (zdarma, vyžadují technickou zdatnost) až po enterprise platformy (vyšší cena, ale komplexní monitoring a optimalizace).
Implementace optimálních délek pasáží vyžaduje systematický přístup vyvažující technickou optimalizaci s kvalitou obsahu. Postupujte podle tohoto plánu pro maximální potenciál AI citací:
Tento systematický přístup obvykle přináší měřitelné zlepšení citací během 60–90 dní, s pokračujícím růstem, jak AI systémy reindexují a učí se strukturu vašeho obsahu.
Budoucnost optimalizace na úrovni pasáží bude formována vyvíjejícími se schopnostmi AI a stále sofistikovanějšími mechanismy citací. Objevují se klíčové trendy: AI systémy přecházejí k jemnějším, pasážovým přiřazením místo stránkových citací, což činí přesné dělení ještě důležitější. Kontextová okna se zvětšují (některé modely nyní podporují přes 128 000 tokenů), což může posunout optimální velikosti úseků nahoru, ale zachovává význam sémantických hranic. Multimodální dělení je na vzestupu, protože AI systémy stále více zpracovávají obrázky, videa a text dohromady, což vyžaduje nové strategie pro dělení smíšených médií. Standardem se pravděpodobně stane průběžná optimalizace dělení pomocí strojového učení, kdy systémy automaticky upravují velikost úseků podle vzorů dotazů a výkonu vyhledávání. Transparentnost citací se stává konkurenční výhodou, přičemž platformy jako AmICited.com pomáhají tvůrcům přesně pochopit, jak a kde je jejich obsah citován. S tím, jak se AI systémy zdokonalují, schopnost optimalizovat pro citace na úrovni pasáží bude klíčovou konkurenční výhodou pro tvůrce obsahu, vydavatele i znalostní organizace. Ti, kdo zvládnou strategie dělení již nyní, budou nejlépe připraveni získat hodnotu z citací, protože AI-driven vyhledávání bude stále více dominovat objevování informací. Spojení lepšího dělení, pokročilého monitoringu a vyspělosti AI systémů znamená, že optimalizace na úrovni pasáží se posune z technického detailu na základní požadavek obsahové strategie.
Optimální rozmezí je 100–500 tokenů, obvykle 75–350 slov v závislosti na složitosti. Menší úseky (100–200 tokenů) zajišťují vyšší přesnost pro konkrétní dotazy, zatímco větší úseky (300–500 tokenů) zachovávají více kontextu. Nejvhodnější délka závisí na typu vašeho obsahu a cílovém embedding modelu.
Správně velké pasáže jsou AI systémy častěji citovány, protože je lze snadněji extrahovat a prezentovat jako kompletní odpovědi. Příliš dlouhé úseky mohou být zkráceny nebo jen částečně citovány, zatímco příliš krátké nemusejí obsahovat dostatek kontextu pro přesné zobrazení.
Ne. I když konzistence pomáhá, důležitější jsou sémantické hranice než jednotná délka. Definice může potřebovat jen 50 slov, zatímco vysvětlení procesu třeba 250 slov. Klíčem je, aby každý úsek byl samostatný a odpovídal na jednu konkrétní otázku.
Počet tokenů se liší podle embedding modelu a způsobu tokenizace. Obecně platí, že 1 token ≈ 0,75 slova, ale může se to lišit. Pro přesné počty použijte tokenizér konkrétního embedding modelu. Nástroje jako Pinecone a LangChain poskytují utilitky na počítání tokenů.
Featured snippets obvykle vytahují úryvky o délce 40–60 slov, což dobře odpovídá atomickým úsekům. Tvořením dobře strukturovaných, zaměřených pasáží zvyšujete šanci na výběr do featured snippetů i AI generovaných odpovědí.
Většina velkých AI systémů (ChatGPT, Google AI Overviews, Perplexity) používá podobné mechanismy vyhledávání podle pasáží, takže rozmezí 100–500 tokenů funguje napříč platformami. Přesto otestujte svůj obsah v cílových AI systémech a optimalizujte pro jejich konkrétní vzory vyhledávání.
Ano, a je to doporučeno. Zařazení 10–15% překryvu mezi sousedními úseky zajistí, že informace u hranic sekcí zůstanou dostupné a zabrání ztrátě důležitého kontextu při vyhledávání.
AmICited.com monitoruje, jak AI systémy odkazují na vaši značku napříč ChatGPT, Google AI Overviews a Perplexity. Sledováním, které pasáže jsou citovány a jak jsou prezentovány, můžete identifikovat optimální délky a struktury pasáží pro váš konkrétní obsah a odvětví.
Sledujte, jak AI systémy citují váš obsah napříč ChatGPT, Google AI Overviews a Perplexity. Optimalizujte délku svých pasáží na základě skutečných dat o citacích.
Zjistěte, jak strukturovat svůj obsah, abyste získali citace od AI vyhledávačů jako ChatGPT, Perplexity a Google AI. Odborné strategie pro viditelnost a citace ...
Zjistěte optimální hloubku, strukturu a míru detailu obsahu pro získání citací od ChatGPT, Perplexity a Google AI. Objevte, co činí obsah vhodným ke citaci pro ...
Diskuze komunity o tom, jak vydavatelé optimalizují obsah pro AI citace ve vyhledávání. Skutečné strategie digitálních vydavatelů na odpověď na prvním místě, st...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.