
Halucinace AI a bezpečnost značky: Ochrana vaší reputace
Zjistěte, jak halucinace AI ohrožují bezpečnost značky v Google AI Overviews, ChatGPT a Perplexity. Objevte strategie monitorování, techniky zpevnění obsahu a p...
9 min čtení

Objevte, jak grounding LLM a webové vyhledávání umožňují AI systémům přístup k aktuálním informacím v reálném čase, snižují halucinace a poskytují přesné citace. Naučte se RAG, strategie implementace a osvědčené firemní postupy.
Velké jazykové modely jsou trénovány na obrovském množství textových dat, ale tento proces má zásadní omezení: zachycuje pouze informace dostupné do určitého časového bodu, známého jako datum znalostního cutoffu. Například pokud byl LLM trénován na datech do prosince 2023, nemá povědomí o událostech, objevech či vývoji, k nimž došlo po tomto datu. Když se uživatelé ptají na aktuální dění, nové produkty nebo nejnovější zprávy, model nemůže tyto informace získat ze svých tréninkových dat. Místo přiznání nejistoty často LLM generují odpovědi, které zní věrohodně, ale jsou fakticky nesprávné—tomuto jevu se říká halucinace. Tato tendence je obzvlášť problematická v aplikacích, kde je zásadní přesnost, například v zákaznické podpoře, finančním poradenství či medicínských informacích, kde zastaralé nebo smyšlené údaje mohou mít vážné důsledky.
Grounding je proces rozšiřování předtrénovaných znalostí LLM o externí, kontextové informace v čase inference. Místo spoléhání se pouze na vzory naučené při tréninku propojuje grounding model s reálnými zdroji dat—ať už webovými stránkami, interními dokumenty, databázemi či API. Tento koncept vychází z kognitivní psychologie, konkrétně z teorie situované kognice, která tvrdí, že znalosti jsou nejefektivněji aplikovány, když jsou zakotveny v kontextu, kde budou použity. V praxi grounding mění problém z „vygeneruj odpověď z paměti“ na „syntetizuj odpověď z poskytnutých informací“. Přísná definice z nedávného výzkumu vyžaduje, aby LLM využil všechny podstatné znalosti z dodaného kontextu a držel se jeho rámce, aniž by halucinoval další informace.
| Aspekt | Ne-groundovaná odpověď | Groundovaná odpověď |
|---|---|---|
| Zdroj informací | Pouze předtrénované znalosti | Předtrénované znalosti + externí data |
| Přesnost pro aktuální události | Nízká (omezení knowledge cutoff) | Vysoká (přístup k aktuálním informacím) |
| Riziko halucinací | Vysoké (model hádá) | Nízké (omezeno kontextem) |
| Schopnost citovat | Omezená nebo nemožná | Plná dohledatelnost ke zdrojům |
| Škálovatelnost | Fixní (velikost modelu) | Flexibilní (možnost přidávat nové zdroje) |
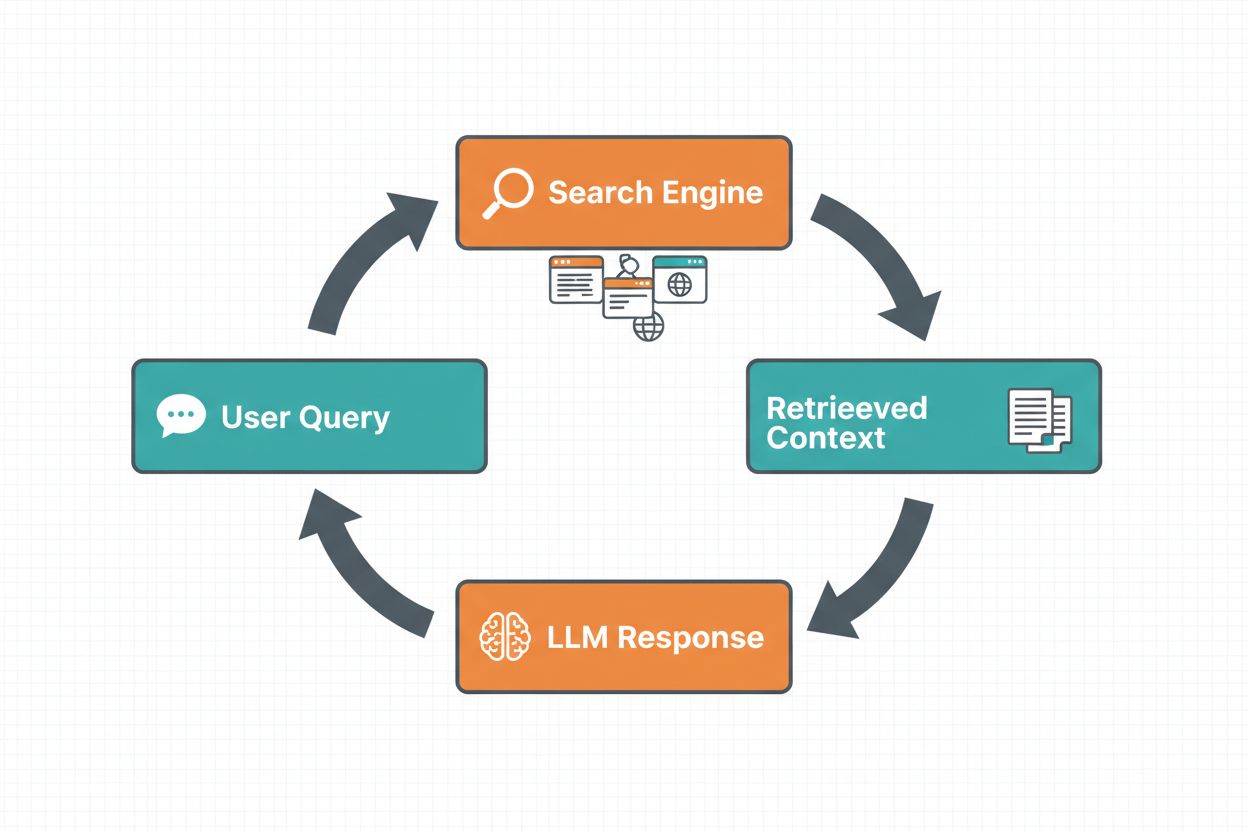
Grounding přes webové vyhledávání umožňuje LLM přístup k informacím v reálném čase tím, že automaticky vyhledává na webu a začleňuje výsledky do procesu generování odpovědi. Workflow následuje strukturovanou sekvenci: nejprve systém analyzuje uživatelský prompt a určí, zda by webové vyhledávání zlepšilo odpověď; dále generuje jeden nebo více dotazů optimalizovaných pro získání relevantních informací; poté tyto dotazy provede ve vyhledávači (například Google Search nebo DuckDuckGo); následně zpracuje výsledky vyhledávání a extrahuje relevantní obsah; a nakonec poskytne tento kontext LLM jako součást promptu, což modelu umožní vygenerovat groundovanou odpověď. Systém také vrací grounding metadata—strukturované informace o tom, jaké vyhledávací dotazy byly provedeny, jaké zdroje získány a jak jsou konkrétní části odpovědi podpořeny těmito zdroji. Tato metadata jsou zásadní pro budování důvěry a umožnění ověřování tvrzení.
Workflow groundingu přes webové vyhledávání:
Retrieval Augmented Generation (RAG) se stal dominantní groundingovou technikou, která kombinuje desetiletí výzkumu v oblasti informačního vyhledávání s moderními schopnostmi LLM. RAG funguje tak, že nejprve získá relevantní dokumenty či pasáže z externí znalostní báze (typicky indexované ve vektorové databázi), a tyto získané položky následně poskytne LLM jako kontext. Proces vyhledání obvykle zahrnuje dvě fáze: retriever využívá efektivní algoritmy (například BM25 nebo sémantické vyhledávání s embeddingy) k nalezení kandidátních dokumentů a ranker použije sofistikovanější neuronové modely k přeřazení těchto kandidátů podle relevance. Získaný kontext je pak začleněn do promptu, což umožní LLM syntetizovat odpovědi zakotvené v autoritativních informacích. RAG nabízí významné výhody oproti fine-tuningu: je levnější (není třeba model přeškolovat), lépe škálovatelný (stačí přidat nové dokumenty do znalostní báze) a snadněji udržovatelný (aktualizace informací bez přeškolování). Například RAG prompt může vypadat takto:
Použijte následující dokumenty k zodpovězení otázky.
[Otázka]
Jaké je hlavní město Kanady?
[Dokument 1]
Ottawa je hlavní město Kanady, které se nachází v Ontariu...
[Dokument 2]
Kanada je země v Severní Americe s deseti provinciemi...
Jednou z nejpřesvědčivějších výhod groundingu přes webové vyhledávání je schopnost začlenit do odpovědí LLM aktuální informace v reálném čase. To je obzvláště hodnotné pro aplikace vyžadující nejnovější data—analýzy zpráv, průzkum trhu, informace o událostech či dostupnost produktů. Kromě samotného přístupu k čerstvým informacím grounding poskytuje citace a zdrojovou atribuci, což je klíčové pro budování důvěry uživatelů a umožnění ověřování. Když LLM vygeneruje groundovanou odpověď, vrací strukturovaná metadata, která mapují konkrétní tvrzení zpět na jejich zdrojové dokumenty, což umožňuje vložené citace typu “[1] source.com” přímo v textu odpovědi. Tato schopnost je přímo v souladu s posláním platforem jako AmICited.com, které monitorují, jak AI systémy odkazují a citují zdroje napříč různými platformami. Schopnost sledovat, jaké zdroje AI systém použil a jak informace přiřadil, je čím dál důležitější pro monitoring značek, atribuci obsahu a zajištění odpovědného nasazení AI.
Halucinace vznikají proto, že LLM jsou v základu navrženy tak, aby predikovaly další token na základě předchozích tokenů a naučených vzorů, bez vnitřního povědomí o hranicích svých znalostí. Když čelí otázkám mimo svá tréninková data, pokračují v generování textu, který zní věrohodně, místo aby přiznaly nejistotu. Grounding toto řeší tím, že zásadně mění úlohu modelu: místo generování z paměti model nyní syntetizuje z dodaných informací. Technicky vzato, pokud je v promptu zahrnut relevantní externí kontext, mění se pravděpodobnostní rozložení tokenů směrem k odpovědím zakotveným v tomto kontextu, což snižuje pravděpodobnost halucinací. Výzkumy ukazují, že grounding může snížit míru halucinací o 30–50 % v závislosti na úloze a implementaci. Například na otázku „Kdo vyhrál Euro 2024?“ bez groundingu starší model odpoví nesprávně; s groundingem přes výsledky webového vyhledávání správně identifikuje Španělsko jako vítěze s konkrétními detaily zápasu. Tento mechanismus funguje proto, že mechanismy pozornosti modelu se nyní mohou zaměřit na dodaný kontext a nespoléhají jen na potenciálně neúplné nebo konfliktní vzory z tréninkových dat.
Implementace groundingu přes webové vyhledávání vyžaduje integraci několika komponent: vyhledávací API (například Google Search, DuckDuckGo přes Serp API nebo Bing Search), logiku určující, kdy je grounding potřeba, a prompt engineering pro efektivní začlenění výsledků vyhledávání. Praktická implementace obvykle začíná vyhodnocením, zda uživatelský dotaz vyžaduje aktuální informace—lze to provést například tím, že se LLM samo zeptáme, zda prompt potřebuje informace novější než jeho knowledge cutoff. Pokud je grounding potřeba, systém provede webové vyhledávání, zpracuje výsledky a extrahuje relevantní úryvky a sestaví prompt, který obsahuje jak původní otázku, tak kontext z vyhledávání. Důležité jsou nákladové aspekty: každé webové vyhledávání znamená náklady na API, proto implementace dynamického groundingu (vyhledávání jen v případě potřeby) může výrazně snížit výdaje. Například dotaz jako „Proč je nebe modré?“ pravděpodobně nepotřebuje webové vyhledávání, zatímco „Kdo je současný prezident?“ rozhodně ano. Pokročilé implementace využívají menší a rychlejší modely pro rozhodování o groundingu, čímž zkracují latenci a šetří náklady, zatímco větší modely rezervují pro finální generování odpovědí.
Přestože je grounding velmi mocný, přináší několik výzev, které je třeba pečlivě řešit. Relevance dat je klíčová—pokud získané informace ve skutečnosti neodpovídají uživatelskému dotazu, grounding nepomůže a může dokonce přidat nerelevantní kontext. Množství dat představuje paradox: i když se zdá, že více informací je lepší, výzkumy ukazují, že výkon LLM často s příliš velkým vstupem klesá, což je fenomén známý jako bias „ztraceno uprostřed“, kdy má model problém najít a využít informace umístěné uprostřed dlouhého kontextu. Efektivita tokenů je dalším aspektem, protože každý získaný kus kontextu spotřebovává tokeny, což zvyšuje latenci a náklady. Platí zde zásada „méně je více“: získávejte pouze nejrelevantnější top-k výsledky (obvykle 3–5), pracujte s menšími textovými bloky místo celých dokumentů a zvažte extrakci klíčových vět z delších pasáží.
| Výzva | Dopad | Řešení |
|---|---|---|
| Relevance dat | Nerelevantní kontext mate model | Použít sémantické vyhledávání + rankery; testovat kvalitu vyhledávání |
| Bias ztraceno uprostřed | Model přehlíží důležité informace uprostřed | Minimalizovat velikost vstupu; klíčové informace na začátek/konec |
| Efektivita tokenů | Vysoká latence a náklady | Získávat méně výsledků; používat menší bloky |
| Zastaralé informace | Zastaralý kontext ve znalostní bázi | Zavést aktualizační politiky; verzování |
| Latence | Pomalé odpovědi kvůli vyhledávání + inferenci | Používat asynchronní operace; cachovat časté dotazy |
Nasazení groundingových systémů v produkčním prostředí vyžaduje pečlivou pozornost k řízení, bezpečnosti a provozním otázkám. Zajištění kvality dat je základ—informace, na kterých grounding stojí, musí být přesné, aktuální a relevantní pro vaše use-casy. Kontrola přístupu je zásadní při groundingu na proprietárních nebo citlivých dokumentech; musíte zajistit, že LLM přistupuje jen k informacím, které jsou pro daného uživatele povolené. Správa aktualizací a driftu vyžaduje nastavit politiky, jak často se znalostní báze obnovuje a jak řešit konfliktní informace napříč zdroji. Auditní logování je nezbytné pro compliance a ladění—měli byste zaznamenávat, jaké dokumenty byly získány, jak byly seřazeny a jaký kontext byl modelu poskytnut. Další aspekty zahrnují:
Oblast groundingu LLM se rychle vyvíjí nad rámec prostého textového vyhledávání. Objevuje se multimodální grounding, kdy systémy zakotvují odpovědi nejen v textech, ale i v obrázcích, videu a strukturovaných datech—což je obzvlášť důležité pro oblasti jako je analýza právních dokumentů, medicínské zobrazování či technická dokumentace. Automatizované uvažování je vrstveno nad RAG, což umožňuje agentům nejen vyhledávat informace, ale také je syntetizovat napříč více zdroji, vyvozovat logické závěry a vysvětlovat své postupy. Guardrails jsou integrovány s groundingem, aby i při přístupu k externím informacím modely zachovávaly bezpečnostní limity a soulad s politikami. Aktualizace modelu na místě představují další hranici—místo spoléhání pouze na externí retrieval se zkoumá možnost přímo upravovat váhy modelu novými informacemi, což by mohlo snížit potřebu rozsáhlých externích znalostních bází. Tyto pokroky naznačují, že budoucí groundingové systémy budou inteligentnější, efektivnější a schopné řešit složité, vícekrokové úlohy při zachování faktické správnosti a dohledatelnosti.
Grounding rozšiřuje LLM o externí informace v čase inference bez úpravy samotného modelu, zatímco fine-tuning znamená přeškolení modelu na nových datech. Grounding je cenově efektivnější, rychlejší na implementaci a snadnější na aktualizaci novými informacemi. Fine-tuning je vhodný, když potřebujete zásadně změnit chování modelu nebo naučit doménově specifické vzory.
Grounding snižuje halucinace tím, že poskytuje LLM faktický kontext, ze kterého může čerpat, místo aby se spoléhal pouze na tréninková data. Pokud je v promptu zahrnuta relevantní externí informace, mění se pravděpodobnostní rozložení tokenů směrem k odpovědím zakotveným v tomto kontextu, což snižuje pravděpodobnost smyšlených informací. Výzkumy ukazují, že grounding může snížit míru halucinací o 30–50 %.
Retrieval Augmented Generation (RAG) je groundingová technika, která získává relevantní dokumenty z externí znalostní báze a poskytuje je jako kontext pro LLM. RAG je důležitý, protože je škálovatelný, cenově efektivní a umožňuje aktualizovat informace bez přeškolování modelu. Stal se oborovým standardem pro tvorbu grounded AI aplikací.
Grounding webovým vyhledáváním implementujte tehdy, když vaše aplikace potřebuje přístup k aktuálním informacím (zprávy, události, nedávná data), když je kritická přesnost a citace, nebo když je znalostní cutoff vašeho LLM limitující. Používejte dynamický grounding a vyhledávejte jen tehdy, když je to nutné, čímž snížíte náklady a latenci u dotazů, které čerstvé informace nevyžadují.
Klíčovými výzvami jsou zajištění relevance dat (získané informace musí skutečně odpovídat na otázku), správa množství dat (více není vždy lépe), práce s biasem „ztraceno uprostřed“, kdy modely přehlížejí informace uprostřed dlouhých kontextů, a optimalizace efektivity tokenů. Řešení zahrnuje použití sémantického vyhledávání s rankery, získávání menšího množství kvalitnějších výsledků a umisťování klíčových informací na začátek nebo konec kontextu.
Grounding přímo souvisí s monitoringem AI odpovědí, protože umožňuje systémům poskytovat citace a zdrojovou atribuci. Platformy jako AmICited sledují, jak AI systémy odkazují na zdroje, což je možné jen při správné implementaci groundingu. To pomáhá zajistit odpovědné nasazení AI a atribuci značky napříč různými AI platformami.
Bias „ztraceno uprostřed“ je fenomén, kdy LLM podávají horší výkony, pokud je relevantní informace umístěna uprostřed dlouhého kontextu, oproti informacím na začátku nebo konci. Děje se to proto, že modely mají tendenci „přeskakovat“, když zpracovávají velké objemy textu. Řešení zahrnuje minimalizaci velikosti vstupu, umístění klíčových informací na preferovaná místa a použití menších textových bloků.
Pro produkční nasazení se zaměřte na zajištění kvality dat, implementujte přístupová práva pro citlivé informace, nastavte politiku aktualizací a obnov, umožněte auditní logování pro compliance a vytvořte zpětnovazební smyčky uživatelů pro detekci chyb. Sledujte využití tokenů pro optimalizaci nákladů, implementujte verzování znalostních bází a monitorujte chování modelu pro detekci driftu.
AmICited sleduje, jak GPTs, Perplexity a Google AI Overviews citují a odkazují na váš obsah. Získejte přehled v reálném čase o monitoringu AI odpovědí a atribuci značky.
Zjistěte, jak halucinace AI ohrožují bezpečnost značky v Google AI Overviews, ChatGPT a Perplexity. Objevte strategie monitorování, techniky zpevnění obsahu a p...

Zjistěte, jak Retrieval-Augmented Generation mění AI citace, umožňuje přesné přiřazení zdrojů a zakotvené odpovědi napříč ChatGPT, Perplexity a Google AI Overvi...

Komplexní definice velkých jazykových modelů (LLM): AI systémy trénované na miliardách parametrů pro porozumění a generování jazyka. Zjistěte, jak LLM fungují, ...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.