Algoritmus výběru citací
Zjistěte, jak systémy AI vybírají, které zdroje citovat a které parafrázovat. Pochopte algoritmy výběru citací, vzorce zaujatosti a strategie pro zlepšení vidit...
6 min čtení

Zjistěte, jak AI modely jako ChatGPT, Perplexity a Gemini vybírají zdroje k citování. Pochopte mechanismy citací, hodnotící faktory i optimalizační strategie pro AI viditelnost.
AI modely rozhodují, co citovat, pomocí Retrieval-Augmented Generation (RAG), kdy hodnotí zdroje na základě autority domény, aktuálnosti obsahu, sémantické relevance, struktury informací a hustoty faktů. Rozhodovací proces probíhá během milisekund pomocí vektorového porovnávání podobnosti a multifaktorových algoritmů, které posuzují důvěryhodnost, signály odbornosti a kvalitu obsahu.
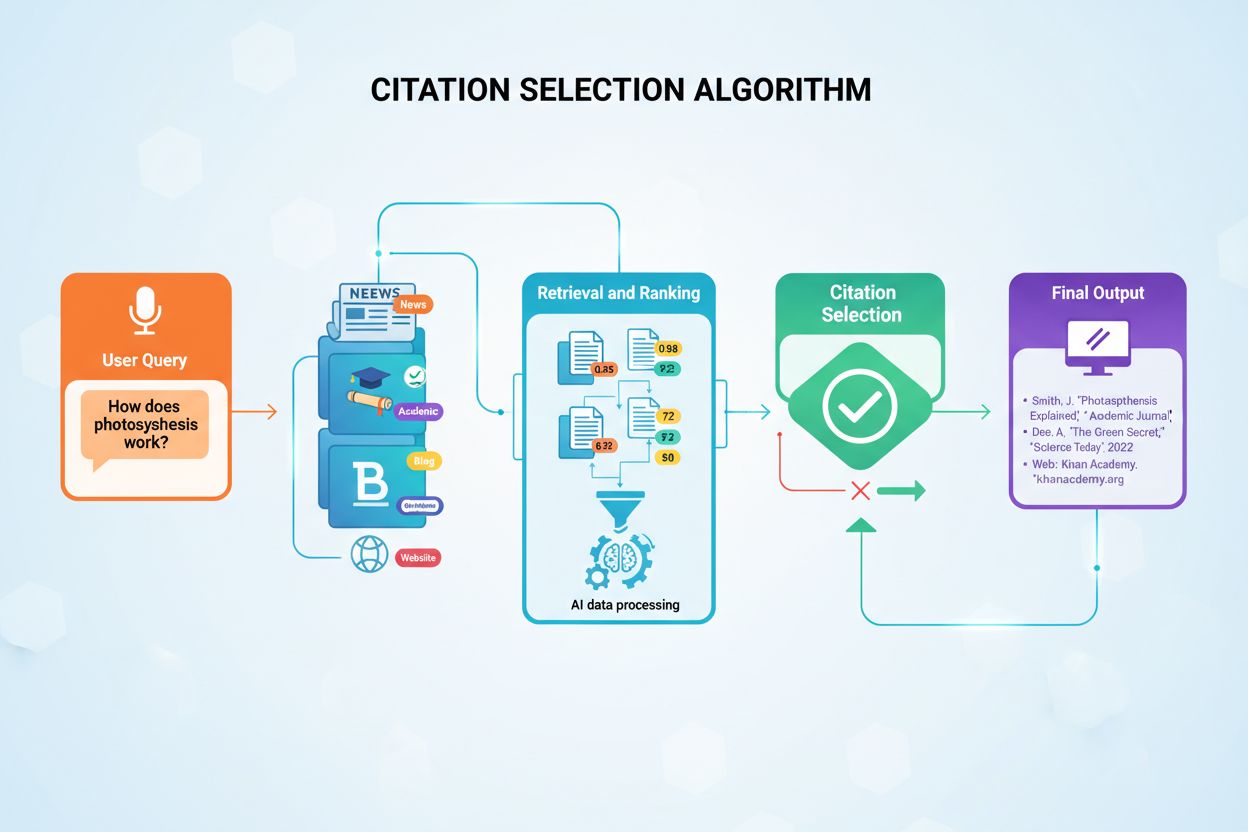
AI modely nevybírají zdroje k citování náhodně. Místo toho využívají sofistikované algoritmy, které během milisekund vyhodnocují stovky signálů a rozhodují, kterým zdrojům přiznat autorství. Tento proces, známý jako Retrieval-Augmented Generation (RAG), se zásadně liší od toho, jak tradiční vyhledávače řadí obsah. Zatímco algoritmus Googlu se zaměřuje na řazení stránek pro viditelnost ve výsledcích vyhledávání, AI algoritmy citací upřednostňují zdroje, které poskytují nejautoritativnější, nejrelevantnější a nejdůvěryhodnější informace pro konkrétní uživatelský dotaz. Tento rozdíl znamená, že dosažení viditelnosti v AI generovaných odpovědích vyžaduje zcela jiný soubor optimalizačních principů než tradiční SEO.
Rozhodnutí o citaci probíhá vícestupňovým procesem, který začíná okamžitě po zadání dotazu uživatelem. AI systém převádí otázku do číselných vektorů zvaných embeddingy, které reprezentují sémantický význam dotazu. Tyto embeddingy poté prohledávají indexované databáze obsahu obsahující miliony dokumentů a hledají sémanticky podobné úseky. Systém nevybírá pouze nejpodobnější obsah; současně aplikuje několik hodnotících kritérií, aby potenciální zdroje seřadil podle vhodnosti pro citaci. Tento paralelní hodnotící proces zajišťuje, že nejdůvěryhodnější, nejrelevantnější a nejlépe strukturované zdroje se dostanou na vrchol žebříčku.
Retrieval-Augmented Generation (RAG) je základní architektura, která AI modelům vůbec umožňuje citovat externí zdroje. Na rozdíl od tradičních velkých jazykových modelů, které se spoléhají pouze na trénovací data z doby vývoje, RAG systémy aktivně ve chvíli dotazu prohledávají indexované dokumenty a teprve pak generují odpověď. Tento architektonický rozdíl vysvětluje, proč některé platformy jako Perplexity a Google AI Overviews důsledně uvádějí citace, zatímco jiné, například základní ChatGPT, často odpovídají bez explicitního odkazu na zdroj. Pochopení RAG osvětluje, proč je některý obsah citován a jiný, i když je kvalitní, zůstává pro AI neviditelný.
Proces RAG probíhá ve čtyřech fázích, které určují, které zdroje nakonec získají citaci. Nejprve se dokumenty rozdělí na úseky o 200–500 slovech, aby AI mohla extrahovat konkrétní relevantní informace bez nutnosti zpracovávat celý článek. Zadruhé se tyto úseky převedou na číselné vektory pomocí strojového učení, které rozumí sémantice. Zatřetí, když uživatel položí otázku, systém hledá sémanticky podobné vektory pomocí porovnání vektorové podobnosti a identifikuje obsah, který odpovídá základním konceptům dotazu. Začtvrté AI vygeneruje odpověď s využitím nalezeného obsahu jako kontextu a ty zdroje, které nejvíce přispěly k odpovědi, získají citaci. Tato architektura vysvětluje, proč struktura obsahu, jeho jasnost a sémantická shoda s běžnými dotazy přímo ovlivňují pravděpodobnost citace.
Algoritmy citací v AI hodnotí zdroje podle pěti klíčových dimenzí, které společně určují vhodnost pro citování. Tyto faktory dohromady vytvářejí komplexní posouzení kvality zdroje, přičemž každá dimenze přispívá k celkovému skóre citace.
| Faktor citace | Úroveň vlivu | Klíčové indikátory |
|---|---|---|
| Autorita domény | Velmi vysoká (25-30 %) | Profil zpětných odkazů, stáří domény, přítomnost v knowledge graphu, zmínky na Wikipedii |
| Aktuálnost obsahu | Vysoká (20-25 %) | Datum publikace, četnost aktualizací, čerstvost statistik a dat |
| Sémantická relevance | Vysoká (20-25 %) | Shoda dotazu s obsahem, specifičnost tématu, přítomnost přímé odpovědi |
| Struktura informací | Středně vysoká (15-20 %) | Hierarchie nadpisů, přehledný formát, implementace schema markup |
| Hustota faktů | Střední (10-15 %) | Konkrétní data, statistiky, citace odborníků, řetězení citací |
Autorita je nejvíce vážený faktor při rozhodování o citaci v AI. Výzkum 150 000 AI citací ukazuje, že Reddit a Wikipedia představují 40,1 % a 26,3 % všech citací LLM, což dokládá, jak zásadní vliv má zavedená autorita. AI posuzují autoritu pomocí více důvěryhodnostních signálů, jako je stáří domény, kvalita zpětných odkazů, přítomnost v knowledge grafech a validace třetími stranami. Weby s autoritou domény nad 60 mají trvale vyšší citovanost napříč ChatGPT, Perplexity a Gemini. Autorita však není jen o úrovni domény; zahrnuje i důvěryhodnost autorů – obsah podepsaný ověřitelnými experty má přednost před anonymními příspěvky.
Aktuálnost slouží jako klíčový časový filtr, který určuje, zda obsah zůstává vhodný pro citaci. Obsah publikovaný nebo aktualizovaný během 48–72 hodin získává přednostní řazení, zatímco bez aktualizací začíná viditelnost rychle klesat během 2–3 dnů. Tato preference aktuálnosti odráží snahu AI poskytovat aktuální informace, zejména u rychle se měnících témat, kde zastaralé informace mohou uživatele uvést v omyl. Přesto může nadčasový obsah s čerstvými aktualizacemi překonat novější, ale povrchní texty – kombinace vysoké kvality a aktuálnosti je důležitější než každý faktor samostatně. Organizace, které pravidelně aktualizují obsah v kvartálních či ročních cyklech, dosahují vyšší citovanosti.
Relevance měří sémantickou shodu mezi uživatelským dotazem a obsahem dokumentu. Zdroje, které se přímo a stručně věnují jádru otázky, skórují lépe než obsáhlé, ale nejednoznačné materiály. AI hodnotí relevanci pomocí podobnosti embeddingů, tedy porovnáváním číselné reprezentace dotazu s dokumentovými úseky. Obsah psaný konverzačním jazykem, odpovídající přirozeným dotazům, funguje lépe než texty optimalizované pro tradiční SEO. Obsah ve stylu FAQ a formát otázek a odpovědí jsou přirozeně v souladu s tím, jak AI zpracovává dotazy, a jsou tak zvláště vhodné pro citování.
Struktura zahrnuje jak architekturu informací, tak technické provedení. Jasné hierarchické členění s popisnými nadpisy, logickou návazností a přehledným formátem pomáhá AI určit hranice obsahu a extrahovat relevantní informace. Strukturovaná data ve formátu schema (FAQ schema, Article schema, Organization schema) mohou zvýšit pravděpodobnost citace až o 10 %. Obsah ve formě stručných shrnutí, odrážkových seznamů, srovnávacích tabulek a otázek a odpovědí má přednost před hutnými odstavci s utajenými informacemi. Tato strukturální preference odráží trénink AI na rozpoznávání dobře uspořádaných informací, které poskytují kompletní a kontextové odpovědi.
Hustota faktů označuje koncentraci konkrétních a ověřitelných informací v textu. Zdroje obsahující konkrétní data, statistiky, data a příklady převyšují čistě koncepční obsah. Zásadní je i citování autoritativních referencí, které vytváří řetěz důvěry – AI dědí důvěru ze zdrojů, které daný text sám cituje. Obsah s podloženými tvrzeními a odkazy na primární zdroje má vyšší citovanost než nepodložená tvrzení. To znamená, že každé významné tvrzení by mělo být podloženo citací na autoritativní zdroj s uvedením data a expertních údajů.
Různé AI platformy implementují rozdílné strategie citací podle své architektury a filozofie návrhu. Pochopení těchto preferencí pomáhá tvůrcům obsahu optimalizovat napříč více AI systémy zároveň.
ChatGPT vzorce citací ukazují silnou preferenci pro encyklopedické a autoritativní zdroje. Wikipedia se objevuje zhruba ve 35 % citací ChatGPT, což dokládá závislost modelu na uznávaných komunitně ověřených informacích. Platforma se vyhýbá obsahům z diskusních fór, pokud uživatel výslovně nepožaduje komunitní názory, a upřednostňuje zdroje s jasnou citací a ověřitelnými fakty před názorovými texty. Tento konzervativní přístup odpovídá tréninku na kvalitních datech a filozofii upřednostňující přesnost před šíří. Organizace usilující o citace od ChatGPT by měly budovat přítomnost v knowledge grafech, vytvářet záznamy na Wikipedii a publikovat obsah v encyklopedickém stylu s důrazem na neutralitu.
Google AI systémy včetně Gemini a AI Overviews zahrnují rozmanitější typy zdrojů, což odpovídá širší indexační filozofii Googlu. Příspěvky z Redditu tvoří přibližně 5 % citací v AI Overviews a platforma upřednostňuje obsah, který se objevuje i ve špičkových organických výsledcích vyhledávání, což vytváří synergii mezi tradičním SEO a AI citacemi. Google AI je ochotnější citovat novější a uživatelsky generovaný obsah než ChatGPT, pokud vykazuje relevanci a autoritu. To znamená, že silný výkon v tradičním SEO koreluje s úspěchem i v AI citacích na platformách Googlu, ačkoliv korelace není dokonalá.
Perplexity AI preferuje transparentnost a přímou citaci zdrojů. Platforma obvykle uvádí 3–5 zdrojů na odpověď s přímými odkazy, přičemž preferuje oborové recenzní weby, odborné publikace a datově podložený obsah. Autorita domény má velkou váhu; zavedené publikace mají přednost, zatímco komunitní obsah tvoří asi 1 % citací, a to hlavně u doporučení produktů. Filozofie Perplexity je pomáhat uživateli ověřit informace díky jasné citaci zdrojů, což je užitečné i pro sledování viditelnosti značky. Organizace optimalizující pro Perplexity by měly tvořit datově bohatý obsah, oborové zdroje a expertně podepsané materiály, které prokazují autoritu.
Autorita domény funguje v AI algoritmech jako zástupný ukazatel spolehlivosti, signalizuje, že zdroj si dlouhodobě buduje důvěryhodnost. Systémy hodnotí autoritu na základě několika signálů, které tvoří asi 5 % celkové pravděpodobnosti citace, s tím, že u témat YMYL (Your Money, Your Life – zdraví, finance, bezpečnost) se tento podíl výrazně zvyšuje. Klíčové indikátory autority jsou stáří domény, SSL certifikáty, zásady ochrany osobních údajů a soulad s normami jako SOC 2 či GDPR. Tyto technické signály v kombinaci s kvalitním obsahem vytvářejí násobný efekt, kdy technicky kvalitní weby s výborným obsahem překonávají i vynikající obsah na technicky slabých stránkách.
Profil zpětných odkazů zásadně ovlivňuje vnímání zdroje v AI. Modely hodnotí autoritu odkazujících domén, relevanci kontextu odkazu a různorodost portfolia. Výzkum ukazuje, že deset zpětných odkazů z hlavních médií má větší váhu než 100 odkazů z méně významných stránek – kvalita je zásadnější než kvantita. Citace odborníků (byline) výrazně zvyšují pravděpodobnost citace; obsah podepsaný ověřitelnými autory má mnohem vyšší výkon než anonymní texty. Schema markup autora a detailní biografie pomáhají AI validovat odbornost, zatímco zmínky v oborových médiích autoritu dále posilují. Organizace by měly usilovat o zpětné odkazy z autoritativních zdrojů, budovat expertní profily a získávat zmínky v médiích.
Přítomnost na Wikipedii a v knowledge grafech dramaticky zvyšuje citovanost bez ohledu na další faktory. Zdroje odkazované na Wikipedii mají velkou výhodu, protože knowledge graphy slouží jako autoritativní referenční základna, ke které se AI modely opakovaně vracejí napříč různými dotazy. Informace z Google Knowledge Panelu přímo ovlivňují, jak AI chápe vztahy a autoritu entit. Organizace bez prezentace na Wikipedii se jen těžko prosazují v citacích, i když mají kvalitní obsah, což naznačuje, že rozvoj knowledge graphu by měl být prioritou. Tento základní vrstva důvěry je pro jazykové modely výchozí referencí při vyhledávání.
Srovnání s přirozenými dotazy představuje zásadní odklon od tradiční SEO optimalizace. Obsah strukturovaný ve formě otázek a odpovědí je pro AI retrieval algoritmy vhodnější než text zaměřený na klíčová slova. FAQ stránky a obsah napodobující přirozené jazykové dotazy získávají přednost, protože AI je trénovaná na konverzačních datech a lépe chápe jazykové vzory než řetězce klíčových slov. Znamená to, že obsah psaný jako odpověď na otázku kamaráda překonává texty psané pro vyhledávače. Organizace by měly auditovat svůj obsah z hlediska konverzačního tónu, přímých odpovědí na běžné otázky a sladění s tím, jak lidé opravdu pokládají dotazy.
Kvalita citací v obsahu vytváří řetězy důvěry, které přesahují samotný zdroj. AI hodnotí, zda tvrzení obsahují podkladová data a důkazy. Obsah citující autoritativní reference dědí důvěryhodnost těchto zdrojů, což má násobný efekt. Zdroje s důkazy a odkazy na primární reference mají vyšší citovanost než nepodložená tvrzení. Znamená to, že každé významné tvrzení by mělo být podloženo citací na autoritativní zdroj s datem a expertními údaji. Organizace by měly do citovatelných textů zahrnout alespoň 5–8 autoritativních zdrojů, 2–3 expertní citace s plnými údaji a 3–5 aktuálních statistik s datem.
Konzistence napříč platformami ovlivňuje, jak AI vnímá důvěryhodnost zdroje. Pokud AI najde konzistentní informace v několika zdrojích, zvyšuje se důvěra v citování jednotlivce z tohoto okruhu. Zdroje, které odporují většinovému konsenzu, dostávají nižší prioritu, pokud nepřinášejí přesvědčivé důkazy. Tato tendence znamená, že sjednocená komunikace napříč vlastněnými, získanými i sdílenými kanály posiluje citovatelnost. Organizace by měly zajistit konzistentní sdělení na webu, sociálních sítích, v oborových médiích i na třetích stranách.
Strategie frekvence aktualizací je v éře AI důležitější než v tradičním SEO. Četnost publikace přímo ovlivňuje citovanost – AI upřednostňuje čerstvě aktualizovaný obsah. Organizace by měly aktualizovat obsah každých 48–72 hodin, aby udržely signály aktuálnosti, i když to nemusí znamenat kompletní přepis. Stačí doplnit nová data, aktualizovat statistiky nebo rozšířit sekce o novinky. Redakční systémy sledující frekvenci a čerstvost obsahu pomáhají udržet konkurenceschopnou citovanost, protože AI stále více zvýhodňuje aktuálnost. Tento kontinuální přístup se liší od tradičního SEO, kde obsah mohl zůstat na špici i bez aktualizací.
Strategické umístění na agregátorových webech vytváří více cest pro AI, jak obsah objevit. Získání místa v oborových žebříčcích, seznamech expertů nebo recenzních webech otevírá další příležitosti nad rámec vlastních zdrojů. Jediná zmínka ve vysoce citované publikaci vytváří více příležitostí pro objevení a zvyšuje šanci na citaci. Mediální vztahy a partnerské spolupráce nabývají na významu pro AI viditelnost stejně jako strategické umístění v oborových databázích a katalozích. Organizace by měly usilovat o zmínky v oborových žebříčcích, seznamech expertů i recenzních webech v rámci své AI strategie.
Implementace strukturovaných dat zvyšuje pravděpodobnost citace tím, že dělá obsah lépe strojově čitelným. Schema markup v AI čitelných formátech pomáhá AI rozpoznat a extrahovat konkrétní fakta bez nutnosti zpracovávat nestrukturovaný text. FAQ schema, Article schema s informacemi o autorovi a Organization schema vytvářejí strojově čitelné signály, které AI upřednostňuje. JSON-LD strukturovaná data umožňují AI efektivně extrahovat fakta, což zvyšuje pravděpodobnost citace i přesnost citovaných informací. Organizace využívající komplexní schema markup zaznamenávají měřitelné zlepšení citovanosti napříč AI platformami.
Rozvoj Wikipedie a knowledge graphu přináší násobící efekt, přestože vyžaduje dlouhodobé úsilí. Budování přítomnosti na Wikipedii vyžaduje neutrální, dobře zdrojovaný obsah splňující redakční pravidla. Paralelní optimalizace profilů na Wikidata, Google Knowledge Panelu a oborových databázích vytváří základní vrstvu důvěry, ke které se AI opakovaně vrací. Tyto záznamy v knowledge graphu slouží jako autoritativní referenční body, které modely konzultují napříč dotazy, proto je jejich rozvoj strategickou prioritou pro organizace usilující o dlouhodobou AI viditelnost.
Organizace by měly sledovat frekvenci citací ručním testováním relevantních dotazů napříč ChatGPT, Google AI Overviews, Perplexity a dalšími platformami. Pravidelné testování promptů odhalí, který obsah úspěšně získává citace a kde jsou mezery v AI reprezentaci. Tato metoda poskytuje přímý náhled do výkonu citací a pomáhá identifikovat příležitosti k optimalizaci. Algoritmy AI citací se neustále vyvíjejí, jak přibývají trénovací data a mění se strategie vyhledávání, což znamená, že strategie obsahu je nutné přizpůsobovat na základě výkonu. Pokud obsah přestane být citován navzdory předchozímu úspěchu, je čas na aktualizaci, doplnění čerstvých informací nebo lepší sémantické sladění.
Na jeden dotaz může být citováno více zdrojů, což vytváří prostor pro ko-citace místo přístupu “všechno nebo nic”. Organizace těží z tvorby komplexního obsahu, který doplňuje – ne duplikuje – již hojně citované zdroje. Analýza konkurenčního prostředí ukáže, které značky dominují viditelnosti v konkrétních kategoriích a kde jsou příležitosti. Dlouhodobé sledování výkonu citací odhaluje trendy a které URL přinášejí úspěch, což umožňuje replikovat vítězné strategie a škálovat úspěšné přístupy.
Získejte přehled, kde se váš obsah objevuje v odpovědích generovaných AI napříč ChatGPT, Perplexity, Google AI Overviews a dalšími platformami. Získejte aktuální vhled do své AI viditelnosti a výkonu citací.
Zjistěte, jak systémy AI vybírají, které zdroje citovat a které parafrázovat. Pochopte algoritmy výběru citací, vzorce zaujatosti a strategie pro zlepšení vidit...

Zjistěte, co jsou AI citace, jak fungují napříč ChatGPT, Perplexity a Google AI, a proč jsou důležité pro viditelnost vaší značky v generativních vyhledávačích....

Zjistěte, jak akademické citace ovlivňují vaši viditelnost v AI-generovaných odpovědích. Objevte, proč jsou citace důležitější než návštěvnost pro AI vyhledávač...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.