Míra, do jaké platformy s umělou inteligencí zveřejňují, jak vybírají a řadí zdroje při generování odpovědí. Transparentnost řazení AI označuje viditelnost algoritmů a kritérií, která určují, které zdroje se objevují v odpovědích generovaných AI, a tím ji odlišuje od tradičního řazení vyhledávačů. Tato transparentnost je zásadní pro tvůrce obsahu, vydavatele i uživatele, kteří potřebují porozumět tomu, jak je informace vybírána a upřednostňována. Bez transparentnosti nemohou uživatelé ověřit důvěryhodnost zdrojů ani pochopit možné zkreslení v obsahu generovaném AI.
Transparentnost řazení AI
Míra, do jaké platformy s umělou inteligencí zveřejňují, jak vybírají a řadí zdroje při generování odpovědí. Transparentnost řazení AI označuje viditelnost algoritmů a kritérií, která určují, které zdroje se objevují v odpovědích generovaných AI, a tím ji odlišuje od tradičního řazení vyhledávačů. Tato transparentnost je zásadní pro tvůrce obsahu, vydavatele i uživatele, kteří potřebují porozumět tomu, jak je informace vybírána a upřednostňována. Bez transparentnosti nemohou uživatelé ověřit důvěryhodnost zdrojů ani pochopit možné zkreslení v obsahu generovaném AI.
Co je transparentnost řazení AI?
Transparentnost řazení AI označuje zveřejnění toho, jak systémy umělé inteligence vybírají, upřednostňují a prezentují zdroje při generování odpovědí na uživatelské dotazy. Na rozdíl od tradičních vyhledávačů, které zobrazují seřazené seznamy odkazů, moderní platformy AI jako Perplexity, ChatGPT a Google AI Overviews integrují výběr zdrojů přímo do procesu generování odpovědi, takže kritéria řazení jsou pro uživatele většinou neviditelná. Tato neprůhlednost vytváří zásadní mezeru mezi tím, co uživatel vidí (syntetizovaná odpověď), a tím, jak tato odpověď vznikla (které zdroje byly vybrány, jak byly ohodnoceny a citovány). Pro tvůrce obsahu a vydavatele tato netransparentnost znamená, že jejich viditelnost závisí na algoritmech, kterým nemohou rozumět ani je ovlivnit tradičními optimalizačními metodami. Rozdíl oproti transparentnosti tradičních vyhledávačů je podstatný: zatímco Google zveřejňuje obecné faktory řazení a kvalitativní směrnice, platformy AI často považují své mechanismy výběru zdrojů za firemní tajemství. Klíčovými zasaženými aktéry jsou tvůrci obsahu usilující o viditelnost, vydavatelé sledující přisuzování návštěvnosti, správci značek monitorující reputaci, výzkumníci ověřující zdroje informací a uživatelé, kteří potřebují chápat důvěryhodnost odpovědí generovaných AI. Porozumění transparentnosti řazení AI se stalo zásadní pro každého, kdo vytváří, šíří nebo spoléhá na digitální obsah v čím dál více AI-zprostředkovaném informačním prostředí.
Jak platformy AI řadí a vybírají zdroje
Platformy AI používají systémy Retrieval-Augmented Generation (RAG), které kombinují jazykové modely s vyhledáváním informací v reálném čase, aby odpovědi zakládaly na skutečných zdrojích místo výhradně na trénovacích datech. Proces RAG zahrnuje tři hlavní fáze: vyhledání (nalezení relevantních dokumentů), řazení (uspořádání zdrojů podle relevance) a generování (syntéza informací při zachování citací). Různé platformy uplatňují odlišné přístupy k řazení—Perplexity upřednostňuje autoritu a aktuálnost zdrojů, Google AI Overviews klade důraz na tematickou relevanci a signály E-E-A-T (Zkušenost, Odbornost, Autoritativnost, Důvěryhodnost), zatímco ChatGPT Search balancuje kvalitu zdrojů s komplexností odpovědi. Mezi faktory ovlivňující výběr zdrojů obvykle patří autorita domény (zavedená pověst a zpětné odkazy), aktuálnost obsahu (čerstvost informací), tematická relevance (sémantická shoda s dotazem), signály zapojení (metriky interakce uživatelů) a četnost citací (jak často jsou zdroje citovány jinými autoritativními weby). Systémy AI váží tyto signály různě dle záměru dotazu—faktické dotazy mohou upřednostnit autoritu a aktuálnost, zatímco u názorových dotazů může být důraz na různorodost pohledů a zapojení. Algoritmy řazení zůstávají převážně nezveřejněné, i když dokumentace platforem nabízí jen omezený vhled do jejich váhových mechanismů.
Průmysl AI postrádá standardizované postupy zveřejňování, jak řadicí systémy fungují, což vytváří roztříštěné prostředí, kde si každá platforma určuje vlastní úroveň transparentnosti. OpenAI ChatGPT Search poskytuje minimální vysvětlení výběru zdrojů, systémy AI od Metas nabízí omezenou dokumentaci a Google AI Overviews zveřejňuje více než konkurence, ale stále zadržuje zásadní algoritmické detaily. Platformy odmítají plné zveřejnění s odkazem na konkurenční výhodu, firemní tajemství a složitost vysvětlování strojového učení široké veřejnosti—tato neprůhlednost však brání externím auditům a odpovědnosti. Objevuje se problém tzv. “praní zdrojů”, kdy systémy AI citují zdroje, které samy agregují nebo přepisují původní obsah, což zatemňuje skutečný původ informací a může šířit dezinformace přes několik vrstev syntézy. Regulační tlak roste: Zákon o AI v EU vyžaduje, aby systémy AI s vysokým rizikem vedly dokumentaci trénovacích dat a rozhodovacích procesů, zatímco Politika odpovědnosti za AI (NTIA) žádá firmy o zveřejnění schopností, omezení a vhodných použití AI systémů. Konkrétní nedostatky v transparentnosti zahrnují počáteční problémy Perplexity se správným připsáním zdrojů (následně zlepšené), vágní vysvětlení Googlu o výběru zdrojů v AI Overviews a omezenou transparentnost ChatGPT ohledně toho, proč se určité zdroje v odpovědích objevují a jiné ne. Absence standardizovaných metrik pro měření transparentnosti ztěžuje uživatelům a regulátorům objektivně srovnávat platformy.
Dopad na tvůrce obsahu a vydavatele
Neprůhlednost řadících systémů AI vytváří významné výzvy v oblasti viditelnosti pro tvůrce obsahu, protože tradiční SEO strategie navržené pro vyhledávače se nedají přímo aplikovat na optimalizaci pro AI platformy. Vydavatelé nemohou snadno pochopit, proč se jejich obsah v některých AI odpovědích objevuje a v jiných ne, což znemožňuje vytvářet cílené strategie pro zvýšení viditelnosti v odpovědích generovaných AI. Vzniká citace bias, kdy systémy AI nepoměrně zvýhodňují určité zdroje—zavedená mediální média, akademické instituce nebo weby s vysokou návštěvností—zatímco menší vydavatele, nezávislé tvůrce či experty na úzká témata mohou opomíjet, přestože mají stejně hodnotné informace. Menší vydavatelé čelí zvláštním nevýhodám, protože řadicí systémy AI často kladou velkou váhu na autoritu domény a novější či specializované weby postrádají zpětné odkazy a povědomí značky, které mají zavedené subjekty. Výzkum Search Engine Land ukazuje, že AI Overviews snížily míru prokliků na tradiční výsledky vyhledávače o 18–64 % v závislosti na typu dotazu, přičemž návštěvnost je koncentrována mezi málo zdrojů citovaných v AI odpovědích. Rozdíl mezi SEO (optimalizace pro vyhledávače) a GEO (optimalizace pro generativní stroje) nabývá na významu—zatímco SEO se zaměřuje na řazení v tradičním vyhledávání, GEO vyžaduje pochopení a optimalizaci pro kritéria výběru AI platforem, která zůstávají většinou neprůhledná. Tvůrci obsahu potřebují nástroje jakoAmICited.com pro sledování, kde se jejich obsah objevuje v AI odpovědích, sledování četnosti citací a pochopení své viditelnosti napříč různými platformami AI.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mechanismy a standardy transparentnosti
Průmysl AI vyvinul několik rámců pro dokumentaci a zveřejňování chování systémů, i když jejich implementace zůstává na platformách nejednotná. Modelové karty poskytují standardizovanou dokumentaci výkonu strojového učení, zamýšlených použití, omezení a analýzy biasu—podobně jako nutriční štítky pro AI systémy. Datasheety pro datasety dokumentují složení, metodiku sběru a možné biasy v trénovacích datech, čímž řeší princip, že AI systémy jsou jen tak dobré jako jejich tréninkové informace. Systémové karty mají širší záběr a dokumentují chování systému jako celku včetně interakce komponent, možných selhání a výkonnosti v různých uživatelských skupinách. Politika odpovědnosti za AI (NTIA) doporučuje, aby firmy vedly podrobnou dokumentaci vývoje, testování a nasazení AI systémů, se zvláštním důrazem na aplikace s vysokým dopadem na veřejný zájem. Zákon o AI v EU vyžaduje, aby systémy AI s vysokým rizikem vedly technickou dokumentaci, evidenci trénovacích dat a protokoly výkonu, včetně povinných zpráv transparentnosti a informování uživatelů. Nejlepší průmyslové postupy nyní zahrnují:
Datasheety – Zdroje trénovacích dat, metody sběru, možné biasy
Systémové karty – Chování celého systému, interakce komponent, selhání
Technické zprávy – Detaily architektury, rozhodnutí při návrhu, metodika evaluace
Zprávy o transparentnosti – Pravidelné zveřejňování výkonu systému, stížností uživatelů, změn algoritmů
API dokumentace – Vysvětlení faktorů řazení, kritérií výběru zdrojů, možností uživatelské kontroly
Srovnání přístupů k transparentnosti na různých AI platformách
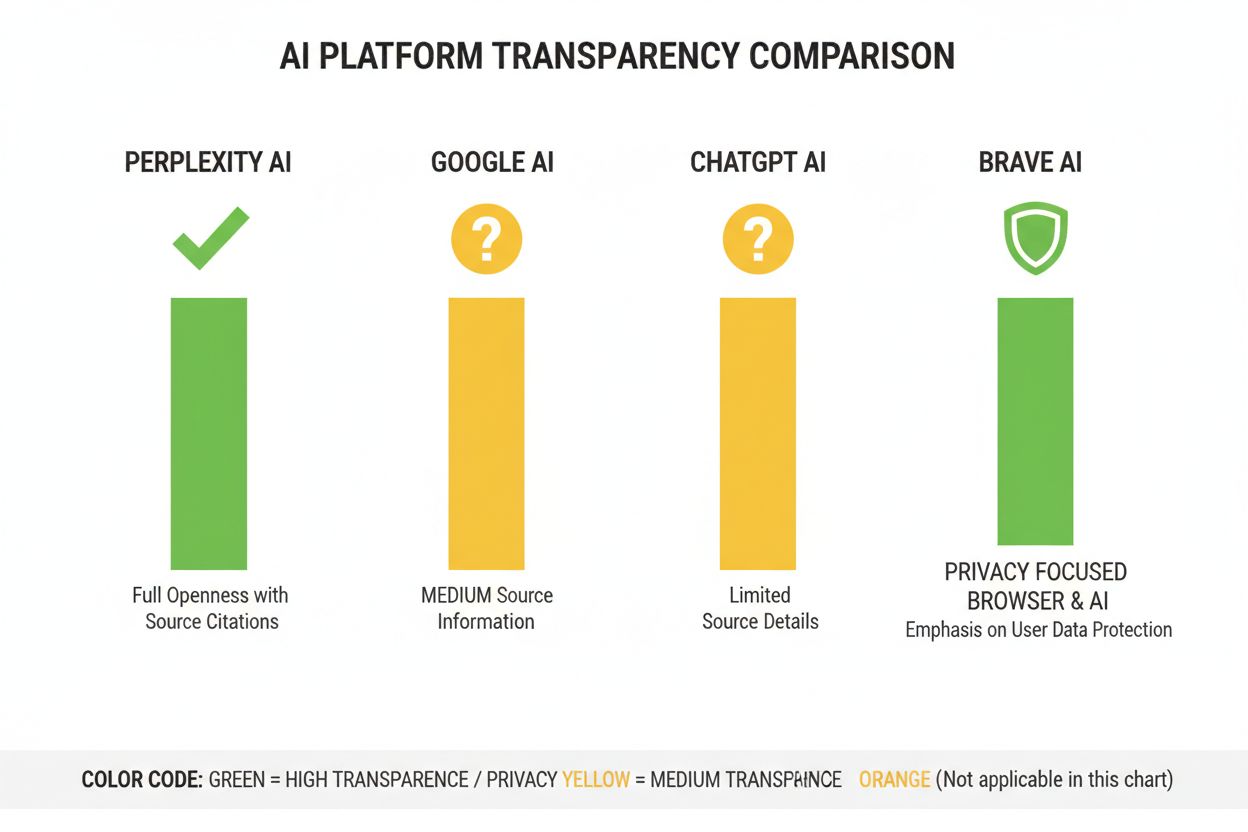
Perplexity se profiluje jako nejtransparentnější AI platforma v oblasti citací, zobrazuje odkazy na zdroje přímo v odpovědích a umožňuje uživatelům přesně vidět, které zdroje přispěly ke konkrétním tvrzením. Platforma poskytuje poměrně jasnou dokumentaci svého přístupu k řazení s důrazem na autoritu zdrojů, odbornou způsobilost a aktuálnost obsahu, i když přesné váhy těchto faktorů zůstávají firemním tajemstvím. Google AI Overviews nabízejí střední úroveň transparentnosti tím, že na konci odpovědí uvádějí citované zdroje, ale poskytují jen omezené vysvětlení, proč byly některé zdroje vybrány a jiné ne nebo jak algoritmus váží různé signály. Dokumentace Googlu zdůrazňuje principy E-E-A-T, ale zcela neodhaluje, jak jsou tyto principy měřeny či váženy v řazení AI. OpenAI ChatGPT Search představuje střední cestu, zobrazuje zdroje odděleně od samotného textu odpovědi a umožňuje uživatelům prokliknout se na původní obsah, ale nabízí jen minimální vysvětlení kritérií výběru zdrojů či metodologie řazení. Brave Leo upřednostňuje transparentnost zaměřenou na soukromí, zveřejňuje, že používá zdroje respektující soukromí a nesleduje dotazy uživatelů, což je však vykoupeno menším vysvětlením mechanismů řazení. Consensus je výjimkou, zaměřuje se výlučně na akademický výzkum a poskytuje vysokou transparentnost díky metrikám citovanosti, recenzovanosti a indikátorům kvality studie—čímž je nejtransparentnější platformou z hlediska algoritmů pro výzkumné dotazy. Uživatelská kontrola se výrazně liší: Perplexity umožňuje filtrování zdrojů, Consensus umožňuje filtrovat podle typu a kvality studií, zatímco Google a ChatGPT nabízejí jen minimální přizpůsobení preferencí řazení. Odlišnosti v přístupu k transparentnosti odrážejí různé obchodní modely a cílové skupiny: akademicky zaměřené platformy upřednostňují zveřejňování, zatímco platformy pro širokou veřejnost balancují mezi transparentností a ochranou firemního know-how.
Proč na transparentnosti řazení záleží
Důvěra a důvěryhodnost zásadně závisí na tom, zda uživatelé rozumí tomu, jak se k nim informace dostávají—když systémy AI zamlčují své zdroje nebo logiku řazení, uživatelé nemohou nezávisle ověřit tvrzení ani posoudit spolehlivost zdroje. Transparentnost umožňuje ověřování a fact-checking, protože výzkumníci, novináři a informovaní uživatelé mohou sledovat tvrzení zpět k původním zdrojům a hodnotit jejich přesnost a kontext. Prevence dezinformací a biasu je dalším zásadním benefitem transparentnosti: když jsou algoritmy řazení viditelné, výzkumníci mohou odhalit systematické biasy (například zvýhodňování určitých politických pohledů nebo komerčních zájmů) a platformy mohou být činěny odpovědnými za šíření nepravdivých informací. Odpovědnost algoritmů je základním právem uživatele v demokratických společnostech—lidé si zaslouží rozumět tomu, jak systémy, které formují jejich informační prostředí, činí rozhodnutí, zvlášť když tyto systémy ovlivňují veřejné mínění, nákupní rozhodnutí a přístup ke znalostem. Pro výzkum a akademickou práci je transparentnost naprosto nezbytná, protože odborníci musí znát výběr zdrojů pro správné zasazení AI generovaných souhrnů a zajištění, že se omylem nespoléhají na biasované či neúplné zdroje. Obchodní dopady pro tvůrce obsahu jsou zásadní: bez znalosti faktorů řazení nemohou vydavatelé optimalizovat svou obsahovou strategii, menší tvůrci nemohou férově soutěžit s velkými médii a celý ekosystém se stává méně meritokratickým. Transparentnost navíc chrání uživatele před manipulací—pokud jsou kritéria řazení skryta, mohou je zneužít aktéři s nekalými úmysly k propagaci zavádějícího obsahu, zatímco transparentní systémy lze auditovat a vylepšovat.
Budoucnost transparentnosti řazení AI
Regulační trendy směřují k povinné transparentnosti: implementace Zákona o AI v EU v letech 2025-2026 bude vyžadovat podrobnou dokumentaci a zveřejňování pro systémy AI s vysokým rizikem, přičemž podobné regulace se objevují také ve Velké Británii, Kalifornii a dalších jurisdikcích. Průmysl směřuje ke standardizaci transparentních postupů, přičemž organizace jako Partnership on AI a akademické instituce vytvářejí společné rámce pro dokumentaci a zveřejňování chování AI systémů. Uživatelská poptávka po transparentnosti roste s tím, jak si veřejnost více uvědomuje roli AI v distribuci informací—průzkumy ukazují, že více než 70 % uživatelů chce rozumět tomu, jak AI vybírá zdroje a řadí informace. Technologické inovace v oblasti vysvětlitelné AI (XAI) činí stále reálnějším poskytování podrobných vysvětlení rozhodnutí o řazení bez nutnosti plně prozradit firemní algoritmy, například pomocí technik jako LIME (Local Interpretable Model-agnostic Explanations) a SHAP (SHapley Additive exPlanations). Monitorovací nástroje jako AmICited.com budou stále důležitější, protože platformy zavádějí opatření transparentnosti a pomáhají tvůrcům obsahu a vydavatelům sledovat svou viditelnost napříč více AI systémy a chápat, jak změny v řazení ovlivňují jejich dosah. Souhra regulačních požadavků, uživatelských očekávání a technických možností naznačuje, že roky 2025–2026 budou pro transparentnost řazení AI klíčové, přičemž platformy pravděpodobně osvojí více standardizované postupy zveřejňování, zavedou lepší uživatelské možnosti výběru zdrojů a poskytnou srozumitelnější vysvětlení logiky řazení. Budoucí prostředí bude pravděpodobně charakterizovat vrstvená transparentnost—akademické a výzkumné platformy budou v čele s vysokou úrovní zveřejňování, platformy pro běžné uživatele nabídnou střední úroveň transparentnosti s možnostmi uživatelského přizpůsobení a dodržování regulací se stane základním očekáváním napříč celým průmyslem.
Často kladené otázky
Co je transparentnost řazení AI a proč na ní záleží?
Transparentnost řazení AI znamená, jak otevřeně platformy AI zveřejňují své algoritmy pro výběr a řazení zdrojů ve vygenerovaných odpovědích. Je důležitá, protože uživatelé potřebují rozumět důvěryhodnosti zdrojů, tvůrci obsahu musí optimalizovat viditelnost v AI a výzkumníci potřebují ověřovat informační zdroje. Bez transparentnosti mohou systémy AI zesilovat dezinformace a vytvářet neférové výhody pro zavedená média na úkor menších vydavatelů.
Jak platformy AI jako Perplexity a Google vybírají zdroje?
Platformy AI používají systémy Retrieval-Augmented Generation (RAG), které kombinují jazykové modely s vyhledáváním informací v reálném čase. Řadí zdroje na základě faktorů jako je autorita domény, aktuálnost obsahu, tematická relevance, signály zapojení a četnost citací. Přesné váhy těchto faktorů však většina platforem ponechává jako firemní tajemství a nezveřejňuje je.
Jaký je rozdíl mezi transparentností řazení AI a tradičním SEO?
Tradiční SEO se zaměřuje na řazení v seznamech odkazů vyhledávače, kde Google zveřejňuje obecné faktory řazení. Transparentnost řazení AI se týká toho, jak platformy AI vybírají zdroje pro syntetizované odpovědi, což zahrnuje odlišná kritéria a je většinou nezveřejněno. Zatímco strategie SEO jsou dobře zdokumentované, faktory řazení AI zůstávají převážně neprůhledné.
Jak mohu ověřit, zda jsou zdroje citované AI přesné?
Můžete kliknout na původní zdroje a ověřit tvrzení v jejich plném kontextu, zkontrolovat, zda jsou ze seriózních domén, hledat status recenzovanosti (zejména u akademického obsahu) a porovnávat informace napříč více zdroji. Nástroje jako AmICited pomáhají sledovat, které zdroje se objevují v AI odpovědích a jak často je váš obsah citován.
Které platformy AI jsou nejtransparentnější ohledně svých metod řazení?
Consensus vede v transparentnosti tím, že se zaměřuje výhradně na recenzovaný akademický výzkum s jasnými metrikami citovanosti. Perplexity poskytuje inline citace zdrojů a středně podrobné informace o faktorech řazení. Google AI Overviews nabízí střední úroveň transparentnosti, zatímco ChatGPT Search a Brave Leo zveřejňují o svých algoritmech řazení jen minimum informací.
Co jsou modelové karty a datasheety v kontextu AI transparentnosti?
Modelové karty jsou standardizovaná dokumentace výkonnosti AI systémů, zamýšlených použití, omezení a analýzy zkreslení. Datasheety dokumentují složení trénovacích dat, metody sběru a možné biasy. Systémové karty popisují chování systému jako celku. Tyto nástroje pomáhají zvyšovat transparentnost a srovnatelnost AI systémů, podobně jako nutriční štítky u potravin.
Jak ovlivňuje Zákon o AI v EU transparentnost řazení AI?
Zákon o AI v EU vyžaduje, aby systémy AI s vysokým rizikem vedly podrobnou technickou dokumentaci, evidenci trénovacích dat a protokoly výkonnosti. Stanovuje povinnost transparentních zpráv a informování uživatelů o použití AI systémů. Tyto požadavky tlačí AI platformy k většímu zveřejňování mechanismů řazení a kritérií výběru zdrojů.
AmICited.com je platforma pro monitoring citací v AI, která sleduje, jak systémy AI jako Perplexity, Google AI Overviews a ChatGPT citují vaši značku a obsah. Poskytuje přehled o tom, které zdroje se objevují v AI odpovědích, jak často je váš obsah citován a jak si vaše transparentnost řazení vede na různých platformách AI.
Sledujte viditelnost své značky na platformách AI
Sledujte, jak platformy AI jako Perplexity, Google AI Overviews a ChatGPT citují váš obsah. Pochopte transparentnost svého řazení a optimalizujte svou viditelnost napříč vyhledávači postavenými na AI s AmICited.
Transparentnost v úsilí o viditelnost AI: Nejlepší postupy pro zveřejnění
Zjistěte zásadní osvědčené postupy transparentnosti a zveřejnění AI. Objevte behaviorální, slovní a technické metody zveřejnění pro budování důvěry a zajištění ...
Jak se zotavit z nízké AI viditelnosti: Kompletní strategie obnovy
Zjistěte, jak se zotavit z nízké AI viditelnosti pomocí konkrétních strategií pro ChatGPT, Perplexity a další AI vyhledávače. Zlepšete přítomnost své značky v A...
Skryté náklady neviditelnosti v AI: Co se stane, když ChatGPT ignoruje vaši značku
Objevte skryté náklady neviditelnosti vaší značky v AI. Zjistěte, proč na zmínkách v ChatGPT záleží, jak měřit ztrátu viditelnosti a 8 taktik, jak znovu získat ...
9 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.