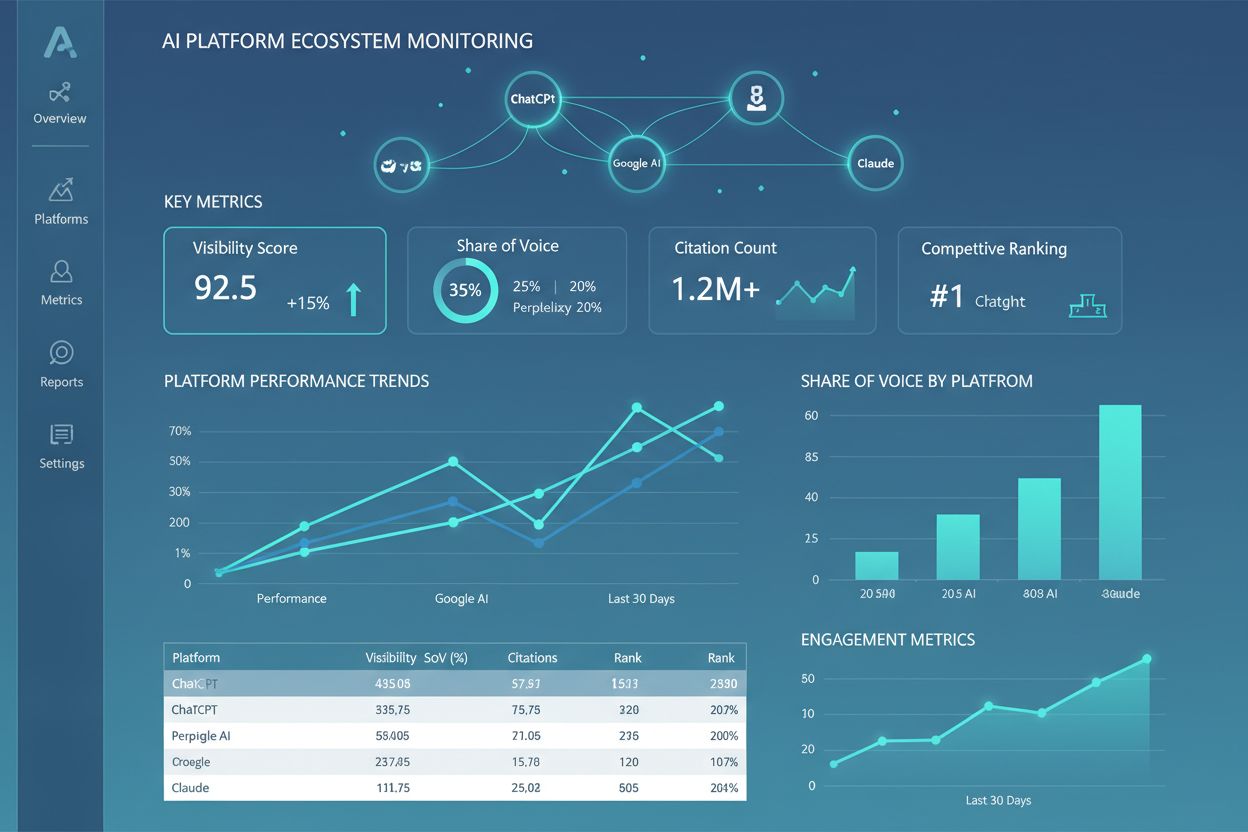
Ekosystém AI platforem
Zjistěte, co je ekosystém AI platforem, jak spolu propojené AI systémy spolupracují a proč je důležité řídit přítomnost vaší značky napříč více AI platformami p...
5 min čtení

Izolovaná sandboxová prostředí navržená pro validaci, hodnocení a ladění modelů a aplikací umělé inteligence před nasazením do produkce. Tato kontrolovaná prostředí umožňují testování výkonu AI obsahu na různých platformách, měření metrik a zajištění spolehlivosti bez ovlivnění živých systémů nebo vystavení citlivých dat.
Izolovaná sandboxová prostředí navržená pro validaci, hodnocení a ladění modelů a aplikací umělé inteligence před nasazením do produkce. Tato kontrolovaná prostředí umožňují testování výkonu AI obsahu na různých platformách, měření metrik a zajištění spolehlivosti bez ovlivnění živých systémů nebo vystavení citlivých dat.
Testovací prostředí pro AI je kontrolovaný, izolovaný výpočetní prostor navržený k validaci, hodnocení a ladění modelů a aplikací umělé inteligence před jejich nasazením do produkčního prostředí. Slouží jako sandbox, kde mohou vývojáři, datoví vědci a QA týmy bezpečně spouštět AI modely, testovat různé konfigurace a měřit výkon podle předem definovaných metrik bez ovlivnění živých systémů nebo vystavení citlivých dat. Tato prostředí replikují produkční podmínky při zachování úplné izolace, což týmům umožňuje identifikovat problémy, optimalizovat chování modelu a zajistit spolehlivost v různých scénářích. Testovací prostředí představuje klíčový kvalitativní mezník v životním cyklu vývoje AI, propojující experimentální prototypování s podnikovým nasazením.

Komplexní testovací prostředí pro AI se skládá z několika propojených technických vrstev, které společně poskytují úplné testovací možnosti. Vrstva spouštění modelu zajišťuje samotnou inferenci a výpočty, podporuje více frameworků (PyTorch, TensorFlow, ONNX) a typů modelů (LLM, počítačové vidění, časové řady). Vrstva správy dat spravuje testovací datasety, fixturny a generování syntetických dat při zachování izolace a souladu s předpisy. Hodnoticí framework zahrnuje moduly pro metriky, knihovny asercí a skórovací systémy, které měří výstupy modelu vůči očekávaným výsledkům. Vrstva monitoringu a logování zachycuje trasování běhu, výkonové metriky, latenci a chybové logy pro následnou analýzu. Orchestrace řídí testovací workflow, paralelní spouštění, alokaci zdrojů a provisioning prostředí. Níže je porovnání klíčových architektonických komponent u různých typů testovacích prostředí:
| Komponenta | Testování LLM | Počítačové vidění | Časové řady | Multi-modální |
|---|---|---|---|---|
| Spouštění modelu | Inference Transformeru | Inference akcelerovaná GPU | Sekvenční zpracování | Hybridní exekuce |
| Formát dat | Text/tokens | Obrázky/tenzory | Číselné sekvence | Smíšená média |
| Hodnoticí metriky | Sémantická podobnost, halucinace | Přesnost, IoU, F1-skóre | RMSE, MAE, MAPE | Cross-modální zarovnání |
| Požadavky na latenci | Obvykle 100-500 ms | Obvykle 50-200 ms | <100 ms typicky | 200-1000 ms obvykle |
| Metoda izolace | Kontejner/VM | Kontejner/VM | Kontejner/VM | Firecracker microVM |
Moderní testovací prostředí pro AI musí podporovat heterogenní ekosystémy modelů, což umožňuje týmům hodnotit aplikace napříč různými poskytovateli LLM, frameworky a cílovými nasazeními současně. Multi-platformní testování umožňuje organizacím porovnávat výstupy modelů od OpenAI GPT-4, Anthropic Claude, Mistral a open-source alternativ jako Llama ve stejném testovacím prostředí, což usnadňuje informované rozhodování o výběru modelu. Platformy jako E2B poskytují izolované sandboxy, které spouštějí kód generovaný libovolným LLM, podporují Python, JavaScript, Ruby a C++ s plným přístupem k souborovému systému, terminálu a instalaci balíčků. IntelIQ.dev umožňuje paralelní porovnání více AI modelů s unifikovaným rozhraním, což týmům dovoluje testovat prompty s ochranou a šablony s politikami napříč různými poskytovateli. Testovací prostředí musí zvládat:
Testovací prostředí pro AI slouží různorodým potřebám organizací v oblasti vývoje, zajištění kvality a compliance. Vývojové týmy používají testovací prostředí k validaci chování modelů během iterativního vývoje, testování různých promptů, ladění parametrů a ladění neočekávaných výstupů před integrací. Datoví vědci využívají tato prostředí k hodnocení výkonu modelů na odložených datasetech, porovnávání různých architektur a měření metrik, jako jsou přesnost, recall, F1-skóre. Monitoring produkce zahrnuje průběžné testování nasazených modelů vůči základním metrikám, detekci degradace výkonu a spouštění retrainovacích pipeline při překročení kvalitativních prahů. Compliance a bezpečnostní týmy využívají testovací prostředí k ověření, že modely splňují regulatorní požadavky, negenerují zaujaté výstupy a správně pracují s citlivými daty. Podniková použití zahrnují:
Ekosystém testování AI zahrnuje specializované platformy pro různé scénáře testování a organizační úrovně. DeepEval je open-source hodnoticí framework pro LLM s více než 50 výzkumně podloženými metrikami včetně správnosti odpovědí, sémantické podobnosti, detekce halucinací a skórování toxicity, s nativní integrací do Pytest pro CI/CD workflowy. LangSmith (od LangChain) nabízí komplexní observabilitu, hodnocení a nasazení s vestavěným trasováním, verzováním promptů a správou datasetů pro LLM aplikace. E2B poskytuje bezpečné, izolované sandboxy poháněné Firecracker microVMs, podporuje spouštění kódu s náběhem pod 200 ms, až 24hodinové relace a integraci s hlavními poskytovateli LLM. IntelIQ.dev klade důraz na testování s ochranou soukromí díky end-to-end šifrování, řízení přístupu na základě rolí a podpoře více AI modelů včetně GPT-4, Claude a open-source alternativ. Následující tabulka porovnává klíčové schopnosti:
| Nástroj | Primární zaměření | Metriky | Integrace s CI/CD | Podpora více modelů | Cenový model |
|---|---|---|---|---|---|
| DeepEval | Hodnocení LLM | 50+ metrik | Nativní Pytest | Omezená | Open-source + cloud |
| LangSmith | Observabilita & hodnocení | Vlastní metriky | API integrace | Ekosystém LangChain | Freemium + enterprise |
| E2B | Spouštění kódu | Výkonové metriky | GitHub Actions | Všechny LLM | Platba za použití + enterprise |
| IntelIQ.dev | Testování s důrazem na soukromí | Vlastní metriky | Workflow builder | GPT-4, Claude, Mistral | Předplatné |
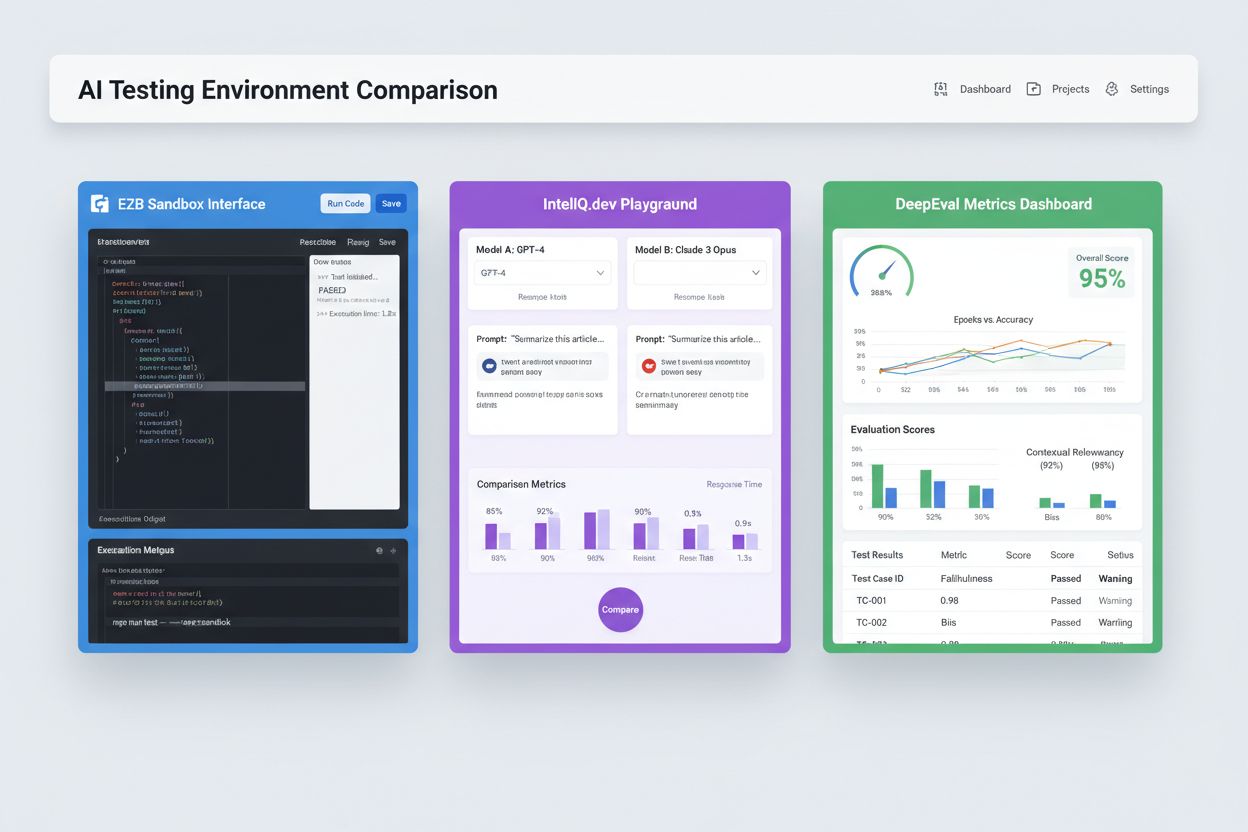
Podniková testovací prostředí pro AI musí implementovat přísná bezpečnostní opatření na ochranu citlivých dat, zajištění souladu s předpisy a prevenci neoprávněného přístupu. Izolace dat vyžaduje, aby testovací data nikdy neunikla do externích API nebo třetích stran; platformy jako E2B používají Firecracker microVMs pro úplnou izolaci procesů bez sdíleného jádra. Šifrování by mělo zahrnovat end-to-end šifrování pro data v klidu i v přenosu, s podporou požadavků HIPAA, SOC 2 Type 2 a GDPR. Řízení přístupu musí vynucovat oprávnění na základě rolí, auditní logování a schvalovací workflowy pro citlivé scénáře. Doporučené postupy zahrnují: udržování oddělených testovacích datasetů bez produkčních dat, maskování osobně identifikovatelných údajů (PII), použití syntetických dat pro realistické testování bez rizika ohrožení soukromí, pravidelné bezpečnostní audity testovací infrastruktury a dokumentaci všech výsledků testů pro účely compliance. Organizace by měly také implementovat detekci zaujatosti k odhalení diskriminačního chování modelu, používat interpretační nástroje jako SHAP nebo LIME pro pochopení rozhodnutí modelu a zavést logování rozhodnutí pro sledování, jak modely dospívají ke konkrétním výstupům pro regulační odpovědnost.
Testovací prostředí pro AI se musí plynule integrovat do stávajících pipeline pro kontinuální integraci a nasazení, aby umožnila automatizované kvalitativní brány a rychlé iterace. Nativní integrace s CI/CD umožňuje automatické spouštění testů při commitech, pull requestech nebo v plánovaných intervalech prostřednictvím platforem jako GitHub Actions, GitLab CI nebo Jenkins. Integrace DeepEval s Pytest umožňuje vývojářům psát testovací případy jako standardní Python testy, které se spouštějí v rámci stávajících CI workflow, s výsledky reportovanými spolu s tradičními unit testy. Automatizované hodnocení může měřit výkonové metriky modelů, porovnávat výstupy s referenčními verzemi a blokovat nasazení, pokud nejsou splněny kvalitativní prahy. Správa artefaktů zahrnuje ukládání testovacích datasetů, checkpointů modelů a výsledků hodnocení do verzovacích systémů nebo repozitářů pro auditovatelnost a reprodukovatelnost. Mezi integrační vzory patří:
Oblast testovacích prostředí pro AI se rychle vyvíjí, aby řešila nové výzvy v oblasti složitosti modelů, škálovatelnosti a heterogenity. Agentní testování nabývá na významu, protože AI systémy se posouvají od jednorázových inferencí k vícekrokovým workflow, kde agenti využívají nástroje, rozhodují se a interagují s externími systémy—vyžadující nové hodnoticí frameworky, které měří dokončení úkolu, bezpečnost a spolehlivost. Distribuované hodnocení umožňuje testování ve velkém měřítku díky spouštění tisíců paralelních testovacích instancí v cloudu, což je klíčové pro reinforcement learning a trénink velkých modelů. Monitoring v reálném čase se posouvá od batchového hodnocení k průběžnému, produkčnímu testování, které detekuje degradaci výkonu, drift dat a vznikající zaujatosti v živých systémech. Observační platformy jako AmICited se stávají klíčovými nástroji pro komplexní monitoring a přehled AI, poskytují centralizované dashboardy pro sledování výkonu modelu, vzorců používání a kvalitativních metrik napříč celým AI portfoliem. Budoucí testovací prostředí budou stále více zahrnovat automatizovanou nápravu, kdy systémy nejen detekují problémy, ale také automaticky spouští retrainovací pipeline nebo aktualizace modelů, a cross-modální hodnocení, tedy simultánní testování textových, obrazových, zvukových a video modelů v rámci jednotných frameworků.
Testovací prostředí pro AI je izolovaný sandbox, kde můžete bezpečně testovat modely, prompty a konfigurace bez ovlivnění živých systémů nebo uživatelů. Produkční nasazení je živé prostředí, kde modely slouží skutečným uživatelům. Testovací prostředí vám umožní odhalit problémy, optimalizovat výkon a ověřit změny před nasazením do produkce, čímž snižuje riziko a zajišťuje kvalitu.
Ano, moderní testovací prostředí pro AI podporují testování více modelů současně. Platformy jako E2B, IntelIQ.dev a DeepEval vám umožní testovat stejný prompt nebo vstup na různých LLM poskytovatelích (OpenAI, Anthropic, Mistral atd.) zároveň, což umožňuje přímé porovnání výstupů a výkonových metrik.
Podniková testovací prostředí pro AI implementují několik bezpečnostních vrstev včetně izolace dat (kontejnerizace nebo microVM), end-to-end šifrování, řízení přístupu na základě rolí, auditní logování a certifikace souladu (SOC 2, GDPR, HIPAA). Data nikdy neopouštějí izolované prostředí, pokud nejsou explicitně exportována, což chrání citlivé informace.
Testovací prostředí umožňují dodržování předpisů poskytováním auditních stop všech hodnocení modelů, podporou maskování dat a generování syntetických dat, vynucováním řízení přístupu a udržováním úplné izolace testovacích dat od produkčních systémů. Tato dokumentace a kontrola pomáhá organizacím splnit regulační požadavky jako GDPR, HIPAA a SOC 2.
Klíčové metriky závisí na vašem použití: pro LLM sledujte přesnost, sémantickou podobnost, míru halucinací a latenci; pro RAG systémy měřte přesnost/recall kontextu a věrohodnost; pro klasifikační modely sledujte přesnost, recall a F1 skóre; pro všechny modely sledujte degradaci výkonu v čase a indikátory zaujatosti.
Náklady se liší podle platformy: DeepEval je open-source a zdarma; LangSmith nabízí bezplatnou verzi s placenými plány od 39 $/měsíc; E2B používá platbu podle využití na základě času běhu sandboxu; IntelIQ.dev nabízí předplatné. Mnoho platforem nabízí také podnikové ceny pro rozsáhlé nasazení.
Ano, většina moderních testovacích prostředí podporuje integraci s CI/CD. DeepEval se nativně integruje s Pytest, E2B pracuje s GitHub Actions a GitLab CI a LangSmith poskytuje integraci přes API. To umožňuje automatizované testování při každém commitu a vynucení kontrolních bran při nasazení.
End-to-end testování považuje celou vaši AI aplikaci za černou skříňku a testuje konečný výstup oproti očekávaným výsledkům. Testování na úrovni komponent hodnotí jednotlivé části (LLM volání, retrievery, použití nástrojů) samostatně pomocí trasování a instrumentace. Testování komponent poskytuje hlubší vhled do toho, kde dochází k problémům, zatímco end-to-end testování ověřuje celkové chování systému.
AmICited sleduje, jak AI systémy odkazují na vaši značku a obsah v ChatGPT, Claude, Perplexity a Google AI. Získejte okamžitý přehled o vaší AI přítomnosti díky komplexnímu monitoringu a analytice.
Zjistěte, co je ekosystém AI platforem, jak spolu propojené AI systémy spolupracují a proč je důležité řídit přítomnost vaší značky napříč více AI platformami p...
Zjistěte, co je AI Visibility Center of Excellence, jeho klíčové odpovědnosti, monitorovací schopnosti a jak umožňuje organizacím udržovat transparentnost a kon...

Diskuze komunity o strategiích monitorování AI na více platformách. Skutečné zkušenosti marketérů a SEO profesionálů se sledováním viditelnosti značky napříč Ch...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.