
Budování entity značky pro rozpoznání AI
Zjistěte, jak vybudovat a optimalizovat entitu své značky pro rozpoznání umělou inteligencí. Implementujte schema markup, propojování entit a strukturovaná data...
14 min čtení

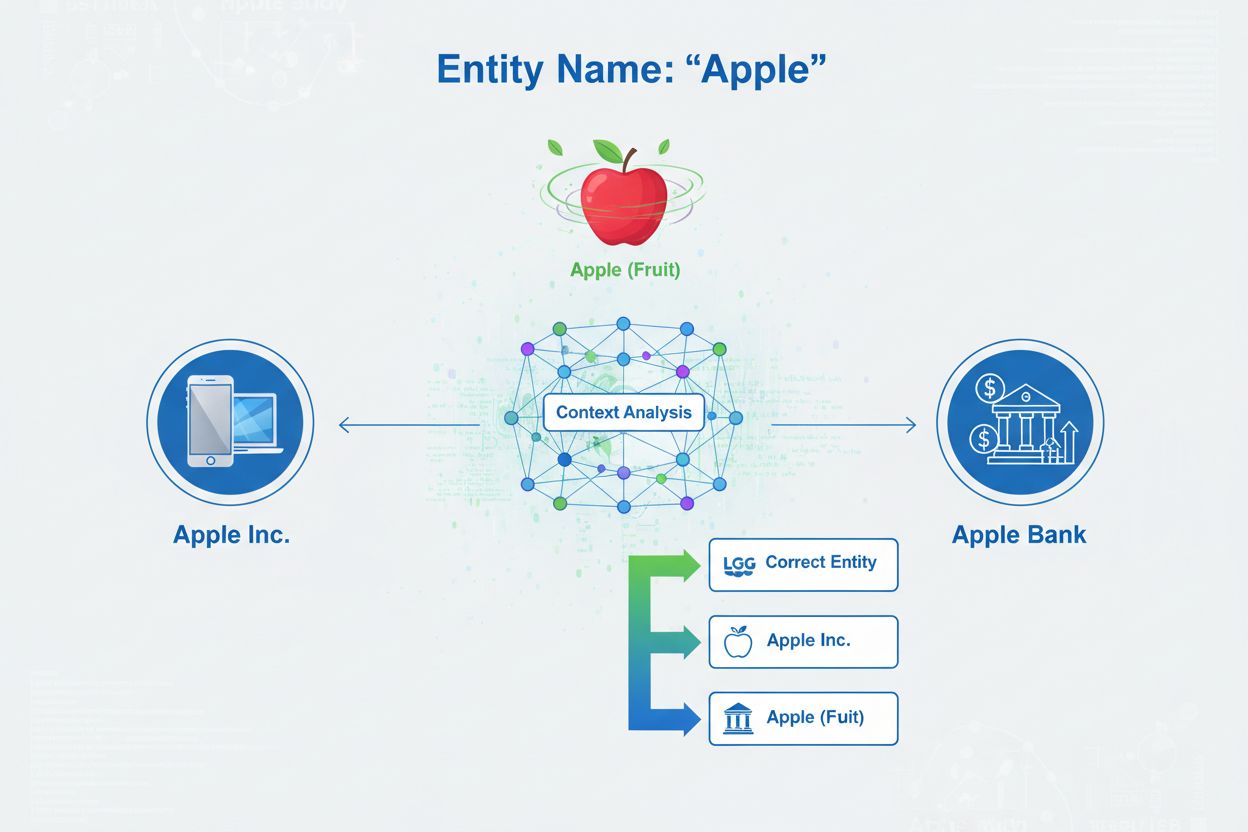
Disambiguace entity je proces určování, na kterou konkrétní entitu se daná zmínka vztahuje, když více entit sdílí stejné jméno. Pomáhá AI systémům přesně chápat a citovat obsah tím, že řeší nejednoznačnost v odkazech na pojmenované entity a zajišťuje, že zmínky o ‘Apple’ správně identifikují, zda se jedná o Apple Inc., ovoce nebo jinou entitu se stejným názvem.
Disambiguace entity je proces určování, na kterou konkrétní entitu se daná zmínka vztahuje, když více entit sdílí stejné jméno. Pomáhá AI systémům přesně chápat a citovat obsah tím, že řeší nejednoznačnost v odkazech na pojmenované entity a zajišťuje, že zmínky o 'Apple' správně identifikují, zda se jedná o Apple Inc., ovoce nebo jinou entitu se stejným názvem.
Disambiguace entity je proces určování, na kterou konkrétní entitu se daná zmínka vztahuje, když více entit sdílí stejné jméno nebo podobné odkazy. V kontextu umělé inteligence a zpracování přirozeného jazyka (NLP) disambiguace entity zajišťuje, že když AI systém narazí v textu na pojmenovanou entitu, správně určí, na jaký skutečný objekt, osobu, organizaci nebo místo se odkazuje. To se zásadně liší od rozpoznávání pojmenovaných entit (NER), které pouze identifikuje, že entita existuje, a zařadí ji do kategorie jako “osoba”, “organizace” nebo “místo”. Zatímco NER odpovídá na otázku “Je zde nějaká entita?”, disambiguace entity odpovídá “Která konkrétní entita to je?” Například při zpracování věty “Apple byl výtvorem Stevea Jobse” NER identifikuje “Apple” jako organizaci, ale disambiguace entity určí, zda jde o Apple Inc., technologickou společnost, nebo případně o jinou entitu se stejným jménem. Tento rozdíl je zásadní pro AI systémy, které potřebují přesně chápat a citovat obsah, a proto AmICited.com sleduje, jak AI systémy jako ChatGPT, Perplexity a Google AI Přehledy zvládají disambiguaci entity při generování odpovědí o značkách a organizacích.
Základním problémem, který disambiguace entity řeší, je nejednoznačnost—skutečnost, že mnoho názvů entit může odkazovat na různé skutečné objekty. Tato nejednoznačnost představuje významné výzvy pro AI systémy, které se snaží porozumět a generovat přesný obsah. Podle Stanford AI Index 2024 více než 18 % výstupů LLM týkajících se značkových entit obsahuje buď halucinace, nebo chybné přiřazení entit, což znamená, že AI systémy často zaměňují jednu entitu za jinou nebo generují nepravdivé informace o entitách. Tato míra chyb má vážné důsledky pro reprezentaci značky a přesnost obsahu. Když AI systém nesprávně identifikuje entitu, může poskytnout nesprávné informace, přiřadit výroky špatné organizaci nebo nedokázat správně citovat zdroj informací.
| Název entity | Možné významy | Míra záměny AI |
|---|---|---|
| Apple | Technologická společnost / Ovoce / Banka | Vysoká |
| Delta | Letecká společnost / Výrobce baterií / Řecké písmeno | Vysoká |
| Jaguar | Výrobce aut / Druh zvířete | Střední |
| Amazon | E-commerce společnost / Deštný prales / Řeka | Vysoká |
| Orange | Barva / Ovoce / Telekomunikační společnost | Střední |
Důsledky špatné disambiguace entity přesahují prosté věcné chyby. Pro tvůrce obsahu a značky může nesprávná identifikace v AI-generovaných odpovědích znamenat ztrátu viditelnosti, nesprávné přiřazení a poškození pověsti značky. Když se uživatel zeptá AI systému na “Delta”, může mít na mysli Delta Airlines, ale pokud systém zamění tuto entitu s Delta Faucet Company, dostane uživatel nerelevantní informace. Právě proto AmICited.com monitoruje, jak AI systémy rozlišují entity—aby značky věděly, zda jsou ve výstupech AI na různých platformách správně identifikovány a citovány.
Disambiguace entity funguje prostřednictvím systematického procesu, který kombinuje různé NLP techniky k odstranění nejednoznačnosti a správné identifikaci entit. Porozumění tomuto procesu odhaluje, proč některé AI systémy dosahují lepší přesnosti citování než jiné.
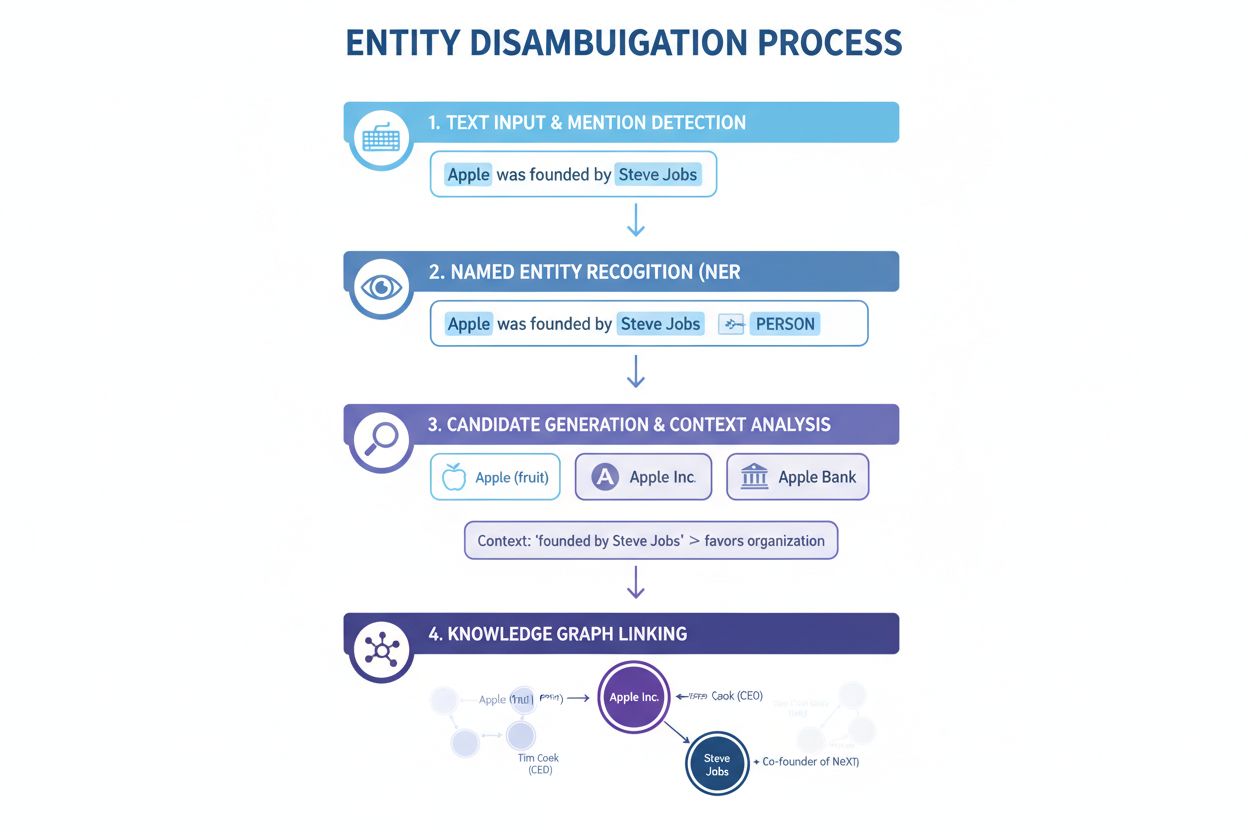
Rozpoznávání pojmenovaných entit (NER): Prvním krokem je identifikace a klasifikace pojmenovaných entit v textu. NER systémy procházejí textová data a vyhledávají zmínky o entitách, přičemž je zařazují do předdefinovaných kategorií, jako je osoba, organizace, místo, produkt nebo datum. Například ve větě “Apple byl výtvorem Stevea Jobse” NER identifikuje “Apple” i “Steve Jobs” jako entity a zařadí je jako organizaci a osobu. Tento základní krok je nezbytný, protože disambiguace nemůže proběhnout bez předchozí identifikace entit v textu.
Kategorizace entity: Jakmile jsou entity identifikovány, musí být přesněji kategorizovány. Nejde jen o širokou klasifikaci, ale i o pochopení konkrétního typu a kontextu každé entity. Systém analyzuje okolní text, aby zjistil, zda se “Apple” vyskytuje v souvislosti s technologiemi (Apple Inc.), jídlem (ovoce), nebo financemi (Apple Bank). Tato kontextová analýza pomáhá zúžit možnosti před samotnou disambiguací.
Disambiguace: Toto je jádro procesu, kde systém určuje, na kterou konkrétní entitu se odkazuje. Systém vyhodnotí více kandidátských entit, které odpovídají zjištěnému jménu, a použije různé signály—včetně kontextu, popisů entit, sémantických vztahů a informací ze znalostních grafů—k výběru nejpravděpodobnější správné entity. U věty “Apple byl výtvorem Stevea Jobse” systém rozpozná, že Steve Jobs je silně spojen s Apple Inc., což z této entity činí správnou volbu.
Propojení se znalostní bází: Posledním krokem je propojení rozlišené entity s unikátním identifikátorem v externí znalostní bázi nebo znalostním grafu, jako je Wikidata, Wikipedia nebo vlastní databáze. Toto propojení potvrzuje identitu entity a obohacuje text o sémantické informace použitelné pro další zpracování a analýzu. Entitě je přiřazen unikátní URI (Uniform Resource Identifier), který slouží jako jednoznačný referenční bod.
V průběhu času se vyvinuly různé přístupy k disambiguaci entity, z nichž každý má své výhody i omezení. Porozumění těmto přístupům vysvětluje, proč se přesnost disambiguace u moderních AI systémů liší.
Pravidlové přístupy: Tyto systémy používají předdefinovaná jazyková pravidla a heuristiky pro disambiguaci entit. Mohou například použít pravidlo “pokud se ‘Apple’ vyskytuje blízko ‘iPhone’ nebo ‘MacBook’, jedná se o Apple Inc.” nebo “pokud se ‘Delta’ vyskytuje u ’letecké společnosti’ nebo ’letu’, jedná se o Delta Airlines.” Pravidlové systémy jsou dobře interpretovatelné a nevyžadují velké trénovací datasety, ale mají potíže s novými kontexty a bez manuální úpravy pravidel se nepřizpůsobí novým významům entit.
Strojové učení: Supervizované modely strojového učení se učí z anotovaných trénovacích dat předpovídat správnou entitu podle kontextových vlastností. Tyto systémy extrahují znaky z okolního textu a používají algoritmy jako Support Vector Machines nebo Random Forests k určení nejpravděpodobnější entity. Strojové učení je pružnější než pravidlové systémy, ale vyžaduje rozsáhlá označená trénovací data a nemusí dobře generalizovat na entity, které během tréninku neviděly.
Hluboké učení a modely založené na transformerech: Moderní disambiguace entity se stále více opírá o architektury jako BERT, RoBERTa nebo specializované modely jako GENRE a BLINK. Tyto modely využívají neuronové sítě k hlubšímu pochopení kontextu, zachycují sémantické vztahy a jemné jazykové vzory. Transformery dosahují špičkových výsledků v benchmarkových testech a lépe zvládají složité scénáře disambiguace. Například systém Ontotext CEEL (Common English Entity Linking) využívá transformerovou architekturu optimalizovanou pro efektivitu na CPU a dosahuje přesnosti rozpoznání entity 96 % a přesnosti propojení entity 76 % na standardních benchmarcích.
Integrace znalostních grafů: Moderní systémy stále častěji kombinují strojové učení se znalostními grafy—strukturovanými databázemi, které reprezentují entity a jejich vztahy. Znalostní grafy poskytují bohatý kontext o entitách, jejich vlastnostech a vztazích s dalšími entitami. Dotazováním znalostních grafů během disambiguace mohou systémy získat metadata, popisy a vztahové informace, které pomáhají přesněji řešit nejednoznačnost.
Disambiguace entity je nezbytná v mnoha odvětvích a aplikacích, která těží z přesné identifikace a citování entit.
Vyhledávače: Google, Bing a další vyhledávače se silně spoléhají na disambiguaci entity, aby poskytly relevantní výsledky. Když uživatel hledá “Apple”, musí vyhledávač určit, zda má na mysli Apple Inc., ovoce nebo jinou entitu tohoto jména. Vyhledávače využívají kontext dotazu, historii uživatele a znalostní grafy k disambiguaci a zobrazují nejrelevantnější výsledky. Proto se při hledání “Apple” zobrazuje jako první technologická společnost—systém se naučil, že jde o nejčastější záměr uživatele.
Média a vydavatelství: Zpravodajské organizace a obsahové platformy využívají disambiguaci entity ke zlepšení dohledatelnosti obsahu a propojení souvisejících článků. Pokud článek zmiňuje “Apple”, systém může automaticky propojit na záznam o Apple Inc. ve znalostní bázi a nabídnout čtenářům další kontext a související články. To zvyšuje zapojení uživatelů a pomáhá pochopit širší kontext zpráv.
Zdravotnictví: Zdravotnická zařízení využívají disambiguaci entity k přesné identifikaci léků, nemocí a lékařských procedur v záznamech pacientů i odborné literatuře. Disambiguace názvů léků je zvlášť kritická—“aspirin” může označovat generický lék, konkrétní značku nebo variantu dávkování. Přesná disambiguace zajišťuje, že zdravotníci mají správné informace a záznamy pacientů jsou správně organizovány.
Finanční služby: Investiční společnosti a finanční analytici využívají disambiguaci entity ke sledování zmínek o firmách v médiích, výkazech a tržních datech. Při analýze tržní expozice je třeba přesně identifikovat všechny zmínky o určité společnosti v různých zdrojích. Disambiguace entity zajistí, aby odkazy na “Apple” byly správně přiřazeny Apple Inc. a ne jiné entitě, což umožňuje přesné hodnocení rizik a analýzu portfolia.
E-commerce: Online prodejci využívají disambiguaci entity ke spárování zmínek o produktech se skutečnými položkami v katalogu. Když zákazník hledá “Apple notebook”, systém musí disambiguovat “Apple” jako společnost a zobrazit odpovídající produkty. To zvyšuje přesnost hledání a pomáhá zákazníkům rychleji najít požadované zboží.
AmICited.com aplikuje principy disambiguace entity ke sledování, jak AI systémy jako ChatGPT, Perplexity a Google AI Přehledy zpracovávají značkové zmínky. Sledováním, zda systémy správně rozlišují značkové entity a přesně je citují, AmICited pomáhá značkám pochopit jejich viditelnost a reprezentaci v AI-generovaném obsahu.
Znalostní grafy se staly základem moderních systémů pro disambiguaci entity, protože poskytují strukturované reprezentace entit a jejich vztahů. Znalostní graf je v podstatě databáze entit (uzly) a vztahů mezi nimi (hrany). Každý uzel entity obsahuje metadata jako název entity, popis, typ a vlastnosti. Například ve znalostním grafu může mít entita “Apple Inc.” vlastnosti jako “založeno 1976”, “sídlo v Cupertinu”, “odvětví: technologie” a vztahy jako “založil Steve Jobs” a “vyrábí iPhone”.
Když systém pro disambiguaci entity narazí na nejednoznačnou zmínku, může dotazovat znalostní graf a získat bohaté kontextové informace o kandidátských entitách. Tyto informace pomáhají systému činit informovanější rozhodnutí při disambiguaci. Například když se systém snaží rozlišit “Apple” a zjistí, že okolní text zmiňuje “Steve Jobs”, může dotazovat znalostní graf a zjistit, že Steve Jobs je silně spojen s Apple Inc., což z této entity činí nejpravděpodobnější volbu. Znalostní grafy jako Wikidata a Wikipedia poskytují veřejně dostupné informace o entitách, které používá mnoho AI systémů při inferenci. Vlastní znalostní grafy společností jako Google, Microsoft a dalších poskytují další doménově specifické informace. Integrace znalostních grafů se strojovým učením významně zlepšila přesnost disambiguace entity, protože systémy nyní dokážou kombinovat naučené vzory se strukturovanými fakty.
Navzdory významnému pokroku čelí systémy pro disambiguaci entity stále několika přetrvávajícím výzvám, které omezují jejich přesnost a použitelnost.
Polysémie a nejednoznačnost: Mnoho názvů entit má více legitimních významů a samotný kontext nemusí stačit k jejich rozlišení. “Bank” může označovat finanční instituci i břeh řeky. “Crane” může být pták nebo stavební stroj. Některé názvy jsou tak nejednoznačné, že s určením správného významu mají problém i lidé bez dalšího kontextu. AI systémy se musí naučit rozpoznat, kdy je kontext nedostatečný, a takové případy řešit vhodně.
Nové a vznikající entity: Znalostní báze a trénovací datasety zastarávají s příchodem nových entit. Když vznikne nová společnost nebo produkt, systémy pro disambiguaci entity o nich nemusí mít informace. Zero-shot entity linking—schopnost rozlišit entity, které nebyly během tréninku viděny—zůstává náročným problémem. Systémy musí rozpoznat, že je entita nová, a naložit s ní správně, nikoliv ji chybně přiřadit k existující podobně pojmenované entitě.
Variace jmen a překlepy: Entity často mají více názvů, zkratek a variant. “United States”, “USA”, “U.S.” a “America” označují stejnou entitu. Překlepy a chyby v psaní dále komplikují disambiguaci. Systémy musí tyto varianty rozpoznat a správně je mapovat na kanonickou entitu, což je zvlášť náročné v uživatelsky generovaném obsahu.
Neúplná nebo zastaralá data: Znalostní báze mohou obsahovat neúplné informace o entitách, nebo se informace může zastarat s vývojem entit. Sídlo firmy se může změnit, vedení může být jiné, nebo může být společnost koupena. Pokud není znalostní báze rychle aktualizována, mohou systémy používat při rozhodování zastaralé informace.
Škálovatelnost a výkon: Zpracování velkých objemů textu s vysokou přesností disambiguace entity vyžaduje značné výpočetní zdroje. Reálná disambiguace pro webové aplikace je výpočetně náročná. Systémy musí balancovat mezi přesností, rychlostí a náklady, což často znamená kompromisy na úkor kvality disambiguace.
Pro značky a tvůrce obsahu je pochopení disambiguace entity zásadní pro zajištění přesné reprezentace v AI-generovaném obsahu. Jak AI systémy stále více ovlivňují, jak je obsah objevován a konzumován, značky musí podnikat proaktivní kroky, aby byly správně rozlišeny a citovány.
Preventivní strategie disambiguace: Značky mohou zavádět strategie, které usnadní AI systémům jejich správnou disambiguaci. To zahrnuje vytváření jasných, odlišitelných digitálních signálů, které pomáhají AI systémům jednoznačně identifikovat značku. Klíčovou strategií je implementace strukturovaných dat pomocí označení Schema.org a formátu JSON-LD na webu značky. Tato strukturovaná data výslovně sdělují AI systémům identitu značky, včetně oficiálního názvu, popisu, loga, sídla a dalších rozlišovacích znaků. Když AI systémy narazí na název značky, mohou tato strukturovaná data použít k potvrzení správné entity.
Optimalizace znalostních grafů: Značky by měly mít silnou prezenci v hlavních znalostních grafech jako Wikidata a Wikipedia. To zahrnuje vytváření a udržování přesných článků na Wikipedii, zajištění úplnosti a aktuálnosti záznamů na Wikidatách a budování vztahů mezi entitou značky a souvisejícími entitami. Čím komplexnější a přesnější je zastoupení značky ve znalostních grafech, tím více informací mají AI systémy k dispozici pro disambiguaci.
Strategie kontextového obsahu: Značky mohou vytvářet obsah, který jasně poskytuje kontext o jejich identitě a odlišuje je od jiných podobně pojmenovaných entit. Obsah, který výslovně zmiňuje odvětví značky, produkty, zakladatele a jedinečný přínos, pomáhá AI systémům chápat charakteristiky značky. Tento kontext se stává součástí trénovacích dat a kontextu, který AI systémy využívají při disambiguaci.
Sledování citací: Nástroje jako AmICited.com umožňují značkám sledovat, jak AI systémy rozlišují a citují jejich značku napříč různými platformami. Sledováním, zda ChatGPT, Perplexity, Google AI Přehledy a další systémy správně identifikují značku, mohou značky odhalit chyby v disambiguaci a přijmout nápravná opatření. Toto sledování je zásadní pro pochopení viditelnosti značky v době generativní AI.
Optimalizace pro generativní AI (GEO): S rostoucí důležitostí disambiguace entity pro viditelnost v AI by měly značky zařadit optimalizaci entity do své širší strategie Generative Engine Optimization. To zahrnuje zajištění, aby entita značky byla jasně definovaná, dobře zdokumentovaná a snadno odlišitelná od konkurence. GEO zahrnuje nejen tradiční SEO, ale i optimalizaci pro to, jak AI systémy značky chápou a prezentují.
Disambiguace entity se neustále vyvíjí s rozvojem AI technologií a novými výzvami. Několik trendů utváří budoucnost této klíčové schopnosti.
Vícejazyčná disambiguace entity: Jak se AI systémy stávají globálními, je stále důležitější schopnost rozlišovat entity napříč jazyky. Jméno osoby může mít v různých jazycích různé podoby a stejná entita může být v různých jazykových kontextech označována odlišně. Vyvíjejí se pokročilé vícejazyčné modely, které umožní disambiguaci napříč jazyky a zajistí skutečně globální AI systémy.
Reálná disambiguace v rámci velkých jazykových modelů: Moderní velké jazykové modely jako GPT-4 a Claude stále více začleňují disambiguaci entity v reálném čase během generování textu. Nejsou tak závislé pouze na trénovacích datech, ale mohou během inference dotazovat znalostní grafy a externí databáze, aby ověřily informace o entitách a zajistily přesnou disambiguaci. Tím se zvyšuje přesnost citací a snižují halucinace.
Lepší zero-shot učení: Budoucí systémy pro disambiguaci entity pravděpodobně dosáhnou lepších výsledků při práci s entitami, které během tréninku neviděly. Pokroky ve few-shot a zero-shot learningu umožní systémům disambiguovat nové entity efektivněji, čímž se sníží potřeba častého přeškolování a zvýší se adaptabilita na nové entity.
Integrace s Retrieval-Augmented Generation (RAG): Systémy, které kombinují jazykové modely s vyhledáváním informací, jsou stále populárnější. Tyto systémy mohou během generování textu načítat relevantní informace o entitách ze znalostních bází, což zlepšuje přesnost disambiguace a citování. Tato integrace je významným krokem vpřed směrem k přesnému citování zdrojů AI systémy.
Standardizace a interoperabilita: S rostoucím významem disambiguace entity pro AI systémy pravděpodobně vzniknou průmyslové standardy pro reprezentaci a rozlišování entit. Tyto standardy umožní lepší interoperabilitu mezi různými systémy a znalostními bázemi a usnadní AI systémům jednotný přístup k informacím o entitách napříč platformami.
Disambiguace entity se vyvinula z okrajové NLP úlohy v klíčovou schopnost, která zajišťuje správné porozumění a prezentaci informací v AI systémech. S tím, jak AI stále více ovlivňuje, jak je obsah objevován a chápán, bude význam přesné disambiguace entity jen narůstat. Pro značky, tvůrce obsahu i organizace je pochopení a optimalizace pro disambiguaci entity zásadní pro udržení viditelnosti a správné reprezentace v éře generativní AI.
Rozpoznávání pojmenovaných entit identifikuje, že se v textu vyskytuje entita, a zařazuje ji do kategorií jako osoba, organizace nebo místo. Disambiguace entity jde dál a určí, na kterou konkrétní entitu se odkazuje, když více entit sdílí stejné jméno. Například NER identifikuje 'Apple' jako organizaci, zatímco disambiguace entity určí, zda se jedná o Apple Inc., Apple Bank nebo jinou entitu.
Disambiguace entity zajišťuje, že AI systémy přesně chápou, o které entitě je řeč, a správně ji citují. Podle Stanford AI Index 2024 obsahuje více než 18 % výstupů LLM týkajících se značkových entit halucinace nebo chybné přiřazení. Přesná disambiguace entity zabraňuje tomu, aby AI systémy zaměnily jednu entitu za jinou, což je klíčové pro udržení pověsti značky a správné citování.
Znalostní grafy poskytují strukturované informace o entitách a jejich vztazích. Když AI systém narazí na nejednoznačnou zmínku o entitě, může dotazovat znalostní graf a získat metadata, popisy a informace o vztazích kandidátských entit. Tyto kontextové informace pomáhají systému činit informovanější rozhodnutí při disambiguaci a vybrat správnou entitu.
Ano, díky přístupům zero-shot entity linking. Moderní systémy dokáží rozpoznat, kdy je entita nová, a podle toho s ní naložit, místo aby ji nesprávně přiřadily k existující entitě. Přesto zůstává tento problém náročný a systémy dosahují lepších výsledků, pokud mají nové entity jasné kontextové signály, které je odlišují od existujících entit.
Přesná disambiguace entity zajišťuje, že vaše značka je ve výstupech AI správně identifikována a citována. Když AI systémy správně rozliší vaši značku, uživatelé dostávají přesné informace o vaší organizaci, což zlepšuje viditelnost a pověst značky. Špatná disambiguace může vést k záměně vaší značky s konkurencí nebo jinými entitami, což snižuje viditelnost a může poškodit pověst.
Klíčové výzvy zahrnují polysémii (více významů pro stejné jméno), nové entity mimo trénovací data, variace jmen a překlepy, neúplné nebo zastaralé znalostní báze a problémy se škálovatelností. Některá jména entit jsou navíc ze své podstaty nejednoznačná a samotný kontext nemusí stačit k určení správné entity.
Značky mohou implementovat strukturovaná data pomocí značkování Schema.org, udržovat přesné záznamy na Wikipedii a Wikidatách, vytvářet kontextový obsah, který jasně odlišuje jejich značku, a sledovat, jak AI systémy rozlišují jejich značku pomocí nástrojů jako AmICited. Tyto strategie pomáhají AI systémům správně identifikovat a citovat vaši značku.
Kontext je pro disambiguaci entity klíčový. Okolní text, související entity a sémantické vztahy poskytují signály, které pomáhají AI systémům určit, na kterou entitu se odkazuje. Například pokud se 'Apple' vyskytuje poblíž 'Steve Jobs' a 'technologie', systém může tento kontext využít k tomu, aby ji správně rozlišil jako Apple Inc., nikoliv ovoce.
Sledujte přesnost disambiguace entity napříč AI platformami a zajistěte, že vaše značka je ve výstupech AI správně identifikována a citována.
Zjistěte, jak vybudovat a optimalizovat entitu své značky pro rozpoznání umělou inteligencí. Implementujte schema markup, propojování entit a strukturovaná data...

Zjistěte, jak posílit entitu své značky pro viditelnost ve vyhledávání AI. Optimalizujte pro ChatGPT, Perplexity, Google AI Overviews a Claude pomocí strategií ...

Rozpoznávání entit je schopnost AI NLP identifikující a kategorizující pojmenované entity v textu. Zjistěte, jak funguje, jeho využití v AI monitoringu a jeho r...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.