Co je znalostní graf a proč na něm záleží? | AI Monitoring FAQ
Objevte, co jsou znalostní grafy, jak fungují a proč jsou nezbytné pro moderní správu dat, AI aplikace a business intelligence.
8 min čtení
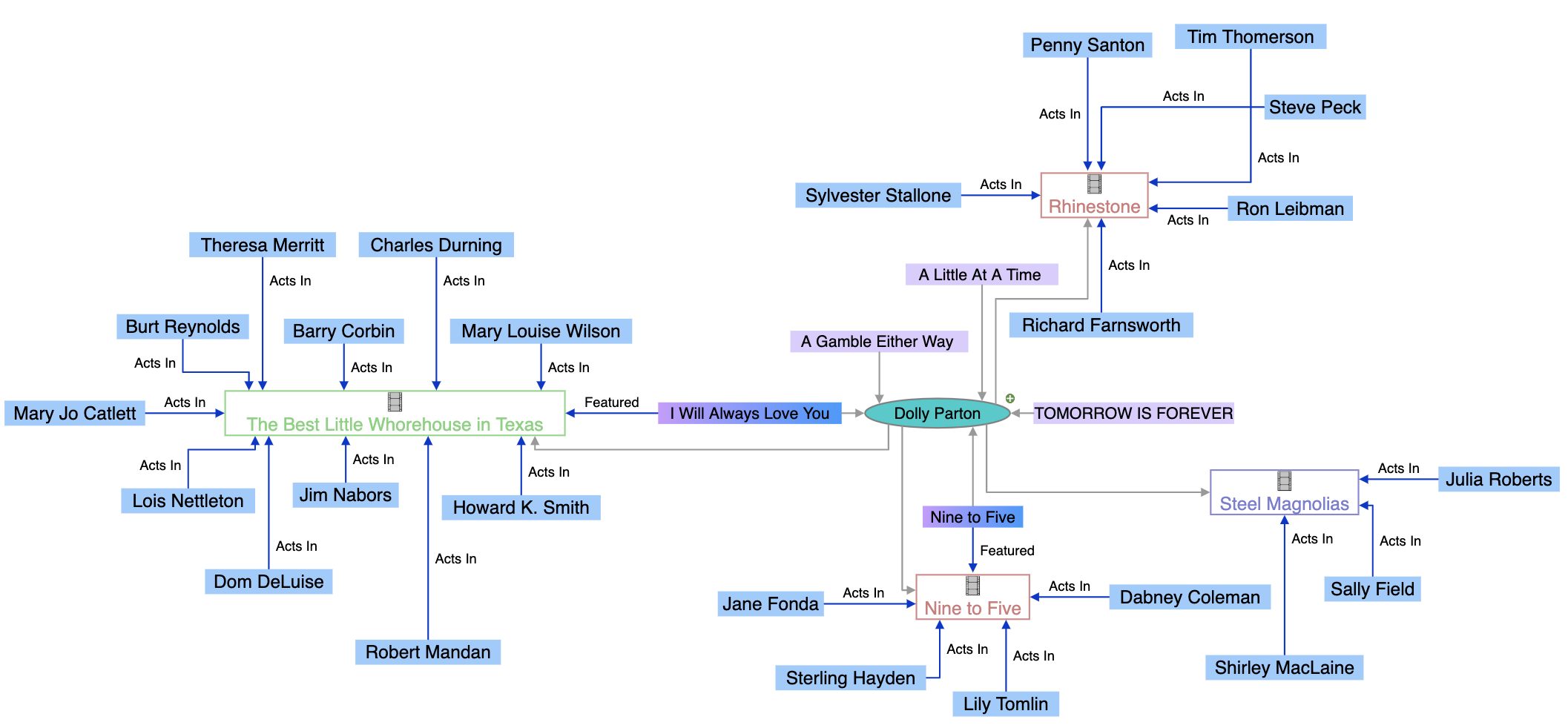
Knowledge graph je databáze propojených informací, která reprezentuje reálné entity – například lidi, místa, organizace a koncepty – a znázorňuje sémantické vztahy mezi nimi. Vyhledávače jako Google používají knowledge graphy k pochopení záměru uživatele, doručování relevantnějších výsledků a pohánění AI funkcí jako jsou knowledge panely a AI Přehledy.
Knowledge graph je databáze propojených informací, která reprezentuje reálné entity – například lidi, místa, organizace a koncepty – a znázorňuje sémantické vztahy mezi nimi. Vyhledávače jako Google používají knowledge graphy k pochopení záměru uživatele, doručování relevantnějších výsledků a pohánění AI funkcí jako jsou knowledge panely a AI Přehledy.
Knowledge graph je databáze propojených informací, která reprezentuje reálné entity – například lidi, místa, organizace a koncepty – a znázorňuje sémantické vztahy mezi nimi. Na rozdíl od tradičních databází, které organizují informace v pevných tabulkových formátech, knowledge graphy strukturovaně ukládají data jako sítě uzlů (entit) a hran (vztahů), což systémům umožňuje chápat význam a kontext namísto prostého párování klíčových slov. Google Knowledge Graph, spuštěný v roce 2012, způsobil revoluci ve vyhledávání tím, že zavedl porozumění na bázi entit, což umožnilo vyhledávači odpovědět na faktické otázky jako „Jak vysoká je Eiffelova věž?“ nebo „Kde se konaly Letní olympijské hry 2016?“ tím, že pochopí, co uživatel skutečně hledá, a ne jen slova, která použil. K květnu 2024 obsahuje Google Knowledge Graph přes 1,6 bilionu faktů o 54 miliardách entit, což představuje obrovské rozšíření oproti 500 miliardám faktů o 5 miliardách entit v roce 2020. Tento růst odráží rostoucí význam strukturovaných, sémantických znalostí pro pohánění moderního vyhledávání, AI systémů a inteligentních aplikací napříč odvětvími.
Koncept knowledge graphů vznikl z desítek let výzkumu v oblasti umělé inteligence, technologií sémantického webu a reprezentace znalostí. Širokého uznání však pojem nabyl až v okamžiku, kdy Google v roce 2012 představil svůj Knowledge Graph, což zásadně změnilo způsob, jakým vyhledávače doručují výsledky. Před zavedením Knowledge Graphu vyhledávače převážně používaly párování klíčových slov – pokud jste hledali „tuleň“, Google zobrazil výsledky pro všechna možná významová použití slova, aniž by chápal, o jakou entitu vám skutečně šlo. Knowledge Graph tuto paradigmu změnil aplikací principů ontologie – formálního rámce pro definici entit, jejich atributů a vztahů – v masovém měřítku. Tento posun od „řetězců ke věcem“ představoval zásadní pokrok ve vyhledávacích technologiích, protože algoritmy začaly chápat, že „tuleň“ může znamenat mořského savce, zpěváka, vojenskou jednotku nebo bezpečnostní pečeť, a určovat nejrelevantnější význam podle kontextu. Význam knowledge graphů potvrzuje i jejich globální trh, jehož růst se odhaduje z 1,49 miliardy dolarů v roce 2024 na 6,94 miliardy do roku 2030, což odpovídá složené roční míře růstu přibližně 35 %. Tento explozivní růst pohání adopce ve firmách napříč financemi, zdravotnictvím, maloobchodem i logistikou, kde si organizace stále více uvědomují, že pochopení vztahů mezi entitami je zásadní pro rozhodování, detekci podvodů i efektivitu provozu.
Knowledge graphy fungují díky sofistikované kombinaci datových struktur, sémantických technologií a algoritmů strojového učení. Jejich základ tvoří grafově strukturovaný datový model sestávající ze tří klíčových komponent: uzly (reprezentují entity jako lidé, organizace či koncepty), hrany (reprezentují vztahy mezi entitami) a popisky (popisují povahu těchto vztahů). Například v jednoduchém knowledge graphu může být „Seal“ uzlem, „je“ popiskem hrany a „zpěvák“ dalším uzlem, což vytváří sémantický vztah „Seal je zpěvák“. Tato struktura se zásadně liší od relačních databází, které nutí data do řádků a sloupců s předdefinovanými schématy. Knowledge graphy jsou stavěny buď jako labeled property graphs (kde vlastnosti ukládáte přímo na uzlech a hranách), nebo jako RDF (Resource Description Framework) triple store (kde jsou všechny informace reprezentovány jako trojice subjekt-predicate-objekt). Síla knowledge graphů spočívá v jejich schopnosti integrovat data z různých zdrojů a s různou strukturou. Při načítání dat do knowledge graphu používají procesy sémantického obohacení metody zpracování přirozeného jazyka (NLP) a strojového učení k identifikaci entit, extrakci vztahů a pochopení kontextu. Díky tomu knowledge graphy automaticky rozpoznají, že „IBM“, „International Business Machines“ i „Big Blue“ označují stejnou entitu, a porozumí, jak tato entita souvisí s dalšími jako „Watson“, „cloud computing“ nebo „umělá inteligence“. Výsledná propojená struktura umožňuje pokročilé dotazy a odvozování, které v tradičních databázích nejsou možné, takže systémy dokážou odpovídat na složité otázky prostupováním vztahů a vyvozováním nových znalostí z existujících propojení.
| Aspekt | Knowledge Graph | Tradiční relační databáze | Grafová databáze |
|---|---|---|---|
| Datová struktura | Uzly, hrany a popisky reprezentující entity a vztahy | Tabulky, řádky a sloupce s předdefinovaným schématem | Uzly a hrany optimalizované pro procházení vztahů |
| Flexibilita schématu | Vysoce flexibilní, vyvíjí se s novými informacemi | Rigidní, vyžaduje schéma před zadáním dat | Flexibilní, podporuje dynamický vývoj schématu |
| Zpracování vztahů | Nativní podpora složitých, vícekrokových vztahů | Vyžaduje spojování více tabulek, výpočetně náročné | Optimalizováno pro efektivní dotazy na vztahy |
| Dotazovací jazyk | SPARQL (pro RDF), Cypher (pro property graphy), nebo vlastní API | SQL | Cypher, Gremlin, nebo SPARQL |
| Sémantické porozumění | Důraz na význam a kontext skrze ontologie | Zaměření na ukládání a získávání dat | Zaměření na efektivní procházení a hledání vzorů |
| Využití | Sémantické vyhledávání, objevování znalostí, AI systémy, rozlišení entit | Firemní transakce, reporting, OLTP systémy | Doporučovací systémy, detekce podvodů, analýza sítí |
| Integrace dat | Vyniká v integraci heterogenních dat z více zdrojů | Vyžaduje rozsáhlé ETL a transformaci dat | Dobré pro propojená data, méně důraz na sémantiku |
| Škálovatelnost | Škáluje na miliardy entit a biliony faktů | Dobře škáluje pro strukturovaná transakční data | Dobře škáluje pro dotazy zaměřené na vztahy |
| Inferenční schopnosti | Pokročilé odvozování a získávání znalostí přes ontologie | Omezené, vyžaduje explicitní programování | Omezené, zaměřuje se na hledání vzorů |
Knowledge graphy jsou v současnosti středobodem moderních SEO a AI strategií, protože zásadně ovlivňují, jak se informace zobrazují ve výsledcích vyhledávání i v AI generovaných odpovědích. Když Google zpracovává dotaz, jedním z hlavních úkolů je identifikovat entitu, kterou uživatel hledá, a poté získat relevantní informace z Knowledge Graphu pro naplnění funkcí na stránce výsledků. Tento přístup založený na entitách vedl ke vzniku sémantického vyhledávání – schopnosti Google chápat význam a kontext dotazů, nikoliv jen párovat klíčová slova. Knowledge Graph pohání několik viditelných funkcí SERP, které přímo ovlivňují míru prokliku i viditelnost značky. Knowledge panely se zobrazují prominentně na desktopu i mobilu a prezentují kurátorská fakta o hledané entitě pocházející z Knowledge Graphu. AI Přehledy (dříve Search Generative Experience) syntetizují informace z více zdrojů identifikovaných přes knowledge graphové vztahy a poskytují komplexní odpovědi, které často posunují tradiční organické výsledky níže na stránce. People Also Ask boxy využívají vztahy mezi entitami k návrhu souvisejících dotazů a témat. Pochopení těchto funkcí je zásadní pro značky, protože představují nejcennější prostor ve výsledcích vyhledávání, často výše než organické výsledky. Pro firmy monitorující svou přítomnost v AI systémech jako jsou Perplexity, ChatGPT, Claude a Google AI Přehledy, je optimalizace knowledge graphu klíčová. Tyto AI systémy se stále více spoléhají na strukturované informace o entitách a sémantické vztahy pro generování přesných a kontextových odpovědí. Značka, která správně optimalizovala svou entitní přítomnost v knowledge graphech – implementací strukturovaných dat, nárokováním knowledge panelu a konzistentními informacemi napříč zdroji – se mnohem častěji objeví v AI generovaných odpovědích na relevantní témata. Naopak značky s nekompletními nebo nekonzistentními informacemi mohou být v AI systémech opomenuty nebo špatně zobrazeny, což přímo ovlivňuje jejich viditelnost a reputaci.
Google Knowledge Graph čerpá z různorodého ekosystému datových zdrojů, přičemž každý přináší odlišné typy informací a slouží jinému účelu. Otevřená data a komunitní projekty jako Wikipedia a Wikidata tvoří základ mnoha obsahů v Knowledge Graphu. Wikipedia poskytuje narativní popisy a souhrnné informace, které se často vyskytují v knowledge panelech, zatímco Wikidata – strukturovaná znalostní báze podporující Wikipedii – poskytuje strojově čitelná data o entitách a jejich vztazích. Google dříve používal Freebase, vlastní komunitně editovanou databázi, ale po jejím uzavření v roce 2016 přešel na Wikidata. Vládní datové zdroje přispívají autoritativními informacemi, zejména pro faktografické dotazy. CIA World Factbook poskytuje informace o státech, geografických oblastech a organizacích. Data Commons, veřejný projekt Google, agreguje data z vládních a mezinárodních organizací jako OSN a Evropská unie a poskytuje statistiky i demografické informace. Údaje o počasí a kvalitě ovzduší pocházejí z národních a mezinárodních meteorologických agentur a umožňují například funkce „nowcast“ počasí. Licencovaná privátní data doplňují Knowledge Graph informacemi, které se rychle mění nebo vyžadují specializované znalosti. Google licencuje finanční data od poskytovatelů jako Morningstar, S&P Global nebo Intercontinental Exchange pro informace o cenách akcií a trzích. Sportovní data pocházejí z partnerství s ligami, týmy a agregátory jako Stats Perform, které poskytují aktuální skóre i historické statistiky. Strukturovaná data z webových stránek významně přispívají k obohacení Knowledge Graphu. Pokud weby implementují označení Schema.org, poskytují Googlu explicitní sémantické informace, které může extrahovat a zařadit. Proto je správná implementace strukturovaných dat – Organization, LocalBusiness, FAQPage a další relevantní schémata – zásadní pro značky, které chtějí ovlivnit své zastoupení v Knowledge Graphu. Data z Google Books z více než 40 milionů naskenovaných a digitalizovaných knih poskytují historický kontext, biografické informace a detailní popisy pro rozšíření znalostí o entitách. Uživatelská zpětná vazba a nárokované knowledge panely umožňují jednotlivcům i organizacím přímo ovlivnit informace v Knowledge Graphu. Když uživatelé odešlou zpětnou vazbu k knowledge panelům nebo když oprávnění zástupci nárokují a aktualizují panely, tyto informace jsou zpracovány a mohou vést k aktualizaci Knowledge Graphu. Tento přístup s lidským prvkem zajišťuje, že Knowledge Graph zůstává přesný a reprezentativní, ačkoliv finální rozhodnutí o zobrazovaných informacích činí automatizované systémy Google.
Google explicitně uvádí, že při tvorbě a aktualizaci Knowledge Graphu upřednostňuje informace ze zdrojů vykazujících vysokou E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness – zkušenost, odbornost, autorita a důvěryhodnost). Toto spojení mezi E-E-A-T a zařazením do Knowledge Graphu není náhodné – odráží širší závazek Google upřednostňovat spolehlivé, autoritativní informace. Pokud je obsah vašeho webu vybírán do funkcí SERP poháněných Knowledge Graphem, je to často silný signál, že Google váš web považuje za autoritativní v daném tématu. Naopak pokud se váš obsah v těchto funkcích neobjevuje, může to znamenat problémy s E-E-A-T, které je třeba řešit. Budování E-E-A-T pro viditelnost v Knowledge Graphu vyžaduje vícevrstvý přístup. Zkušenost znamená prokázat, že vy nebo vaši autoři máte reálné zkušenosti s daným tématem. U zdravotnického webu může jít o obsah od licencovaných lékařů s letitou praxí; u technologické firmy o prezentaci odbornosti inženýrů a výzkumníků, kteří dané produkty vytvářeli. Odbornost spočívá ve vytváření hluboce znalostního obsahu, který pokrývá témata komplexně a přesně. Jde o víc než povrchní popisy – je třeba prokázat skutečné porozumění nuancím, okrajovým případům i pokročilým konceptům. Autorita vyžaduje vybudovat uznání v oboru, například díky oceněním, certifikacím, zmínkám v médiích, přednáškám nebo citacím od jiných autorit. U organizací to znamená etablovat vaši značku jako lídra v odvětví. Důvěryhodnost staví na předchozích třech prvcích a projevuje se transparentností, přesností, správným citováním, jasným autorstvím a vstřícným zákaznickým servisem. Organizace, které vynikají v E-E-A-T signálech, mají větší šanci na zařazení informací do Knowledge Graphu a na výskyt v AI odpovědích, což vytváří pozitivní cyklus, kdy autorita vede k viditelnosti, která dále posiluje autoritu.
Vzrůstající význam velkých jazykových modelů (LLM) a generativní AI přináší knowledge graphům v AI ekosystému novou roli. Ačkoliv LLM jako ChatGPT, Claude nebo Perplexity nejsou přímo trénovány na proprietárním Knowledge Graphu Google, stále více se opírají o podobně strukturované znalosti a sémantické porozumění. Mnoho AI systémů využívá přístup retrieval-augmented generation (RAG), kdy model při generování odpovědi dotazuje knowledge graphy nebo strukturované databáze, aby odpovědi ukotvil ve faktech a snížil halucinace. Veřejně dostupné knowledge graphy jako Wikidata se využívají k dolaďování modelů nebo vkládání strukturovaných znalostí, což zlepšuje schopnost AI chápat vztahy mezi entitami a poskytovat přesné informace. Pro značky a organizace to znamená, že optimalizace knowledge graphu má dopad i mimo tradiční Google Search. Když uživatel položí AI systému dotaz na váš obor, produkt či organizaci, schopnost systému podat přesné informace závisí mimo jiné na tom, jak je vaše entita zastoupena ve strukturovaných znalostních zdrojích. Organizace s dobře udržovaným záznamem ve Wikidata, nárokovaným Google knowledge panelem a konzistentními strukturovanými daty na webu má mnohem větší šanci na přesné zobrazení v AI generovaných odpovědích. Naopak organizace s neúplnými či rozpornými údaji mohou být v AI odpovědích opomenuty nebo zkresleny. To vytváří novou dimenzi monitoringu AI viditelnosti – sledování nejen, jak se vaše značka zobrazuje v klasických výsledcích vyhledávání, ale i jak je reprezentována v AI odpovědích napříč platformami. Nástroje a platformy pro monitoring značky v AI systémech se stále více zaměřují na pochopení vztahů mezi entitami a znalostní reprezentace v knowledge graphech, protože tyto faktory přímo ovlivňují AI viditelnost.
Organizace, které chtějí optimalizovat svou přítomnost v knowledge graphech, by měly postupovat systematicky, vycházet ze SEO základů a přidat strategie zaměřené na entity. Prvním krokem je implementace strukturovaného označení dat pomocí slovníku Schema.org. To znamená přidat na web JSON-LD, Microdata nebo RDFa značky, které explicitně popisují vaši organizaci, produkty, osoby a další relevantní entity. Klíčové typy schémat zahrnují Organization (pro informace o firmě), LocalBusiness (pro lokální informace), Person (pro profily osob), Product (pro informace o produktech) a FAQPage (pro často kladené otázky). Po implementaci schématu je zásadní otestovat a validovat označení pomocí Google Structured Data Testing Tool, abyste ověřili správnost a rozpoznání. Druhým krokem je audit a optimalizace informací ve Wikidata a Wikipedii. Pokud má vaše organizace nebo klíčové entity stránky na Wikipedii, ujistěte se, že jsou přesné, komplexní a správně zdrojované. U Wikidata ověřte existenci vaší entity a správnost jejích vlastností a vztahů. Editace Wikipedie nebo Wikidata však vyžaduje pečlivé dodržování jejich zásad – přímá sebeprezentace nebo skryté střety zájmů mohou vést ke zrušení úprav a poškození pověsti. Třetím krokem je nárokování a optimalizace Google Business Profile (pro lokální firmy) a knowledge panelů (pro osoby a organizace). Nárokovaný knowledge panel vám dává větší kontrolu nad zobrazením vaší entity ve vyhledávání a umožňuje rychlejší navrhování úprav. Čtvrtým krokem je zajištění konzistence napříč všemi kanály – web, Google Business Profile, sociální sítě i třetí strany. Rozpory mezi zdroji matou systémy Google a brání přesné reprezentaci v Knowledge Graphu. Pátým krokem je tvorba obsahu zaměřeného na entity místo tradičního obsahu zaměřeného na klíčová slova. Místo psaní článků na „nejlepší CRM software“, „funkce Salesforce“ a „ceny HubSpotu“ vytvořte komplexní obsahový klastr, který jasně vymezuje vztahy mezi entitami: Salesforce je CRM platforma, konkuruje HubSpotu, integruje se se Slackem apod. Tento přístup pomáhá knowledge graphům lépe chápat sémantický význam a vztahy vašeho obsahu.
Knowledge graphy se rychle vyvíjejí v reakci na pokroky v umělé inteligenci, změny ve vyhledávacím chování i vznik nových platforem a technologií. Jedním z významných trendů je rozvoj multimodálních knowledge graphů, které integrují textová, obrazová, zvuková a video data. S rostoucím významem hlasového a vizuálního vyhledávání se knowledge graphy přizpůsobují tak, aby chápaly a reprezentovaly informace napříč různými modalitami. Práce Google na multimodálním vyhledávání s produkty jako Google Lens tento vývoj ilustruje – systém musí rozumět nejen textovým dotazům, ale i vizuálním vstupům, což vyžaduje knowledge graphy schopné reprezentovat a propojovat informace napříč médii. Dalším důležitým vývojem je rostoucí sofistikovanost sémantického obohacení a zpracování přirozeného jazyka při tvorbě knowledge graphů. S tím, jak NLP schopnosti rostou, knowledge graphy dokážou extrahovat jemnější sémantické vztahy z nestrukturovaných textů a snižovat závislost na ručně kurátorovaných či explicitně označených datech. To znamená, že organizace s kvalitním, dobře napsaným obsahem mohou být do knowledge graphů zařazeny i bez explicitního strukturovaného označení, ačkoliv markup zůstává důležitý pro zajištění přesné reprezentace. Integrace knowledge graphů s velkými jazykovými modely a generativní AI představuje možná nejvýznamnější evoluci. Jak se AI systémy stávají hlavním způsobem získávání informací, důležitost optimalizace pro knowledge graphy přesahuje tradiční vyhledávání a zahrnuje i AI viditelnost napříč platformami. Organizace, které knowledge graphům rozumí a optimalizují pro
Tradiční databáze ukládá data v pevných, tabulkových formátech s předdefinovanými schématy, zatímco knowledge graph organizuje informace jako propojené uzly a hrany, které reprezentují entity a jejich sémantické vztahy. Knowledge graphy jsou flexibilnější, samopopisné a lépe se hodí pro pochopení složitých vztahů mezi různými typy dat. Umožňují systémům chápat význam a kontext, nejen shodu klíčových slov, což je činí ideálními pro AI a sémantické vyhledávání.
Google využívá svůj Knowledge Graph k pohánění více funkcí SERP včetně knowledge panelů, AI Přehledů, boxů Lidé se také ptají a návrhů souvisejících entit. K květnu 2024 obsahuje Google Knowledge Graph více než 1,6 bilionu faktů o 54 miliardách entit. Když uživatel hledá, Google identifikuje entitu, kterou hledá, a zobrazí relevantní propojené informace z Knowledge Graphu, což uživatelům pomáhá najít 'věci, ne řetězce', jak to Google popisuje.
Knowledge graphy agregují data z více zdrojů včetně open-source projektů jako Wikipedia a Wikidata, vládních databází jako CIA World Factbook, licencovaných soukromých dat pro finanční a sportovní informace, strukturovaného označení dat z webů pomocí Schema.org, dat Google Books a uživatelské zpětné vazby prostřednictvím oprav knowledge panelů. Tento multi-zdrojový přístup zajišťuje komplexní a přesné informace o entitách napříč miliardami faktů.
Knowledge graphy přímo ovlivňují, jak se značky zobrazují ve výsledcích vyhledávání a AI systémech tím, že vytvářejí vztahy a propojení entit. Značky, které optimalizují svou prezenci v knowledge graphech pomocí strukturovaných dat, nárokovaných knowledge panelů a konzistentních informací napříč zdroji, získávají lepší viditelnost v AI generovaných odpovědích. Pochopení vztahů v knowledge graphech pomáhá značkám monitorovat svou přítomnost v AI systémech jako ChatGPT, Perplexity a Claude, které se stále více spoléhají na strukturované informace o entitách.
Sémantické obohacení je proces, při kterém algoritmy strojového učení a zpracování přirozeného jazyka (NLP) analyzují data za účelem identifikace jednotlivých objektů a pochopení vztahů mezi nimi. Tento proces umožňuje knowledge graphům jít nad rámec jednoduchého párování klíčových slov a chápat význam i kontext. Při načítání dat sémantické obohacení automaticky rozpoznává entity, jejich atributy a vztahy k dalším entitám, což umožňuje inteligentnější vyhledávání a odpovídání na dotazy.
Organizace mohou optimalizovat pro knowledge graphy implementací strukturovaného označení dat pomocí Schema.org, udržováním konzistentních informací napříč všemi kanály (web, Google Business Profile, sociální sítě), nárokováním a aktualizací knowledge panelů, budováním silných E-E-A-T signálů skrze autoritativní obsah a zajištěním přesnosti dat napříč zdroji. Vytváření obsahových klastrů zaměřených na entity místo tradičních klíčových slov také pomáhá posilovat vztahy, které knowledge graphy rozpoznávají a využívají.
Knowledge graphy poskytují sémantický základ pro AI Přehledy tím, že pomáhají AI systémům chápat vztahy a kontext entit. Při generování souhrnů vyhledávání AI systémy využívají data z knowledge graphů k identifikaci relevantních entit, pochopení jejich propojení a syntéze informací z více zdrojů. To umožňuje přesnější, kontextové odpovědi, které jdou nad rámec jednoduchého párování klíčových slov, což činí knowledge graphy klíčovou infrastrukturou pro moderní generativní vyhledávání.
Knowledge graph je návrhový vzor a sémantická vrstva, která definuje, jak jsou entity a vztahy modelovány a chápány, zatímco grafová databáze je technologická infrastruktura pro ukládání a dotazování těchto dat. Knowledge graphy se zaměřují na význam a sémantické vztahy, grafové databáze na efektivní ukládání a vyhledávání. Knowledge graph lze realizovat pomocí různých grafových databází jako Neo4j, Amazon Neptune nebo RDF triple store, ale samotný knowledge graph je konceptuální model.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Objevte, co jsou znalostní grafy, jak fungují a proč jsou nezbytné pro moderní správu dat, AI aplikace a business intelligence.
Diskuze komunity vysvětlující Knowledge Graphy a jejich význam pro viditelnost ve vyhledávání s umělou inteligencí. Odborníci sdílejí, jak entity a jejich vztah...
Zjistěte, co jsou grafy, jaké existují typy a jak proměňují surová data v užitečné poznatky. Zásadní průvodce formáty vizualizace dat pro analytiku a reporting....
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.