
Multimodální AI vyhledávání: Optimalizace pro obrazové a hlasové dotazy
Ovládněte optimalizaci multimodálního AI vyhledávání. Naučte se, jak optimalizovat obrázky a hlasové dotazy pro výsledky vyhledávání poháněné AI, včetně strateg...
8 min čtení

AI systémy, které současně zpracovávají a odpovídají na dotazy zahrnující text, obrázky, zvuk a video, což umožňuje komplexnější porozumění a kontextově citlivé odpovědi napříč různými typy dat.
AI systémy, které současně zpracovávají a odpovídají na dotazy zahrnující text, obrázky, zvuk a video, což umožňuje komplexnější porozumění a kontextově citlivé odpovědi napříč různými typy dat.
Multimodální AI vyhledávání označuje systémy umělé inteligence, které současně zpracovávají a integrují informace z více typů dat neboli modalit—jako je text, obrázky, zvuk a video—aby poskytly komplexnější a kontextově relevantní výsledky. Na rozdíl od unimodální AI, která spoléhá na jeden typ vstupu (například pouze textové vyhledávače), multimodální systémy využívají komplementární silné stránky různých datových formátů k dosažení hlubšího porozumění a přesnějších výsledků. Tento přístup napodobuje lidské poznávání, kdy přirozeně kombinujeme vizuální, sluchové a textové informace, abychom pochopili své okolí. Zpracováním různorodých vstupních typů společně dokážou multimodální AI vyhledávací systémy zachytit nuance a vztahy, které by byly pro přístupy s jedinou modalitou neviditelné.
Multimodální AI vyhledávání funguje prostřednictvím sofistikovaných fúzních technik, které kombinují informace z různých modalit v různých fázích zpracování. Systém nejprve extrahuje příznaky z každé modality nezávisle a poté tyto reprezentace strategicky spojuje za účelem vytvoření sjednoceného porozumění. Načasování a metoda fúze mají významný dopad na výkon, jak ukazuje následující srovnání:
| Typ fúze | Kdy se aplikuje | Výhody | Nevýhody |
|---|---|---|---|
| Raná fúze | Ve vstupní fázi | Zachycuje nízkoúrovňové korelace | Méně robustní při nevyrovnaných datech |
| Střední fúze | Ve fázi předzpracování | Vyvážený přístup | Složitější |
| Pozdní fúze | Na úrovni výstupu | Modulární design | Méně soudržný kontext |
Raná fúze kombinuje surová data okamžitě, čímž zachycuje jemné interakce, ale má potíže s nevyrovnanými vstupy. Střední fúze aplikuje spojení během zpracování, nabízí kompromis mezi složitostí a výkonem. Pozdní fúze funguje na výstupní úrovni, umožňuje nezávislé zpracování modalit, ale může přijít o důležitý mezimodální kontext. Volba strategie fúze závisí na konkrétních požadavcích aplikace a povaze zpracovávaných dat.
Několik klíčových technologií pohání moderní multimodální AI vyhledávací systémy a umožňuje jim efektivně zpracovávat a integrovat různé typy dat:
Tyto technologie synergicky spolupracují na vytváření systémů schopných porozumět složitým vztahům mezi různými typy informací.
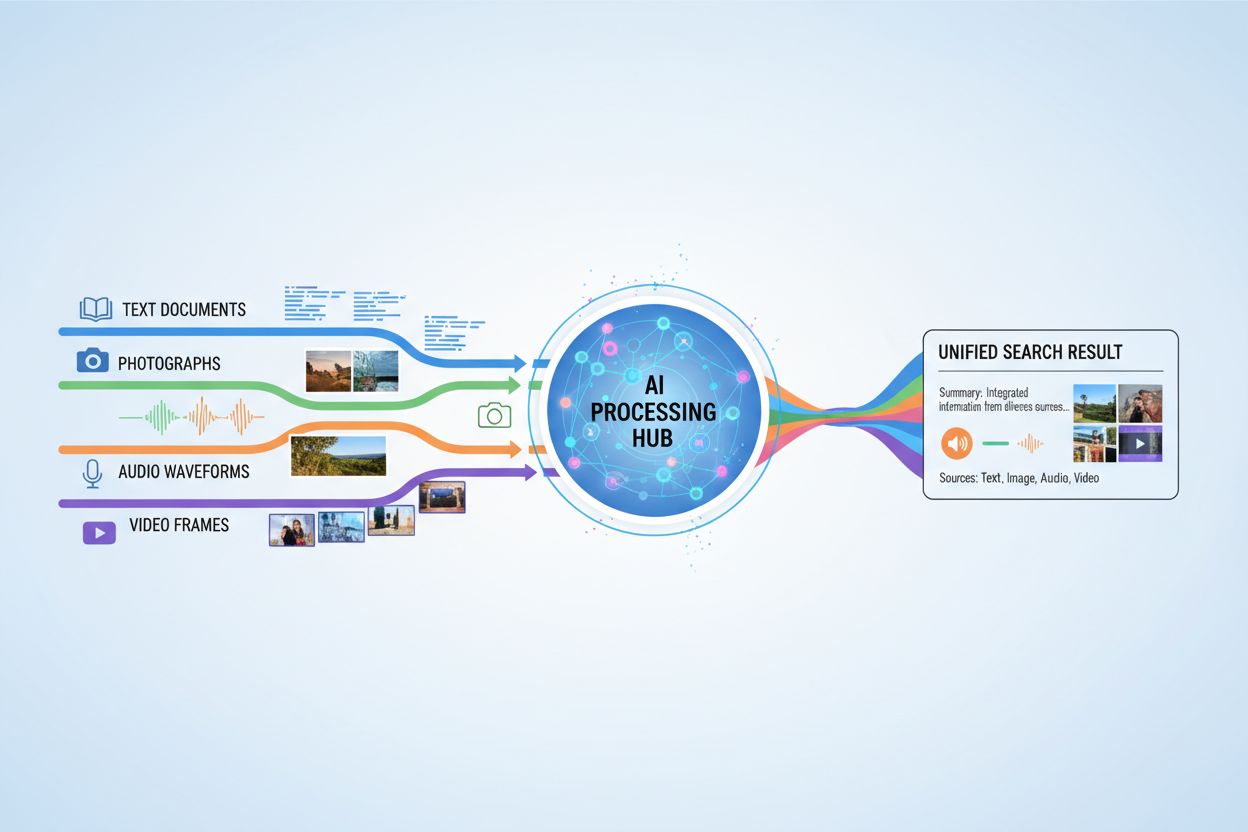
Multimodální AI vyhledávání má transformační využití napříč mnoha odvětvími a oblastmi. Ve zdravotnictví systémy analyzují lékařské snímky spolu s pacientskými záznamy a klinickými poznámkami pro zlepšení přesnosti diagnóz a doporučení léčby. E-commerce platformy využívají multimodální vyhledávání, které zákazníkům umožňuje hledat produkty pomocí kombinace textových popisů, vizuálních referencí nebo dokonce skic. Autonomní vozidla spoléhají na multimodální fúzi kamerových záznamů, radarových dat a senzorických vstupů pro bezpečnou navigaci a rozhodování v reálném čase. Systémy pro moderování obsahu kombinují rozpoznávání obrázků, analýzu textu a zpracování zvuku, aby účinněji identifikovaly škodlivý obsah než jednovstupové přístupy. Multimodální vyhledávání také zvyšuje přístupnost, protože uživatelé mohou vyhledávat pomocí preferovaného vstupního způsobu—hlasem, obrázkem nebo textem—zatímco systém chápe záměr napříč všemi formáty.

Multimodální AI vyhledávání přináší významné přínosy, které ospravedlňují jeho vyšší složitost a výpočetní náročnost. Zlepšená přesnost vyplývá z využití doplňujících se informačních zdrojů, čímž se redukují chyby, kterých by se systémy s jednou modalitou mohly dopustit. Lepší kontextové porozumění nastává, když se vizuální, textové a zvukové informace spojují a poskytují bohatší sémantický význam. Vyšší uživatelský komfort je dosažen díky intuitivnějším rozhraním vyhledávání, která přijímají různé typy vstupů a poskytují relevantnější výsledky. Mezioborové učení je umožněno tím, že znalosti z jedné modality mohou ovlivnit porozumění v jiné, což umožňuje transfer learning napříč různými typy dat. Vyšší robustnost znamená, že systém udrží výkon i při degradaci nebo nedostupnosti jedné modality, protože ostatní modality mohou kompenzovat chybějící informace.
Navzdory svým výhodám čelí multimodální AI vyhledávání významným technickým a praktickým výzvám. Sladění a synchronizace dat zůstává obtížná, protože různé modality mají často odlišné časové charakteristiky a úrovně kvality, které je třeba pečlivě řídit. Výpočetní náročnost výrazně roste při současném zpracování více datových proudů, což vyžaduje značné výpočetní zdroje a specializovaný hardware. Otázky zaujatosti a spravedlnosti se objevují, když trénovací data obsahují nerovnováhu mezi modalitami nebo když jsou určité skupiny v některých typech dat nedostatečně zastoupeny. Soukromí a bezpečnost jsou složitější s více datovými proudy, což zvyšuje možné riziko úniku a vyžaduje pečlivé zacházení s citlivými informacemi. Obrovské požadavky na data znamenají, že efektivní trénink multimodálních systémů vyžaduje podstatně větší a rozmanitější datasety než unimodální alternativy, což může být nákladné a časově náročné na získání a anotaci.
Multimodální AI vyhledávání má zásadní význam také pro monitoring AI a sledování citací, zejména když AI systémy čím dál více generují odpovědi odkazující nebo syntetizující informace z více zdrojů. Platformy jako AmICited.com se zaměřují na sledování, jak AI systémy citují a připisují informace původním zdrojům, což zajišťuje transparentnost a odpovědnost v AI generovaných odpovědích. Podobně FlowHunt.io sleduje generování AI obsahu a pomáhá organizacím pochopit, jak jejich značkový obsah zpracovávají a referencují multimodální AI systémy. Jak se multimodální AI vyhledávání stává běžnějším, sledování, jak tyto systémy citují značky, produkty a původní zdroje, je klíčové pro firmy, které chtějí znát svou viditelnost ve výsledcích generovaných AI. Tato monitorovací schopnost organizacím umožňuje ověřit, že jejich obsah je přesně reprezentován a správně připisován při syntéze informací napříč textem, obrázky a dalšími modalitami.
Budoucnost multimodálního AI vyhledávání směřuje k stále sjednocenější a plynulejší integraci různých typů dat, tedy za hranici současných fúzních přístupů k holističtějším modelům, které zpracovávají všechny modality jako vzájemně propojené. Schopnosti zpracování v reálném čase se rozšíří, takže multimodální vyhledávání bude fungovat na živých video streamech, kontinuálním zvuku i dynamickém textu současně bez prodlev. Pokročilé techniky augmentace dat pomohou řešit současný nedostatek dat syntetickým generováním multimodálních trénovacích příkladů, které zachovávají sémantickou konzistenci napříč modalitami. Mezi nově vznikající trendy patří základní modely trénované na rozsáhlých multimodálních datech, které lze efektivně přizpůsobit specifickým úkolům, neuromorfní výpočetní přístupy blíže napodobující biologické multimodální zpracování a federativní multimodální učení, které umožňuje trénink napříč distribuovanými zdroji dat při zachování soukromí. Tyto pokroky učiní multimodální AI vyhledávání dostupnějším, efektivnějším a schopným zvládat stále složitější scénáře reálného světa.
Unimodální AI systémy zpracovávají pouze jeden typ datového vstupu, například pouze textové vyhledávače. Multimodální AI systémy naopak současně zpracovávají a integrují více typů dat—text, obrázky, zvuk a video—což umožňuje hlubší porozumění a přesnější výsledky díky využití komplementárních silných stránek různých datových formátů.
Multimodální AI vyhledávání zvyšuje přesnost kombinací doplňujících se informačních zdrojů, které zachycují nuance a vztahy neviditelné pro přístupy s jedním typem vstupu. Když se spojí vizuální, textové a zvukové informace, systém dosáhne bohatšího sémantického porozumění a může činit informovanější rozhodnutí na základě více pohledů na stejnou informaci.
Klíčové výzvy zahrnují sladění a synchronizaci dat napříč různými modalitami, značnou výpočetní náročnost, otázky zaujatosti a spravedlnosti při nevyvážených trénovacích datech, otázky ochrany soukromí a bezpečnosti při práci s více datovými proudy a obrovské požadavky na data pro efektivní trénink. Každá modalita má jiné časové charakteristiky a úrovně kvality, které je třeba pečlivě řídit.
Zdravotnictví těží z analýzy lékařských snímků spolu s pacientskými záznamy a klinickými poznámkami. E-commerce využívá multimodální vyhledávání pro vizuální objevování produktů. Autonomní vozidla spoléhají na multimodální fúzi kamer, radaru a senzorů. Moderace obsahu kombinuje analýzu obrázků, textu a zvuku. Zákaznické služby využívají více typů vstupů pro lepší podporu a aplikace pro přístupnost umožňují uživatelům vyhledávat pomocí preferovaného vstupního způsobu.
Embeddingové modely převádějí různé modality na číselné reprezentace, které zachycují sémantický význam. Vektorové databáze ukládají tyto embeddingy do sdíleného matematického prostoru, kde lze měřit a porovnávat vztahy mezi různými typy dat. To umožňuje systému nalézat souvislosti mezi textem, obrázky, zvukem a videem porovnáváním jejich pozic v tomto společném sémantickém prostoru.
Multimodální AI systémy pracují s více citlivými typy dat—zaznamenanými konverzacemi, daty z rozpoznávání obličeje, psanou komunikací a lékařskými snímky—což zvyšuje rizika pro soukromí. Kombinace různých modalit vytváří více příležitostí pro úniky dat a vyžaduje přísné dodržování předpisů, jako jsou GDPR a CCPA. Organizace musí zavádět robustní bezpečnostní opatření na ochranu identity uživatelů a citlivých informací napříč všemi modalitami.
Platformy jako AmICited.com monitorují, jak AI systémy citují a připisují informace původním zdrojům, což zajišťuje transparentnost AI generovaných odpovědí. Organizace mohou sledovat svou viditelnost ve výsledcích multimodálního AI vyhledávání, ověřit přesnost reprezentace svého obsahu a potvrdit správné připisování, když AI systémy syntetizují informace napříč textem, obrázky a dalšími modalitami.
Budoucnost zahrnuje sjednocené modely, které zpracovávají všechny modality jako vzájemně propojené, zpracování živých video a audio streamů v reálném čase, pokročilé techniky augmentace dat pro řešení nedostatku dat, základní modely trénované na rozsáhlých multimodálních datech, neuromorfní výpočetní přístupy napodobující biologické zpracování a federativní učení, které zachovává soukromí při tréninku na distribuovaných zdrojích.
Sledujte, jak multimodální AI vyhledávače citují a připisují váš obsah napříč textem, obrázky a dalšími modalitami díky komplexní monitorovací platformě AmICited.
Ovládněte optimalizaci multimodálního AI vyhledávání. Naučte se, jak optimalizovat obrázky a hlasové dotazy pro výsledky vyhledávání poháněné AI, včetně strateg...

Zjistěte, co je multimodální obsah pro AI, jak funguje a proč je důležitý. Prozkoumejte příklady multimodálních AI systémů a jejich využití v různých odvětvích....

Zjistěte, jak optimalizovat text, obrázky a video pro multimodální AI systémy. Objevte strategie pro zlepšení AI citací a viditelnosti napříč ChatGPT, Gemini a ...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.