RAG (Retrieval-Augmented Generation) pipeline je pracovní postup, který umožňuje AI systémům vyhledávat, řadit a citovat externí zdroje při generování odpovědí. Kombinuje vyhledávání dokumentů, sémantické řazení a generování pomocí LLM k poskytování přesných, kontextuálně relevantních odpovědí podložených reálnými daty. RAG systémy snižují halucinace tím, že před vytvořením odpovědí konzultují externí znalostní báze, což je činí zásadními pro aplikace, které požadují faktickou přesnost a uvedení zdrojů.
RAG Pipeline
RAG (Retrieval-Augmented Generation) pipeline je pracovní postup, který umožňuje AI systémům vyhledávat, řadit a citovat externí zdroje při generování odpovědí. Kombinuje vyhledávání dokumentů, sémantické řazení a generování pomocí LLM k poskytování přesných, kontextuálně relevantních odpovědí podložených reálnými daty. RAG systémy snižují halucinace tím, že před vytvořením odpovědí konzultují externí znalostní báze, což je činí zásadními pro aplikace, které požadují faktickou přesnost a uvedení zdrojů.
Co je RAG Pipeline?
RAG (Retrieval-Augmented Generation) pipeline je AI architektura, která kombinuje vyhledávání informací s generováním pomocí velkého jazykového modelu (LLM), aby poskytovala přesnější, kontextuálně relevantní a ověřitelné odpovědi. Namísto spoléhání pouze na trénovací data LLM RAG systémy dynamicky získávají relevantní dokumenty či data z externích znalostních bází před samotným generováním odpovědí, což výrazně snižuje halucinace a zvyšuje faktickou přesnost. Pipeline funguje jako most mezi statickými trénovacími daty a aktuálními informacemi, takže AI systémy mohou odkazovat na současný, doménový nebo proprietární obsah. Tento přístup se stal zásadním pro organizace požadující odpovědi podložené citacemi, dodržování přesnosti a transparentnosti v AI generovaném obsahu. RAG pipeline jsou obzvláště cenné při monitorování AI systémů, kde jsou dohledatelnost a atribuce zdrojů kritickými požadavky.
Klíčové komponenty
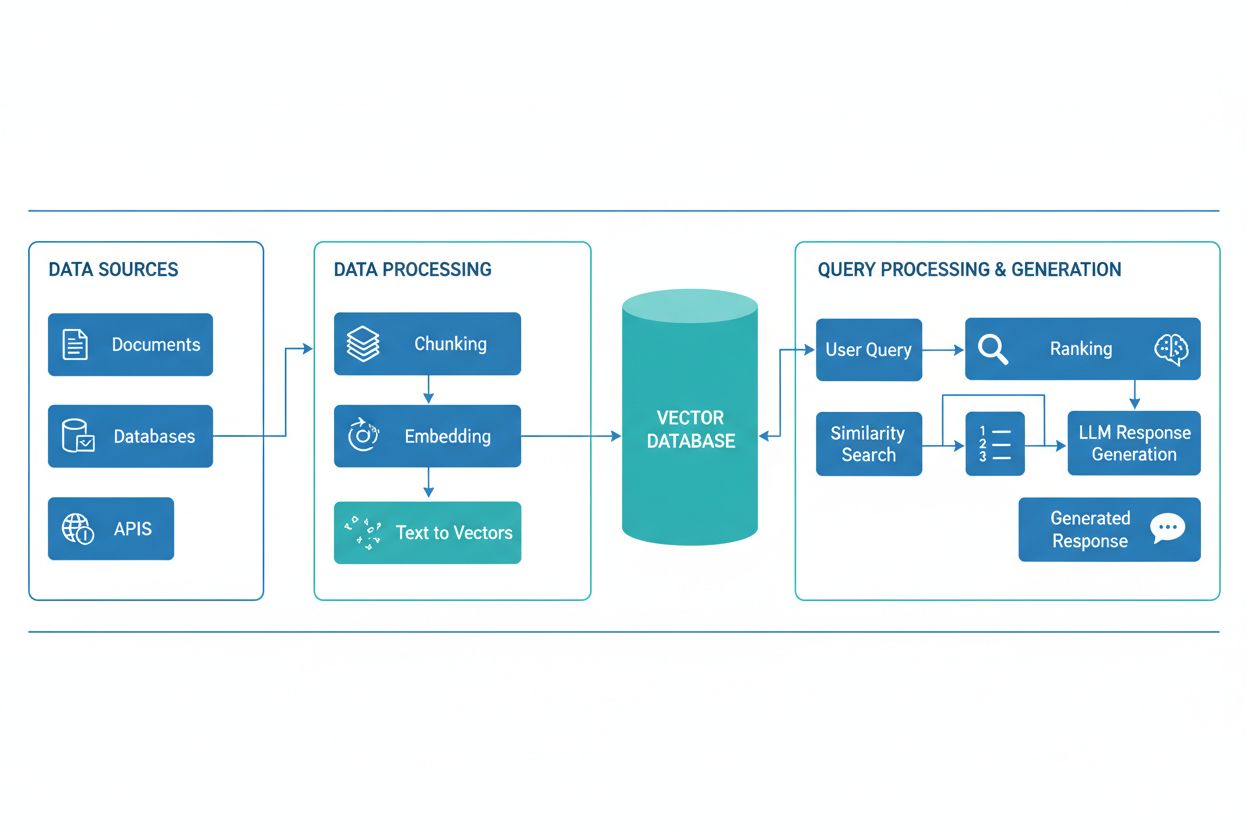
RAG pipeline se skládá z několika propojených komponent, které spolupracují na vyhledávání relevantních informací a generování podložených odpovědí. Architektura obvykle zahrnuje vrstvu pro příjem dokumentů, která zpracovává a připravuje surová data, vektorovou databázi nebo znalostní bázi pro ukládání embeddingů a indexovaného obsahu, vyhledávací mechanismus pro identifikaci relevantních dokumentů na základě dotazu uživatele, systém pro řazení výsledků podle relevance a generovací modul poháněný LLM, který syntetizuje získané informace do srozumitelných odpovědí. Další komponenty zahrnují zpracování a předzpracování dotazů, embeddingové modely převádějící text na číselné reprezentace a zpětnovazební smyčku pro kontinuální zvyšování přesnosti vyhledávání. Orchestrace těchto komponent určuje celkovou efektivitu a výkonnost RAG systému.
Komponenta
Funkce
Klíčové technologie
Příjem dokumentů
Zpracování a příprava surových dat
Apache Kafka, LangChain, Unstructured
Vektorová databáze
Ukládání embeddingů a indexovaného obsahu
Pinecone, Weaviate, Milvus, Qdrant
Vyhledávací engine
Identifikace relevantních dokumentů
BM25, Dense Passage Retrieval (DPR)
Systém řazení
Prioritizace výsledků vyhledávání
Cross-encodery, reranking pomocí LLM
Generovací modul
Syntéza odpovědí z kontextu
GPT-4, Claude, Llama, Mistral
Zpracování dotazů
Normalizace a pochopení dotazu uživatele
BERT, T5, vlastní NLP pipeline
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
RAG pipeline funguje ve dvou oddělených fázích: vyhledávací fázi a generovací fázi. Během vyhledávací fáze je uživatelský dotaz převeden na embedding pomocí stejného embeddingového modelu, jaký byl použit pro dokumenty znalostní báze, a poté je prohledána vektorová databáze za účelem nalezení nejvíce sémanticky podobných dokumentů nebo pasáží. Tato fáze obvykle vrátí seřazený seznam kandidátních dokumentů, který může být dále zpřesněn pomocí přerovnávacích algoritmů využívajících cross-encodery nebo skórování pomocí LLM pro zajištění relevance. V generovací fázi jsou nejlépe hodnocené vyhledané dokumenty vloženy do kontextového okna a spolu s původním dotazem předány LLM, čímž model generuje odpovědi podložené skutečnými zdroji. Tento dvoufázový přístup zajišťuje, že odpovědi jsou kontextově vhodné a dohledatelné ke konkrétním zdrojům, což je ideální pro aplikace vyžadující citace a odpovědnost. Kvalita finálního výstupu závisí zásadně jak na relevanci vyhledaných dokumentů, tak na schopnosti LLM koherentně syntetizovat informace.
Klíčové technologie a nástroje
Ekosystém RAG zahrnuje širokou škálu specializovaných nástrojů a frameworků, které usnadňují tvorbu a nasazení pipeline. Moderní implementace RAG využívají několik kategorií technologií:
Orchestrační frameworky: LangChain, LlamaIndex (dříve GPT Index) a Haystack poskytují abstrakci pro tvorbu RAG workflow bez nutnosti správy jednotlivých komponent
Vektorové databáze: Pinecone, Weaviate, Milvus, Qdrant a Chroma nabízejí škálovatelné ukládání a vyhledávání embeddingů s velmi nízkou latencí dotazů
Embeddingové modely: OpenAI text-embedding-3, Cohere Embed API a open source modely jako all-MiniLM-L6-v2 převádějí text do sémantických reprezentací
Poskytovatelé LLM: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) a Mistral nabízejí různé velikosti modelů a schopnosti pro generování
Řešení pro reranking: Cohere Rerank API, cross-encoder modely z Hugging Face a proprietární rerankery na bázi LLM zvyšují přesnost vyhledávání
Nástroje pro přípravu dat: Unstructured, Apache Kafka a vlastní ETL pipeline zajišťují příjem dokumentů, dělení a předzpracování
Monitorování a evaluace: Nástroje jako Ragas, TruLens a vlastní hodnotící frameworky vyhodnocují výkonnost RAG systému a identifikují slabá místa
Tyto nástroje lze modulárně kombinovat, což umožňuje organizacím sestavit RAG systémy přesně dle svých požadavků a infrastrukturních omezení.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Vyhledávací mechanismy
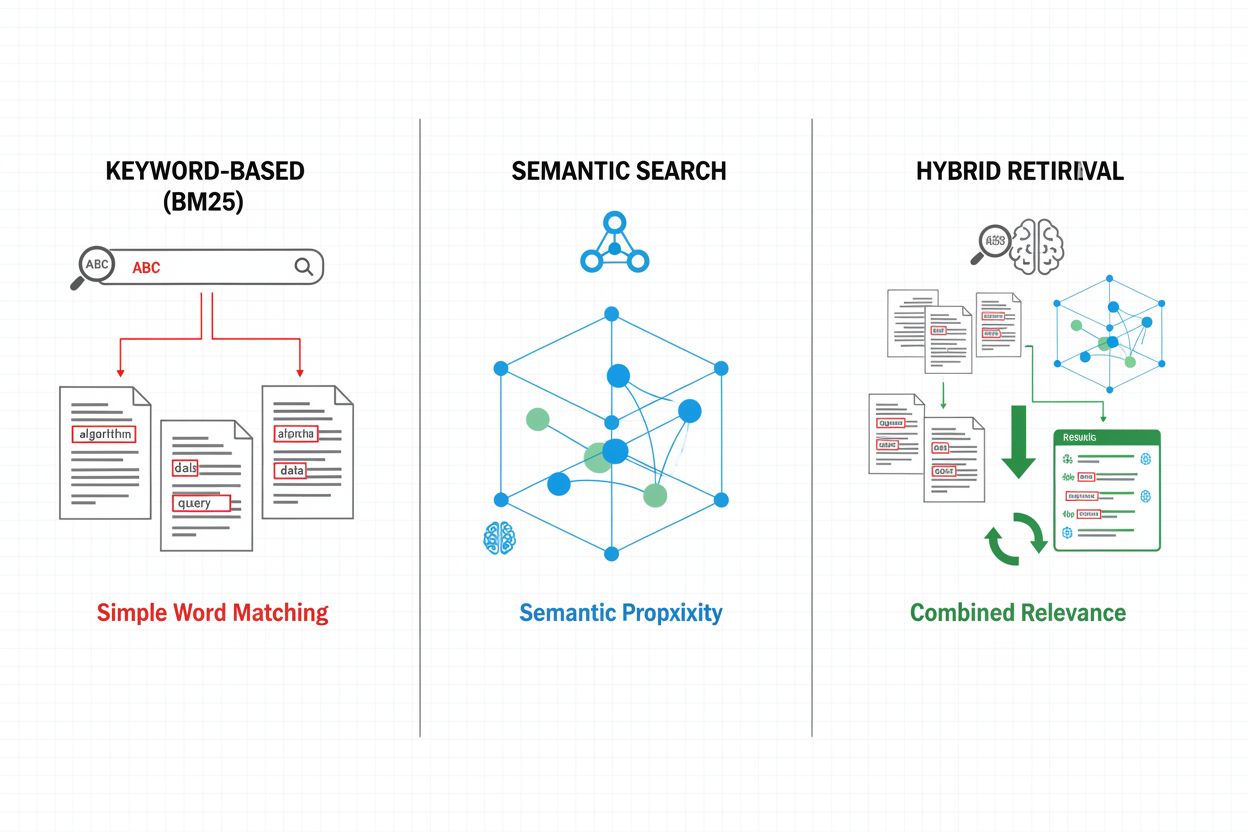
Vyhledávací mechanismy tvoří základ efektivity RAG pipeline a vyvíjejí se od jednoduchých klíčových slov až po sofistikované sémantické vyhledávání. Tradiční vyhledávání na bázi klíčových slov s algoritmem BM25 je výpočetně efektivní a vhodné pro přesné shody, ale nedokáže zachytit sémantiku a synonymii. Dense Passage Retrieval (DPR) a další neuronové metody překonávají tyto limity tím, že převádějí dotazy i dokumenty do hustých vektorových embeddingů, umožňujících sémantické porovnání významů nad rámec klíčových slov. Hybridní vyhledávání kombinuje obě metody a využívá jejich předností pro zvýšení přesnosti a pokrytí napříč různými typy dotazů. Pokročilé mechanismy zahrnují rozšíření dotazu (query expansion), kdy je původní dotaz obohacen o příbuzné termíny či přeformulace, aby bylo možné zachytit více relevantních dokumentů. Přerovnávací vrstvy dále zpřesňují výsledky pomocí výpočetně náročnějších modelů, které skórují kandidátní dokumenty podle hlubšího sémantického porozumění nebo úlohově specifických kritérií. Volba vyhledávacího mechanismu významně ovlivňuje jak přesnost vyhledaného kontextu, tak výpočetní náročnost pipeline, a vyžaduje pečlivé zvážení rychlosti versus kvality.
Výhody RAG pipeline
RAG pipeline přináší zásadní výhody oproti samotným LLM, zejména pro aplikace vyžadující přesnost, aktuálnost a dohledatelnost. Zakotvením odpovědí ve vyhledaných dokumentech RAG systémy dramaticky snižují halucinace—situace, kdy LLM generují věrohodně znějící, ale fakticky nesprávné informace—, což je činí vhodnými pro vysoce regulované oblasti jako zdravotnictví, právo či finance. Možnost využívat externí znalostní báze umožňuje RAG systémům poskytovat aktuální informace bez nutnosti přeučování modelů, takže organizace mohou udržovat odpovědi v souladu s nejnovějšími daty. RAG pipeline podporují doménovou customizaci začleněním proprietárních dokumentů, interních znalostních bází a specializované terminologie, což vede k relevantnějším a kontextovějších odpovědím. Vyhledávací složka zajišťuje transparentnost a auditovatelnost tím, že jasně ukazuje, které zdroje byly použity pro každou odpověď, což je zásadní pro dodržování compliance a důvěru uživatelů. Efektivita nákladů se zvyšuje díky možnosti využívat menší, úspornější LLM, které při správném kontextu generují kvalitní odpovědi a tím snižují výpočetní zátěž oproti větším modelům. Tyto výhody činí RAG obzvlášť cenným pro organizace zavádějící AI monitorovací systémy, kde je přesnost citací a viditelnost obsahu zásadní.
Výzvy a omezení
Navzdory výhodám čelí RAG pipeline několika technickým i provozním výzvám, které vyžadují pečlivé řízení. Kvalita vyhledaných dokumentů přímo určuje kvalitu odpovědí, takže chyby ve vyhledávání jsou těžko napravitelné—jde o fenomén „garbage in, garbage out“, kdy irelevantní či zastaralé dokumenty ve znalostní bázi proniknou až do finální odpovědi. Embeddingové modely mohou mít problém s doménovou terminologií, vzácnými jazyky nebo velmi technickým obsahem, což vede k nepřesné sémantické shodě a opomenutí relevantních dokumentů. Výpočetní náklady na vyhledávání, generování embeddingů a přerovnávání mohou být značné ve velkém měřítku, zejména při zpracování rozsáhlých znalostních bází či vysokém počtu dotazů. Omezení kontextového okna LLM limitují množství vyhledaných informací, které lze vložit do promptu, což vyžaduje pečlivý výběr a sumarizaci relevantních pasáží. Udržování aktuálnosti a konzistence znalostní báze je provozní výzva, hlavně v dynamickém prostředí s častými změnami informací nebo více zdroji. Hodnocení výkonu RAG systému vyžaduje komplexní metriky přesahující tradiční míry přesnosti, včetně přesnosti vyhledávání, relevance odpovědí a správnosti citací, což je často obtížné automaticky měřit.
RAG vs. jiné přístupy
RAG představuje jednu z více strategií pro zvýšení přesnosti a relevance LLM, přičemž každá má své výhody a nevýhody. Fine-tuning znamená přeškolení LLM na doménově specifických datech, což poskytuje hluboké přizpůsobení modelu, ale vyžaduje značné výpočetní prostředky, anotovaná data a pravidelnou údržbu při změně informací. Prompt engineering optimalizuje zadání a kontext poskytovaný LLM bez úpravy vah modelu, nabízí flexibilitu a nízké náklady, ale je omezený trénovacími daty modelu a velikostí kontextového okna. In-context learning využívá příkladů v promptu pro rychlé přizpůsobení, ale spotřebovává cenné kontextové tokeny a vyžaduje pečlivý výběr ukázek. Oproti těmto přístupům nabízí RAG střední cestu: zajišťuje dynamický přístup k aktuálním informacím bez retréninku, transparentnost díky explicitnímu uvádění zdrojů a efektivní škálování napříč znalostními doménami. RAG však přináší dodatečnou složitost v podobě vyhledávací infrastruktury a rizika chyb ve vyhledávání, zatímco fine-tuning umožňuje těsnější integraci doménových znalostí do chování modelu. Optimální strategie často kombinuje více přístupů—například použití RAG s fine-tuned modely a promyšlenými prompty—pro maximalizaci přesnosti a relevance pro konkrétní scénáře.
Budování a nasazení RAG
Implementace produkční RAG pipeline vyžaduje systematické plánování v oblasti přípravy dat, návrhu architektury i provozu. Proces začíná přípravou znalostní báze: sběrem relevantních dokumentů, čištěním a standardizací formátů a dělením obsahu na vhodně velké části, které vyvažují zachování kontextu s přesností vyhledávání. Následuje výběr embeddingových modelů a vektorových databází dle požadavků na výkon, latenci a škálovatelnost, včetně parametrů jako rozměr embeddingu, propustnost dotazů a kapacita úložiště. Pak je nakonfigurován vyhledávací systém, včetně volby algoritmů (klíčová slova, sémantika, hybrid), strategií přerovnávání a kritérií filtrování výsledků. Následuje integrace s poskytovateli LLM, propojení s generovacími modely a definice prompt šablon, které efektivně využijí vyhledaný kontext. Testování a vyhodnocování jsou klíčové, zahrnují metriky kvality vyhledávání (precision, recall, MRR), generování (relevance, koherence, faktualita) a výkonu systému jako celku. Nasazení vyžaduje nastavení monitoringu přesnosti vyhledávání a kvality generace, implementaci zpětné vazby pro identifikaci a řešení selhání a zavedení procesů pro aktualizace a údržbu znalostní báze. Nakonec je nutná průběžná optimalizace na základě analýzy uživatelských interakcí, identifikace častých selhání a iterativní vylepšování vyhledávacích mechanismů, strategií přerovnávání i prompt engineeringu pro zvýšení celkového výkonu systému.
RAG v AI monitoringu a citacích
RAG pipeline jsou základem moderních AI monitorovacích platforem jako AmICited.com, kde je zásadní sledování zdrojů a přesnosti AI generovaného obsahu. Explicitním vyhledáváním a citováním zdrojových dokumentů vytvářejí RAG systémy auditovatelnou stopu, která umožňuje monitorovacím platformám ověřovat tvrzení, hodnotit faktickou správnost a identifikovat možné halucinace nebo chybné přiřazení. Tato citační schopnost řeší zásadní nedostatek transparentnosti AI: uživatelé i auditoři mohou sledovat odpovědi zpět ke zdrojům, což umožňuje nezávislé ověření a posiluje důvěru v AI generovaný obsah. Pro tvůrce obsahu a organizace používající AI nástroje přináší monitoring s podporou RAG přehled o tom, které zdroje ovlivnily konkrétní odpovědi, což podporuje soulad s požadavky na přiřazení a správu obsahu. Vyhledávací komponenta RAG pipeline generuje bohatá metadata—včetně skóre relevance, pořadí dokumentů a metrik důvěry ve vyhledávání—, která lze analyzovat pro hodnocení spolehlivosti odpovědí a zjištění, kdy AI systémy operují mimo své znalostní domény. Integrace RAG s monitorovacími platformami umožňuje detekci tzv. citačního driftu, kdy AI systémy postupně upouštějí od autoritativních zdrojů ve prospěch méně důvěryhodných, a podporuje prosazování politik ohledně kvality a diverzity zdrojů. Jak se AI systémy stávají součástí kritických workflow, kombinace RAG pipeline s komplexním monitoringem vytváří mechanismy odpovědnosti, které chrání uživatele, organizace i celý informační ekosystém před dezinformacemi generovanými AI.
Často kladené otázky
Jaký je rozdíl mezi RAG a fine-tuningem?
RAG a fine-tuning jsou komplementární přístupy ke zlepšení výkonu LLM. RAG získává externí dokumenty v čase dotazu bez úprav modelu, což umožňuje přístup k aktuálním datům a snadné aktualizace. Fine-tuning přeškoluje model na doménově specifických datech, nabízí hlubší přizpůsobení, ale vyžaduje značné výpočetní zdroje a ruční aktualizace při změně informací. Mnoho organizací používá obě techniky dohromady pro optimální výsledky.
Jak RAG snižuje halucinace v AI odpovědích?
RAG snižuje halucinace tím, že zakládá odpovědi LLM na vyhledaných faktických dokumentech. Namísto spoléhání pouze na trénovací data systém nejprve vyhledá relevantní zdroje a teprve poté generuje odpovědi, čímž modelu poskytuje konkrétní důkazy k citování. Tento přístup zajišťuje, že odpovědi jsou založené na skutečných informacích, nikoli pouze na naučených vzorcích modelu, což výrazně zvyšuje faktickou přesnost a snižuje falešná či zavádějící tvrzení.
Co jsou vektorové embeddingy a proč jsou v RAG důležité?
Vektorové embeddingy jsou číselné reprezentace textu, které zachycují sémantický význam v mnohorozměrném prostoru. Umožňují RAG systémům provádět sémantické vyhledávání a nalézat dokumenty s podobným významem, i když používají různá slova. Embeddingy jsou klíčové, protože umožňují RAG překročit rámec porovnávání klíčových slov a chápat konceptuální vztahy, což zlepšuje relevanci vyhledávání a přesnost generovaných odpovědí.
Mohou RAG pipeline pracovat s daty v reálném čase?
Ano, RAG pipeline mohou zahrnovat data v reálném čase prostřednictvím kontinuálního příjmu a indexace. Organizace mohou nastavit automatizované pipeline, které pravidelně aktualizují vektorovou databázi novými dokumenty, aby znalostní báze zůstávala aktuální. Díky této schopnosti je RAG ideální pro aplikace, které vyžadují aktuální informace, jako je analýza zpráv, cenová inteligence a monitorování trhu, a to bez nutnosti přeučovat základní LLM.
Jaký je rozdíl mezi sémantickým vyhledáváním a RAG?
Sémantické vyhledávání je metoda získávání dokumentů na základě významové podobnosti pomocí vektorových embeddingů. RAG je kompletní pipeline, která kombinuje sémantické vyhledávání s generováním pomocí LLM, aby produkovala odpovědi založené na získaných dokumentech. Zatímco sémantické vyhledávání se zaměřuje na nalezení relevantních informací, RAG přidává i generování, které získaný obsah syntetizuje do koherentních odpovědí s citacemi.
Jak RAG systémy rozhodují, které zdroje citovat?
RAG systémy využívají různé mechanismy pro výběr citovaných zdrojů. Používají vyhledávací algoritmy k nalezení relevantních dokumentů, modely pro přerovnání výsledků k upřednostnění nejrelevantnějších a ověřovací procesy k zajištění, že citace skutečně podporují uváděná tvrzení. Některé systémy využívají přístup 'citace při psaní', kde jsou tvrzení vytvářena pouze na základě nalezených zdrojů, jiné ověřují citace až po vygenerování odpovědi a nepodložené tvrzení odstraňují.
Jaké jsou hlavní výzvy při budování RAG pipeline?
Klíčovými výzvami jsou udržování aktuálnosti a kvality znalostní báze, optimalizace přesnosti vyhledávání napříč různými typy obsahu, řízení výpočetních nákladů ve velkém měřítku, práce s doménovou terminologií, kterou embeddingové modely nemusí dobře chápat, a hodnocení výkonnosti systému pomocí komplexních metrik. Organizace musí také řešit omezení kontextového okna LLM a zajišťovat, že vyhledané dokumenty zůstávají relevantní, jak se informace vyvíjejí.
Jak AmICited monitoruje RAG citace v AI systémech?
AmICited sleduje, jak AI systémy jako ChatGPT, Perplexity a Google AI Overviews získávají a citují obsah prostřednictvím RAG pipeline. Platforma monitoruje, které zdroje byly vybrány k citaci, jak často se vaše značka objevuje v AI odpovědích a zda jsou citace přesné. Tato transparentnost pomáhá organizacím porozumět jejich přítomnosti v AI vyhledávání a zajistit správné přiřazení jejich obsahu.
Monitorujte svou značku v AI odpovědích
Sledujte, jak AI systémy jako ChatGPT, Perplexity a Google AI Overviews odkazují na váš obsah. Získejte přehled o citacích RAG a monitorování AI odpovědí.
Co je RAG ve vyhledávání pomocí AI: Kompletní průvodce Retrieval-Augmented Generation
Zjistěte, co je RAG (Retrieval-Augmented Generation) ve vyhledávání pomocí AI. Objevte, jak RAG zvyšuje přesnost, snižuje halucinace a pohání ChatGPT, Perplexit...
Jak funguje Retrieval-Augmented Generation: Architektura a proces
Zjistěte, jak RAG kombinuje LLM s externími datovými zdroji pro generování přesných odpovědí AI. Pochopte pětistupňový proces, komponenty a proč je důležitý pro...
Zjistěte, co je Retrieval-Augmented Generation (RAG), jak funguje a proč je zásadní pro přesné odpovědi AI. Prozkoumejte architekturu RAG, výhody a podnikové ap...
11 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.