Hodnocení důvěryhodnosti zdrojů
Zjistěte, jak AI systémy hodnotí důvěryhodnost zdrojů prostřednictvím odbornosti autorů, citací a ověření. Pochopte technické mechanismy, klíčové faktory a nejl...
8 min čtení
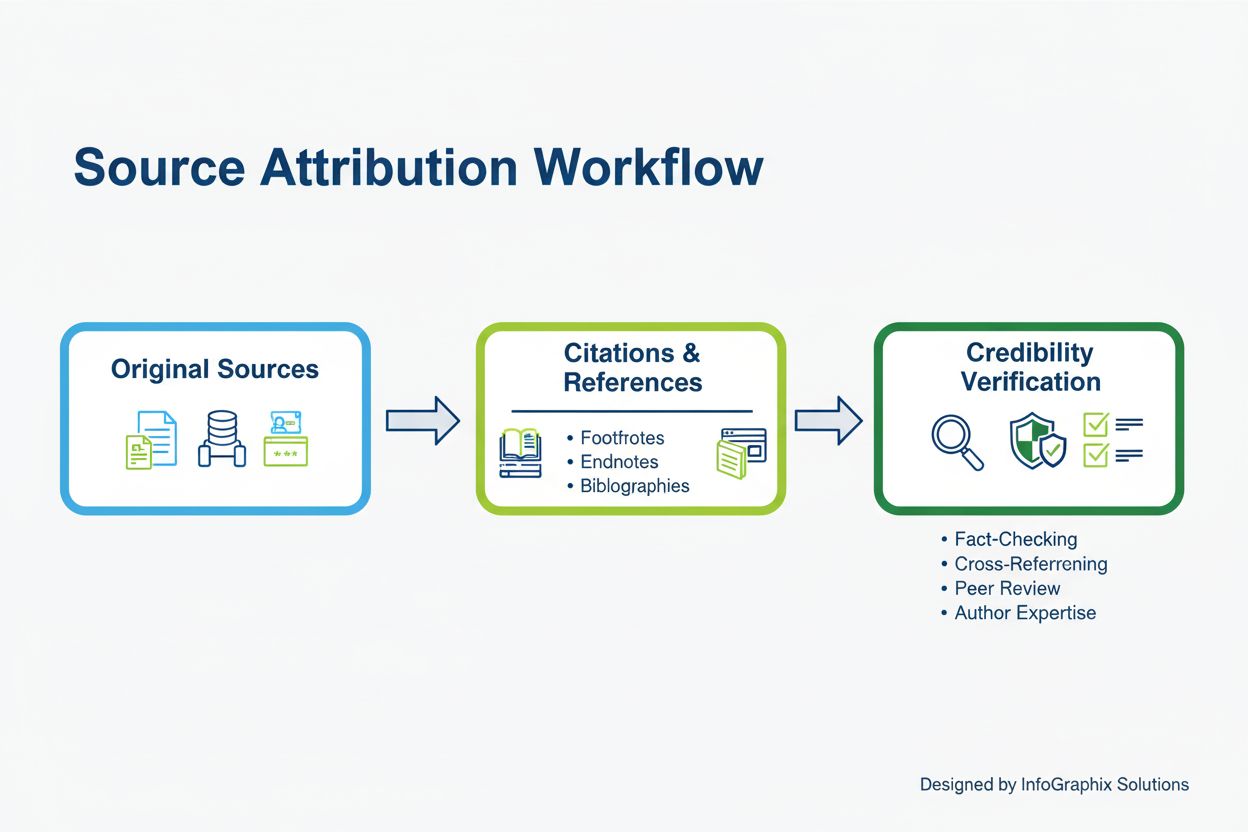
Přisuzování zdrojů je praxe identifikace a uvedení původních zdrojů informací, nápadů nebo obsahu použitých v publikované práci. Spočívá v explicitním uznání toho, odkud fakta, citace, data a koncepty pocházejí, čímž se zajišťuje důvěryhodnost a transparentnost a zároveň se respektují autorská práva.
Přisuzování zdrojů je praxe identifikace a uvedení původních zdrojů informací, nápadů nebo obsahu použitých v publikované práci. Spočívá v explicitním uznání toho, odkud fakta, citace, data a koncepty pocházejí, čímž se zajišťuje důvěryhodnost a transparentnost a zároveň se respektují autorská práva.
Přisuzování zdrojů je praxe identifikace a uvedení původních zdrojů informací, nápadů, dat nebo kreativního obsahu použitých v publikované práci. Představuje základní princip etické komunikace, intelektuální poctivosti a profesní integrity napříč žurnalistikou, akademickou sférou, marketingem a tvorbou digitálního obsahu. Při přisuzování zdroje explicitně uznáváte, odkud fakta, citace, statistiky, výsledky výzkumu nebo koncepty pocházejí, čímž poskytujete čtenářům a publiku transparentní cestu k ověření informací a hlubšímu prozkoumání témat. V kontextu moderních AI-vyhledávacích prostředí se přisuzování zdrojů posunulo za hranice tradičních citačních praktik a stalo se klíčovým metrem viditelnosti, které určuje, zda značky a vydavatelé získají uznání, návštěvnost a autoritu od AI platforem jako ChatGPT, Perplexity, Google AI Overviews a Claude. Rozlišení mezi přisuzováním a citací je důležité: přisuzování se zaměřuje na uznání držitele zdroje a duševního vlastnictví, zatímco citace sleduje specifická formátovací pravidla pro akademickou či profesní dokumentaci.
Koncept přisuzování zdrojů má hluboké historické kořeny ve vědeckých a novinářských tradicích. Akademické instituce již dlouho vyžadují správné přisuzování, aby zabránily plagiátorství a zachovaly intelektuální rigor, přičemž formální citační systémy jako APA, MLA a Chicago vznikly ve 20. století pro standardizaci přisuzovacích praktik. Žurnalistika ustanovila přisuzování jako základ důvěryhodnosti, kdy NPR, The New York Times a další přední zpravodajské organizace vyvinuly přísné standardy přisuzování pro budování důvěry publika a odpovědnosti. Digitální revoluce přisuzovací praktiky výrazně změnila. S tím, jak se informace staly snadněji dostupnými a sdílenými online, se sledování obsahu až k původním zdrojům stalo mnohem složitějším. Agregace obsahu, sdílení na sociálních sítích a rozšíření sekundárních zdrojů vytvořily přisuzovací výzvy, na které tradiční citační systémy nebyly navrženy. Podle výzkumu American Press Institute si přibližně 68 % uživatelů online obsahu cení transparentního uvádění zdrojů a s větší pravděpodobností důvěřuje značkám, které jasně přisuzují své informační zdroje. Nástup AI-generovaného obsahu vytvořil zcela novou dimenzi přisuzování zdrojů, což nutí platformy a tvůrce obsahu znovu promýšlet, jak přisuzování funguje, když algoritmy syntetizují informace z více zdrojů do ucelených odpovědí.
Efektivní přisuzování zdrojů vyžaduje několik klíčových prvků, které společně vytvářejí transparentnost a důvěryhodnost. Rámec TASL (Název, Autor, Zdroj, Licence) představuje komplexní přístup doporučovaný organizací Creative Commons a široce přijímaný na digitálních platformách. Název označuje název práce, na kterou se odkazuje, což pomáhá publiku identifikovat a najít konkrétní zdroj. Autor identifikuje tvůrce nebo držitele autorských práv, čímž určuje, kdo si zaslouží uznání a kdo vlastní práva k duševnímu vlastnictví. Zdroj uvádí místo, kde lze práci nalézt, obvykle URL nebo vydavatelský údaj, což umožňuje publiku získat přístup k původním materiálům nezávisle. Licence specifikuje podmínky, za kterých lze práci použít, což je obzvláště důležité pro obsah sdílený pod Creative Commons nebo jinými otevřenými licencemi. Kromě těchto základních prvků by efektivní přisuzování mělo zahrnovat data publikace pro doložení aktuálnosti a důvěryhodnosti, kvalifikace autora jako signál odbornosti a viditelné odkazy pro snadný přístup. Formát a prezentace přisuzování se liší podle média—psaný obsah používá citace v textu a seznamy literatury, digitální obsah těží z hypertextových odkazů a panelů zdrojů, zatímco multimédia vyžadují přisuzování v popisech, titulcích nebo překryvech. Výzkum University of North Carolina Libraries ukazuje, že komplexní přisuzování zahrnující všechny prvky TASL zvyšuje důvěru publika přibližně o 45 % ve srovnání s minimálním přisuzováním.
| Metoda přisuzování | Příklady platforem | Viditelnost | Generování návštěvnosti | Uživatelská zkušenost | Nejvhodnější pro |
|---|---|---|---|---|---|
| Prolinkované citace | Perplexity, Google AI Overviews, Microsoft Copilot | Vysoká – očíslované citace s URL | Výborná – proklikávací odkazy přivádějí návštěvnost | Jasné a akční | AI platformy využívající retrieval-augmented generation |
| Neprolinkované zmínky | ChatGPT (základní), Claude | Střední – viditelnost značky, ale bez odkazu | Žádná – pouze informovanost | Konverzační, ale omezené | Modely bez real-time vyhledávání |
| Odkazy v textu | Akademické práce, výzkumné zprávy | Střední – integrováno v textu | Minimální – vyžaduje ruční vyhledání | Profesionální a formální | Vědecký a technický obsah |
| Panely zdrojů | Perplexity, Google AI Mode | Vysoká – vyhrazená sekce rozhraní | Dobrá – organizované a dohledatelné | Organizované a přehledné | Transparentnost zdrojů |
| Implicitní přisuzování | Tradiční LLM, základní ChatGPT | Nízká – žádné explicitní uznání | Žádná – bez přímého přisuzování | Plynulé, ale neprůhledné | Obecná syntéza znalostí |
| Poznámky pod čarou/konec | Tradiční publikace, akademické psaní | Střední – vyžaduje navigaci čtenáře | Žádná – offline nebo ručně | Formální a detailní | Dlouhý psaný obsah |
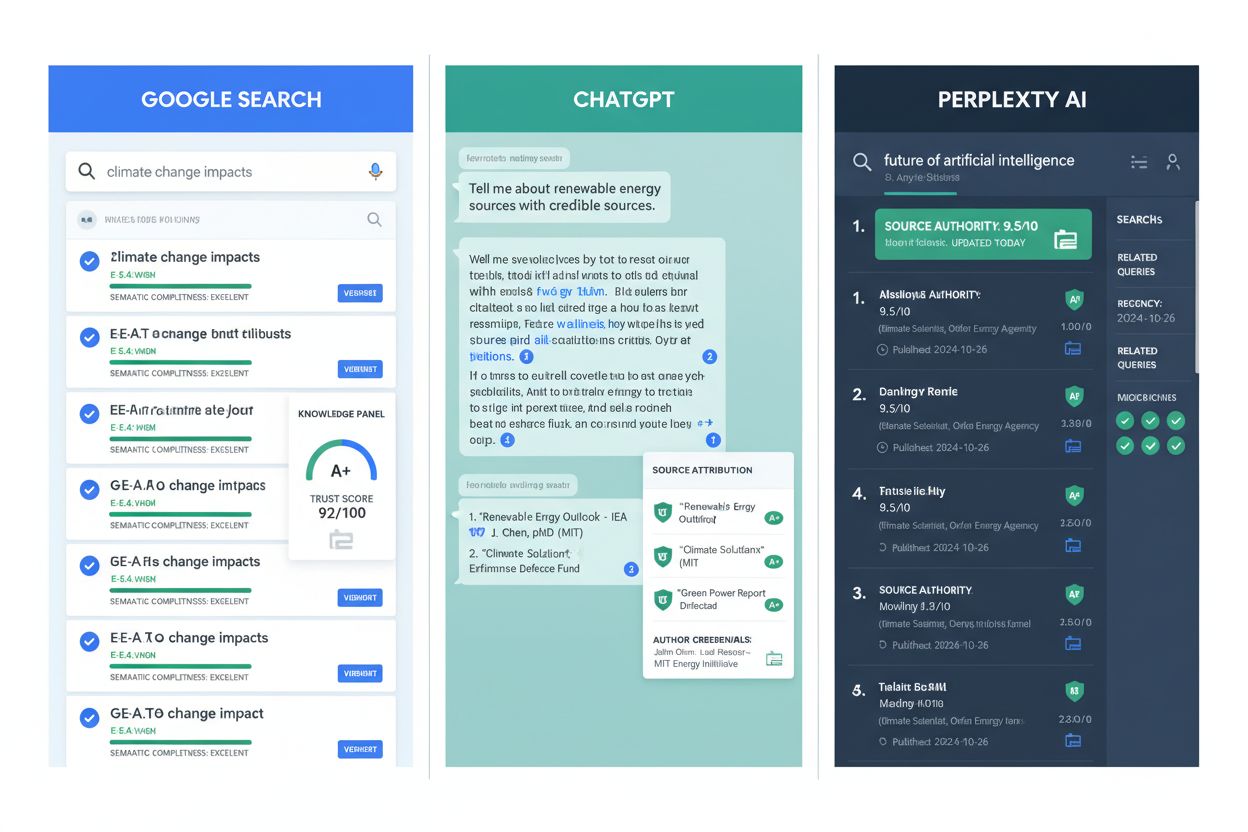
Technická implementace přisuzování zdrojů se výrazně liší napříč AI platformami v závislosti na architektuře a metodách získávání dat. Systémy s retrieval-augmented generation (RAG) jako Perplexity a Google AI Overviews mohou poskytovat explicitní citace, protože aktivně vyhledávají aktuální informace na webu a znají přesně ty URL, které načetly. Tyto systémy provádějí tzv. “query fan-out”, kdy spouštějí více vyhledávacích dotazů ke zpracovávanému tématu, následně syntetizují výsledky do komplexních odpovědí při zachování referencí zdrojů. Technickou výhodou RAG systémů je možnost sledovat původ informací během celého procesu generování a tím citovat konkrétní zdroje s URL i pozicí informace. Naproti tomu modely založené na trénování, jako základní ChatGPT a Claude, spoléhají na znalosti naučené při trénování, ne na aktuální vyhledávání. Tyto modely nemohou citovat konkrétní zdroje, protože jejich syntéza znalostí překrývá původní přisuzování—model si osvojil vzorce z trénovacích dat, ale neudržuje explicitní odkazy na zdrojové dokumenty. Tento rozdíl v architektuře vysvětluje, proč některé AI platformy poskytují bohaté přisuzování a jiné pouze implicitní nebo žádné. Vznik ChatGPT s vyhledáváním a podobných hybridních přístupů znamená posun k lepšímu přisuzování kombinací modelů s retrieval schopnostmi. Z technického hlediska vyžaduje efektivní přisuzování čistou HTML strukturu, rychlé načítání stránek, optimalizaci pro mobilní zařízení a strukturovaná data, která AI systémům usnadní spolehlivé vyhledání a citování obsahu.
Pro značky, vydavatele a tvůrce obsahu se přisuzování zdrojů vyvinulo z požadavku na soulad v obchodní strategické aktivum. V tradičním vyhledávacím prostředí určovala viditelnost pozice ve výsledcích—zobrazení na první stránce Google znamenalo návštěvnost a autoritu. V AI-vyhledávacím prostředí se přisuzování zdrojů stává hlavním mechanismem viditelnosti. Pokud Perplexity cituje váš výzkum nebo Google AI Overviews odkazuje na vaše srovnání produktů, získáváte třetí stranou potvrzenou autoritu, která ovlivňuje vnímání vaší důvěryhodnosti a odbornosti. Tento posun má zásadní dopady na obsahovou strategii a konkurenční postavení. Podle výzkumu Digiday z roku 2025 nyní přibližně 78 % podniků sleduje zmínky o své značce v AI-generovaných odpovědích, protože frekvence citací AI koreluje s povědomím o značce a jejím vlivem. Konkurence je výrazná: pokud vaši konkurenti získají citace u 60 % klíčových dotazů v kategorii, zatímco vy pouze u 20 %, čelíte významné krizi viditelnosti. Sledování citací je nezbytné pro pochopení tržního postavení a identifikaci optimalizačních příležitostí. Kromě viditelnosti přináší přisuzování zdrojů referral návštěvnost z AI platforem, i když aktuální objemy zůstávají menší ve srovnání s tradičním vyhledáváním. Nicméně s růstem využívání AI a větší závislostí uživatelů na AI systémech pro objevování informací potenciál návštěvnosti výrazně roste. Vydavatelé také zkoumají monetizační strategie kolem AI viditelnosti, využívají data o citacích k prokázání odbornosti a vlivu při nabízení partnerství či reklamních možností značkám, které hledají důvěryhodné umístění.
Efektivní přisuzování zdrojů vyžaduje systematický přístup napříč tvorbou obsahu, publikací i monitoringem. Tvůrci obsahu by měli zavést jasné zásady práce se zdroji tím, že ověří informace před publikací, dokumentují zdroje během výzkumu a vedou detailní záznamy o původu faktů a dat. Při psaní explicitně přisuzujte tvrzení jejich zdrojům jasnými formulacemi jako „Podle [zdroj]“, „Výzkum [organizace] zjistil“ nebo „Jak uvádí [publikace]“. U digitálního obsahu odkazujte zdroje hypertextovými odkazy pro možnost okamžitého přístupu k původním materiálům. Vydavatelé by měli vytvořit stylové manuály definující požadavky na přisuzování, proškolit týmy v přisuzovacích praktikách a nastavit redakční procesy ověřující správnost přisuzování před publikací. Technická implementace je zásadní—zajistěte rychlé načítání webu, optimalizaci pro mobilní zařízení, čistou HTML strukturu a strukturovaná data, která AI systémům pomohou objevit a citovat váš obsah. Zahrňte data publikace, údaje o autorech a jasné signály odbornosti, které AI systémům usnadní posouzení důvěryhodnosti. Struktura obsahu by měla podporovat extrahovatelnost—používejte jasné nadpisy, odrážky, srovnávací tabulky a FAQ formátování, které AI snadno zpracuje a ocituje. Monitoring a optimalizace vyžadují sledování, kde se váš obsah objevuje v AI-generovaných odpovědích, které platformy vás citují, pozici a frekvenci citací a zda citace obsahují proklikávací odkazy. Nástroje jako AmICited umožňují systematické sledování zmínek o značce napříč AI platformami, odhalují vzorce a optimalizační příležitosti.
Různé AI platformy implementují přisuzování zdrojů odlišně, což vytváří různé dopady na viditelnost a návštěvnost pro značky. Perplexity představuje zlatý standard přisuzování, zobrazující očíslované citace s proklikávacími odkazy na prominentním místě za generovanými odpověďmi. Uživatelé mohou snadno přistupovat ke zdrojům a rozhraní Perplexity klade důraz na transparentnost zdrojů. Být citován Perplexity obvykle generuje významnou referral návštěvnost a silné signály viditelnosti. Google AI Overviews (dříve SGE) zobrazuje zdroje ve vyhrazených panelech pod AI-generovanými odpověďmi, čímž poskytuje jasné přisuzování s odkazy. Pozice a výraznost citací v Google AI Overviews výrazně ovlivňují proklikovost, přičemž zdroje na prvním místě získávají nepoměrně více návštěvnosti. ChatGPT s vyhledáváním poskytuje citace, ale často v méně výrazné formě, zatímco základní ChatGPT neposkytuje explicitní přisuzování vůbec, místo toho syntetizuje informace bez uznání zdroje. Claude také spoléhá na znalosti z trénování bez real-time přisuzování. Microsoft Copilot nabízí citace ve stylu poznámek pod čarou podobné Perplexity. Porozumění těmto rozdílům je pro obsahovou strategii zásadní—optimalizace pro Perplexity vyžaduje jiné přístupy než optimalizace pro ChatGPT. Pro Perplexity a Google AI Overviews zvyšuje pravděpodobnost citace tvorba extrahovatelného, dobře strukturovaného obsahu s jasnými signály odbornosti. U modelů založených na trénování ovlivňuje zařazení do trénovacích dat doménová autorita získaná zpětnými odkazy, mediálním pokrytím a přítomností v znalostních bázích a tím i to, jak prominentně je váš obsah v modelových výstupech zastoupen.
Přisuzování zdrojů prochází zásadní proměnou, jak se AI systémy stávají sofistikovanějšími a běžnějšími při objevování informací. Trajektorie naznačuje několik důležitých trendů. Za prvé, pravděpodobně vznikne standardizace přisuzování díky snahám profesních organizací a platforem o jednotné rámce pro citování zdrojů AI systémy. V současnosti nedostatek standardizace způsobuje zmatek a nekonzistentnost—různé platformy citují odlišně, což organizacím ztěžuje komplexní optimalizaci. Za druhé, transparentnost přisuzování bude stále důležitější, protože regulátoři a uživatelé požadují jasnější přehled o tom, jak AI systémy používají a přisuzují zdroje. Evropský AI Act a podobné regulace začínají vyžadovat transparentnost ohledně trénovacích dat a využití zdrojů, což povede k explicitnějším přisuzovacím praktikám. Za třetí, monetizace přisuzování poroste, jak vydavatelé a tvůrci obsahu vyvinou obchodní modely založené na AI viditelnosti. Namísto čekání na referral návštěvnost budou organizace stále více využívat data o citacích k prokazování vlivu a vyjednávání partnerství, licenčních smluv nebo reklamních příležitostí. Za čtvrté, real-time sledování přisuzování se stane standardní praxí, kdy nástroje jako AmICited umožní organizacím nepřetržitě monitorovat zmínky o značce napříč AI platformami, odhalovat optimalizační příležitosti a reagovat na konkurenční hrozby. Za páté, metriky kvality přisuzování se posunou za hranici prostého počítání citací a budou měřit výraznost, pozici, stav odkazu a dopad na návštěvnost, což přinese nuancovanější pohled na hodnotu AI viditelnosti. A konečně, optimalizace obsahu pro přisuzování bude stejně sofistikovaná jako tradiční SEO, přičemž organizace budou vyvíjet specializované strategie pro zvýšení frekvence a výraznosti citací napříč různými AI platformami. Organizace, které ovládnou přisuzování zdrojů v AI prostředí, získají v tomto transformačním období objevování informací významné konkurenční výhody v oblasti viditelnosti, autority a důvěry publika.
Přisuzování zdrojů a citace jsou příbuzné, ale odlišné pojmy. Přisuzování dává uznání držiteli zdroje za použití jeho duševního vlastnictví a uznává, odkud informace pochází, zatímco citace konkrétně uvádí použité zdroje v díle pomocí formálních stylů, jako je APA nebo MLA. Přisuzování je širší a zaměřuje se na důvěryhodnost a respekt, zatímco citace sleduje specifická strukturální pravidla pro akademické a profesionální psaní. Oba pojmy jsou nezbytné pro etickou tvorbu obsahu a udržování důvěry publika.
Přisuzování zdrojů je pro AI platformy zásadní, protože určuje, zda mohou uživatelé ověřit informace, získat přístup k původním zdrojům a porozumět důvěryhodnosti generovaných odpovědí. Platformy jako Perplexity zobrazují očíslované citace s proklikávacími odkazy, zatímco ChatGPT často poskytuje odpovědi bez explicitního přisuzování. Pro značky a vydavatele představuje citace AI systémy nový metr viditelnosti a zdroj návštěvnosti, což činí sledování přisuzování zásadním pro pochopení AI-driven objevování a udržení autority značky v AI-vyhledávacím prostředí.
Hlavní metody přisuzování zdrojů zahrnují citace v textu (vložené informace o zdroji v rámci obsahu), hypertextové odkazy na původní zdroje, poznámky pod čarou nebo na konci a panely zdrojů zobrazující konzultované materiály. Rámec TASL (Název, Autor, Zdroj, Licence) představuje komplexní přístup k přisuzování. Vhodná metoda závisí na typu a médiu obsahu—psaný obsah typicky používá citace v textu, zatímco digitální obsah těží z hypertextových odkazů a multimédia vyžadují uvedení zdrojů v popisech nebo titulcích.
Přisuzování zdrojů výrazně zvyšuje důvěryhodnost značky tím, že demonstruje důkladný výzkum, etické postupy a respekt k duševnímu vlastnictví. Pokud značky správně přisuzují zdroje, publikum je vnímá jako transparentní a důvěryhodné, což posiluje vztahy a buduje autoritu. Naopak nesprávné přisuzování zdrojů poškozuje pověst, vytváří právní rizika a eroduje důvěru publika. Studie ukazují, že transparentní praxe se zdroji zvyšuje důvěru publika v obsah a zlepšuje vnímání značky napříč digitálními i tradičními médii.
Nesprávné přisuzování zdrojů může vést k nárokům z porušení autorských práv, právní odpovědnosti a finančním sankcím. Kromě právních důsledků poškozuje nesprávné přisuzování pověst značky, vede ke ztrátě důvěry publika a může poškodit profesní vztahy. Firmy, které používají cizí práci bez přisuzování, čelí negativní publicitě a mohou být vyloučeny z budoucích spoluprací. Kromě toho obsah bez přisuzování porušuje etické standardy a může být odstraněn z platforem, což dále snižuje viditelnost a důvěryhodnost.
Organizace mohou optimalizovat přisuzování v AI tím, že vytvoří jasnou autoritu entity prostřednictvím konzistentního pojmenování a ověřování, vytvářením strukturovaných částí obsahu jako jsou souhrny a srovnávací tabulky a zahrnutím signálů původu, jako jsou data publikace a kvalifikace autora. Poskytování původního výzkumu, proprietárních dat a unikátních poznatků zvyšuje pravděpodobnost citací. Důležitá je i technická přístupnost—rychlost načítání stránek, optimalizace pro mobily a čistá HTML struktura zajišťují, že AI systémy mohou obsah efektivně najít a citovat.
Přisuzování zdrojů je hlavním mechanismem, díky kterému značky získávají viditelnost v AI-generovaných odpovědích. Sledování citací monitoruje, kde, jak a proč se obsah značky objevuje jako zdroj v AI odpovědích na platformách jako ChatGPT, Perplexity a Google AI Overviews. Přisuzování určuje, zda citace obsahují proklikávací odkazy (přivádějící návštěvnost) nebo pouze nezalinkované zmínky (pouze informovanost). Pochopení vzorců přisuzování pomáhá organizacím měřit AI viditelnost, identifikovat konkurenční postavení a optimalizovat obsahové strategie pro AI objevování.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte, jak AI systémy hodnotí důvěryhodnost zdrojů prostřednictvím odbornosti autorů, citací a ověření. Pochopte technické mechanismy, klíčové faktory a nejl...
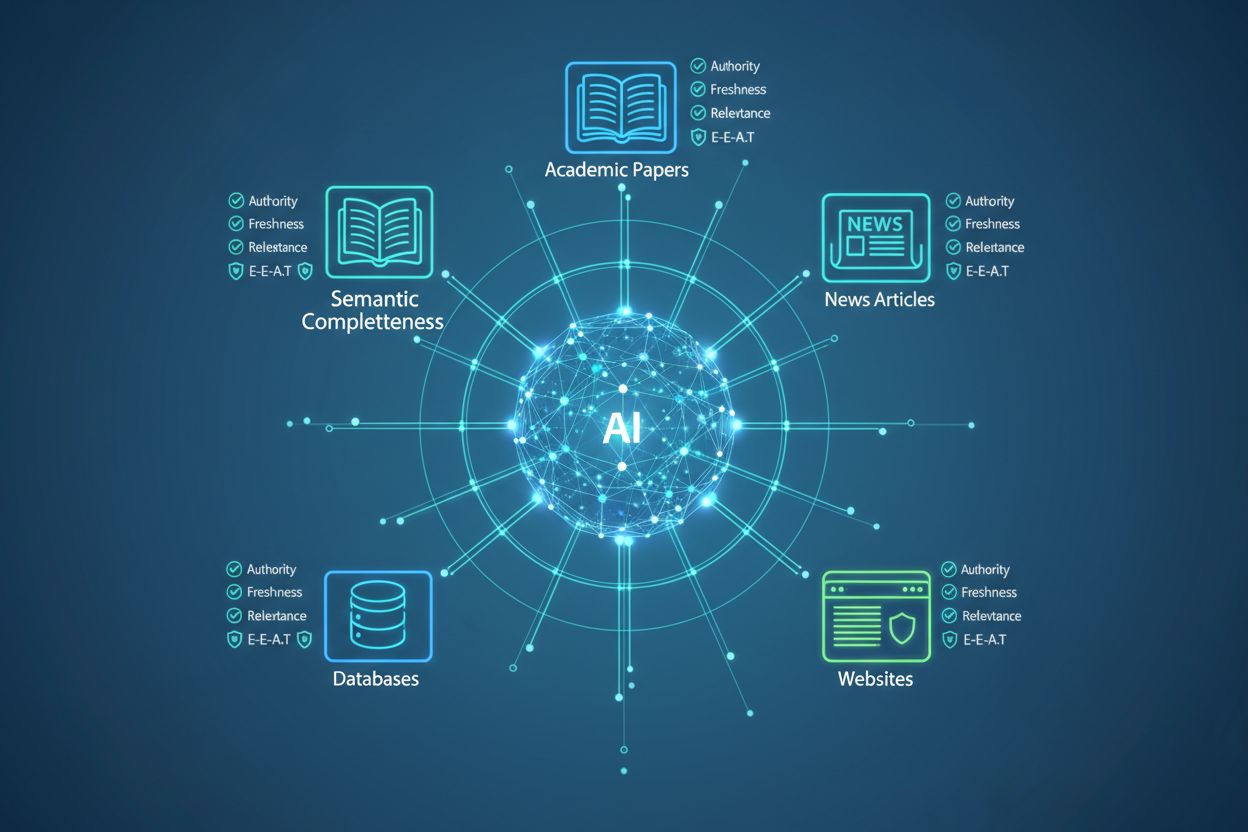
Zjistěte, jak AI systémy vyhodnocují a hodnotí zdroje pro citace. Objevte 7 klíčových signálů hodnocení včetně autority, aktuálnosti, relevance a E-E-A-T, které...

Naučte se, jak identifikovat, vyhledávat, hodnotit a začleňovat důvěryhodné zdroje do svého obsahu. Objevte osvědčené postupy pro citování zdrojů, vyhýbání se p...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.