
Sådan håndterer du dobbelt indhold for AI-søgemaskiner
Lær hvordan du håndterer og forhindrer dobbelt indhold, når du bruger AI-værktøjer. Opdag kanoniske tags, omdirigeringer, detektionsværktøjer og bedste praksis ...
12 min læsning

Lær hvordan kanoniske URL’er forhindrer problemer med dubleret indhold i AI-søgesystemer. Oplev bedste praksis for implementering af kanoniske tags for at forbedre AI-synlighed og sikre korrekt indholdsattribution.
Store sprogmodeller og AI-søgesystemer anvender sofistikerede klyngealgoritmer til at identificere og gruppere næsten-identiske URL’er og behandler flere versioner af det samme indhold som én enhed med henblik på rangering og citat. Når AI-systemer støder på dubleret indhold, skal de vælge, hvilken version de vil prioritere—en beslutning, der direkte påvirker, hvilken URL der opnår synlighed, autoritetssignaler og bruger-attribution. Det kritiske problem opstår, når AI vælger den forkerte version: hvis din kanoniske URL peger på den foretrukne side, men AI-systemet grupperer og rangerer en dublet af lavere kvalitet i stedet, mister dit indhold synlighed og citat-kredit. Intent-signaler bliver udvandet på tværs af dublette versioner, hvilket fragmenterer den autoritet, der burde samles på en enkelt URL, og får hver dublet til at modtage svagere rangering end hvis al autoritet var samlet på den kanoniske version.
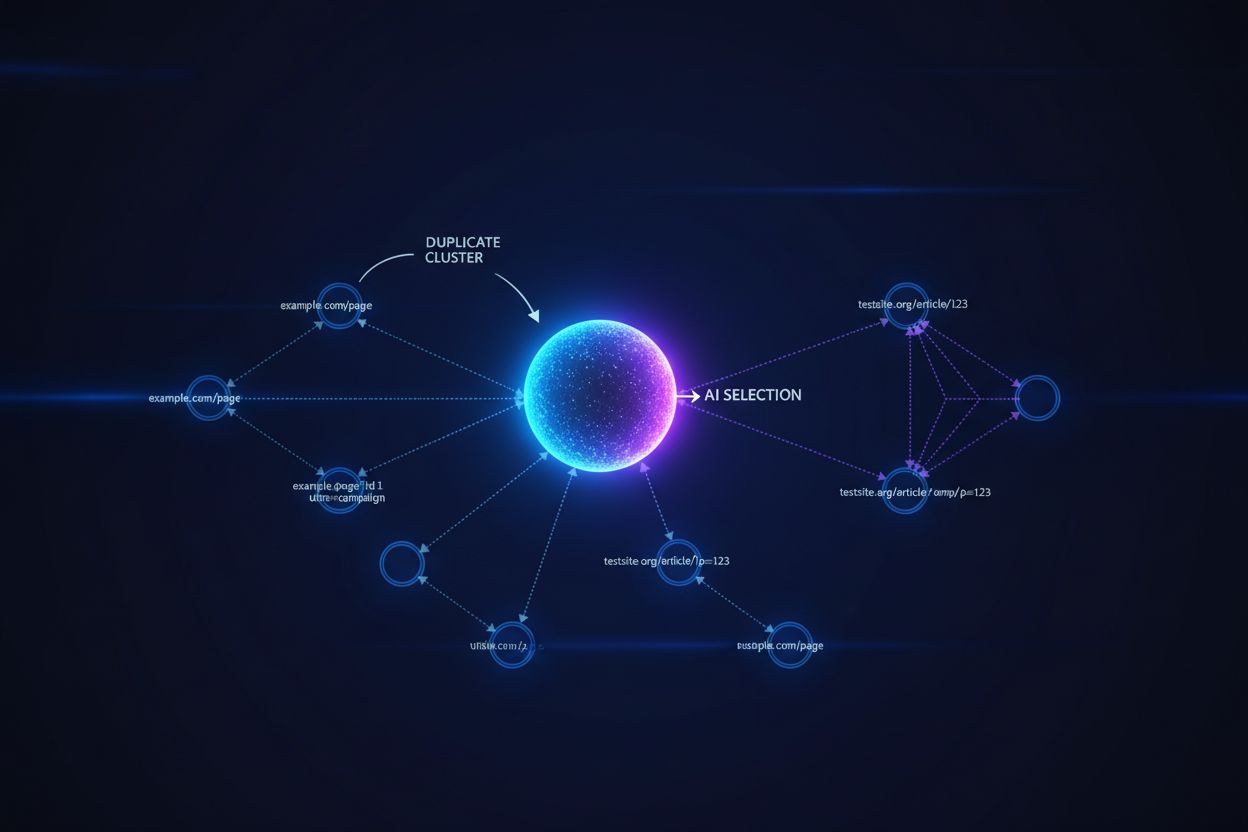
Kanoniske tags fungerer som eksplicitte signaler til AI-systemer om, hvilken version af dubleret indhold der skal betragtes som autoritativ, hvilket direkte påvirker, om din foretrukne URL vises i AI-genererede svar og modtager korrekt attribution. Uden kanoniske tags skal AI-systemer selv træffe beslutning om gruppering baseret på indholdslighed, linkmønstre og friskhedssignaler—hvilket ofte resulterer i, at den forkerte version udvælges som kanonisk kilde. Når dubleret indhold eksisterer uden korrekt kanonisk implementering, kan AI-svar citere en syndikeret version, en cachet kopi eller en variant af lavere kvalitet i stedet for dit originale indhold, hvilket fragmenterer din synlighed på tværs af flere URL’er. Kanoniske URL’er sikrer, at når AI-systemer støder på dit indhold på tværs af forskellige domæner, parametre eller versioner, forstår de, hvilken enkelt URL der skal have kredit og fremhæves i svar.
| Scenarie | Uden kanonisk | Med kanonisk |
|---|---|---|
| Påvirkning på AI | AI grupperer dubletter uafhængigt; kan vælge forkert version til rangering | AI genkender én autoritativ kilde; konsoliderer alle signaler til kanonisk URL |
| Citat-kredit | Attribution spredt på flere URL’er; svagere autoritet pr. URL | Alle citater og autoritet flyder til kanonisk URL; stærkere synlighed |
| Resultat | Indhold vises i AI-svar, men forkert URL får kredit; fragmenteret synlighed | Foretrukken URL vises i AI-svar med konsoliderede autoritetssignaler |
Kanoniske tags og redirects tjener forskellige formål i håndtering af dubleret indhold for AI-systemer: kanoniske tags fortæller søgemaskiner og AI-systemer, hvilken version der foretrækkes, mens begge URL’er forbliver tilgængelige, mens redirects permanent sender brugere og crawlere fra én URL til en anden. Redirects (301 for permanente, 302 for midlertidige) er stærkere signaler, fordi de konsoliderer al autoritet i én URL og fjerner dubletten helt fra nettet, hvilket gør dem ideelle, når du permanent nedlægger en URL eller konsoliderer domæner. Kanoniske tags er at foretrække, når du skal opretholde flere URL’er af forretningsmæssige årsager—såsom sporingsparametre for analyse, opretholdelse af ældre URL’er til bogmærker, eller forskellige versioner til forskellige målgrupper—og samtidig signalere til AI-systemer, hvilken version der er autoritativ. Brug redirects, når du konsoliderer domæner efter en migration, fjerner forældede versioner eller eliminerer parameter-variationer, der ikke tjener et særskilt formål. Brug kanoniske tags, når du skal opretholde flere URL’er, men ønsker at undgå straf for dubleret indhold og sikre, at AI-systemer forstår din foretrukne version.
Væsentlige forskelle mellem kanoniske tags og redirects:
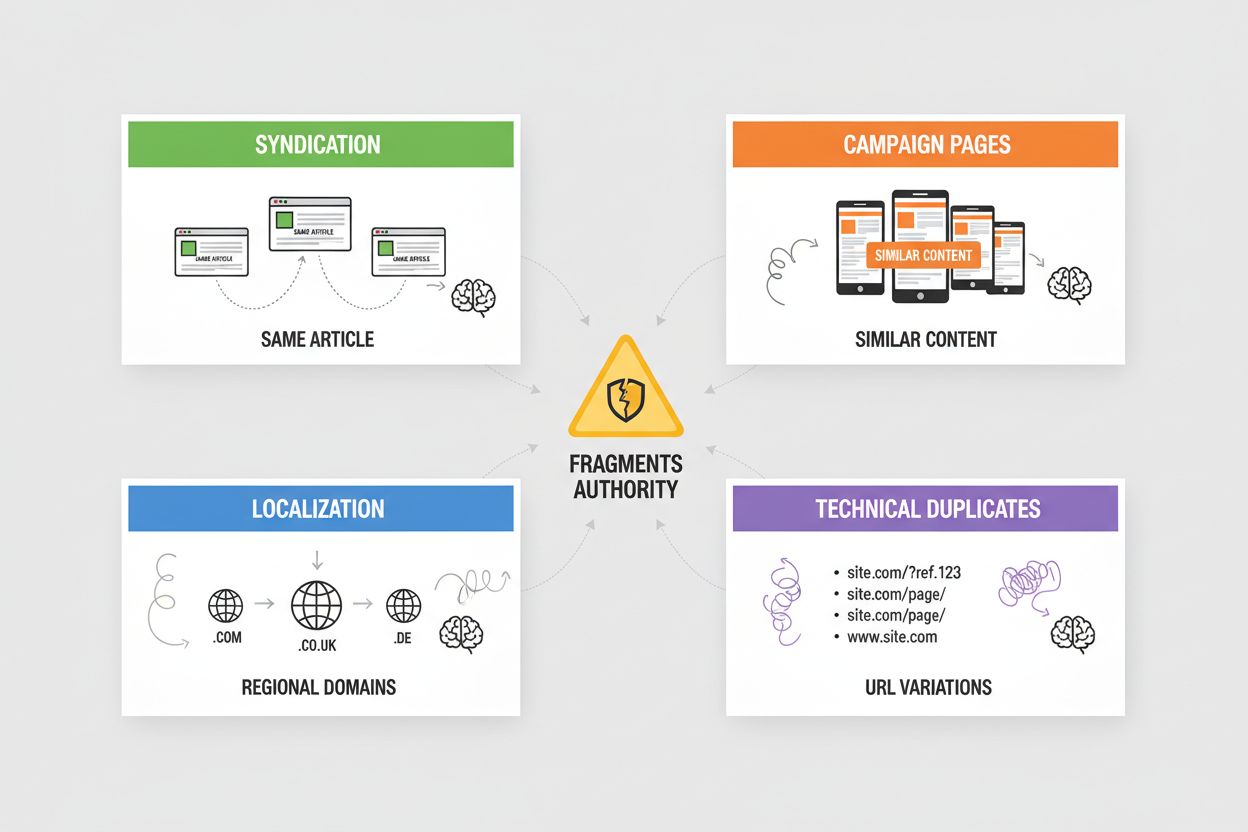
Syndikering skaber udbredt dubleret indhold, når dine artikler genpubliceres på partnerwebsites, nyhedsaggregatorer eller indholdsnetværk—AI-systemer skal afgøre, om de skal kreditere den originale kilde eller den syndikerede version, og vælger ofte den, de først finder i deres crawl. Kampagnesider genererer dubletter, når du opretter flere landingssider med identisk eller næsten identisk indhold til forskellige marketingkanaler, UTM-parametre eller A/B-test, hvilket får AI-systemer til at fragmentere autoritet på tværs af variationer, der burde konsolideres. Lokalisering og internationalisering skaber dubletter, når du serverer lignende indhold på tværs af regionale domæner (example.com, example.co.uk, example.de) eller sprogversioner, hvilket kræver hreflang-tags og kanonisk implementering for at forhindre, at AI-systemer behandler disse som dubleret indhold frem for tilsigtede variationer. Tekniske dubletter opstår fra sessions-id’er, sporingsparametre, udskriftsvenlige versioner og URL-variationer (www vs. non-www, http vs. https, skråstreger), der skaber flere URL’er til identisk indhold—AI-systemer ser disse som dubletter og skal afgøre, hvilken version de vil prioritere. Hver af disse scenarier udvander den autoritet, der burde koncentreres på din foretrukne URL, reducerer din synlighed i AI-genererede svar og får citat-kredit til at sprede sig over flere versioner.
Brug altid absolutte URL’er i dine kanoniske tags frem for relative URL’er for at sikre, at AI-systemer og søgemaskiner utvetydigt kan identificere mål-URL’en, uanset hvor tagget vises. Inkludér selvrefererende kanoniske tags på dine foretrukne sider—selv sider uden dubletter bør henvise til sig selv som kanonisk for at forhindre, at AI-systemer udleder kanonikaler baseret på linkmønstre eller indholdslighed. Placer kanoniske tags i <head>-sektionen af dit HTML-dokument, og for ikke-HTML-indhold (PDF’er, billeder) implementér kanoniske tags via HTTP-headere for at sikre, at AI-crawlere genkender din præference uanset indholdstype.
<!-- Korrekt kanonisk implementering i HTML-head -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
Inkludér kanoniske URL’er i dine XML-sitemaps for at forstærke, hvilke versioner der er autoritative, og kombiner kanoniske tags med hreflang-tags, når du håndterer internationalt eller lokaliseret indhold for at forhindre, at AI-systemer behandler regionale variationer som dubletter. Undgå almindelige fejl: lav aldrig kæder af kanoniske tags (A→B→C), peg aldrig kanoniske tags på noindexed sider, og brug aldrig kanoniske tags til at manipulere rangeringer ved at pege på ikke-relateret indhold. Overvåg din kanoniske implementering med værktøjer som Google Search Console, Bing Webmaster Tools og AmICited.com for at verificere, at AI-systemer genkender dine foretrukne URL’er og tilskriver indholdet korrekt.
<!-- Korrekt implementering med hreflang for internationalt indhold -->
<link rel="canonical" href="https://example.com/article/canonical-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/article/canonical-urls-ai" />
<link rel="alternate" hreflang="de" href="https://example.de/artikel/canonical-urls-ai" />
Auditér dine kanoniske URL’er ved at crawle hele dit site med værktøjer som Screaming Frog, SEMrush eller Ahrefs for at identificere sider med manglende kanoniske tags, brudte kanoniske kæder eller kanoniske tags, der peger på noindexed sider—disse problemer forhindrer AI-systemer i at konsolidere autoritet korrekt. Brug Google Search Console’s Coverage-rapport til at identificere sider med dubleret indhold og verificere, at Google genkender dine kanoniske præferencer, og krydstjek med Bing Webmaster Tools for at sikre konsistens på tværs af AI-søgesystemer. Implementér IndexNow for straks at underrette søgemaskiner og AI-crawlere, når du tilføjer, opdaterer eller fjerner kanoniske tags, hvilket fremskynder opdagelsen af dine kanoniske præferencer frem for at vente på naturlige crawl-cyklusser. Overvåg AI-citater med værktøjer som AmICited.com og manuelle søgninger i ChatGPT, Claude og Perplexity for at sikre, at dine foretrukne URL’er får attribution i AI-genererede svar—hvis dubletter bliver citeret i stedet, gennemgå din kanoniske implementering igen og sørg for, at tags er korrekt formateret og placeret. Auditér regelmæssigt for nyt dubleret indhold skabt gennem syndikeringspartnerskaber, kampagnelanceringer eller tekniske ændringer, og implementér kanoniske tags proaktivt frem for reaktivt for at opretholde konsekvent AI-synlighed.
En kanonisk URL er den foretrukne version af en side, som du ønsker, at søgemaskiner og AI-systemer skal genkende som autoritativ. Det er vigtigt for AI-søgning, fordi LLM'er grupperer næsten-identiske URL'er og vælger én version til at repræsentere sættet. Uden korrekt implementering af kanoniske tags kan AI-systemer citere den forkerte version af dit indhold, hvilket fragmenterer din synlighed og attribution på tværs af flere URL'er.
AI-systemer bruger klyngealgoritmer til at gruppere næsten-identiske URL'er i enkelt-enheder og vælger derefter én version til at repræsentere hele klyngen. Dette adskiller sig fra traditionelle søgemaskiner, fordi AI-svar kræver en enkelt kilde-URL til attribution. Hvis din kanoniske ikke er korrekt implementeret, kan AI vælge en syndikeret version, cachet kopi eller en variant af lavere kvalitet i stedet for din foretrukne URL.
Brug kanoniske tags, når du har brug for at opretholde flere URL'er af forretningsmæssige årsager (sporingsparametre, ældre URL'er, forskellige målgrupper) og samtidig signalere præference til AI-systemer. Brug redirects, når du permanent nedlægger en URL, konsoliderer domæner eller fjerner parameter-variationer, der ikke tjener et formål. Redirects er stærkere signaler, fordi de fuldt ud konsoliderer autoritet, mens kanoniske tags fordeler autoriteten, men signalerer præference.
De mest almindelige problemer er: syndikering (genpublicerede artikler på partnerwebsites), kampagnesider (flere landingssider med identisk indhold), lokalisering (lignende indhold på tværs af regionale domæner) og tekniske dubletter (URL-parametre, sessions-id'er, skråstreger). Hver af disse fragmenterer autoritet på tværs af flere URL'er, hvilket reducerer synligheden i AI-genererede svar.
Brug altid absolutte URL'er (https://example.com/page, ikke /page), placer kanoniske tags i HTML-head sektionen, inkludér selvrefererende kanoniske tags på alle sider, og undgå kanoniske kæder (A→B→C). For ikke-HTML-indhold som PDF'er, brug HTTP-headere. Inkludér kanoniske tags i dit XML-sitemap og par dem med hreflang-tags for internationalt indhold.
Brug Google Search Console og Bing Webmaster Tools til at verificere kanonisk genkendelse, overvåg AI-citater med AmICited.com og manuelle søgninger i ChatGPT/Claude/Perplexity, og auditér dit website med crawl-værktøjer som Screaming Frog eller SEMrush. Hvis dubletter bliver citeret i stedet for din kanoniske, så gennemgå din implementering igen og sørg for, at tags er korrekt formateret og placeret i HTML-head.
IndexNow er en protokol, der straks giver besked til søgemaskiner og AI-crawlere, når du tilføjer, opdaterer eller fjerner kanoniske tags, i stedet for at vente på naturlige crawl-cyklusser. Dette fremskynder opdagelsen af dine kanoniske præferencer og hjælper med at sikre, at AI-systemer hurtigere genkender dine foretrukne URL'er, hvilket reducerer den tid, dubletter vises i AI-svar.
Ja, kanoniske tags er stærke signaler, men ikke direktiver. AI-systemer kan tilsidesætte din kanoniske præference, hvis de vurderer, at en anden version er mere autoritativ baseret på indholdskvalitet, linkmønstre, friskhed eller andre signaler. Derfor er korrekt implementering kombineret med stærkt indhold og autoritetssignaler vigtigt—det øger sandsynligheden for, at AI-systemer respekterer din kanoniske præference.
Følg med i, hvordan AI-systemer som ChatGPT, Claude og Perplexity citerer dit indhold. Sikr dig, at dine kanoniske URL'er bliver korrekt genkendt, og at dit brand modtager korrekt attribution i AI-genererede svar.
Lær hvordan du håndterer og forhindrer dobbelt indhold, når du bruger AI-værktøjer. Opdag kanoniske tags, omdirigeringer, detektionsværktøjer og bedste praksis ...
Fællesskabsdiskussion om, hvordan AI-systemer håndterer duplikeret indhold anderledes end traditionelle søgemaskiner. SEO-professionelle deler indsigt om indhol...

Dubleret indhold er identisk eller lignende indhold på flere URL'er, som forvirrer søgemaskiner og udvander autoriteten. Lær, hvordan det påvirker SEO, AI-synli...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.