
So lehnen Sie das KI-Training auf großen Plattformen ab
Vollständiger Leitfaden zum Ablehnen der Datensammlung für KI-Training auf ChatGPT, Perplexity, LinkedIn und anderen Plattformen. Erfahren Sie Schritt-für-Schri...
8 Min. Lesezeit

Erfahren Sie, woher ChatGPT seine Trainingsdaten bezieht, wie es Quellen zitiert, zu welchen Zeitpunkten das Wissen begrenzt ist und warum die Überwachung von KI-Zitaten für Ihre Marke wichtig ist.
Die Wissensbasis von ChatGPT basiert auf einer vielfältigen Sammlung öffentlich verfügbarer Internetdaten, kombiniert mit lizenzierten Datensätzen und der Verfeinerung durch menschliches Feedback. Das Modell wurde auf drei Hauptquellen trainiert: öffentlich verfügbare Internetdaten (Webseiten, Artikel und Online-Inhalte), lizenzierte Datensätze (einschließlich Bücher und wissenschaftlicher Publikationen) und menschliches Feedback von Trainern, die bei der Verbesserung der Antworten halfen. Diese Trainingsdaten umfassen eine außerordentlich breite Palette von Quellen, darunter Nachrichtenwebsites, Fachzeitschriften, Bücher, technische Dokumentationen, Foren wie Reddit und Stack Overflow, Wikipedia-Artikel und unzählige weitere öffentlich zugängliche Webseiten. Das enorme Volumen und die Vielfalt dieser Quellen – über viele Sprachen, Fachgebiete und Perspektiven hinweg – schaffen eine umfassende Wissensbasis, die es ChatGPT ermöglicht, Themen von Quantenphysik über mittelalterliche Geschichte bis hin zu zeitgenössischer Popkultur zu diskutieren. Es ist jedoch wichtig zu verstehen, dass ChatGPT keinen Zugang zu Echtzeitinformationen oder proprietären Datenbanken hat; es kann nur auf das zugreifen, was während seines Trainingszeitraums verfügbar war.
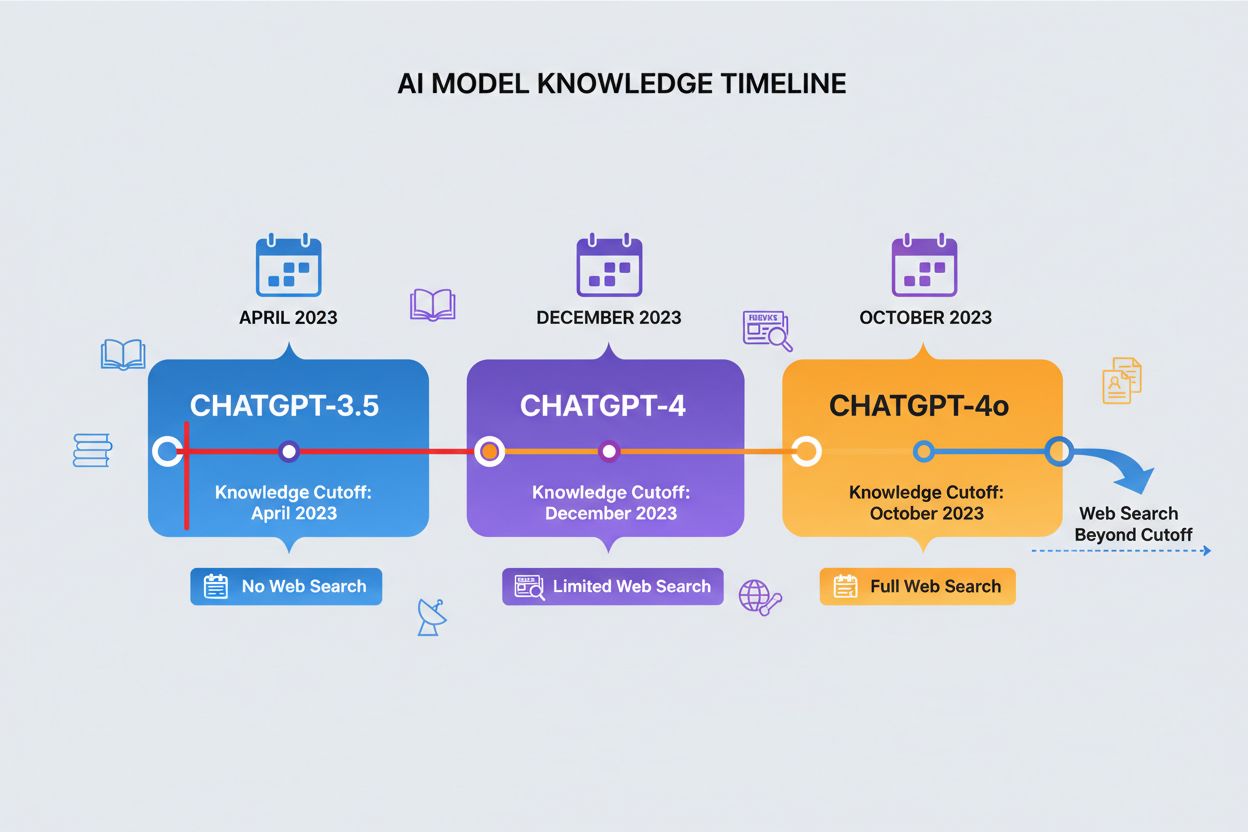
Ein Wissensstichtag bezeichnet den Zeitpunkt, nach dem ChatGPT keine Trainingsdaten mehr besitzt, und stellt eine feste Grenze für die zugänglichen Informationen dar. Unterschiedliche Versionen von ChatGPT haben verschiedene Stichtage: ChatGPT-4 wurde bis Dezember 2023 trainiert, während ChatGPT-4o (die optimierte Version) einen Wissensstichtag im Oktober 2023 hat. Diese Stichtage beeinflussen die Genauigkeit und Relevanz der Antworten maßgeblich, insbesondere bei aktuellen Ereignissen, neu veröffentlichten Studien oder Statistiken, die sich seit der Datensammlung geändert haben könnten. Einige neuere Versionen von ChatGPT können Websuchen durchführen, um aktuelle Informationen über die Stichtage hinaus zu erhalten, wobei diese Funktion jedoch nicht in allen Versionen oder Kontexten verfügbar ist. Das Verständnis des jeweiligen Wissensstichtags ist für Nutzer, die aktuelle Informationen benötigen, entscheidend, da ChatGPT keine präzisen Antworten zu Ereignissen oder Entwicklungen geben kann, die nach dem Trainingszeitraum stattgefunden haben. Diese Einschränkung ist einer der wichtigsten Faktoren bei der Bewertung der Zuverlässigkeit von ChatGPT für zeitkritische Anfragen.
| ChatGPT-Version | Wissensstichtag | Websuche möglich | Haupteinsatzgebiet |
|---|---|---|---|
| ChatGPT-4 | Dezember 2023 | Eingeschränkt | Allgemeines Wissen, Analyse, Schlussfolgerungen |
| ChatGPT-4o | Oktober 2023 | Verfügbar | Optimierte Leistung, multimodale Aufgaben |
| ChatGPT-3.5 | April 2023 | Nein | Grundlegende Anfragen, kostengünstige Option |
| ChatGPT mit Browsing | Echtzeit | Ja | Aktuelle Ereignisse, neue Forschung |
Im Gegensatz zu Suchmaschinen, die konkrete Dokumente oder Webseiten abrufen, generiert ChatGPT Antworten, indem es während des Trainings gelernte Muster synthetisiert – ein grundlegend anderer Ansatz. Wenn Sie ChatGPT eine Frage stellen, durchsucht es keine Datenbank oder einen Index, sondern verwendet statistische Muster aus seinen Trainingsdaten, um die wahrscheinlichste Wortfolge für eine hilfreiche Antwort vorherzusagen. Dieser generative Ansatz bedeutet, dass ChatGPT Informationen aus mehreren Quellen seiner Trainingsdaten kombiniert, um neue Antworten zu erstellen, die so möglicherweise nirgendwo wortwörtlich existieren. Das Modell lernt im Wesentlichen die Beziehungen zwischen Konzepten, Fakten und Ideen und rekonstruiert dieses Wissen für Ihre spezifische Anfrage. Dieser Prozess hat jedoch einen erheblichen Nachteil: Wenn das Modell unsicher ist oder wenn die Muster in den Trainingsdaten widersprüchlich oder lückenhaft sind, kann es plausibel klingende, aber falsche Informationen erzeugen – ein Phänomen, das als „Halluzination“ bezeichnet wird. Neuere Versionen von ChatGPT, die Websuche-Funktionalität integrieren, können diesen Prozess ergänzen, indem sie aktuelle Informationen aus dem Internet abrufen. Diese Funktion erfordert jedoch eine explizite Aktivierung und ist nicht auf allen Plattformen verfügbar.
Die Trainingsdaten von ChatGPT stammen aus mehreren wichtigen Quellenkategorien, von denen jede einen eigenen Beitrag zur Wissensbasis leistet:
Die Bedeutung dieser vielfältigen Quellen liegt in ihren sich ergänzenden Stärken: Wissenschaftliche Arbeiten bieten Strenge, Nachrichtenartikel Aktualität, Bücher Tiefe und Foren praktische Anwendung. Allerdings variiert die Qualität der Quellen stark – eine peer-reviewte wissenschaftliche Publikation hat mehr Gewicht als ein beliebiger Blogpost, doch ChatGPT unterscheidet im Trainingsprozess nicht explizit zwischen ihnen. Das bedeutet, ChatGPTs Wissen spiegelt sowohl hochwertige, autoritative Quellen als auch weniger zuverlässige oder potenziell irreführende Inhalte wider. Daher bleibt die Überprüfung beim Einsatz des Modells für wichtige Entscheidungen unerlässlich.
Nach dem anfänglichen Training mit großen Mengen Textdaten setzte OpenAI eine Technik namens Reinforcement Learning from Human Feedback (RLHF) ein, um die Antworten von ChatGPT zu verfeinern. In diesem Prozess bewerteten menschliche Trainer die Modellausgaben und gaben Feedback, wodurch das System lernte, welche Antworten hilfreicher, genauer und besser an menschliche Werte angepasst sind. Diese Trainer überprüften jedoch nicht jede Aussage auf Faktenrichtigkeit, sondern beurteilten die Gesamtqualität, Hilfsbereitschaft und Sicherheit der Antworten, was indirekt beeinflusste, wie das Modell Informationen priorisiert und präsentiert. Der RLHF-Prozess beeinflusst maßgeblich, welche Informationen in Antworten betont werden und wie Themen dargestellt werden – menschliches Urteil wird so in ein ansonsten rein statistisches Modell eingebracht. Dennoch hat dieser Feedback-Prozess inhärente Grenzen: Trainer haben eigene Vorurteile, Wissenslücken und können nicht die Genauigkeit jeder Aussage aus allen Fachgebieten bewerten. Außerdem ist der Prozess ressourcenintensiv und kann nur auf einen Bruchteil aller möglichen Modellausgaben angewendet werden, sodass ein Großteil des Verhaltens von ChatGPT weiterhin die Rohmuster der Trainingsdaten widerspiegelt und nicht explizite menschliche Auswahl.
Die Zitierung von ChatGPT ist für wissenschaftliche Integrität und Transparenz wichtig, damit Leser nachvollziehen können, woher Informationen stammen und Ihre Erkenntnisse ggf. überprüfen können. Die Zitierweise hängt vom jeweiligen Stil ab, hier die gängigsten Ansätze:
MLA-Format Beispiel:
OpenAI. "ChatGPT." Zugriff am [Datum], https://chat.openai.com.
Im MLA-Stil zitieren Sie ChatGPT wie eine Website und fügen das Zugriffsdatum hinzu, da sich die Inhalte dynamisch ändern können. Wenn Sie eine bestimmte Antwort zitieren, sollten Sie das Zugriffsdatum und idealerweise die gestellte Frage (Prompt) angeben.
APA-Format Beispiel:
OpenAI. (2024). ChatGPT (Version 4) [Großes Sprachmodell].
Abgerufen von https://chat.openai.com
Im APA-Stil wird ChatGPT als Software-Tool oder Anwendung behandelt, mit Angabe der Versionsnummer und des Abrufdatums. Manche APA-Richtlinien empfehlen, den konkreten Prompt als Zitat oder als Anmerkung aufzuführen.
Wann sollte man ChatGPT zitieren: Sie sollten das Tool immer dann zitieren, wenn Sie seine Ausgaben in wissenschaftlichen Arbeiten, professionellen Berichten oder überall dort verwenden, wo die Quellenangabe relevant ist. Dokumentieren Sie den exakten Prompt, das Zugriffsdatum und idealerweise die Version von ChatGPT, da diese Angaben die Nachvollziehbarkeit beeinflussen. Der entscheidende Unterschied zur klassischen Quellenangabe besteht darin, dass ChatGPT-Antworten dynamisch erzeugt werden – derselbe Prompt kann zu unterschiedlichen Zeiten unterschiedliche Ausgaben liefern. Daher wird das Zitieren des Prompts selbst Teil der korrekten Zitierpraxis. Viele Institutionen entwickeln noch formale Richtlinien für KI-Zitate, daher sollten Sie sich bei Ihrer Organisation oder Publikation nach den bevorzugten Vorgaben erkundigen.
So leistungsfähig ChatGPT auch ist, es gibt deutliche Einschränkungen, die die Verlässlichkeit seiner Informationen betreffen. ChatGPT kann mit Überzeugung falsche Informationen liefern, ein Problem, das als Halluzination bezeichnet wird – vor allem bei obskuren Themen, aktuellen Ereignissen nach dem Wissensstichtag oder bei widersprüchlichen Trainingsdaten. Die Trainingsdaten des Modells enthalten inhärente Verzerrungen, die die in den Quellen vorhandenen Perspektiven, demografischen Merkmale und Ansichten widerspiegeln. Das kann dazu führen, dass Antworten unbeabsichtigt bestimmte Sichtweisen bevorzugen oder Stereotype enthalten. Informationen in den Trainingsdaten von ChatGPT veralten mit der Zeit, was es für aktuelle Statistiken, neue Forschungsergebnisse oder sich entwickelnde Situationen unzuverlässig macht. Aus diesen Gründen ist es unerlässlich, die Aussagen von ChatGPT zu überprüfen, besonders bei wichtigen Entscheidungen – prüfen Sie zentrale Fakten anhand von Primärquellen, aktuellen Publikationen und autoritativen Datenbanken. Um Aussagen von ChatGPT zu verifizieren, vergleichen Sie sie mit mehreren unabhängigen Quellen, überprüfen Sie Daten und Statistiken auf Aktualität und seien Sie besonders vorsichtig bei spezifischen Zahlen, Namen oder aktuellen Ereignissen. Bedenken Sie abschließend, dass ChatGPT keine Primärquelle ist – es ist eine sekundäre Quelle, die Informationen anderer Quellen zusammenfasst. Für wissenschaftliche oder professionelle Arbeiten sollten daher die Originalquellen zitiert werden, auf die sich ChatGPT bezieht, nicht ChatGPT selbst.
Da ChatGPT und andere KI-Systeme zunehmend in die Informationssuche der Menschen integriert werden, ist es entscheidend, die Erwähnungen und Zitate Ihrer Marke oder Organisation in diesen Systemen zu überwachen. AmICited ist eine Monitoring-Plattform für KI-Antworten, die speziell darauf ausgelegt ist, wie ChatGPT, Claude und andere große Sprachmodelle Ihr Unternehmen, Ihre Produkte oder Ihre Marke in ihren Antworten erwähnen, zitieren oder referenzieren. Die Plattform hilft Ihnen zu verstehen, wann und wie Ihre Marke in KI-generierten Antworten erscheint und verschafft Einblicke in einen neuen und wachsenden Kanal der Informationsfindung, den herkömmliche Web-Monitoring-Tools oft nicht erfassen. Diese Überwachungsfunktion ist wichtig, da KI-Zitate anders funktionieren als klassische Web-Zitate – sie sind in dialogorientierte Antworten eingebettet, mit denen täglich Millionen von Nutzern interagieren, und dennoch haben die meisten Marken keinen Einblick, wie sie dort dargestellt werden. Mit AmICited erhalten Sie Einblicke in die Markenwahrnehmung in KI-Systemen, können Ungenauigkeiten oder veraltete Informationen identifizieren und erkennen, wie Ihre Marke im Vergleich zu Wettbewerbern in KI-generierten Antworten abschneidet. In einer Zeit, in der KI-Systeme für viele Nutzer zur primären Informationsquelle werden, ist die Überwachung Ihrer Präsenz in diesen Systemen ebenso wichtig wie die Überwachung klassischer Suchergebnisse – Tools wie AmICited sind daher unerlässlich für modernes Markenmanagement und KI-Transparenz.
ChatGPT wurde auf drei Hauptquellen trainiert: öffentlich verfügbare Internetdaten (Webseiten, Artikel, Foren), lizenzierte Datensätze (Bücher und wissenschaftliche Publikationen) und menschliches Feedback von Trainern. Die Trainingsdaten umfassen Nachrichtenwebsites, wissenschaftliche Zeitschriften, technische Dokumentationen, Wikipedia, Reddit, Stack Overflow und zahllose andere öffentlich zugängliche Webseiten, die bis zum jeweiligen Wissensstichtag gesammelt wurden.
Ein Wissensstichtag ist der Zeitpunkt, nach dem ChatGPT keine Trainingsdaten mehr hat. ChatGPT-4 verfügt über einen Wissensstichtag im Dezember 2023, während ChatGPT-4o einen Wissensstichtag im Oktober 2023 hat. Das ist wichtig, weil ChatGPT keine genauen Informationen über Ereignisse, Forschungen oder Entwicklungen liefern kann, die nach dem Trainingszeitraum stattgefunden haben, was es für zeitkritische Anfragen unzuverlässig macht.
ChatGPT kann allein aus seinen Trainingsdaten keine Echtzeitinformationen abrufen. Neuere Versionen von ChatGPT können jedoch Websuchen durchführen, um aktuelle Informationen über ihren Wissensstichtag hinaus zu erhalten, wobei diese Funktion nicht in allen Versionen oder Kontexten verfügbar ist und explizit aktiviert werden muss.
Im MLA-Format zitieren Sie ChatGPT wie eine Website mit dem Zugriffsdatum. Im APA-Format behandeln Sie es als Software und geben die Versionsnummer an. In beiden Formaten müssen Sie die genaue von Ihnen verwendete Eingabe, das Zugriffsdatum und idealerweise die ChatGPT-Version dokumentieren, da die gleiche Eingabe zu unterschiedlichen Zeitpunkten unterschiedliche Ergebnisse liefern kann.
Nein. ChatGPT kann mit Überzeugung falsche Informationen liefern (Halluzination), insbesondere zu obskuren Themen, aktuellen Ereignissen nach dem Wissensstichtag oder bei widersprüchlichen Informationen. Die Trainingsdaten enthalten inhärente Verzerrungen, und die Informationen veralten zunehmend. Überprüfen Sie daher wichtige Aussagen immer anhand von Primärquellen und autoritativen Datenbanken.
Die Trainingsdaten von ChatGPT werden nicht kontinuierlich aktualisiert. Neue Versionen werden periodisch mit aktualisierten Wissensstichtagen veröffentlicht, aber es gibt keine laufende Aktualisierung des Basismodells. OpenAI veröffentlicht neue Versionen (wie GPT-4o) mit aktuelleren Trainingsdaten, aber der genaue Aktualisierungszeitplan wird nicht öffentlich bekanntgegeben.
ChatGPT zitiert keine spezifischen Quellen für einzelne Aussagen, da es Informationen aus Mustern in den Trainingsdaten synthetisiert, anstatt einzelne Dokumente abzurufen. Es kann Ihnen nicht die genaue Quelle einer Tatsache nennen. Für wissenschaftliche Arbeiten sollten Sie die Aussagen von ChatGPT überprüfen und die Originalquellen zitieren, die Sie selbst finden – nicht ChatGPT selbst.
AmICited verfolgt, wie ChatGPT, Claude und andere KI-Systeme Ihre Marke in ihren Antworten erwähnen, zitieren oder referenzieren. Es verschafft Ihnen Einblick, wie Ihr Unternehmen in KI-generierten Antworten erscheint, hilft dabei, Ungenauigkeiten zu erkennen, und zeigt, wie Ihre Marke im Vergleich zu Wettbewerbern in KI-Systemen abschneidet – unerlässlich für modernes Markenmanagement im KI-Zeitalter.
Verfolgen Sie ChatGPT-Zitate und KI-Erwähnungen in Echtzeit mit AmICited. Verstehen Sie, wie KI-Systeme Ihre Marke referenzieren und bleiben Sie bei der KI-gestützten Informationssuche einen Schritt voraus.
Vollständiger Leitfaden zum Ablehnen der Datensammlung für KI-Training auf ChatGPT, Perplexity, LinkedIn und anderen Plattformen. Erfahren Sie Schritt-für-Schri...
Erfahren Sie, wie Wikipedia als entscheidender KI-Trainingsdatensatz dient, wie sich dies auf die Modellgenauigkeit auswirkt, welche Lizenzvereinbarungen besteh...

Trainingsdaten sind der Datensatz, mit dem ML-Modelle Muster und Zusammenhänge erlernen. Erfahren Sie, wie qualitativ hochwertige Trainingsdaten die Leistung, G...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.