
KI-Halluzinationen und Markensicherheit: So schützen Sie Ihren Ruf
Erfahren Sie, wie KI-Halluzinationen die Markensicherheit in Google AI Overviews, ChatGPT und Perplexity bedrohen. Entdecken Sie Überwachungsstrategien, Methode...
9 Min. Lesezeit

Erfahren Sie, wie LLM-Grounding und Websuche es KI-Systemen ermöglichen, auf Echtzeitinformationen zuzugreifen, Halluzinationen zu reduzieren und genaue Zitate zu liefern. Lernen Sie RAG, Implementierungsstrategien und Best Practices für Unternehmen kennen.
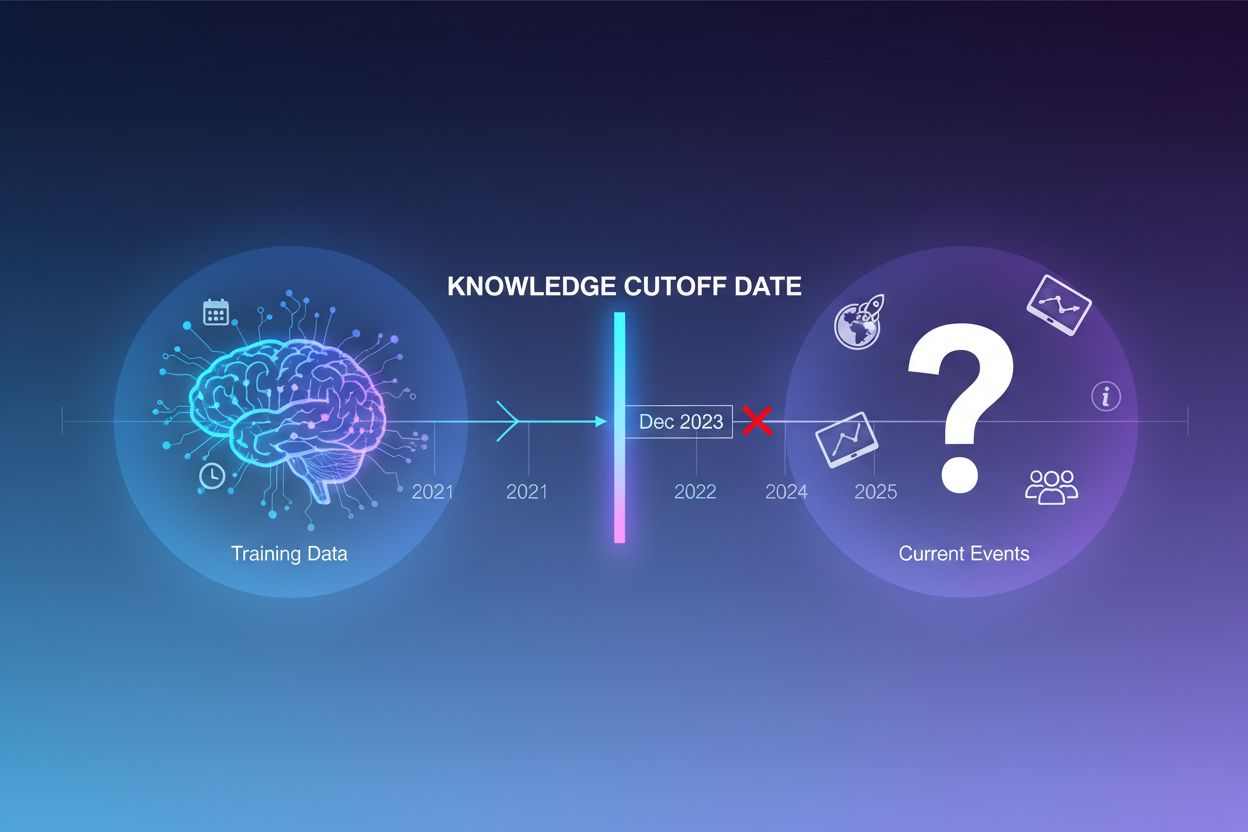
Große Sprachmodelle werden mit riesigen Mengen an Textdaten trainiert, aber dieser Trainingsprozess hat eine entscheidende Einschränkung: Er erfasst nur Informationen, die bis zu einem bestimmten Zeitpunkt verfügbar sind – dem sogenannten Knowledge Cutoff Date. Wenn zum Beispiel ein LLM mit Daten bis Dezember 2023 trainiert wurde, hat es keinerlei Kenntnis über Ereignisse, Entdeckungen oder Entwicklungen nach diesem Zeitpunkt. Stellen Nutzer Fragen zu aktuellen Ereignissen, neuen Produktveröffentlichungen oder aktuellen Nachrichten, kann das Modell auf diese Informationen nicht zugreifen. Statt Unsicherheit zuzugeben, generieren LLMs häufig plausibel klingende, aber faktisch falsche Antworten – ein Phänomen, das als Halluzination bezeichnet wird. Diese Tendenz wird besonders problematisch in Anwendungen, bei denen Genauigkeit entscheidend ist, wie Kundenservice, Finanzberatung oder medizinische Informationen, wo veraltete oder erfundene Angaben schwerwiegende Folgen haben können.
Grounding bezeichnet den Prozess, das vortrainierte Wissen eines LLMs zur Laufzeit mit externen, kontextuellen Informationen zu ergänzen. Anstatt sich ausschließlich auf im Training gelernte Muster zu verlassen, verbindet Grounding das Modell mit realen Datenquellen – seien es Webseiten, interne Dokumente, Datenbanken oder APIs. Dieses Konzept stammt aus der kognitiven Psychologie, insbesondere der Theorie der situativen Kognition, die besagt, dass Wissen am effektivsten angewandt wird, wenn es im jeweiligen Anwendungskontext verankert ist. Praktisch verwandelt Grounding das Problem von „Antwort aus dem Gedächtnis generieren“ zu „Antwort aus bereitgestellten Informationen synthetisieren“. Eine strenge Definition aus der aktuellen Forschung verlangt, dass das LLM sämtliches essentielles Wissen aus dem bereitgestellten Kontext nutzt und sich an dessen Umfang hält, ohne zusätzliche Informationen zu halluzinieren.
| Aspekt | Nicht-gegroundete Antwort | Gegroundete Antwort |
|---|---|---|
| Informationsquelle | Nur vortrainiertes Wissen | Vortrainiertes Wissen + externe Daten |
| Genauigkeit bei aktuellen Ereignissen | Gering (Cutoff-Limit) | Hoch (Zugriff auf aktuelle Infos) |
| Halluzinationsrisiko | Hoch (Modell rät) | Gering (durch Kontext begrenzt) |
| Zitierfähigkeit | Eingeschränkt oder unmöglich | Vollständige Rückverfolgbarkeit zu Quellen |
| Skalierbarkeit | Fest (Modellgröße) | Flexibel (neue Datenquellen ergänzbar) |
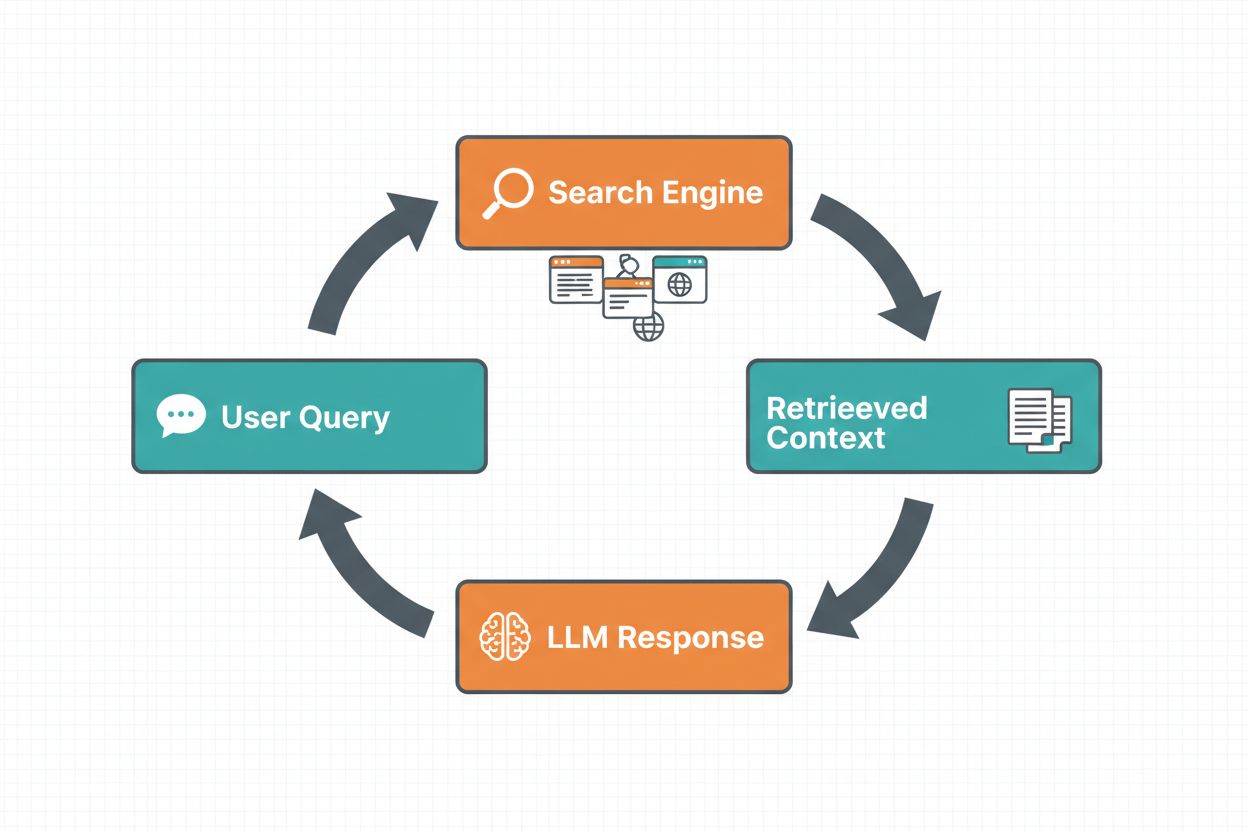
Websuche-Grounding ermöglicht es LLMs, auf Echtzeitinformationen zuzugreifen, indem automatisch das Web durchsucht und die Ergebnisse in den Antwortprozess eingespeist werden. Der Ablauf folgt einer festen Reihenfolge: Zunächst analysiert das System die Nutzereingabe, um zu entscheiden, ob eine Websuche die Antwort verbessern würde; dann werden eine oder mehrere Suchanfragen generiert, die auf relevante Ergebnisse optimiert sind; anschließend werden diese Anfragen an eine Suchmaschine (wie Google Search oder DuckDuckGo) übergeben; nachfolgend werden die Suchergebnisse verarbeitet und relevante Inhalte extrahiert; schließlich wird dieser Kontext dem LLM im Prompt bereitgestellt, sodass das Modell eine gegroundete Antwort generieren kann. Das System liefert zudem Grounding-Metadaten – strukturierte Informationen darüber, welche Suchanfragen ausgeführt, welche Quellen abgerufen und wie spezifische Antwortteile durch diese Quellen gestützt werden. Diese Metadaten sind wesentlich, um Vertrauen aufzubauen und Nutzern die Überprüfung von Aussagen zu ermöglichen.
Ablauf des Websuche-Grounding:
Retrieval Augmented Generation (RAG) hat sich als dominierende Grounding-Technik etabliert und verbindet jahrzehntelange Forschung zur Informationssuche mit modernen LLM-Fähigkeiten. RAG funktioniert, indem zunächst relevante Dokumente oder Passagen aus einer externen Wissensquelle (meist in einer Vektordatenbank indiziert) abgerufen und dann als Kontext dem LLM bereitgestellt werden. Der Retrieval-Prozess besteht typischerweise aus zwei Stufen: Ein Retriever verwendet effiziente Algorithmen (wie BM25 oder semantische Suche mit Embeddings), um Kandidatendokumente zu identifizieren, und ein Ranker sortiert diese Kandidaten mithilfe fortschrittlicher Neuronalmodelle nach Relevanz. Der abgerufene Kontext wird dann in den Prompt eingebunden, sodass das LLM Antworten auf Basis autoritativer Informationen synthetisieren kann. RAG bietet deutliche Vorteile gegenüber Fine-Tuning: Es ist kostengünstiger (kein Retraining nötig), besser skalierbar (neue Dokumente können einfach hinzugefügt werden) und leichter zu warten (Informationen lassen sich ohne Modellneutraining aktualisieren). Ein RAG-Prompt könnte beispielsweise so aussehen:
Verwenden Sie die folgenden Dokumente, um die Frage zu beantworten.
[Frage]
Was ist die Hauptstadt von Kanada?
[Dokument 1]
Ottawa ist die Hauptstadt Kanadas und liegt in Ontario...
[Dokument 2]
Kanada ist ein Land in Nordamerika mit zehn Provinzen...
Einer der überzeugendsten Vorteile von Websuche-Grounding ist die Möglichkeit, Echtzeitinformationen in LLM-Antworten einzubinden. Dies ist besonders wertvoll für Anwendungen, die aktuelle Daten benötigen – Nachrichtenanalysen, Marktforschung, Eventinformationen oder Produktverfügbarkeiten. Über den bloßen Zugriff auf aktuelle Informationen hinaus liefert Grounding Zitate und Quellenangaben, was für den Vertrauensaufbau bei Nutzern und die Überprüfbarkeit entscheidend ist. Wenn ein LLM eine gegroundete Antwort generiert, gibt es strukturierte Metadaten zurück, die spezifische Aussagen auf die zugrundeliegenden Dokumente abbilden; so sind Inline-Zitate wie “[1] source.com” direkt im Antworttext möglich. Diese Fähigkeit steht im Einklang mit der Mission von Plattformen wie AmICited.com, die verfolgen, wie KI-Systeme Quellen auf verschiedenen Plattformen referenzieren und zitieren. Die Möglichkeit, nachzuvollziehen, welche Quellen ein KI-System konsultiert und wie es Informationen zugeordnet hat, gewinnt zunehmend an Bedeutung für Markenüberwachung, Inhaltszuordnung und verantwortungsvolle KI-Nutzung.
Halluzinationen entstehen, weil LLMs grundsätzlich darauf ausgelegt sind, das nächste Token anhand früherer Tokens und gelernter Muster vorherzusagen, ohne die Grenzen ihres Wissens zu erkennen. Werden sie mit Fragen außerhalb ihres Trainingsdatums konfrontiert, generieren sie weiter plausibel klingende Texte, statt Unsicherheit zuzugeben. Grounding setzt hier an, indem es die Modellaufgabe grundlegend verändert: Das Modell soll nicht mehr aus dem Gedächtnis, sondern aus bereitgestellten Informationen synthetisieren. Technisch betrachtet verschiebt relevanter externer Kontext im Prompt die Token-Wahrscheinlichkeitsverteilung hin zu Antworten, die auf diesem Kontext beruhen, sodass Halluzinationen unwahrscheinlicher werden. Studien zeigen, dass Grounding Halluzinationsraten je nach Aufgabe und Umsetzung um 30-50 % senken kann. Fragt man beispielsweise “Wer hat die EM 2024 gewonnen?” ohne Grounding, liefert ein älteres Modell womöglich eine falsche Antwort; mit Grounding und Websuchergebnissen wird korrekt Spanien als Sieger mit konkreten Spieldetails genannt. Dieser Mechanismus funktioniert, weil die Attention-Mechanismen des Modells nun auf den gegebenen Kontext fokussieren können, anstatt sich auf potenziell unvollständige oder widersprüchliche Trainingsmuster zu verlassen.
Die Implementierung von Websuche-Grounding erfordert die Integration mehrerer Komponenten: einer Such-API (wie Google Search, DuckDuckGo via Serp API oder Bing Search), Logik zum Erkennen, wann Grounding benötigt wird, und Prompt-Engineering, um Suchergebnisse effektiv einzubinden. Eine praktische Umsetzung beginnt meist damit zu bewerten, ob die Nutzeranfrage aktuelle Informationen benötigt – dies kann etwa erfolgen, indem das LLM selbst gefragt wird, ob der Prompt Informationen braucht, die nach dem Wissenscutoff liegen. Falls Grounding erforderlich ist, führt das System eine Websuche durch, extrahiert relevante Snippets aus den Ergebnissen und baut einen Prompt, der sowohl die Originalfrage als auch den Suchkontext enthält. Kostenaspekte sind wichtig: Jede Websuche verursacht API-Kosten, daher kann dynamisches Grounding (nur suchen, wenn nötig) die Ausgaben deutlich senken. Beispielsweise benötigt “Warum ist der Himmel blau?” vermutlich keine Websuche, “Wer ist der aktuelle Präsident?” hingegen schon. Fortgeschrittene Implementierungen nutzen kleinere, schnellere Modelle für die Grounding-Entscheidung, um Latenz und Kosten zu senken und reservieren größere Modelle für die finale Antwortgenerierung.
So mächtig Grounding auch ist, es bringt einige Herausforderungen mit sich. Datenrelevanz ist entscheidend – wenn abgerufene Informationen die Nutzerfrage nicht wirklich beantworten, hilft Grounding nicht weiter und kann sogar irrelevanten Kontext einführen. Datenmenge birgt ein Paradoxon: Mehr Informationen scheinen hilfreich, aber Studien zeigen, dass die LLM-Leistung bei zu viel Input oft abnimmt – ein Phänomen namens “Lost in the Middle”-Bias, bei dem Modelle Informationen in der Mitte langer Kontexte übersehen. Token-Effizienz wird relevant, denn jeder Teil des abgerufenen Kontexts verbraucht Tokens, was Latenz und Kosten erhöht. Hier gilt das Prinzip „weniger ist mehr“: Rufen Sie nur die Top-k relevantesten Ergebnisse ab (typisch 3-5), arbeiten Sie mit kleineren Textausschnitten statt ganzen Dokumenten und extrahieren Sie ggf. Schlüsselsätze aus längeren Passagen.
| Herausforderung | Auswirkung | Lösung |
|---|---|---|
| Datenrelevanz | Irrelevanter Kontext verwirrt das Modell | Semantische Suche + Ranker nutzen; Retrieval-Qualität testen |
| Lost in Middle Bias | Modell übersieht wichtige Infos in der Mitte | Eingabegröße minimieren; kritische Infos an Anfang/Ende platzieren |
| Token-Effizienz | Hohe Latenz und Kosten | Weniger Ergebnisse abrufen; kleinere Textstücke verwenden |
| Veraltete Informationen | Überholter Kontext in Wissensbasis | Aktualisierungsrichtlinien und Versionskontrolle implementieren |
| Latenz | Langsame Antworten wegen Suche + Inferenz | Asynchrone Operationen nutzen; häufige Anfragen cachen |
Der Einsatz von Grounding-Systemen im Produktivbetrieb erfordert sorgfältige Beachtung von Governance, Sicherheit und Betrieb. Datenqualitätsmanagement ist grundlegend – die Informationen, auf denen Sie grounden, müssen korrekt, aktuell und für Ihre Anwendungsfälle relevant sein. Zugriffskontrolle ist bei der Arbeit mit proprietären oder sensiblen Dokumenten unerlässlich: Das LLM darf nur Informationen anzeigen, die entsprechend der Nutzerberechtigung zugänglich sind. Aktualisierungs- und Drift-Management verlangt Richtlinien, wie oft Wissensbasen erneuert und wie widersprüchliche Informationen aus verschiedenen Quellen gehandhabt werden. Audit-Logging ist für Compliance und Debugging essenziell – halten Sie fest, welche Dokumente abgerufen, wie sie gerankt und welcher Kontext dem Modell bereitgestellt wurde. Weitere Überlegungen sind:
Das Feld des LLM-Grounding entwickelt sich rasant über reine Text-Retrieval-Ansätze hinaus. Multimodales Grounding hält Einzug, bei dem Systeme Antworten nicht nur in Texte, sondern auch in Bilder, Videos und strukturierte Daten einbetten – besonders relevant für Bereiche wie juristische Dokumentenanalyse, medizinische Bildgebung oder technische Dokumentation. Automatisiertes Reasoning wird auf RAG aufgesetzt, sodass Agenten nicht nur Informationen abrufen, sondern auch über mehrere Quellen hinweg synthetisieren, Schlussfolgerungen ziehen und ihre Argumentation erklären können. Guardrails werden mit Grounding kombiniert, um sicherzustellen, dass Modelle auch bei Zugriff auf externe Informationen Sicherheitsvorgaben und Richtlinien einhalten. Modell-Updates im laufenden Betrieb sind ein weiteres Forschungsfeld – statt sich nur auf externes Retrieval zu verlassen, wird erforscht, wie sich Modellgewichte direkt mit neuen Informationen aktualisieren lassen, was den Bedarf an umfangreichen Wissensbasen reduzieren könnte. Diese Fortschritte deuten darauf hin, dass zukünftige Grounding-Systeme intelligenter, effizienter und besser in der Lage sein werden, komplexe, mehrstufige Argumentationen zu verarbeiten – bei gleichzeitiger Wahrung von Faktentreue und Nachvollziehbarkeit.
Grounding erweitert ein LLM zur Laufzeit mit externen Informationen, ohne das Modell selbst zu verändern, während Fine-Tuning das Modell mit neuen Daten nachtrainiert. Grounding ist kostengünstiger, schneller umzusetzen und leichter mit neuen Informationen zu aktualisieren. Fine-Tuning ist besser geeignet, wenn Sie das Verhalten des Modells grundlegend ändern oder domänenspezifische Muster erlernen müssen.
Grounding reduziert Halluzinationen, indem es dem LLM einen faktenbasierten Kontext liefert, anstatt es ausschließlich auf Trainingsdaten zu stützen. Wird relevante externe Information im Prompt eingebunden, verschiebt sich die Token-Wahrscheinlichkeitsverteilung des Modells hin zu Antworten, die auf diesem Kontext beruhen, wodurch erfundene Aussagen seltener werden. Studien zeigen, dass Grounding Halluzinationsraten um 30-50 % senken kann.
Retrieval Augmented Generation (RAG) ist eine Grounding-Technik, bei der relevante Dokumente aus einer externen Wissensquelle abgerufen und dem LLM als Kontext bereitgestellt werden. RAG ist wichtig, weil es skalierbar, kostengünstig und eine Aktualisierung der Informationen ohne erneutes Training des Modells ermöglicht. Es hat sich als Industriestandard für die Entwicklung von Grounded-AI-Anwendungen etabliert.
Implementieren Sie Websuche-Grounding, wenn Ihre Anwendung Zugriff auf aktuelle Informationen benötigt (Nachrichten, Events, aktuelle Daten), wenn Genauigkeit und Zitate entscheidend sind oder wenn der Wissenscutoff Ihres LLMs eine Einschränkung darstellt. Nutzen Sie dynamisches Grounding, um nur bei Bedarf zu suchen, und reduzieren Sie so Kosten und Latenz bei Anfragen, die keine frischen Informationen erfordern.
Wichtige Herausforderungen sind die Sicherstellung der Datenrelevanz (abgerufene Informationen müssen tatsächlich die Frage beantworten), das Management der Datenmenge (mehr ist nicht immer besser), der Umgang mit dem 'Lost in the Middle'-Bias, bei dem Modelle Informationen in langen Kontexten übersehen, und die Optimierung der Token-Effizienz. Lösungen sind semantische Suche mit Rankern, weniger, aber hochwertigere Ergebnisse abrufen und kritische Informationen am Anfang oder Ende des Kontextes platzieren.
Grounding ist direkt relevant für die Überwachung von KI-Antworten, da es Systemen ermöglicht, Zitate und Quellenangaben bereitzustellen. Plattformen wie AmICited verfolgen, wie KI-Systeme Quellen referenzieren, was nur bei korrekt implementiertem Grounding möglich ist. Dies trägt zu verantwortungsvoller KI-Nutzung und Marken-Attribution über verschiedene KI-Plattformen hinweg bei.
Der 'Lost in the Middle'-Bias beschreibt das Phänomen, dass LLMs schlechter abschneiden, wenn relevante Informationen in der Mitte langer Kontexte platziert werden, im Vergleich zu Informationen am Anfang oder Ende. Das liegt daran, dass Modelle bei großen Textmengen dazu neigen, zu 'überfliegen'. Lösungen sind die Minimierung der Eingabegröße, das Platzieren kritischer Informationen an bevorzugten Stellen und die Nutzung kleinerer Textabschnitte.
Für den Produktiveinsatz sollten Sie auf Qualitätssicherung der Daten achten, Zugriffskontrollen für sensible Informationen implementieren, Aktualisierungs- und Erneuerungsrichtlinien festlegen, Audit-Logging für Compliance aktivieren und Feedbackschleifen mit Nutzern schaffen, um Fehler zu identifizieren. Überwachen Sie die Token-Nutzung, um Kosten zu optimieren, führen Sie Versionskontrolle der Wissensdatenbank ein und verfolgen Sie das Modellverhalten zur Drift-Erkennung.
AmICited verfolgt, wie GPTs, Perplexity und Google AI Overviews Ihre Inhalte zitieren und referenzieren. Erhalten Sie Echtzeit-Einblicke in die Überwachung von KI-Antworten und Marken-Attribution.
Erfahren Sie, wie KI-Halluzinationen die Markensicherheit in Google AI Overviews, ChatGPT und Perplexity bedrohen. Entdecken Sie Überwachungsstrategien, Methode...

Erfahren Sie effektive Methoden, um ungenaue Informationen in KI-generierten Antworten von ChatGPT, Perplexity und anderen KI-Systemen zu erkennen, zu überprüfe...

Entdecken Sie, wie große Sprachmodelle Quellen mittels Evidenzgewichtung, Entitätenerkennung und strukturierter Daten auswählen und zitieren. Erfahren Sie den 7...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.