Query Fanout
Erfahren Sie, wie Query Fanout in KI-Suchsystemen funktioniert. Entdecken Sie, wie KI einzelne Anfragen in mehrere Unteranfragen erweitert, um die Genauigkeit d...
10 Min. Lesezeit
Entdecken Sie, wie moderne KI-Systeme wie Google AI Mode und ChatGPT einzelne Anfragen in mehrere Suchvorgänge zerlegen. Lernen Sie Fanout-Mechanismen kennen, deren Auswirkungen auf KI-Sichtbarkeit und die Optimierung von Content-Strategien.
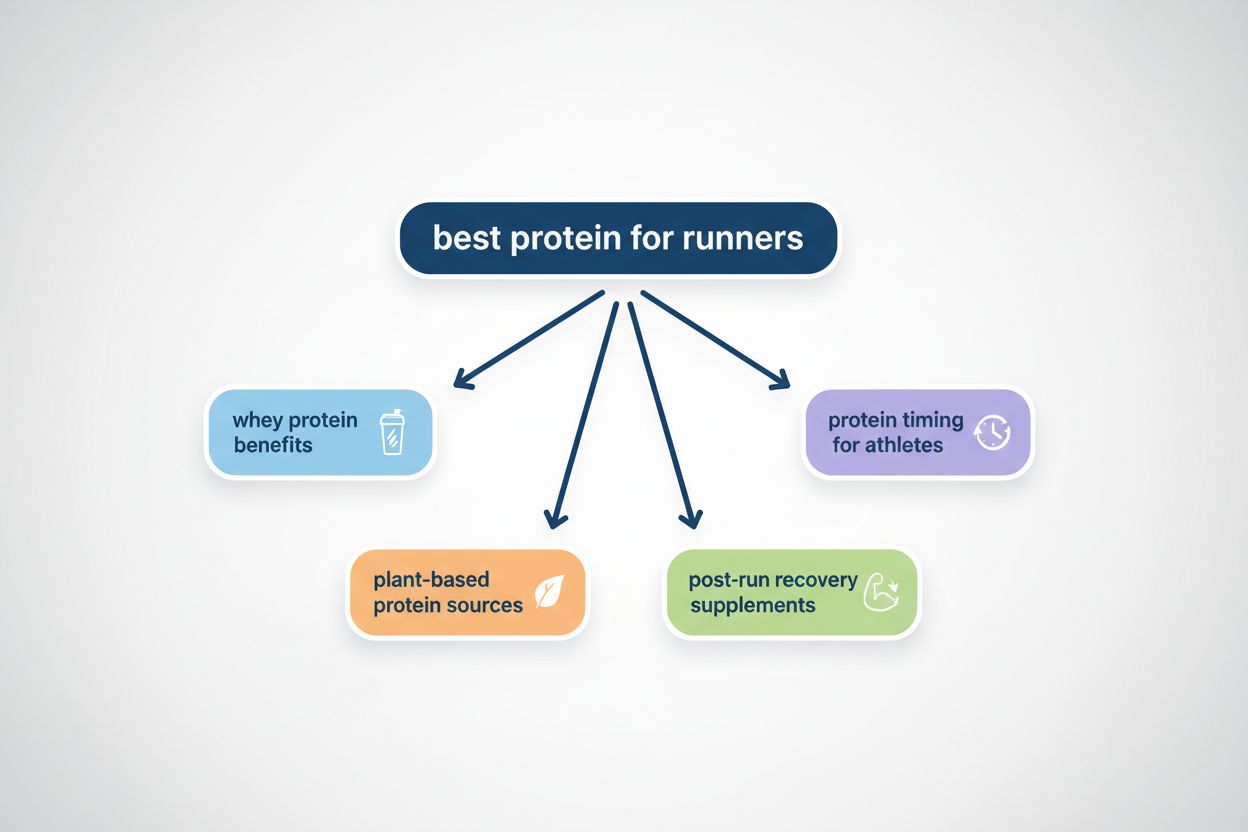
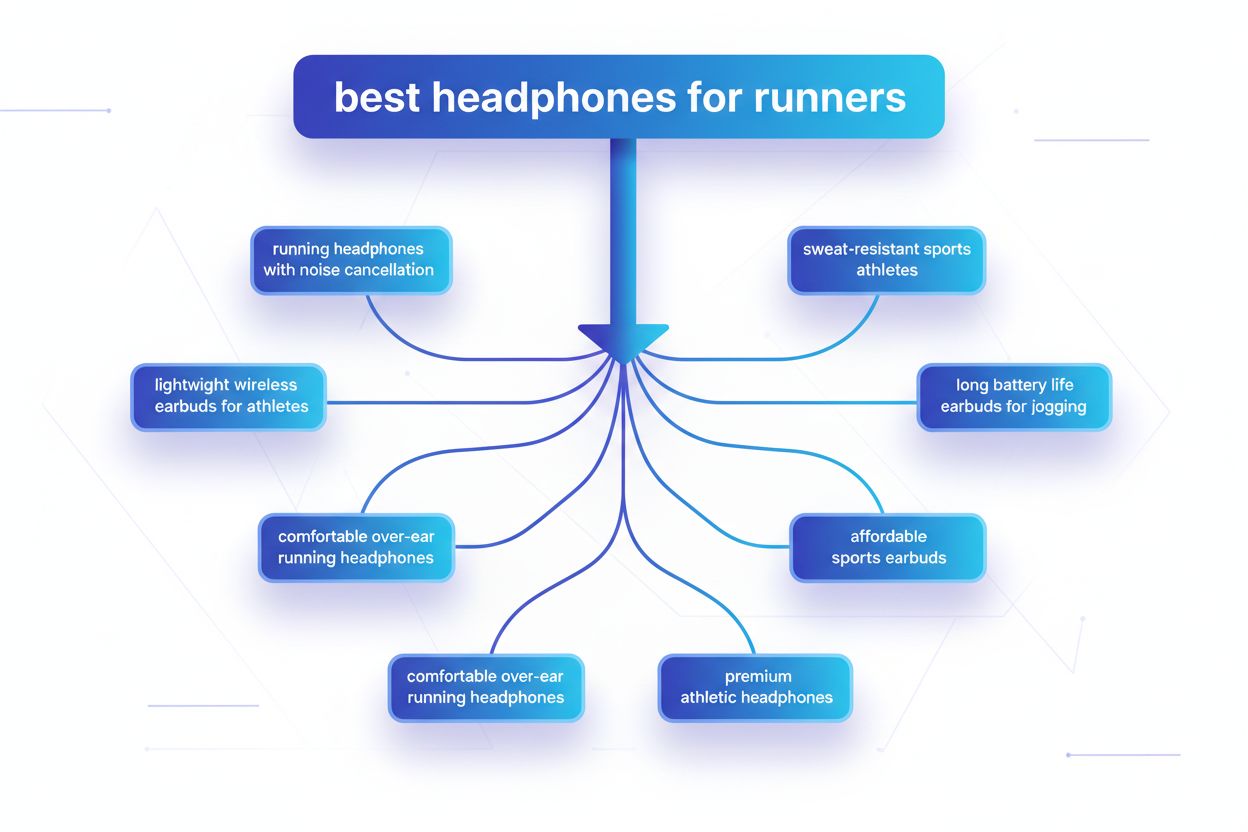
Query Fanout ist der Prozess, bei dem große Sprachmodelle eine einzelne Nutzeranfrage automatisch in mehrere Teilanfragen aufteilen, um umfassendere Informationen aus verschiedenen Quellen zu gewinnen. Anstatt eine einzige Suche auszuführen, zerlegen moderne KI-Systeme die Nutzerabsicht in 5–15 verwandte Anfragen, die unterschiedliche Blickwinkel, Interpretationen und Aspekte des ursprünglichen Wunsches abdecken. Sucht zum Beispiel ein Nutzer in Googles AI Mode nach „beste Kopfhörer für Läufer“, generiert das System etwa 8 verschiedene Suchanfragen, darunter Varianten wie „Laufkopfhörer mit Geräuschunterdrückung“, „leichte kabellose Ohrhörer für Sportler“, „schweißresistente Sportkopfhörer“ und „Ohrhörer mit langer Akkulaufzeit für Jogging“. Das bedeutet einen grundlegenden Wandel gegenüber der traditionellen Suche, bei der eine einzelne Zeichenkette mit einem Index abgeglichen wird. Wichtige Merkmale des Query Fanouts sind:
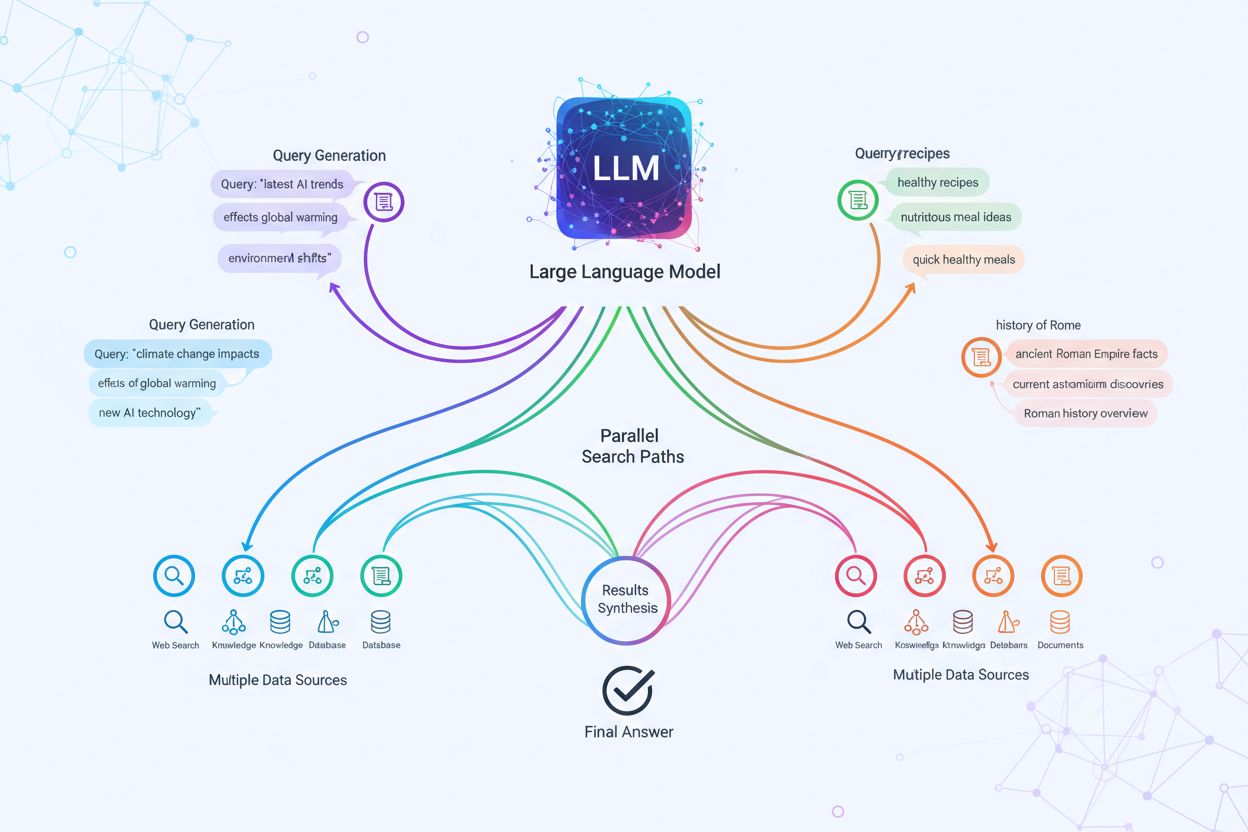
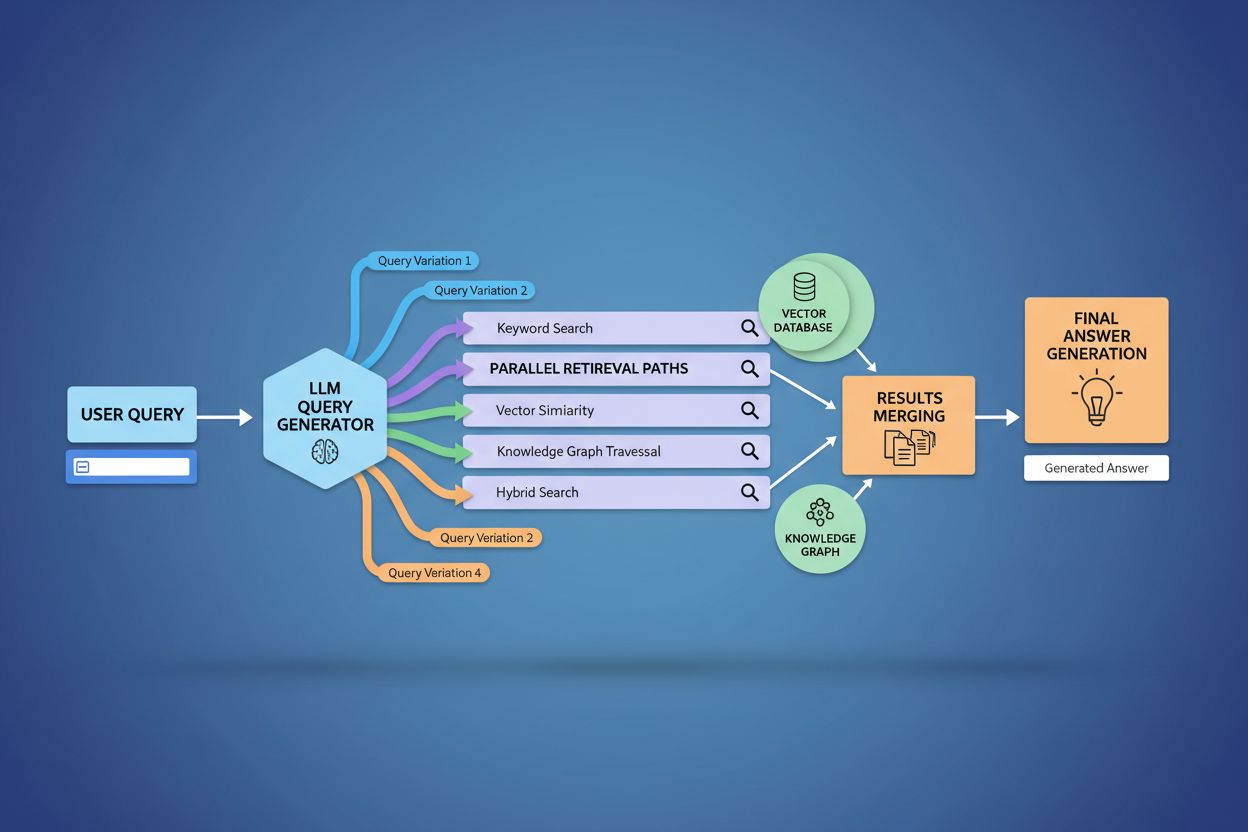
Die technische Umsetzung von Query Fanout basiert auf ausgefeilten NLP-Algorithmen, die die Komplexität einer Anfrage analysieren und semantisch sinnvolle Varianten generieren. LLMs erzeugen acht Haupttypen von Query-Varianten: äquivalente Anfragen (Umformulierungen mit identischer Bedeutung), Folgeanfragen (Erkundung verwandter Themen), Generalisierungsanfragen (Erweiterung des Themas), Spezifizierungsanfragen (Fokussierung), Kanonisierung (Standardisierung der Terminologie), Übersetzungsanfragen (Domänenübertragungen), Implikationsanfragen (logische Folgerungen) und Präzisierungsanfragen (Auflösung von Mehrdeutigkeiten). Das System nutzt neuronale Sprachmodelle, um die Anfragenkomplexität zu bewerten – anhand von Faktoren wie Anzahl der Entitäten, Beziehungsdichte und semantischer Unschärfe – und bestimmt so, wie viele Teilanfragen generiert werden. Nach der Generierung werden diese Anfragen parallel über mehrere Retrieval-Systeme ausgeführt: Webcrawler, Wissensgraphen (z. B. Googles Knowledge Graph), strukturierte Datenbanken und Vektorsuchindizes. Verschiedene Plattformen setzen diese Architektur mit unterschiedlicher Transparenz und Raffinesse um:
| Plattform | Mechanismus | Transparenz | Anzahl Anfragen | Ranking-Methode |
|---|---|---|---|---|
| Google AI Mode | Explizites Fanout mit sichtbaren Anfragen | Hoch | 8–12 Anfragen | Mehrstufiges Ranking |
| Microsoft Copilot | Iterativer Bing Orchestrator | Mittel | 5–8 Anfragen | Relevanz-Scoring |
| Perplexity | Hybrides Retrieval mit Mehrstufen-Ranking | Hoch | 6–10 Anfragen | Zitationsbasiert |
| ChatGPT | Implizite Anfragegenerierung | Niedrig | Unbekannt | Internes Gewichtungssystem |
Komplexe Anfragen werden durch fortschrittliche Zerlegung aufgeschlüsselt: Das System zerlegt sie in Entitäten, Attribute und Beziehungen, bevor Varianten generiert werden. Bei einer Anfrage wie „Bluetooth-Kopfhörer mit bequemem Over-Ear-Design und langanhaltendem Akku, geeignet für Läufer“ erkennt das System zentrale Entitäten (Bluetooth-Kopfhörer, Läufer) und extrahiert kritische Eigenschaften (bequem, Over-Ear, langanhaltender Akku). Die Zerlegung nutzt Wissensgraphen, um die Entitätenbeziehungen und semantische Varianten zu verstehen – etwa, dass „Over-Ear-Kopfhörer“ und „circumaurale Kopfhörer“ synonym sind oder dass „langanhaltender Akku“ je nach Kontext 8+, 24+ Stunden oder mehrere Tage bedeuten kann. Durch semantische Ähnlichkeitsmessungen erkennt das System, dass „schweißresistent“ und „wasserresistent“ verwandt, aber unterschiedlich sind, und dass „Läufer“ auch an „Radfahrer“, „Fitnessstudiobesucher“ oder „Outdoor-Athleten“ interessiert sein könnten. Diese Zerlegung ermöglicht gezielte Teilanfragen, die verschiedene Facetten der Nutzerabsicht abdecken, statt die ursprüngliche Anfrage nur umzuformulieren.
Query Fanout verstärkt grundlegend die Retrieval-Komponente von Retrieval-Augmented Generation (RAG)-Frameworks, indem es eine reichhaltigere, vielfältigere Evidenzbeschaffung vor der Antwortgenerierung ermöglicht. In traditionellen RAG-Pipelines wird eine einzelne Anfrage eingebettet und gegen eine Vektor-Datenbank gematcht – relevante Informationen, die andere Begriffe oder Konzepte nutzen, können so übersehen werden. Query Fanout löst dieses Problem, indem es mehrere Retrieval-Vorgänge parallel für spezifische Varianten ausführt und so Belege aus unterschiedlichen Blickwinkeln und Quellen sammelt. Diese parallele Retrieval-Strategie reduziert das Halluzinationsrisiko deutlich, da LLM-Antworten auf mehreren unabhängigen Quellen basieren – werden Informationen zu „Over-Ear-Kopfhörern“, „circumauralen Designs“ und „Full-Size-Kopfhörern“ separat geholt, kann das System Behauptungen über die verschiedenen Ergebnisse hinweg abgleichen und validieren. Die Architektur nutzt semantisches Chunking und passagenbasiertes Retrieval: Dokumente werden nach sinnvollen semantischen Einheiten statt nach fester Länge aufgeteilt, sodass immer die relevantesten Abschnitte gefunden werden. Durch das Kombinieren von Evidenz aus mehreren Teilabfragen liefern RAG-Systeme umfassendere, besser belegte Antworten und sind weniger anfällig für die typischen Fehler reiner Einzelabfragen.
Nutzerkontext und Personalisierungssignale beeinflussen dynamisch, wie Query Fanout individuelle Anfragen erweitert und so personalisierte Suchpfade schafft, die sich von Nutzer zu Nutzer stark unterscheiden können. Das System bezieht verschiedene Personalisierungsdimensionen ein: Nutzerattribute (Standort, Demografie, Beruf), Suchhistorie (frühere Anfragen, geklickte Ergebnisse), zeitliche Signale (Tageszeit, Saison, aktuelle Ereignisse) und Aufgaben-Kontext (Recherche, Shopping, Lernen). Eine Anfrage nach „beste Kopfhörer für Läufer“ wird für eine 22-jährige Ultramarathonläuferin in Kenia anders erweitert als für einen 45-jährigen Freizeitsportler in Minnesota – die erste Variante betont Haltbarkeit und Hitzebeständigkeit, die zweite Komfort und Zugänglichkeit. Personalisierung bringt jedoch das „Two-Point Transformation“-Problem mit sich: Das System behandelt aktuelle Anfragen als Varianten früherer Muster, was die Suche einschränken und bestehende Vorlieben verstärken kann. Personalisierung kann unbeabsichtigt Filterblasen erzeugen, in denen Anfrageerweiterungen systematisch Quellen und Perspektiven bevorzugen, die dem bisherigen Verhalten entsprechen. Für Content Creators ist es deshalb entscheidend zu verstehen, dass der eigene Content je nach Nutzerprofil und -historie unterschiedlich sichtbar ist.
Große KI-Plattformen implementieren Query Fanout mit teils stark unterschiedlichen Architekturen, Transparenzgraden und Strategien, die ihre Infrastruktur und Philosophie widerspiegeln. Googles AI Mode setzt auf expliziten, sichtbaren Fanout: Nutzer sehen die 8–12 generierten Teilanfragen direkt neben den Ergebnissen; im Hintergrund werden hunderte Einzelsuchen gegen den Google-Index ausgeführt, um umfassende Belege zu sammeln. Microsoft Copilot nutzt einen iterativen Ansatz mit dem Bing Orchestrator, der 5–8 Anfragen nacheinander generiert, die auf Zwischenergebnissen basieren, bevor die finale Suche ausgeführt wird. Perplexity setzt auf hybrides Retrieval mit mehrstufigem Ranking: 6–10 Anfragen werden parallel gegen Webquellen und einen eigenen Index ausgeführt, dann mit ausgefeilten Ranking-Algorithmen bewertet. ChatGPTs Ansatz bleibt für Nutzer weitgehend undurchsichtig – die Anfragegenerierung erfolgt implizit im internen Modell, sodass unklar bleibt, wie viele Anfragen tatsächlich generiert und ausgeführt werden. Diese Architekturunterschiede haben große Auswirkungen auf Transparenz, Reproduzierbarkeit und die Möglichkeiten für Content Creators, für jede Plattform zu optimieren:
| Aspekt | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Sichtbarkeit der Anfragen | Vollständig sichtbar | Teilweise sichtbar | Sichtbar in Zitaten | Versteckt |
| Ausführungsmodell | Parallele Batch-Ausführung | Iterativ-sequenziell | Parallel mit Ranking | Intern/implizit |
| Quellenvielfalt | Nur Google-Index | Bing + proprietär | Web + proprietärer Index | Trainingsdaten + Plugins |
| Zitations-Transparenz | Hoch | Mittel | Sehr hoch | Niedrig |
| Anpassungsmöglichkeiten | Eingeschränkt | Mittel | Hoch | Mittel |
Query Fanout bringt technische und semantische Herausforderungen mit sich, die dazu führen können, dass das System von der eigentlichen Nutzerabsicht abweicht und zwar technisch verwandte, aber letztlich wenig hilfreiche Informationen ausgibt. Semantischer Drift entsteht durch generative Expansion, wenn das LLM Varianten erzeugt, die zwar semantisch verwandt, aber zunehmend vom Ursprung entfernt sind – eine Anfrage nach „beste Kopfhörer für Läufer“ kann so zu „Sportkopfhörer“, dann „Sportequipment“, dann „Fitnesszubehör“ erweitert werden und entfernt sich schrittweise von der Ausgangsabsicht. Das System muss zwischen latenter Absicht (was der Nutzer vielleicht wollen würde, wenn er mehr wüsste) und expliziter Absicht (was tatsächlich gefragt wurde) unterscheiden. Eine zu aggressive Expansion kann diese Kategorien vermischen und Produkte ausliefern, die der Nutzer nie beabsichtigt hat. Iterative Expansion Divergenz entsteht, wenn jede generierte Variante weitere Subanfragen erzeugt und so ein Suchbaum mit immer entfernteren Themen entsteht. Filterblasen und Personalisierungs-Bias führen dazu, dass zwei Nutzer mit identischer Frage systematisch unterschiedliche Anfragen und Ergebnisse erhalten, weil ihre Profile die Expansion beeinflussen – jeder bleibt in seiner Vorzugsblase. In der Praxis zeigen sich diese Fallstricke etwa so: Sucht jemand nach „günstige Kopfhörer“, kann die Anfrage je nach Browserverlauf auf Luxusmarken erweitert werden; fragt jemand nach „Kopfhörer für hörgeschädigte Nutzer“, wird das zu allgemeinen Accessibility-Produkten erweitert, was die ursprüngliche Absicht verwässert.
Mit dem Aufstieg von Query Fanout verschiebt sich die Content-Strategie grundlegend von Keyword-Ranking-Optimierung hin zu zitationsbasierter Sichtbarkeit. Content Creators müssen überdenken, wie sie Informationen strukturieren und präsentieren. Während traditionelles SEO auf Rankings für einzelne Keywords abzielte, zählt in der KI-getriebenen Suche, als autoritäre Quelle über viele Varianten und Kontexte hinweg zitiert zu werden. Die Strategie sollte auf atomaren, entitätsreichen Content mit reichhaltigem semantischem Markup setzen, sodass KI-Systeme relevante Passagen extrahieren und zitieren können. Themencluster und thematische Autorität gewinnen an Bedeutung: Statt isolierte Artikel zu einzelnen Keywords zu erstellen, sollte umfassende Themenabdeckung aufgebaut werden, um bei möglichst vielen Query-Varianten gefunden zu werden. Schema-Markup und strukturierte Daten helfen KI-Systemen, den Content besser zu verstehen und relevante Informationen herauszufiltern – das steigert die Zitationswahrscheinlichkeit. Erfolgsmessung verschiebt sich vom Keyword-Ranking zur Überwachung der Zitationsfrequenz, etwa mit Tools wie AmICited.com, das erfasst, wie oft Marken und Inhalte in KI-Antworten erscheinen. Zu den Best Practices gehören: umfassenden, gut belegten Content zu unterschiedlichen Aspekten eines Themas erstellen, reichhaltiges Schema-Markup (Organisation, Produkt, Artikel) implementieren, thematische Autorität mit vernetztem Content aufbauen und regelmäßig prüfen, wie der eigene Content in KI-Antworten auf verschiedenen Plattformen und für verschiedene Nutzersegmente erscheint.
Query Fanout ist der bedeutendste architektonische Wandel in der Suche seit Mobile-First-Indexierung und verändert grundlegend, wie Informationen gefunden und Nutzern präsentiert werden. Die Entwicklung hin zu semantischer Infrastruktur bedeutet, dass Suchsysteme zunehmend auf Bedeutung statt Keywords arbeiten – Query Fanout wird zum Standardmechanismus für Informationsgewinnung. Zitationsmetriken werden so wichtig wie Backlinks für Sichtbarkeit und Autorität: Ein Content, der in 50 verschiedenen KI-Antworten zitiert wird, ist wertvoller als ein Content, der für ein einzelnes Keyword auf Platz 1 rankt. Dieser Wandel birgt sowohl Herausforderungen als auch Chancen: Klassische SEO-Tools zur Keyword-Überwachung verlieren an Relevanz, neue Messmodelle für Zitationshäufigkeit, Quellenvielfalt und Sichtbarkeit über verschiedene Query-Varianten entstehen. Gleichzeitig eröffnen sich für Marken Chancen, gezielt für KI-Suche zu optimieren, indem sie autoritativen, gut strukturierten Content schaffen, der als zuverlässige Quelle bei vielen Query-Interpretationen dient. Die Zukunft wird wahrscheinlich mehr Transparenz bei Fanout-Mechanismen bringen – Plattformen werden um die beste Sichtbarkeit und Nachvollziehbarkeit ihrer Multi-Query-Logik konkurrieren, und Content Creators entwickeln spezialisierte Strategien, um Sichtbarkeit über die vielfältigen Retrieval-Pfade des Fanouts zu maximieren.
Query Fanout ist der automatisierte Prozess, bei dem KI-Systeme eine einzelne Nutzeranfrage in mehrere Teilanfragen zerlegen und parallel ausführen, während Query Expansion traditionell das Hinzufügen verwandter Begriffe zu einer einzelnen Anfrage bedeutet. Query Fanout ist ausgefeilter und erzeugt semantisch vielfältige Varianten, die verschiedene Aspekte und Interpretationen der ursprünglichen Absicht erfassen.
Query Fanout hat erheblichen Einfluss auf die Sichtbarkeit, da Ihr Content über mehrere Varianten einer Anfrage auffindbar sein muss – nicht nur über die exakte Nutzeranfrage. Content, der verschiedene Blickwinkel abdeckt, unterschiedliche Begriffe nutzt und mit Schema-Markup gut strukturiert ist, wird mit größerer Wahrscheinlichkeit über die vielfältigen Fanout-Teilabfragen gefunden und zitiert.
Alle großen KI-Suchplattformen nutzen Query Fanout-Mechanismen: Google AI Mode verwendet expliziten, sichtbaren Fanout (8–12 Anfragen); Microsoft Copilot nutzt iterativen Fanout über den Bing Orchestrator; Perplexity setzt auf hybrides Retrieval mit mehrstufigem Ranking; und ChatGPT generiert Anfragen implizit. Jede Plattform implementiert dies unterschiedlich, aber alle zerlegen komplexe Anfragen in mehrere Suchen.
Ja. Optimieren Sie, indem Sie atomaren, entitätsreichen Content rund um spezifische Konzepte erstellen, umfassendes Schema-Markup implementieren, thematische Autorität durch vernetzten Content aufbauen, klare und vielfältige Terminologie verwenden und verschiedene Blickwinkel eines Themas abdecken. Tools wie AmICited.com helfen, zu überwachen, wie Ihr Content bei unterschiedlichen Query-Zerlegungen erscheint.
Query Fanout erhöht die Latenz, da mehrere Anfragen parallel ausgeführt werden. Moderne Systeme mildern dies jedoch durch parallele Verarbeitung ab. Während eine einzelne Anfrage etwa 200 ms dauert, erhöht die parallele Ausführung von 8 Anfragen die Gesamtlatenz typischerweise nur um 300–500 ms. Dieser Trade-off lohnt sich für eine bessere Antwortqualität.
Query Fanout stärkt Retrieval-Augmented Generation (RAG), indem es eine reichhaltigere Evidenzbeschaffung ermöglicht. Statt Dokumente für eine einzige Anfrage zu holen, beschafft Fanout parallel Evidenz für mehrere Varianten und bietet dem LLM einen umfassenderen Kontext für präzisere Antworten – und verringert das Halluzinationsrisiko.
Personalisierung formt, wie Anfragen basierend auf Nutzerattributen (Standort, Historie, Demografie), zeitlichen Signalen und Aufgaben-Kontext zerlegt werden. Die gleiche Anfrage wird für verschiedene Nutzer unterschiedlich erweitert und erzeugt so personalisierte Suchpfade. Das kann die Relevanz steigern, aber auch Filterblasen erzeugen, in denen Nutzer systematisch unterschiedliche Ergebnisse sehen.
Query Fanout ist die bedeutendste Veränderung in der Suche seit Mobile-First-Indexierung. Traditionelle Keyword-Ranking-Metriken werden weniger relevant, da die gleiche Anfrage für verschiedene Nutzer unterschiedlich erweitert wird. SEO-Profis müssen den Fokus von Keyword-Rankings hin zu sichtbarkeitsbasierten Zitationen, Content-Struktur und Entitäten-Optimierung verschieben, um im KI-getriebenen Search erfolgreich zu sein.
Verstehen Sie, wie Ihre Marke auf KI-Suchplattformen erscheint, wenn Anfragen erweitert und zerlegt werden. Verfolgen Sie Zitate und Erwähnungen in KI-generierten Antworten.
Erfahren Sie, wie Query Fanout in KI-Suchsystemen funktioniert. Entdecken Sie, wie KI einzelne Anfragen in mehrere Unteranfragen erweitert, um die Genauigkeit d...

Verstehen Sie, wie KI-Such-Funnels anders funktionieren als traditionelle Marketing-Funnels. Erfahren Sie, wie KI-Systeme wie ChatGPT und Google AI die Käuferre...
Erfahren Sie, wie Sie TOFU-Content für KI-Suche optimieren. Beherrschen Sie Awareness-Strategien für ChatGPT, Perplexity, Google AI Overviews und Claude.
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.