
Wie funktioniert das Indexieren für KI-Suchmaschinen?
Erfahren Sie, wie KI-Suchindexierung Daten in durchsuchbare Vektoren umwandelt, sodass KI-Systeme wie ChatGPT und Perplexity relevante Informationen aus Ihren I...
6 Min. Lesezeit
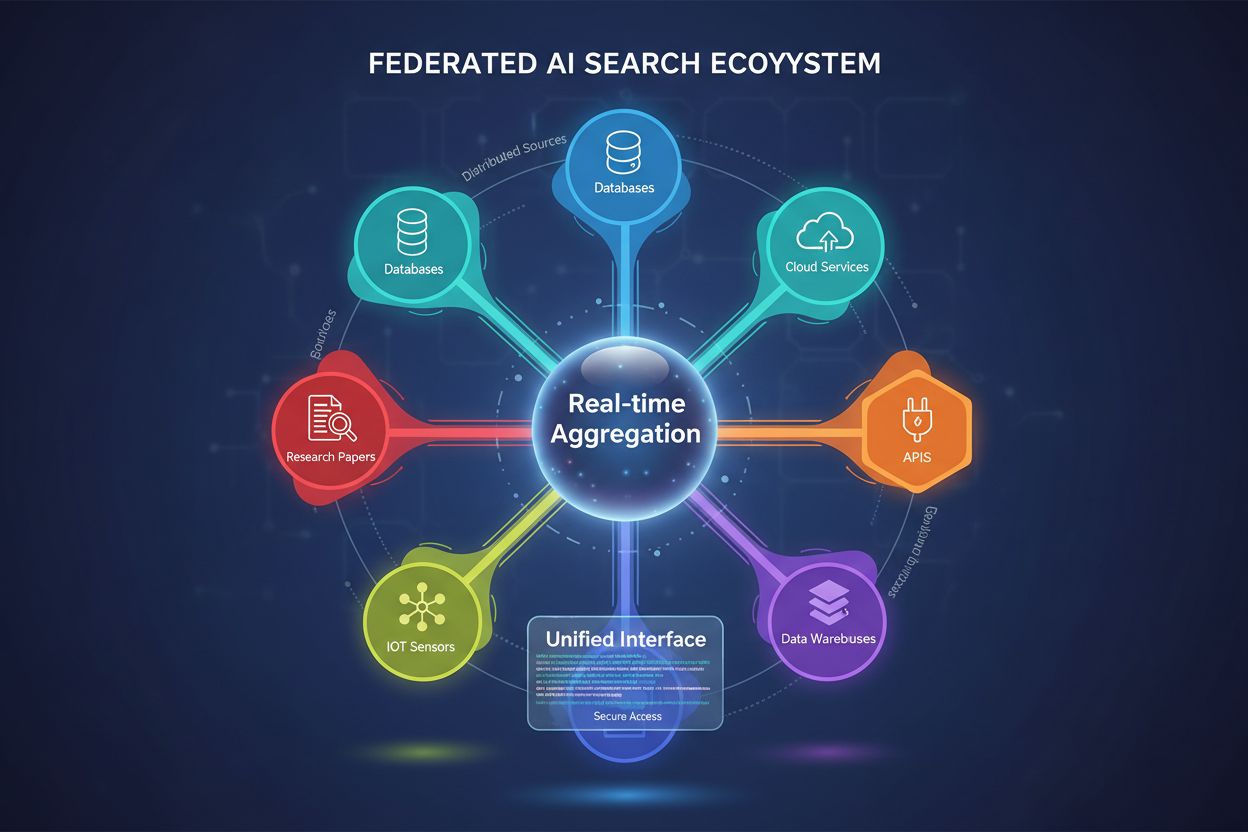
Föderierte KI-Suche ist ein System, das mit einer einzigen Suchanfrage gleichzeitig mehrere unabhängige Datenquellen abfragt und die Ergebnisse in Echtzeit aggregiert, ohne Daten zu verschieben oder zu duplizieren. Es ermöglicht Organisationen den Zugriff auf verteilte Informationen über Datenbanken, APIs und Cloud-Dienste hinweg und wahrt dabei Datensicherheit und Compliance. Im Gegensatz zu traditionellen zentralisierten Suchmaschinen bewahren föderierte Systeme die Datenautonomie und bieten eine einheitliche Informationssuche. Dieser Ansatz ist besonders wertvoll für Unternehmen, die vielfältige Datenquellen über verschiedene Abteilungen, Regionen oder Organisationen hinweg verwalten.
Föderierte KI-Suche ist ein System, das mit einer einzigen Suchanfrage gleichzeitig mehrere unabhängige Datenquellen abfragt und die Ergebnisse in Echtzeit aggregiert, ohne Daten zu verschieben oder zu duplizieren. Es ermöglicht Organisationen den Zugriff auf verteilte Informationen über Datenbanken, APIs und Cloud-Dienste hinweg und wahrt dabei Datensicherheit und Compliance. Im Gegensatz zu traditionellen zentralisierten Suchmaschinen bewahren föderierte Systeme die Datenautonomie und bieten eine einheitliche Informationssuche. Dieser Ansatz ist besonders wertvoll für Unternehmen, die vielfältige Datenquellen über verschiedene Abteilungen, Regionen oder Organisationen hinweg verwalten.
Föderierte KI-Suche ist ein verteiltes Informationsabrufsystem, das gleichzeitig mehrere heterogene Datenquellen abfragt und die Ergebnisse intelligent mittels KI-Techniken aggregiert. Im Gegensatz zu traditionellen zentralisierten Suchmaschinen, die ein einziges indiziertes Repository pflegen, arbeitet die föderierte KI-Suche über dezentralisierte Netzwerke unabhängiger Datenbanken, Wissensbasen und Informationssysteme – ohne Datenkonsolidierung oder zentrale Indizierung.
Das grundlegende Prinzip der föderierten KI-Suche ist das quellenagnostische Abfragen, bei dem eine einzelne Nutzeranfrage intelligent an relevante Datenquellen weitergeleitet, von jeder Quelle unabhängig verarbeitet und dann zu einem einheitlichen Ergebnis zusammengeführt wird. Dieser Ansatz erhält die Datenautonomie und ermöglicht zugleich umfassende Informationssuche über organisatorische und technische Grenzen hinweg.
Zu den wichtigsten Merkmalen föderierter KI-Suchsysteme gehören:
Verteilte Architektur: Daten verbleiben an ihrem Ursprungsort in verschiedenen Repositorien, wodurch Datenmigration oder zentrale Speicherung entfallen. Jede Quelle verwaltet unabhängig ihre Indizierung, Zugriffssteuerung und Aktualisierungsmechanismen.
Intelligentes Query Routing: KI-Algorithmen analysieren eingehende Anfragen, um zu bestimmen, welche Quellen am wahrscheinlichsten relevante Informationen enthalten – dies optimiert die Sucheffizienz und reduziert unnötige Anfragen an irrelevante Datenbanken.
Ergebnisaggregation und Ranking: Maschinelle Lernmodelle bündeln die Resultate aus verschiedenen Quellen und wenden fortschrittliche Ranking-Algorithmen an, die Quellenglaubwürdigkeit, Relevanz, Aktualität und Nutzerkontext berücksichtigen.
Unterstützung heterogener Quellen: Föderierte Systeme unterstützen eine Vielzahl von Datenformaten, Schemata, Abfragesprachen und Zugriffsprotokollen – darunter relationale Datenbanken, Dokumentenspeicher, Wissensgraphen, APIs und unstrukturierte Textsammlungen.
Echtzeit-Integration: Im Gegensatz zu batch-basierten Data-Warehouse-Ansätzen bietet die föderierte Suche nahezu Echtzeit-Zugriff auf aktuelle Informationen aller verbundenen Quellen und gewährleistet so Aktualität und Genauigkeit der Ergebnisse.
Semantisches Verständnis: Moderne föderierte KI-Suche nutzt natürliche Sprachverarbeitung und semantische Analyse, um die Suchabsicht über reine Schlüsselworte hinaus zu erfassen und so eine präzisere Quellenauswahl und Ergebnisinterpretation zu ermöglichen.
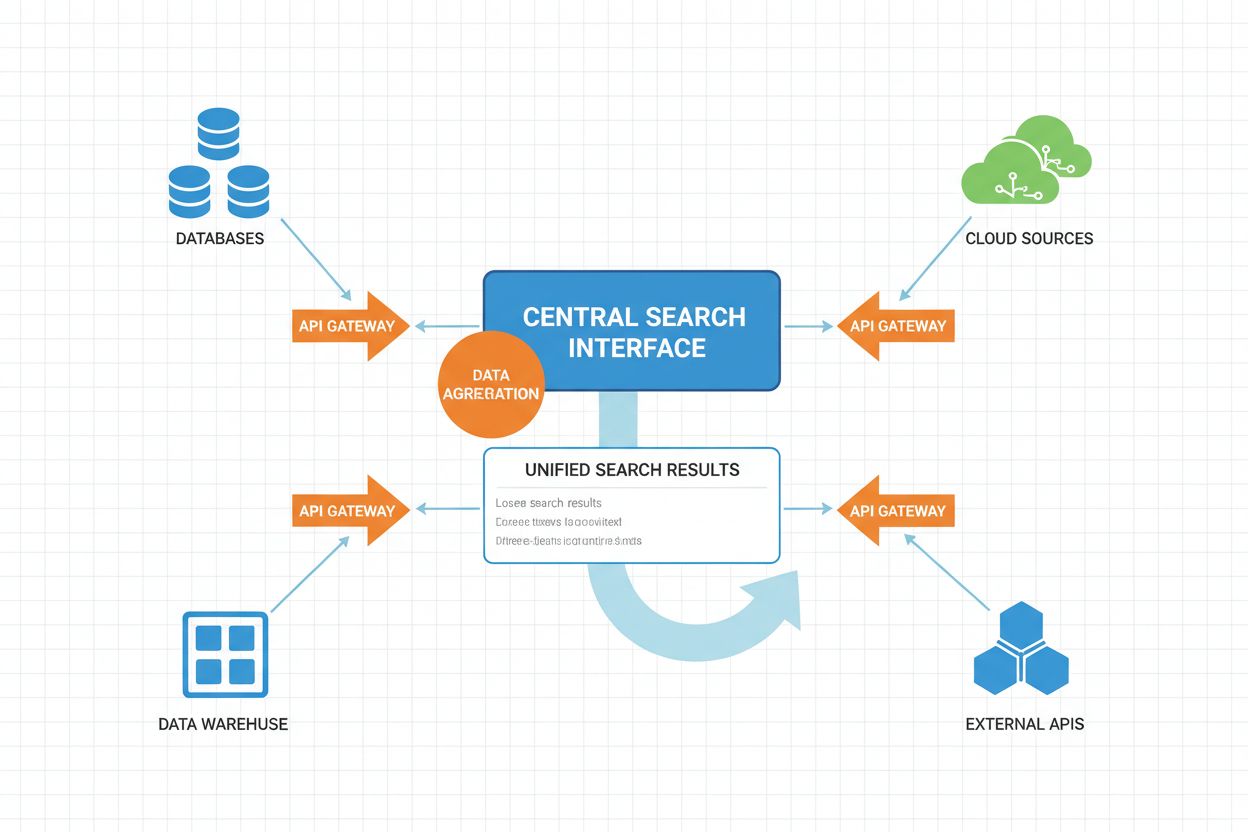
Der operative Ablauf der föderierten KI-Suche umfasst mehrere koordinierte Phasen, die jeweils durch KI optimiert werden, um Leistung und Ergebnisqualität zu steigern.
| Phase | Prozess | KI-Komponente | Output |
|---|---|---|---|
| Abfrageanalyse | Nutzeranfrage wird geparst und auf Intention, Entitäten und Kontext analysiert | NLP, Named Entity Recognition, Intent-Klassifikation | Strukturierte Abfragerepräsentation, identifizierte Entitäten, Intention-Signale |
| Quellenauswahl | System bestimmt, welche Datenquellen für die Anfrage am relevantesten sind | ML-Ranking-Modelle, Quellrelevanz-Klassifikatoren | Priorisierte Zielliste von Quellen, Konfidenzwerte |
| Abfrage-Übersetzung | Anfrage wird in quellspezifische Formate und Abfragesprachen übersetzt | Schemamapping, Abfrageübersetzungsmodelle, semantisches Matching | Quellen-spezifische Abfragen (SQL, SPARQL, API-Calls etc.) |
| Verteilte Ausführung | Abfragen laufen parallel auf den gewählten Quellen | Lastverteilung, Timeout-Management, parallele Verarbeitung | Rohdaten von jeder Quelle, Ausführungs-Metadaten |
| Ergebnisnormalisierung | Ergebnisse verschiedener Quellen werden in ein einheitliches Format überführt | Schema-Angleichung, Datentyp-Konvertierung, Standardisierung | Normalisierter Ergebnissatz mit konsistenter Struktur |
| Semantische Anreicherung | Ergebnisse werden mit zusätzlichem Kontext und Metadaten angereichert | Entity Linking, semantisches Tagging, Wissensgraph-Integration | Angereicherte Resultate mit semantischen Annotationen |
| Ranking & Duplikaterkennung | Ergebnisse werden nach Relevanz sortiert und Duplikate entfernt | Learning-to-Rank-Modelle, Ähnlichkeitserkennung, Relevanzscoring | Duplikatfreies, sortiertes Ergebnis |
| Personalisierung | Ergebnisse werden für Nutzerprofil und Präferenzen angepasst | Collaborative Filtering, User Modeling, Kontextbewusstsein | Personalisierte Ergebnisreihenfolge |
| Präsentation | Ergebnisse werden für die Nutzeransicht aufbereitet | Natural Language Generation, Ergebniszusammenfassung | Nutzerfreundliche Ergebnisdarstellung |
Der Ablauf basiert auf paralleler Ausführung, bei der mehrere Quellen simultan abgefragt werden – das reduziert die Gesamtabfragezeit erheblich, auch wenn Koordination notwendig ist. Fortschrittliche Systeme nutzen adaptives Query-Planning, bei dem aus vergangenen Suchmustern gelernt wird, um Quellenauswahl und Ausführungsstrategien laufend zu optimieren.
Timeout- und Fallback-Mechanismen sind entscheidend für die Zuverlässigkeit: Reagiert eine Quelle langsam oder fällt aus, kann das System entweder mit adaptiven Timeouts warten oder mit den verfügbaren Ergebnissen fortfahren und so die Ergebnisvollständigkeit sanft reduzieren, statt ganz zu scheitern.
Föderierte KI-Suchsysteme lassen sich entlang mehrerer Dimensionen kategorisieren:
Nach Architekturmodell:
Nach Quellentyp:
Nach Umfang und Skalierung:
Nach Intelligenzgrad:
Datenautonomie und Governance: Organisationen behalten die Kontrolle über ihre Daten und müssen sensible Informationen nicht in zentrale Repositorien transferieren. So bleiben Governance-Vorgaben, Compliance- und Sicherheitsanforderungen auf Quellenseite gewahrt.
Skalierbarkeit ohne Konsolidierung: Föderierte Systeme skalieren durch Hinzufügen neuer Quellen, ohne dass Datenmigration oder Data-Warehouse-Umstrukturierungen nötig sind. Damit können Unternehmen Datenquellen inkrementell integrieren, wenn neue Geschäftsbedarfe entstehen.
Echtzeit-Informationszugriff: Durch direkte Abfrage der Quellen erhalten Nutzer aktuelle Informationen ohne die Latenz batch-basierter Datenlagerung – besonders wertvoll für zeitkritische Anwendungen.
Kosteneffizienz: Der Aufbau und Betrieb zentralisierter Data Warehouses entfällt, ebenso wie Datenverdopplung, redundante Speicherung und aufwendige ETL-Prozesse.
Reduzierte Datenredundanz: Im Gegensatz zu Data Warehousing, bei dem Daten dupliziert werden, bleibt bei föderierter Suche jede Quelle der Single Point of Truth mit geringerem Speicherbedarf und höherer Konsistenz.
Flexibilität und Anpassungsfähigkeit: Neue Quellen lassen sich integrieren, ohne bestehende Infrastruktur zu ändern oder zentrale Indizes neu aufzubauen – das ermöglicht schnelle Reaktion auf neue Anforderungen.
Verbesserte Datenqualität: Durch Abfrage autoritativer Quellen werden Probleme durch Datenveraltung und Inkonsistenzen, wie sie bei periodischer Synchronisation im Warehouse entstehen, minimiert.
Erhöhte Sicherheit: Sensible Daten verbleiben an ihrem Ursprungsort, was das Risiko unautorisierten Zugriffs oder Datenlecks minimiert. Zugriffssteuerungen bleiben dezentral.
Unterstützung heterogener Quellen: Technologie-, format- und protokollübergreifende Integration ohne Zwang zur Standardisierung oder Migration auf gemeinsame Plattformen.
Intelligente Ergebnissynthese: KI-basiertes Ranking und Aggregation liefern hochwertigere Resultate als bloßes Zusammenführen – unter Berücksichtigung von Quellenglaubwürdigkeit, Relevanz und Nutzerkontext.
Moderne föderierte KI-Suchsysteme bestehen aus mehreren vernetzten technischen Komponenten, die gemeinsam integrierte Suchfunktionalitäten bereitstellen.
Query-Processing-Engine: Zentrale Komponente, die Nutzeranfragen entgegennimmt und den föderierten Suchablauf steuert. Beinhaltet Parsing, semantische Analyse und Intent-Erkennung. Fortgeschrittene Implementierungen nutzen Transformer-basierte Sprachmodelle für komplexes Query-Verständnis.
Quellenregister und Metadatenmanagement: Verwalten umfassender Metadaten zu verfügbaren Quellen – einschließlich Schemata, Inhaltsmerkmalen, Update-Frequenzen, Verfügbarkeiten und Leistungskennzahlen. Das ermöglicht intelligente Quellenauswahl und Query-Optimierung. ML-Modelle analysieren historische Abfragemuster, um die Relevanz neuer Quellen vorherzusagen.
Intelligentes Quellenauswahl-Modul: Setzt ML-Klassifikatoren ein, um relevante Quellen für eine Anfrage zu bestimmen. Berücksichtigt Inhaltsabdeckung, bisherige Query-Erfolge, Verfügbarkeit und Antwortzeiten. Fortgeschrittene Systeme nutzen Reinforcement Learning zur Optimierung der Strategien.
Abfrage-Übersetzungs- und Anpassungsschicht: Wandelt Nutzeranfragen in quellspezifische Formate und Sprachen um – inkl. SQL für relationale Datenbanken, SPARQL für Wissensgraphen, REST-APIs für Webservices und natürliche Sprache für unstrukturierte Systeme. Semantisches Mapping stellt die Intention über Systemgrenzen hinweg sicher.
Verteilter Ausführungskoordinator: Steuert parallele Abfrageausführung über mehrere Quellen, inklusive Timeout-Management, Lastverteilung und Fehlerbehandlung. Adaptive Timeout-Strategien passen sich Antwortmustern und Systembelastung an.
Ergebnisnormalisierungs-Engine: Überführt Ergebnisse aus heterogenen Quellen in ein gemeinsames Format für Aggregation und Ranking – inkl. Schemamapping, Datentyp-Konvertierung und Standardisierung. Umgang mit fehlenden Feldern, widersprüchlichen Datentypen und strukturellen Unterschieden.
Semantisches Anreicherungsmodul: Ergänzt Resultate um Kontext und semantische Informationen wie Entity Linking, semantisches Tagging und Beziehungsanalyse. Das erhöht die Ranking-Genauigkeit und Verständlichkeit.
Learning-to-Rank-Modell: ML-Modell, trainiert auf historischen Query-Result-Paaren zur Relevanzvorhersage. Berücksichtigt Quellenglaubwürdigkeit, Aktualität, Nutzerprofil und semantische Ähnlichkeit. Moderne Implementierungen nutzen Gradient Boosting oder neuronale Netzwerke.
Deduplication Engine: Erkennt und entfernt Duplikate oder fast identische Ergebnisse aus verschiedenen Quellen mittels Ähnlichkeitsmetriken (exakte und unscharfe Abgleiche, semantische Ähnlichkeit).
Personalisierungs-Engine: Passt die Ergebnisreihenfolge an Nutzerprofile, Präferenzen und Kontext an. Implementiert Collaborative Filtering und Content-basierte Empfehlungen.
Caching- & Optimierungsschicht: Intelligente Caching-Strategien zur Reduktion redundanter Abfragen – inklusive Query-Result-Cache, Metadaten-Cache und Vorhersagen zukünftiger Informationsbedarfe.
Monitoring & Analytics Modul: Überwachung von Systemleistung, Quellenzuverlässigkeit, Suchmustern und Ergebnisqualität. Diese Daten fließen zurück in Optimierungskomponenten für kontinuierliche Verbesserung.
Gesundheitswesen & medizinische Forschung: Integration von Patientendaten aus Krankenhaussystemen, Forschungsdatenbanken, Studienregistern und medizinischer Literatur. Ärzte können vollständige Patientenhistorien über verschiedene Anbieter hinweg abfragen, ohne sensible Daten zu zentralisieren. Forscher erhalten Zugang zu verteilten klinischen Daten für Studien unter Einhaltung von Datenschutz und Compliance.
Finanzdienstleistungen: Banken und Investmentfirmen nutzen föderierte Suche zur gleichzeitigen Abfrage von Handelsdaten, Marktinformationen, Regulierungsdatenbanken und internen Transaktionen. Das ermöglicht Echtzeit-Risikobewertung, Compliance-Monitoring und Marktanalysen ohne zentrale Datenhaltung.
Recht & Compliance: Kanzleien und Rechtsabteilungen suchen über juristische Datenbanken, Gesetzesrepositorien, interne Dokumentensysteme und Vertragsdatenbanken hinweg. Föderierte Suche ermöglicht umfassende Recherche bei Wahrung der Vertraulichkeit.
E-Commerce & Einzelhandel: Onlinehändler integrieren Produktkataloge aus verschiedenen Lagern, Lieferantensystemen und Marktplätzen. Föderierte Suche ermöglicht einheitliche Produktsuche, während Lieferanten unabhängige Lager- und Preissysteme behalten.
Staat & Verwaltung: Behörden durchsuchen verteilte Datenbanken wie Volkszählung, Steuerdaten, Genehmigungssysteme und öffentliche Register, ohne sensible Bürgerdaten zu zentralisieren – für umfassende Services bei hoher Sicherheit.
Fertigung & Supply Chain: Hersteller integrieren Lieferantendatenbanken, Lager, Produktionsaufzeichnungen und Logistikplattformen. Föderierte Suche bietet Transparenz in der Lieferkette, ohne dass Partner ihre Systeme aufgeben oder interne Daten offenlegen müssen.
Bildung & Forschung: Hochschulen suchen über institutionelle Repositorien, Bibliothekssysteme, Forschungsdatenbanken und Open-Access-Publikationen – für umfassende wissenschaftliche Recherche bei Wahrung der Autonomie und Urheberrechte.
Telekommunikation: Anbieter suchen über Kundendaten, Netzwerkinfrastruktur, Abrechnungssysteme und Servicekataloge. Föderierte Suche ermöglicht einheitlichen Kundenservice trotz getrennter Systeme.
Energie & Versorger: Energieunternehmen durchsuchen Erzeugungsdaten, Verteilnetze, Kundendatenbanken und Compliance-Systeme – für operative Transparenz, ohne regionale Unabhängigkeit aufzugeben.
Medien & Verlage: Medienhäuser durchsuchen Inhaltsarchive, Rechteverwaltung und Distributionsplattformen – für umfassende Inhaltsfindung bei Wahrung von Eigentum und Lizenzrechten.
Quellenheterogenität & Integrationsaufwand: Die Integration verschiedenster Datenquellen mit unterschiedlichen Schemata, Sprachen und Protokollen erfordert erheblichen Engineering-Aufwand. Schema-Mapping und semantische Angleichung bleiben schwierig, besonders bei abweichenden Konzeptdarstellungen.
Abfragelatenz & Performance: Föderierte Suche bringt zwangsläufig Latenz durch Mehrfachabfragen mit sich. Langsame oder nicht reagierende Quellen beeinträchtigen die Gesamtperformance. Timeout-Management muss sorgfältig abgestimmt werden.
Quellenzuverlässigkeit & Verfügbarkeit: Das System ist auf die ständige Erreichbarkeit externer Quellen angewiesen. Netzwerkausfälle oder -verzögerungen schlagen direkt auf die Ergebnisqualität durch. Ein sanftes Degradieren der Vollständigkeit ist nötig.
Ergebnisqualität & Ranking: Das Zusammenführen von Ergebnissen unterschiedlicher Qualität, Abdeckung und Relevanz ist anspruchsvoll. Ranking-Modelle müssen Quellenglaubwürdigkeit und Verzerrungen ausbalancieren.
Datenaktualität & Konsistenz: Quellen können unterschiedliche Update-Frequenzen und Konsistenzgarantien haben. Konflikte zwischen widersprüchlichen Informationen erfordern ausgefeilte Auflösungsstrategien.
Skalierungsgrenzen: Mit steigender Quellenzahl wächst der Koordinationsaufwand. Die Auswahl relevanter Quellen aus Tausenden wird rechenintensiv; parallele Ausführung braucht robuste Infrastruktur.
Sicherheit & Zugriffskontrolle: Die Durchsetzung von Zugriffsrechten über die föderierte Plattform hinweg ist komplex, besonders in Multi-Tenant-Umgebungen.
Datenschutz & Compliance: Föderierte Suche muss Vorgaben wie DSGVO, CCPA und branchespezifische Regeln einhalten. Die Vermeidung von Datenlecks durch Ergebnisaggregation oder Metadatenanalyse erfordert sorgfältiges Design.
Quellenmanagement: Das Auffinden, Katalogisieren und Aktualisieren der Quellen sowie das Pflegen der Metadaten ist ein kontinuierlicher Prozess.
Semantische Interoperabilität: Die echte semantische Interoperabilität über verschiedene Ontologien und Datenmodelle hinweg bleibt eine Herausforderung. Automatisiertes Schema-Mapping und Entitätenabgleich haben Grenzen.
Koordinationskosten: Zwar entfallen Kosten der Datenkonsolidierung, aber Koordinationsaufwand entsteht für verteilte Ausführung, Fehlerbehandlung und Query-Optimierung.
Mangelnde Standardisierung: Fehlende einheitliche Standards für föderierte Suchprotokolle und Schnittstellen erschweren die Integration und erhöhen das Risiko von Vendor-Lock-in.
Föderierte KI-Suche vs. Data Warehousing: Data Warehousing bündelt Daten in einem zentralen Repository, ermöglicht schnelle Abfragen, erfordert aber hohen ETL-Aufwand und Datenlatenz. Föderierte Suche fragt Quellen direkt ab und bietet Echtzeit-Zugang mit höherer Abfragelatenz. Warehousing ist ideal für historische Analysen; föderierte Suche für aktuelle Informationsbeschaffung.
Föderierte KI-Suche vs. Data Lakes: Data Lakes speichern Rohdaten zentral und transformationsarm, bieten Flexibilität, verursachen aber hohen Speicher- und Governance-Aufwand. Föderierte Suche verzichtet auf Konsolidierung und erhält Quellensouveränität, benötigt aber komplexere Query-Verarbeitung.
Föderierte KI-Suche vs. APIs & Microservices: APIs erlauben gezielten Zugriff auf einzelne Services, erfordern aber Kenntnis der Schnittstellen. Föderierte Suche abstrahiert diese Details und ermöglicht einheitliche Abfragen über verschiedene Services hinweg. APIs sind für Anwendungsintegration, föderierte Suche für informationsübergreifende Recherche.
Föderierte KI-Suche vs. Wissensgraphen: Wissensgraphen stellen Informationen als Beziehungen zwischen Entitäten dar und ermöglichen semantisches Schließen. Föderierte Suche kann verteilte Graphen abfragen, benötigt aber keinen zentralen Graphen. Wissensgraphen bieten tiefes Verständnis, föderierte Suche betont Quellensouveränität.
Föderierte KI-Suche vs. Suchmaschinen: Traditionelle Suchmaschinen unterhalten zentrale Indizes gecrawlter Inhalte. Föderierte Suche fragt Quellen direkt, ohne Vorab-Indexierung. Suchmaschinen bieten breite Abdeckung öffentlicher Inhalte, föderierte Suche integriert private oder spezialisierte Quellen.
Föderierte KI-Suche vs. Master Data Management (MDM): MDM konsolidiert Stammdaten aus verschiedenen Quellen zu autoritativen Datensätzen. Föderierte Suche fragt Quellen unabhängig ab, ohne Masterdaten zu erzeugen. MDM dient Governance und Konsistenz, föderierte Suche schneller Verfügbarkeit.
Föderierte KI-Suche vs. Enterprise Search: Enterprise Search indiziert interne Dokumente und Datenbanken zentral. Föderierte Suche fragt Quellen direkt ab. Enterprise Search ermöglicht schnelle Volltextsuche, föderierte Suche unterstützt heterogene Quellen und Echtzeit-Aktualität.
Föderierte KI-Suche vs. Blockchain & Distributed Ledger: Blockchain sichert verteilte Konsistenz und Unveränderlichkeit. Föderierte Suche koordiniert Abfragen über unabhängige Quellen, ohne Konsensmechanismen. Blockchain für Vertrauen und Verifikation, föderierte Suche für Informationsentdeckung.
Umfassende Quellenanalyse: Vor der Integration Bewertung der Quellenqualität, Aktualisierungshäufigkeit, Verfügbarkeit, Schema-Komplexität und Zugriffsprotokolle. Das verbessert die Quellenauswahl und Erwartungsmanagement.
Inkrementelle Integration: Start mit wenigen, gut verstandenen Quellen und schrittweiser Ausbau. So lassen sich Erfahrungen sammeln und Herausforderungen früh erkennen.
Robustes Metadatenmanagement: Investition in detaillierte Metadaten zu Schemata, Abdeckung, Qualität und Performance. Automatisches Monitoring und regelmäßige Validierung sichern deren Aktualität.
Intelligente Quellenauswahl: ML-basierte Auswahl, die aus vergangenen Abfragen lernt und die Strategien kontinuierlich optimiert.
Adaptives Timeout-Management: Flexible Timeouts, die sich an Antwortmuster und Systemauslastung anpassen – keine starren Zeitlimits.
Qualitätssicherung der Ergebnisse: Definition von Metriken für Relevanz, Aktualität und Vollständigkeit; Nutzerfeedback für Ranking-Modelle nutzen.
Umfassendes Monitoring: Überwachung von Verfügbarkeit, Antwortzeiten, Ergebnisqualität und Nutzerzufriedenheit – für Optimierung und Problemidentifikation.
Sicherheit und Zugriffskontrolle: Quellenseitige Zugriffsrechte auch im föderierten System durchsetzen; Nutzer dürfen nur autorisierte Informationen sehen.
Caching-Strategien: Intelligentes Caching auf mehreren Ebenen (Abfrageergebnisse, Metadaten, Query-Muster); Balance zwischen Aktualität und Performance.
Optimierung der Nutzererfahrung: Transparenz über Herkunft, Vertrauensniveau und Aktualität der Ergebnisse; Nutzerfreundliche Darstellung und Begründung der Rankings.
Performance-Optimierung: Identifikation von Engpässen, Optimierung von Auswahl, Übersetzung und Aggregation; ggf. Vorberechnung häufiger Muster.
Kontinuierliches Lernen: Feedbackschleifen zur ständigen Verbesserung von Auswahl, Ranking und Präsentation.
Dokumentation & Governance: Detaillierte Dokumentation von Quellen, Integrationswegen und Systemarchitektur; Policies für Quellenverwaltung.
Testing & Validierung: Umfassende Tests auf Komponenten-, Integrations- und End-to-End-Ebene; Ergebnisvalidierung gegen Referenzdaten.
Fortschrittliches Sprachverständnis: Zukünftig nutzen Systeme große Sprachmodelle und fortschrittliche NLP-Methoden, um komplexe, mehrdimensionale Abfragen mit implizitem Kontext und feiner Intention zu verstehen – für noch präzisere Quellenauswahl und Ergebnisinterpretation.
Autonome Quellenerkennung: ML-Systeme werden Datenquellen automatisch entdecken, bewerten und mit minimalem manuellem Aufwand in föderierte Systeme integrieren – das vereinfacht das Quellenmanagement.
Semantic-Web-Integration: Mit der Reife semantischer Webtechnologien werden Ontologien und Linked-Data-Standards für tiefere semantische Interoperabilität genutzt – für bessere Integration heterogener Datenmodelle.
Erklärbare KI & Transparenz: Systeme liefern künftig detaillierte Erklärungen für Rankings, Quellenauswahl und Aggregation – das stärkt das Nutzervertrauen und das Verständnis der Systemlogik.
Föderiertes Lernen: KI-Modelle werden über verteilte Quellen hinweg trainiert, ohne Daten zu zentralisieren – das vereint Autonomie mit den Stärken von Machine Learning.
Integration von Echtzeit-Streams: Föderierte Systeme werden zunehmend auch Echtzeitdatenströme integrieren – für Suche über kontinuierlich aktualisierte Quellen.
Multimodale Suche: Zukünftig wird über Text, Bilder, Videos und Audio hinweg gesucht. Multimodale KI-Modelle ermöglichen crossmediale Suche und Ergebnisaggregation.
Personalisierung & Kontextbewusstsein: Fortschrittliches User Modeling und Kontextverständnis führen zu hochgradig personalisierten Sucherlebnissen – Systeme erkennen Nutzerexpertise, Informationsbedarf und Präferenzen.
Quantencomputing-Anwendungen: Mit der Reife des Quantencomputings könnten Algorithmen zur Quellenauswahl und zum Ranking beschleunigt werden und so noch schnellere Abfragen ermöglichen.
Blockchain-Integration: Föderierte Systeme könnten Blockchain für Quellenverifikation, Ergebnis-Herkunftsnachweis und dezentrale Koordination nutzen – speziell für vertrauensrelevante Anwendungen.
Edge Computing & verteilte Verarbeitung: Quernahe Verarbeitung von Abfragen reduziert Latenz und erhöht Datenschutz durch Verarbeitung direkt an der Quelle.
Autonome Optimierung: Selbstoptimierende Systeme lernen laufend aus Abfragen, Quellen und Nutzerfeedback – für kontinuierliche Leistungssteigerung ohne manuelle Eingriffe.
Domänenübergreifende Wissensintegration: Zukunftssysteme verknüpfen Wissen aus bislang getrennten Domänen – für die Entdeckung neuer Zusammenhänge und Erkenntnisse aus vielfältigen Quellen.
Traditionelle zentralisierte Suche konsolidiert alle Daten in einem einzigen indizierten Repository, was Datenmigration erfordert und Latenz verursacht. Föderierte KI-Suche fragt mehrere unabhängige Quellen direkt in Echtzeit ab, ohne Daten zu verschieben oder zu duplizieren, und bewahrt die Autonomie der Quellen bei gleichzeitig einheitlichem Zugriff. Das macht föderierte Suche ideal für Organisationen mit verteilten Datenquellen und strengen Governance-Anforderungen.
Föderierte KI-Suche belässt Daten an ihrem Ursprungsort und respektiert die Zugriffs- und Sicherheitsrichtlinien jeder Quelle. Nutzer greifen nur auf Informationen zu, für die sie autorisiert sind, und sensible Daten verlassen nie das Quellsystem. Dieser Ansatz vereinfacht die Einhaltung von Vorschriften wie DSGVO und HIPAA, da die Risiken zentralisierter Speicherung entfallen.
Zentrale Herausforderungen sind das Management heterogener Datenquellen mit unterschiedlichen Schemata und Formaten, die Umgang mit Abfragelatenz aus mehreren Quellen, die Sicherstellung konsistenter Ergebnisrankings und die Systemzuverlässigkeit bei Ausfällen von Quellen. Zudem müssen Organisationen in robustes Metadatenmanagement und intelligente Quellenauswahl-Algorithmen investieren, um die Leistung zu optimieren.
Ja, föderierte KI-Suche skaliert durch das Hinzufügen neuer Quellen, ohne dass Datenmigration oder Umstrukturierung von Datenlagern nötig ist. Mit zunehmender Quellenzahl steigt jedoch der Koordinationsaufwand. Moderne Systeme nutzen maschinelles Lernen für intelligente Quellenauswahl und setzen Caching-Strategien ein, um die Leistung auch im großen Maßstab zu gewährleisten.
Data Warehousing konsolidiert Daten in einem zentralen Repository, was schnelle Abfragen ermöglicht, aber erheblichen ETL-Aufwand und Latenz verursacht. Föderierte Suche fragt Quellen direkt ab und bietet Echtzeit-Zugriff, allerdings mit höherer Abfragelatenz. Warehousing eignet sich für historische Analysen und Berichte, während föderierte Suche aktuelle Informationssuche über verteilte Quellen hinweg ermöglicht.
Gesundheitswesen, Finanzwesen, E-Commerce, Regierung und Forschungseinrichtungen profitieren besonders von föderierter Suche. Im Gesundheitswesen dient sie der Integration von Patientendaten verschiedener Anbieter, in der Finanzbranche der Compliance und Risikobewertung, im E-Commerce der einheitlichen Produktsuche und in der Forschung dem Zugriff auf verteilte wissenschaftliche Datenbanken.
KI verbessert föderierte Suche durch natürliche Sprachverarbeitung zur Abfrageverständnis, maschinelles Lernen für intelligente Quellenauswahl, semantische Analyse für besseres Ranking und automatisierte Duplikaterkennung. KI-Modelle lernen aus Abfragemustern und optimieren kontinuierlich Quellenauswahl und Ergebnisaggregation, was die Systemleistung langfristig steigert.
Semantisches Verständnis ermöglicht es föderierten Systemen, die Intention einer Abfrage über reine Schlüsselwortsuche hinaus zu erfassen, relevante Quellen genauer zu identifizieren und Ergebnisse nach Bedeutung statt bloßer Schlüsselwortübereinstimmung zu ranken. Dazu gehören Entitätserkennung, Beziehungsanalyse und Integration von Wissensgraphen, was relevantere und kontextgerechte Suchergebnisse liefert.
AmICited verfolgt, wie KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews Ihre Marke zitieren und referenzieren. Verstehen Sie Ihre Sichtbarkeit bei KI und optimieren Sie Ihre Präsenz in KI-generierten Antworten.
Erfahren Sie, wie KI-Suchindexierung Daten in durchsuchbare Vektoren umwandelt, sodass KI-Systeme wie ChatGPT und Perplexity relevante Informationen aus Ihren I...
Erfahren Sie, was KI-Suchmaschinen sind, wie sie sich von traditionellen Suchmaschinen unterscheiden und welche Auswirkungen sie auf die Sichtbarkeit von Marken...
Erfahren Sie, wie KI-Suchindizes funktionieren, die Unterschiede zwischen den Indizierungsmethoden von ChatGPT, Perplexity und SearchGPT sowie wie Sie Ihre Inha...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.