
ClaudeBot explicado: el rastreador de Anthropic y tu contenido
Descubre cómo funciona ClaudeBot, en qué se diferencia de Claude-Web y Claude-SearchBot, y cómo gestionar los rastreadores web de Anthropic en tu sitio web con ...
9 min de lectura

ClaudeBot es el rastreador web de Anthropic utilizado para recopilar datos de entrenamiento para los modelos de IA Claude. Rastrea sistemáticamente sitios web públicos para reunir contenido destinado al entrenamiento de modelos de aprendizaje automático. Los propietarios de sitios pueden controlar el acceso de ClaudeBot mediante la configuración de robots.txt. El rastreador respeta las directivas estándar de robots.txt, permitiendo que los sitios bloqueen o permitan sus visitas.
ClaudeBot es el rastreador web de Anthropic utilizado para recopilar datos de entrenamiento para los modelos de IA Claude. Rastrea sistemáticamente sitios web públicos para reunir contenido destinado al entrenamiento de modelos de aprendizaje automático. Los propietarios de sitios pueden controlar el acceso de ClaudeBot mediante la configuración de robots.txt. El rastreador respeta las directivas estándar de robots.txt, permitiendo que los sitios bloqueen o permitan sus visitas.
ClaudeBot es un rastreador web operado por Anthropic para descargar datos de entrenamiento para sus grandes modelos de lenguaje (LLM) que impulsan productos de IA como Claude. Este recolector de datos de IA rastrea sistemáticamente sitios web para recopilar contenido específicamente destinado al entrenamiento de modelos de aprendizaje automático, diferenciándose de los rastreadores tradicionales de motores de búsqueda que indexan el contenido para fines de recuperación. ClaudeBot puede identificarse mediante su cadena de agente de usuario y puede ser bloqueado o permitido a través de la configuración de robots.txt, lo que otorga a los propietarios de sitios control sobre si su contenido se utiliza para entrenar los modelos de IA de Anthropic.

ClaudeBot opera mediante métodos sistemáticos de descubrimiento web, incluyendo el seguimiento de enlaces desde sitios indexados, el procesamiento de sitemaps y el uso de URLs semilla de listas públicas de sitios web. El rastreador descarga contenido de sitios para incluirlo en los conjuntos de datos que se utilizan para entrenar los modelos de lenguaje de Claude, recopilando datos de páginas públicas sin requerir autenticación. A diferencia de los rastreadores de motores de búsqueda que priorizan la indexación para la recuperación, los patrones de rastreo de ClaudeBot suelen ser opacos, ya que Anthropic rara vez divulga criterios específicos de selección de sitios, frecuencia de rastreo o prioridades para distintos tipos de contenido.
La siguiente tabla compara a ClaudeBot con otros rastreadores de Anthropic:
| Nombre del bot | Propósito | User Agent | Alcance |
|---|---|---|---|
| ClaudeBot | Obtención de citas en chat y datos de entrenamiento | ClaudeBot/1.0 | Rastreo web general para entrenamiento de modelos |
| anthropic-ai | Recolección masiva de datos de entrenamiento | anthropic-ai | Compilación de grandes conjuntos de datos de entrenamiento |
| Claude-Web | Rastreo web para funciones de Claude | Claude-Web | Búsqueda web e información en tiempo real |
ClaudeBot opera de manera similar a otros rastreadores de entrenamiento de IA importantes como GPTBot (OpenAI) y PerplexityBot (Perplexity), pero con diferencias claras en alcance y metodología. Mientras que GPTBot se centra en las necesidades de entrenamiento de OpenAI y PerplexityBot cumple funciones tanto de búsqueda como de entrenamiento, ClaudeBot apunta específicamente a contenido para el entrenamiento del modelo de Claude. Según datos de Dark Visitors, aproximadamente el 18% de los 1.000 sitios web más importantes del mundo están bloqueando activamente a ClaudeBot, lo que indica una preocupación significativa de los editores respecto a sus prácticas de recopilación de datos. La distinción clave radica en cómo cada empresa prioriza la recopilación de contenido: el enfoque de Anthropic enfatiza el rastreo sistemático y amplio para datos de entrenamiento, mientras que los rastreadores orientados a la búsqueda equilibran la indexación con la generación de tráfico referido.
Los propietarios de sitios pueden identificar las visitas de ClaudeBot monitoreando los registros del servidor en busca de la característica cadena de agente de usuario: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot suele originarse desde rangos de IP de Estados Unidos, y sus visitas pueden rastrearse mediante el análisis de registros del servidor o herramientas de monitoreo dedicadas. Configurar plataformas de analítica de agentes proporciona visibilidad en tiempo real sobre las visitas de ClaudeBot, permitiendo a los propietarios medir la frecuencia y los patrones de rastreo.
Aquí tienes un ejemplo de cómo aparece ClaudeBot en los registros del servidor:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
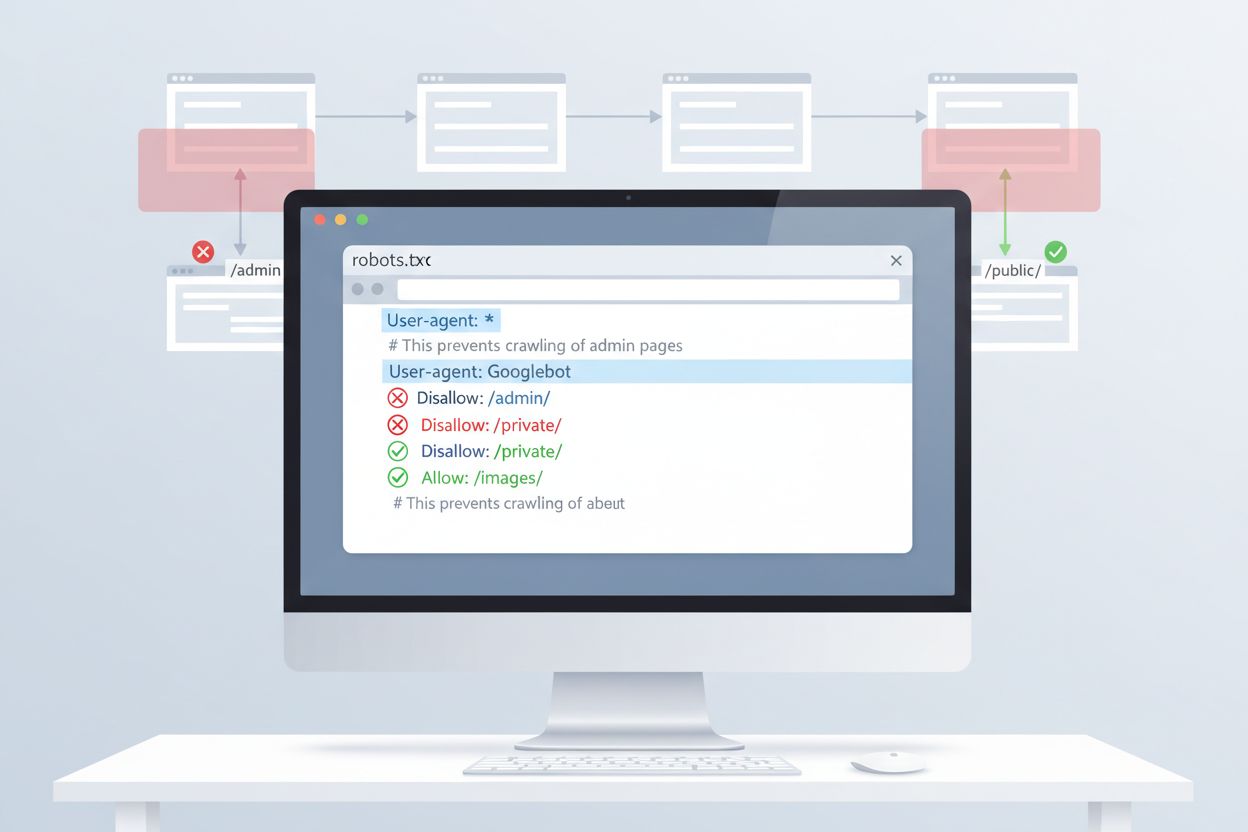
El método más sencillo para controlar el acceso de ClaudeBot es mediante la configuración de robots.txt en el directorio raíz de tu sitio web. Este archivo indica a los rastreadores qué partes de tu sitio pueden acceder, y ClaudeBot de Anthropic respeta estas directivas. Para bloquear toda la actividad de ClaudeBot, añade las siguientes reglas a tu archivo robots.txt:
User-agent: ClaudeBot
Disallow: /
Para un bloqueo más selectivo que impida a ClaudeBot acceder a directorios específicos mientras se permite el rastreo de otro contenido, usa:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Si deseas bloquear a todos los rastreadores de Anthropic (incluidos anthropic-ai y Claude-Web), añade reglas separadas para cada uno:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Aunque robots.txt proporciona la primera línea de defensa, su cumplimiento es voluntario. Para los editores que requieren una protección más fuerte, existen varios métodos de bloqueo adicionales:
Estos métodos requieren mayor experiencia técnica que la configuración de robots.txt, pero ofrecen una protección más sólida ante rastreadores que no cumplen las reglas.
Bloquear a ClaudeBot tiene un impacto directo mínimo en el posicionamiento SEO tradicional, ya que los rastreadores de entrenamiento no contribuyen a la indexación en motores de búsqueda: Google, Bing y otros utilizan rastreadores diferentes (Googlebot, Bingbot) que operan de manera independiente. Sin embargo, bloquear a ClaudeBot puede reducir la representación de tu contenido en respuestas generadas por IA de Claude, lo que podría afectar la visibilidad futura a través de búsquedas y chats de IA. La decisión estratégica de bloquear o permitir a ClaudeBot depende de tu modelo de monetización de contenido: si tus ingresos dependen del tráfico directo y de impresiones publicitarias, bloquear evita que tu contenido se absorba en conjuntos de datos de entrenamiento que puedan reducir el número de visitantes. Por el contrario, permitir a ClaudeBot puede aumentar tu visibilidad en las respuestas de Claude, generando potencialmente tráfico referido de usuarios de chats de IA.
Una gestión efectiva de ClaudeBot requiere monitoreo y pruebas continuas de tu configuración. Utiliza herramientas como el probador de robots.txt de Google Search Console, la herramienta de prueba de robots.txt de Merkle o plataformas especializadas como Dark Visitors para verificar que tus reglas de bloqueo funcionen correctamente. Revisa periódicamente los registros de tu servidor para confirmar si ClaudeBot respeta tus directivas de robots.txt y monitorea cualquier cambio en los patrones de rastreo. Dado que el panorama de rastreadores de IA evoluciona rápidamente con la aparición de nuevos bots, revisa tu configuración de robots.txt cada trimestre para asegurarte de que estás abordando rastreadores emergentes y manteniendo la protección de tu contenido. Probar tu configuración antes de implementarla evita el bloqueo accidental de motores de búsqueda legítimos u otros rastreadores importantes.
ClaudeBot es el rastreador web de Anthropic que visita sistemáticamente sitios web para recopilar datos de entrenamiento para los modelos de IA Claude. Descubre tu sitio siguiendo enlaces, procesando sitemaps o a través de listas públicas de sitios web. El rastreador recopila contenido público para mejorar las capacidades del modelo de lenguaje de Claude.
Puedes bloquear a ClaudeBot añadiendo una regla en robots.txt en el directorio raíz de tu sitio. Simplemente agrega 'User-agent: ClaudeBot' seguido de 'Disallow: /' para evitar todo acceso, o especifica rutas concretas para bloquear selectivamente. ClaudeBot de Anthropic respeta las directivas de robots.txt.
No, bloquear a ClaudeBot no afectará tu posicionamiento en Google o Bing. Los rastreadores de entrenamiento como ClaudeBot funcionan de manera independiente a los motores de búsqueda tradicionales. Solo bloquear Googlebot o Bingbot afectaría tu rendimiento SEO.
Anthropic opera tres rastreadores principales: ClaudeBot (obtención de citas en chat y datos de entrenamiento general), anthropic-ai (recolección masiva de datos de entrenamiento) y Claude-Web (rastreo web para funciones en tiempo real). Cada uno cumple distintos propósitos dentro de la infraestructura de IA de Anthropic.
Revisa los registros de tu servidor para buscar la cadena de agente de usuario de ClaudeBot: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. También puedes usar herramientas de monitoreo como Dark Visitors o configurar analíticas de agentes para rastrear las visitas de ClaudeBot en tiempo real.
Sí, ClaudeBot respeta las directivas de robots.txt según la documentación oficial de Anthropic. Sin embargo, como ocurre con todas las reglas de robots.txt, el cumplimiento es voluntario. Para una protección más fuerte, puedes implementar bloqueos a nivel de servidor, filtrado por IP o reglas WAF.
ClaudeBot puede consumir un ancho de banda significativo dependiendo del tamaño y volumen de contenido de tu sitio. Los recolectores de datos para IA pueden rastrear de forma más agresiva que los motores de búsqueda tradicionales. Monitorea los registros de tu servidor para entender el impacto y decidir si bloquear o permitir el rastreador.
La decisión depende de tu modelo de negocio. Bloquea a ClaudeBot si te preocupan la atribución de contenido, la compensación o el uso de tu trabajo en sistemas de IA. Permítelo si deseas que tu contenido aparezca en las respuestas y resultados de búsqueda de Claude. Considera tu estrategia de monetización de tráfico antes de decidir.
Supervisa a ClaudeBot y otros rastreadores de IA que acceden a tu contenido. Obtén información sobre qué sistemas de IA citan tu marca y cómo se utiliza tu contenido en respuestas generadas por IA.
Descubre cómo funciona ClaudeBot, en qué se diferencia de Claude-Web y Claude-SearchBot, y cómo gestionar los rastreadores web de Anthropic en tu sitio web con ...
Claude es el avanzado asistente de IA de Anthropic impulsado por IA Constitucional. Descubra cómo funciona Claude, sus características clave, mecanismos de segu...

Descubre qué es CCBot, cómo funciona y cómo bloquearlo. Comprende su papel en el entrenamiento de IA, herramientas de monitoreo y mejores prácticas para protege...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.