
ClaudeBot forklaret: Anthropics crawler og dit indhold
Lær hvordan ClaudeBot fungerer, hvordan den adskiller sig fra Claude-Web og Claude-SearchBot, og hvordan du håndterer Anthropics webcrawlers på dit website med ...
7 min læsning

ClaudeBot er Anthropics webcrawler, der bruges til at indsamle træningsdata til Claude AI-modeller. Den crawlersystematisk offentligt tilgængelige websites for at indsamle indhold til maskinlæringsmodellens træning. Websiteejere kan styre ClaudeBots adgang via robots.txt-konfiguration. Crawleren respekterer standard robots.txt-direktiver, hvilket gør det muligt for sider at blokere eller tillade dens besøg.
ClaudeBot er Anthropics webcrawler, der bruges til at indsamle træningsdata til Claude AI-modeller. Den crawlersystematisk offentligt tilgængelige websites for at indsamle indhold til maskinlæringsmodellens træning. Websiteejere kan styre ClaudeBots adgang via robots.txt-konfiguration. Crawleren respekterer standard robots.txt-direktiver, hvilket gør det muligt for sider at blokere eller tillade dens besøg.
ClaudeBot er en webcrawler drevet af Anthropic til at downloade træningsdata til deres store sprogmodeller (LLMs), som driver AI-produkter som Claude. Denne AI-datascraper crawler systematisk websites for at indsamle indhold specifikt til maskinlæringsmodellens træning og adskiller sig dermed fra traditionelle søgemaskinecrawlere, der indekserer indhold til søgning. ClaudeBot kan identificeres ved sin user agent-streng og kan blokeres eller tillades via robots.txt-konfiguration, hvilket giver websiteejere kontrol over, om deres indhold bruges til træning af Anthropics AI-modeller.

ClaudeBot opererer gennem systematiske webopdagelsesmetoder, herunder følgning af links fra indekserede sider, behandling af sitemaps og brug af seed-URLs fra offentligt tilgængelige websitlister. Crawleren downloader websiteindhold til brug i datasæt til træning af Claudes sprogmodeller og indsamler data fra offentligt tilgængelige sider uden krav om login. I modsætning til søgemaskinecrawlere, der prioriterer indeksering til opslag, er ClaudeBots crawlingmønstre typisk uklare, idet Anthropic sjældent oplyser specifikke kriterier for sitevalg, crawlingsfrekvens eller prioritering af forskellige indholdstyper.
Følgende tabel sammenligner ClaudeBot med andre Anthropic-crawlere:
| Botnavn | Formål | User Agent | Omfang |
|---|---|---|---|
| ClaudeBot | Chat-citationsindhentning og træningsdata | ClaudeBot/1.0 | Generel webcrawling til modeltræning |
| anthropic-ai | Masseindsamling af træningsdata | anthropic-ai | Storskaladatasæt til træningsformål |
| Claude-Web | Webfokuseret crawling til Claude-funktioner | Claude-Web | Websøgning og realtidsinformation |
ClaudeBot opererer på lignende vis som andre store AI-træningscrawlere som GPTBot (OpenAI) og PerplexityBot (Perplexity), men med tydelige forskelle i omfang og metode. Hvor GPTBot fokuserer på OpenAIs træningsbehov og PerplexityBot både tjener søgning og træning, sigter ClaudeBot specifikt mod indhold til Claudes modeltræning. Ifølge Dark Visitors-data blokerer cirka 18% af verdens 1.000 største websites aktivt ClaudeBot, hvilket indikerer betydelig bekymring blandt udgivere over dens dataindsamling. Den primære forskel ligger i, hvordan hvert firma prioriterer indsamling—Anthropics tilgang vægter systematisk, bred crawling til træningsdata, mens søgefokuserede crawlere balancerer indeksering med at skabe henvisningstrafik.
Websiteejere kan identificere ClaudeBot-besøg ved at overvåge serverlogs for den karakteristiske user agent-streng: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot udgår typisk fra amerikanske IP-adresser, og besøg kan spores via serverloganalyser eller dedikerede overvågningsværktøjer. Opsætning af agentanalyseplatforme giver realtidsindsigt i ClaudeBot-besøg, så ejere kan måle crawlingfrekvens og mønstre.
Her er et eksempel på, hvordan ClaudeBot ser ud i serverlogs:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
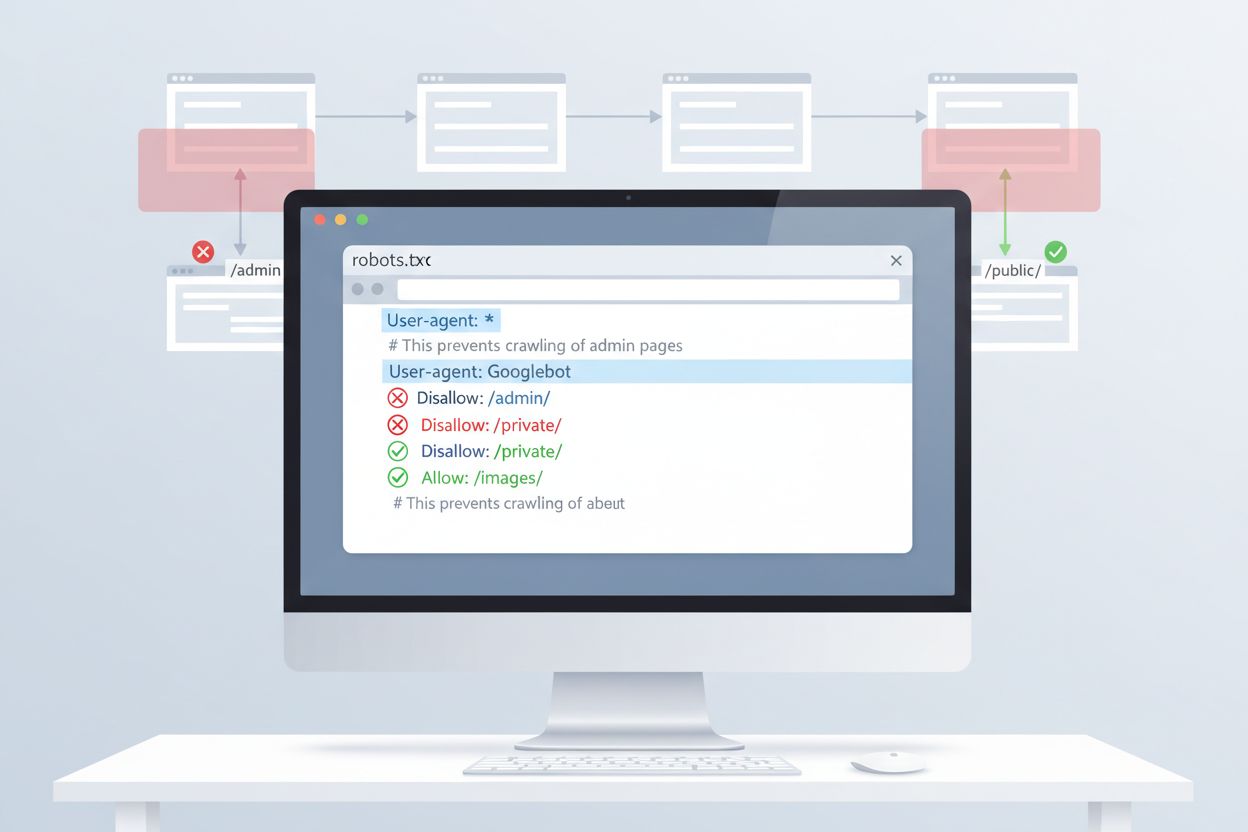
Den mest enkle metode til at styre ClaudeBots adgang er via robots.txt-konfiguration i dit websites rodkatalog. Denne fil fortæller crawlere, hvilke dele af dit website de må tilgå, og Anthropics ClaudeBot respekterer disse direktiver. For at blokere al ClaudeBot-aktivitet skal du tilføje følgende regler til din robots.txt-fil:
User-agent: ClaudeBot
Disallow: /
For mere selektiv blokering, der forhindrer ClaudeBot i at tilgå specifikke mapper, men tillader andet indhold at blive crawlet:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Hvis du vil blokere alle Anthropics crawlere (inklusive anthropic-ai og Claude-Web), skal du tilføje særskilte regler for hver:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Selvom robots.txt er første forsvarslinje, bygger den på frivillig overholdelse. For udgivere med behov for stærkere håndhævelse findes flere yderligere blokeringsmetoder:
Disse metoder kræver mere teknisk viden end robots.txt-konfiguration, men giver stærkere håndhævelse over for ikke-kompatible crawlere.
At blokere ClaudeBot har minimal direkte indflydelse på traditionelle SEO-placeringer, da træningscrawlere ikke bidrager til søgemaskineindeksering—Google, Bing og andre søgemaskiner bruger separate crawlere (Googlebot, Bingbot), som opererer uafhængigt. Blokering af ClaudeBot kan dog mindske dit indholds repræsentation i AI-genererede svar fra Claude, hvilket potentielt kan påvirke fremtidig synlighed via AI-søgning og chatgrænseflader. Den strategiske beslutning om at blokere eller tillade ClaudeBot afhænger af din indtægtsmodel: Hvis din indtjening afhænger af direkte webtrafik og annoncevisninger, forhindrer blokering, at dit indhold bliver brugt i træningsdatasæt, der kan mindske besøgstallet. Omvendt kan tilladelse af ClaudeBot øge din synlighed i Claudes svar og potentielt give henvisningstrafik fra AI-chatbrugere.
Effektiv håndtering af ClaudeBot kræver løbende overvågning og test af din konfiguration. Brug værktøjer som Google Search Consoles robots.txt-tester, Merkles robots.txt-testværktøj eller specialiserede platforme som Dark Visitors for at sikre, at dine blokeringsregler fungerer efter hensigten. Gennemgå regelmæssigt dine serverlogs for at bekræfte, at ClaudeBot respekterer dine robots.txt-direktiver, og overvåg for ændringer i crawlingmønstre. Da AI-crawlerlandskabet udvikler sig hurtigt med nye bots, der opdages løbende, sikrer kvartalsvise gennemgange af din robots.txt-konfiguration, at du håndterer nye crawlere og opretholder beskyttelsesstrategien. Test af din konfiguration før implementering forhindrer utilsigtet blokering af legitime søgemaskiner eller andre vigtige crawlere.
Følg ClaudeBot og andre AI-crawlers, der tilgår dit indhold. Få indsigt i, hvilke AI-systemer der citerer dit brand, og hvordan dit indhold bruges i AI-genererede svar.
Lær hvordan ClaudeBot fungerer, hvordan den adskiller sig fra Claude-Web og Claude-SearchBot, og hvordan du håndterer Anthropics webcrawlers på dit website med ...

Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...

Lær hvordan du bruger robots.txt til at kontrollere, hvilke AI-bots der får adgang til dit indhold. Komplet guide til blokering af GPTBot, ClaudeBot og andre AI...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.