Fondements et recherche web : quand les LLMs cherchent des informations fraîches
Découvrez comment l’ancrage des LLMs et la recherche web permettent aux systèmes d’IA d’accéder à l’information en temps réel, de réduire les hallucinations et de fournir des citations précises. Apprenez le RAG, les stratégies de mise en œuvre et les meilleures pratiques en entreprise.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
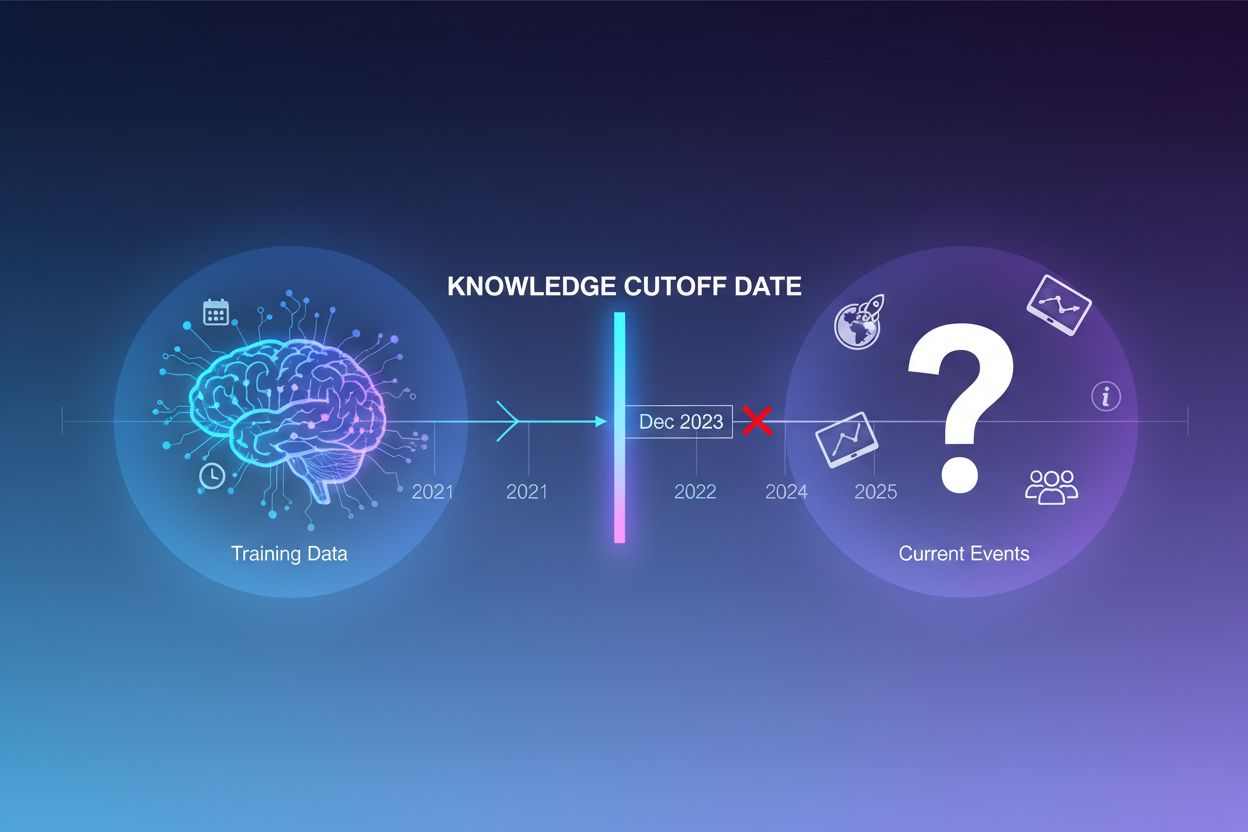
Le problème de la date de coupure des connaissances
Les grands modèles de langage sont entraînés sur d’immenses volumes de textes, mais ce processus a une limite critique : il ne capture que l’information disponible jusqu’à une date précise, appelée date de coupure des connaissances. Par exemple, si un LLM a été entraîné avec des données allant jusqu’à décembre 2023, il n’a aucune connaissance des événements, découvertes ou développements survenus après cette date. Lorsque les utilisateurs posent des questions sur l’actualité, de nouveaux produits ou des informations récentes, le modèle ne peut pas accéder à ces informations dans ses données d’entraînement. Au lieu d’admettre son incertitude, le LLM génère souvent des réponses plausibles mais incorrectes—un phénomène appelé hallucination. Cette tendance devient particulièrement problématique dans les applications où la précision est cruciale, comme le support client, le conseil financier ou l’information médicale, où des informations obsolètes ou inventées peuvent avoir de graves conséquences.
Comprendre les fondamentaux de l’ancrage des LLMs
L’ancrage consiste à augmenter les connaissances pré-entraînées d’un LLM avec des informations contextuelles externes au moment de l’inférence. Plutôt que de s’appuyer uniquement sur les schémas appris pendant l’entraînement, l’ancrage relie le modèle à des sources de données réelles—qu’il s’agisse de pages web, de documents internes, de bases de données ou d’APIs. Ce concept s’inspire de la psychologie cognitive, notamment la théorie de la cognition située, qui postule que la connaissance s’applique efficacement lorsqu’elle est ancrée dans le contexte où elle sera utilisée. Concrètement, l’ancrage transforme la tâche de « générer une réponse de mémoire » en « synthétiser une réponse à partir des informations fournies ». Une définition stricte issue de recherches récentes exige que le LLM utilise toutes les connaissances essentielles du contexte fourni et respecte sa portée sans halluciner d’informations supplémentaires.
Aspect
Réponse non ancrée
Réponse ancrée
Source d’information
Connaissances pré-entraînées uniquement
Connaissances pré-entraînées + données externes
Précision sur l’actualité
Faible (limites de la date de coupure)
Élevée (accès à l’information actuelle)
Risque d’hallucination
Élevé (le modèle devine)
Faible (contraint par le contexte fourni)
Possibilité de citation
Limitée ou impossible
Traçabilité totale vers les sources
Scalabilité
Fixe (taille du modèle)
Flexible (ajout de nouvelles sources de données)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
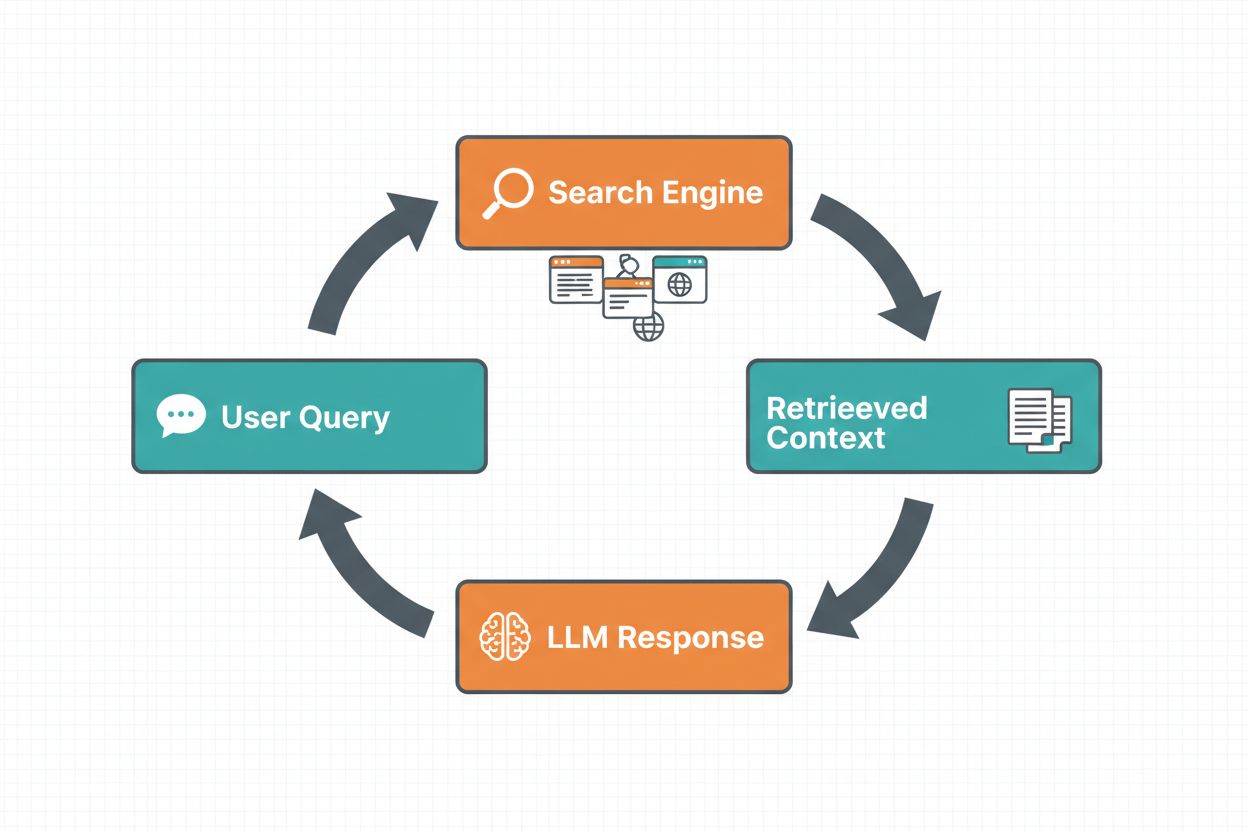
L’ancrage par recherche web permet aux LLMs d’accéder à l’information en temps réel en recherchant automatiquement sur le web et en intégrant les résultats dans le processus de génération de réponse du modèle. Le déroulement suit une séquence structurée : d’abord, le système analyse l’invite de l’utilisateur pour déterminer si une recherche web améliorerait la réponse ; ensuite, il génère une ou plusieurs requêtes optimisées pour obtenir des informations pertinentes ; puis, il exécute ces requêtes sur un moteur de recherche (comme Google Search ou DuckDuckGo) ; ensuite, il traite les résultats et extrait les contenus pertinents ; enfin, il fournit ce contexte au LLM dans l’invite, permettant au modèle de générer une réponse ancrée. Le système retourne également des métadonnées d’ancrage—informations structurées sur les requêtes exécutées, les sources récupérées et la façon dont chaque partie de la réponse est étayée par ces sources. Ces métadonnées sont essentielles pour instaurer la confiance et permettre la vérification des affirmations.
Schéma de l’ancrage par recherche web :
Analyse de l’invite : Le modèle décide si une recherche web est nécessaire
Génération de requête : Crée des requêtes optimisées à partir de la demande utilisateur
Exécution de la recherche web : Récupère les résultats des moteurs de recherche
Traitement des résultats : Extrait et classe les informations pertinentes
Injection de contexte : Ajoute les résultats à l’invite du LLM
Réponse ancrée : Le modèle génère une réponse avec citations
Retour de métadonnées : Fournit les sources et preuves à l’appui
Retrieval Augmented Generation (RAG) – La stratégie dominante
La génération augmentée par récupération (RAG) est devenue la technique d’ancrage dominante, combinant des décennies de recherche en recherche d’information avec les capacités modernes des LLMs. Le RAG fonctionne en récupérant d’abord des documents ou passages pertinents à partir d’une source de connaissance externe (généralement indexée dans une base vectorielle), puis en fournissant ces éléments récupérés en contexte au LLM. Le processus de récupération comporte généralement deux étapes : un retriever utilise des algorithmes efficaces (comme BM25 ou la recherche sémantique avec embeddings) pour identifier les documents candidats, puis un ranker utilise des modèles neuronaux plus sophistiqués pour reclasser ces candidats selon leur pertinence. Le contexte récupéré est ensuite intégré à l’invite, permettant au LLM de synthétiser des réponses ancrées sur des informations fiables. Le RAG offre des avantages significatifs par rapport à l’ajustement fin : il est plus économique (pas besoin de réentraîner le modèle), plus évolutif (il suffit d’ajouter de nouveaux documents à la base de connaissances) et plus facile à maintenir (mise à jour de l’information sans réentraînement). Par exemple, une invite RAG pourrait être :
Utilisez les documents suivants pour répondre à la question.
[Question]
Quelle est la capitale du Canada ?
[Document 1]
Ottawa est la capitale du Canada, située en Ontario...
[Document 2]
Le Canada est un pays d’Amérique du Nord composé de dix provinces...
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Accès à l’information en temps réel et citations
L’un des avantages les plus convaincants de l’ancrage par recherche web est la capacité à accéder à de l’information en temps réel et à l’intégrer dans les réponses du LLM. C’est particulièrement précieux pour les applications nécessitant des données actuelles—analyse d’actualité, études de marché, informations sur les événements ou disponibilité de produits. Au-delà du simple accès à l’information fraîche, l’ancrage permet d’obtenir des citations et l’attribution des sources, essentiel pour instaurer la confiance et permettre la vérification. Lorsqu’un LLM génère une réponse ancrée, il retourne des métadonnées structurées qui relient chaque affirmation à ses documents sources, permettant des citations intégrées comme « [1] source.com » directement dans le texte de la réponse. Cette capacité est directement liée à la mission de plateformes comme AmICited.com, qui surveille la façon dont les systèmes d’IA référencent les sources sur différentes plateformes. La possibilité de suivre quelles sources un système d’IA a consultées et comment il a attribué l’information devient de plus en plus importante pour la veille de marque, l’attribution de contenu et la garantie d’un déploiement responsable de l’IA.
Réduire les hallucinations grâce à l’ancrage
Les hallucinations surviennent parce que les LLMs sont essentiellement conçus pour prédire le prochain token à partir des tokens précédents et des schémas appris, sans compréhension intrinsèque des limites de leurs connaissances. Face à des questions hors de leur base d’entraînement, ils continuent de générer un texte plausible plutôt que d’avouer leur incertitude. L’ancrage change fondamentalement la tâche du modèle : au lieu de générer à partir de la mémoire, il synthétise à partir de l’information fournie. D’un point de vue technique, lorsque du contexte externe pertinent est inclus dans l’invite, cela oriente la distribution de probabilité des tokens vers des réponses fondées sur ce contexte, rendant les hallucinations moins probables. Les recherches démontrent que l’ancrage peut réduire les taux d’hallucination de 30 à 50 % selon la tâche et la mise en œuvre. Par exemple, à la question « Qui a gagné l’Euro 2024 ? » sans ancrage, un ancien modèle peut donner une réponse erronée ; avec ancrage et résultats de recherche web, il identifie correctement l’Espagne comme vainqueur avec des détails précis sur le match. Ce mécanisme fonctionne car l’attention du modèle peut alors se concentrer sur le contexte fourni plutôt que sur des schémas d’entraînement potentiellement incomplets ou contradictoires.
Mise en œuvre de l’ancrage web – Approches pratiques
Mettre en œuvre l’ancrage par recherche web implique l’intégration de plusieurs composants : une API de recherche (telle que Google Search, DuckDuckGo via Serp API ou Bing Search), une logique pour déterminer quand l’ancrage est nécessaire, et un prompt engineering pour intégrer efficacement les résultats de recherche. Une implémentation pratique commence généralement par l’évaluation du besoin d’information actuelle dans la requête utilisateur—cela peut se faire en demandant au LLM lui-même si l’invite nécessite une information postérieure à sa date de coupure. Si l’ancrage est requis, le système effectue une recherche web, traite les résultats pour extraire les fragments pertinents et construit une invite contenant la question originale et le contexte issu de la recherche. Le coût est un élément important : chaque recherche web génère des frais d’API, donc la mise en place de l’ancrage dynamique (ne rechercher que si nécessaire) permet de réduire significativement les dépenses. Par exemple, une question comme « Pourquoi le ciel est-il bleu ? » n’a probablement pas besoin de recherche web, alors que « Qui est le président actuel ? » oui. Les implémentations avancées utilisent de petits modèles plus rapides pour décider de la nécessité d’ancrage, réduisant la latence et les coûts, tout en réservant les grands modèles à la génération finale de la réponse.
Défis et stratégies d’optimisation
Si l’ancrage est puissant, il introduit plusieurs défis à gérer avec soin. La pertinence des données est cruciale : si l’information récupérée ne répond pas réellement à la question de l’utilisateur, l’ancrage sera inutile, voire source de contexte hors-sujet. La quantité de données pose un paradoxe : plus d’information paraît bénéfique, mais les recherches montrent que la performance des LLMs diminue souvent avec trop d’input, un phénomène appelé biais « perdu au milieu » où le modèle peine à exploiter l’information placée au centre de longs contextes. L’efficacité des tokens devient un enjeu car chaque fragment de contexte récupéré consomme des tokens, augmentant la latence et le coût. Le principe du « moins, c’est mieux » s’applique : ne récupérer que les k résultats les plus pertinents (généralement 3 à 5), travailler avec de petits fragments plutôt que des documents entiers, et extraire les phrases clés des passages longs.
Défi
Impact
Solution
Pertinence des données
Un contexte hors-sujet perturbe le modèle
Utiliser la recherche sémantique + rankers ; tester la qualité du retrieval
Biais perdu au milieu
Le modèle manque l’info importante au centre
Réduire la taille de l’input ; placer l’info critique au début/à la fin
Efficacité des tokens
Latence et coût élevés
Récupérer moins de résultats ; utiliser de petits fragments
Information obsolète
Contexte dépassé dans la base de connaissance
Mettre en place des politiques d’actualisation ; gestion de version
Latence
Réponses lentes (recherche + inférence)
Utiliser des opérations asynchrones ; mettre en cache les requêtes fréquentes
Ancrage en production – Enjeux pour l’entreprise
Déployer des systèmes d’ancrage en production nécessite une attention particulière à la gouvernance, la sécurité et l’exploitation. L’assurance qualité des données est fondamentale : l’information sur laquelle vous vous basez doit être exacte, à jour et pertinente pour vos cas d’usage. Le contrôle d’accès devient critique si vous ancrez sur des documents sensibles ou propriétaires ; il faut s’assurer que le LLM n’accède qu’aux informations autorisées pour chaque utilisateur selon ses droits. La gestion des mises à jour et des dérives implique de définir des politiques de rafraîchissement de la base de connaissance et de gestion des conflits d’information entre sources. La journalisation des audits est essentielle pour la conformité et le débogage : il faut tracer quels documents ont été récupérés, comment ils ont été classés et quel contexte a été fourni au modèle. Autres points à considérer :
Mettre en place des boucles de retour utilisateur pour identifier et corriger les échecs d’ancrage
Surveiller l’utilisation des tokens pour optimiser les coûts
Instaurer le contrôle de version des mises à jour de la base de connaissance
Assurer la conformité aux réglementations sur la protection des données (RGPD, HIPAA, etc.)
Suivre le comportement du modèle pour détecter les dérives ou la dégradation dans le temps
Futur de l’ancrage et tendances émergentes
Le domaine de l’ancrage des LLMs évolue rapidement au-delà de la simple récupération de texte. L’ancrage multimodal émerge, permettant d’ancrer les réponses sur des images, des vidéos et des données structurées en plus du texte—particulièrement important pour des domaines comme l’analyse juridique, l’imagerie médicale ou la documentation technique. Le raisonnement automatisé se superpose au RAG, permettant aux agents non seulement de récupérer de l’information mais aussi de synthétiser plusieurs sources, de tirer des conclusions logiques et d’expliquer leur raisonnement. Les garde-fous sont intégrés à l’ancrage pour que, même avec accès à des informations externes, les modèles respectent les contraintes de sécurité et les politiques internes. Les mises à jour in situ du modèle représentent un autre axe : plutôt que de compter uniquement sur la récupération externe, la recherche explore la possibilité de mettre à jour directement les poids du modèle avec de nouvelles informations, ce qui pourrait réduire le besoin de grandes bases de connaissances externes. Ces avancées laissent entrevoir des systèmes d’ancrage toujours plus intelligents, efficaces et capables de gérer des tâches complexes de raisonnement tout en maintenant précision factuelle et traçabilité.
Questions fréquemment posées
Quelle est la différence entre l’ancrage et l’ajustement fin ?
L’ancrage enrichit un LLM avec des informations externes au moment de l’inférence sans modifier le modèle lui-même, tandis que l’ajustement fin consiste à réentraîner le modèle sur de nouvelles données. L’ancrage est plus économique, plus rapide à mettre en œuvre et plus facile à mettre à jour avec de nouvelles informations. L’ajustement fin est préférable lorsque vous devez changer fondamentalement le comportement du modèle ou lorsqu’il y a des schémas spécifiques à un domaine à apprendre.
Comment l’ancrage réduit-il les hallucinations ?
L’ancrage réduit les hallucinations en fournissant au LLM un contexte factuel dont il peut s’inspirer au lieu de se fier uniquement à ses données d’entraînement. Lorsque des informations externes pertinentes sont incluses dans l’invite, cela oriente la distribution de probabilité des tokens du modèle vers des réponses fondées sur ce contexte, rendant les informations inventées moins probables. Les recherches montrent que l’ancrage peut réduire les taux d’hallucination de 30 à 50 %.
Qu’est-ce que le RAG et pourquoi est-il important ?
La génération augmentée par récupération (RAG) est une technique d’ancrage qui récupère des documents pertinents à partir d’une source de connaissance externe et les fournit en contexte au LLM. Le RAG est important car il est évolutif, économique et permet de mettre à jour l’information sans réentraîner le modèle. C’est devenu la norme dans l’industrie pour construire des applications IA fondées sur des sources fiables.
Quand dois-je mettre en œuvre l’ancrage par recherche web ?
Mettez en place l’ancrage par recherche web lorsque votre application nécessite un accès à des informations actuelles (actualités, événements, données récentes), quand l’exactitude et les citations sont essentielles, ou si la date de coupure des connaissances de votre LLM est une limite. Utilisez l’ancrage dynamique pour ne chercher que lorsque c’est nécessaire, réduisant ainsi les coûts et la latence pour les requêtes qui ne nécessitent pas d’informations fraîches.
Quels sont les principaux défis de la mise en œuvre de l’ancrage ?
Les principaux défis incluent la pertinence des données (l’information récupérée doit vraiment répondre à la question), la gestion de la quantité de données (plus n’est pas toujours mieux), la gestion du biais « perdu au milieu » où les modèles manquent l’information dans de longs contextes, et l’optimisation de l’efficacité des tokens. Les solutions incluent l’utilisation de la recherche sémantique avec des rankers, la récupération de moins de résultats mais de meilleure qualité, et le placement des informations critiques au début ou à la fin du contexte.
Comment l’ancrage est-il lié à la surveillance des réponses IA ?
L’ancrage est directement lié à la surveillance des réponses IA car il permet aux systèmes de fournir des citations et l’attribution des sources. Des plateformes comme AmICited suivent la façon dont les systèmes d’IA référencent les sources, ce qui n’est possible que lorsque l’ancrage est correctement mis en œuvre. Cela permet de garantir un déploiement responsable de l’IA et l’attribution de la marque sur différentes plateformes d’IA.
Qu’est-ce que le biais « perdu au milieu » ?
Le biais « perdu au milieu » est un phénomène où les LLMs sont moins performants lorsque l’information pertinente est placée au milieu de longs contextes, comparé à une information placée au début ou à la fin. Cela se produit car les modèles ont tendance à « survoler » lors du traitement de grandes quantités de texte. Les solutions incluent la réduction de la taille de l’entrée, le placement des informations critiques aux emplacements privilégiés et l’utilisation de petits fragments de texte.
Comment optimiser l’ancrage pour un déploiement en production ?
Pour un déploiement en production, concentrez-vous sur l’assurance qualité des données, mettez en place des contrôles d’accès pour les informations sensibles, établissez des politiques de mise à jour et d’actualisation, activez la journalisation des audits pour la conformité et créez des boucles de retour utilisateur pour identifier les échecs. Surveillez l’utilisation des tokens pour optimiser les coûts, mettez en place un contrôle de version pour les bases de connaissances et suivez le comportement du modèle pour détecter les dérives.
Surveillez comment les systèmes d’IA citent votre marque
AmICited suit comment GPTs, Perplexity et Google AI Overviews citent et référencent votre contenu. Obtenez des analyses en temps réel sur la surveillance des réponses IA et l’attribution de marque.
Hallucinations de l'IA et sécurité de la marque : Protéger votre réputation
Découvrez comment les hallucinations de l'IA menacent la sécurité de la marque sur Google AI Overviews, ChatGPT et Perplexity. Découvrez des stratégies de surve...
Découvrez comment la génération augmentée par récupération transforme les citations de l'IA, permettant une attribution précise des sources et des réponses étay...
Qu'est-ce que l'hallucination de l'IA : Définition, causes et impact sur la recherche IA
Découvrez ce qu'est l'hallucination de l'IA, pourquoi elle se produit dans ChatGPT, Claude et Perplexity, et comment détecter les fausses informations générées ...
16 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.