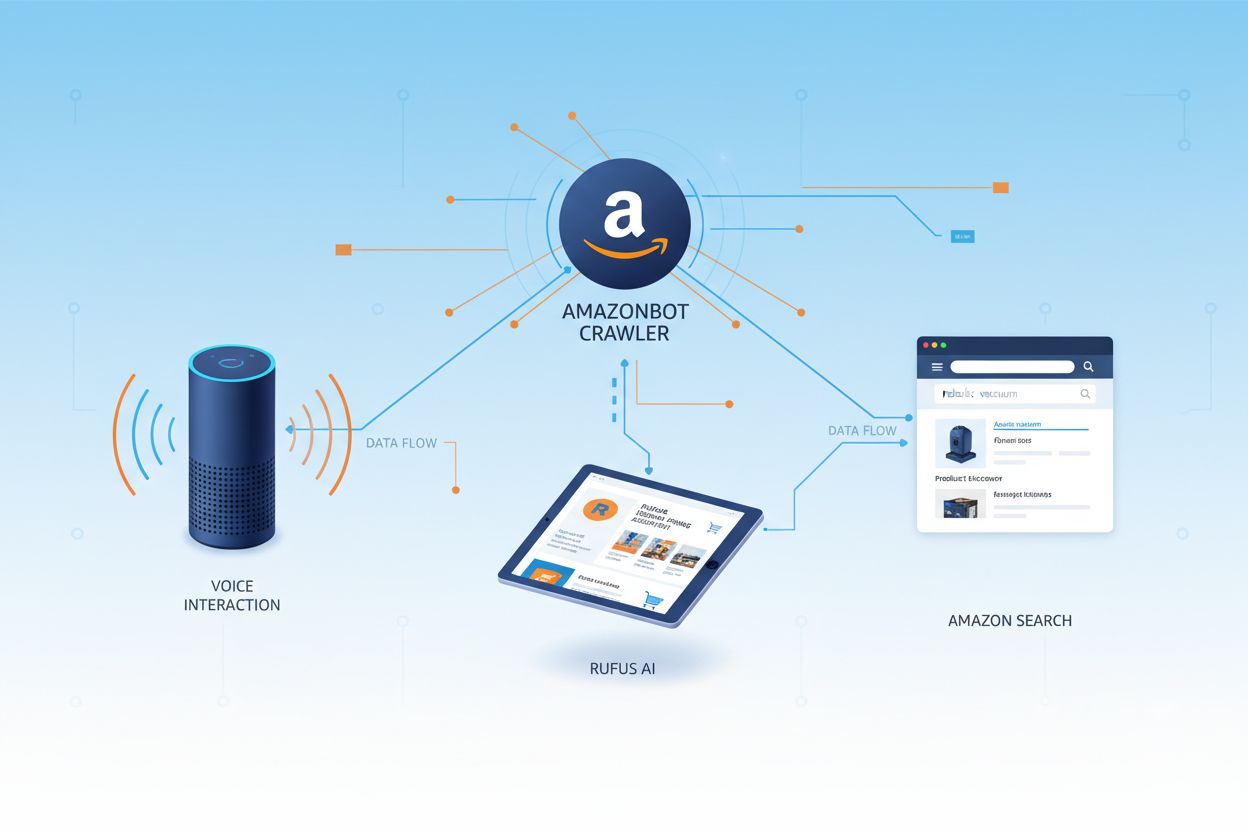
Le robot d’exploration web d’Amazon utilisé pour améliorer les produits et services, y compris Alexa, l’assistant d’achat Rufus, et les fonctionnalités de recherche alimentées par l’IA d’Amazon. Il respecte le protocole d’exclusion des robots et peut être contrôlé via les directives du fichier robots.txt. Peut être utilisé pour l’entraînement de modèles d’IA.
Amazonbot
Le robot d'exploration web d'Amazon utilisé pour améliorer les produits et services, y compris Alexa, l'assistant d'achat Rufus, et les fonctionnalités de recherche alimentées par l'IA d'Amazon. Il respecte le protocole d'exclusion des robots et peut être contrôlé via les directives du fichier robots.txt. Peut être utilisé pour l'entraînement de modèles d'IA.
Qu’est-ce qu’Amazonbot et quel est son objectif
Amazonbot est le robot d’exploration web officiel d’Amazon, conçu pour améliorer les produits et services de la société en collectant et analysant le contenu du web. Ce robot sophistiqué alimente des fonctionnalités clés d’Amazon, dont l’assistant vocal Alexa, l’assistant d’achat IA Rufus et les expériences de recherche avec IA d’Amazon. Amazonbot utilise la chaîne d’agent utilisateur Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, qui l’identifie auprès des serveurs web. Les données collectées par Amazonbot peuvent être utilisées pour entraîner les modèles d’intelligence artificielle d’Amazon, faisant de lui un élément essentiel de l’infrastructure IA et de la stratégie de développement produit d’Amazon.
Fonctionnement d’Amazonbot et robots d’exploration associés
Amazon exploite trois robots d’exploration web distincts, chacun ayant un objectif spécifique dans son écosystème. Amazonbot est le robot principal utilisé pour l’amélioration générale des produits et services, et il peut être utilisé pour l’entraînement de modèles d’IA. Amzn-SearchBot est spécifiquement conçu pour améliorer les expériences de recherche dans les produits Amazon comme Alexa et Rufus, mais il est important de noter qu’il NE parcourt PAS le contenu pour l’entraînement de modèles d’IA générative. Amzn-User prend en charge les actions initiées par l’utilisateur, telles que la récupération d’informations en direct lorsque les clients posent à Alexa des questions nécessitant des données web à jour, et il ne parcourt pas non plus pour l’entraînement d’IA. Les trois robots respectent le protocole d’exclusion des robots (Robots Exclusion Protocol) et les directives du fichier robots.txt, permettant aux propriétaires de sites web de contrôler leur accès. Amazon publie les adresses IP de chaque robot sur son portail développeur, permettant ainsi aux propriétaires de sites de vérifier le trafic légitime. De plus, tous les robots Amazon respectent les directives au niveau du lien rel=nofollow ainsi que les balises meta robots au niveau de la page, y compris noarchive (empêchant l’utilisation pour l’entraînement de modèles), noindex (empêchant l’indexation) et none (empêchant les deux).
Nom du robot
Objectif principal
Entraînement IA
User Agent
Principaux cas d’usage
Amazonbot
Amélioration générale des produits/services
Oui
Amazonbot/0.1
Amélioration globale des services Amazon, entraînement IA
Amzn-SearchBot
Amélioration de l’expérience de recherche
Non
Amzn-SearchBot/0.1
Recherche Alexa, indexation de l’assistant d’achat Rufus
Amzn-User
Récupération de données en direct initiée par l’utilisateur
Non
Amzn-User/0.1
Requêtes Alexa en temps réel, demandes d’informations actuelles
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Amazon respecte le protocole standard d’exclusion des robots (RFC 9309), ce qui signifie que les propriétaires de sites web peuvent contrôler l’accès d’Amazonbot via leur fichier robots.txt. Amazon récupère les fichiers robots.txt au niveau de l’hôte à la racine de votre domaine (par exemple, example.com/robots.txt) et utilisera une copie en cache datant des 30 derniers jours si le fichier ne peut pas être récupéré. Les changements apportés à votre fichier robots.txt prennent généralement environ 24 heures avant d’être pris en compte dans les systèmes d’Amazon. Le protocole prend en charge les directives standard user-agent et allow/disallow, permettant un contrôle granulaire sur l’accès des robots à des répertoires ou fichiers spécifiques. Toutefois, il est important de noter que les robots Amazon NE prennent PAS en charge la directive crawl-delay, ce paramètre sera donc ignoré s’il est inclus dans votre fichier robots.txt.
Voici un exemple de gestion de l’accès à Amazonbot :
# Bloquer Amazonbot pour l'ensemble de votre site
User-agent: Amazonbot
Disallow: /
# Autoriser Amzn-SearchBot pour la visibilité en recherche
User-agent: Amzn-SearchBot
Allow: /
# Bloquer un répertoire spécifique pour Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Autoriser tous les autres robots
User-agent: *
Disallow: /admin/
Identification et vérification d’Amazonbot
Les propriétaires de sites web soucieux du trafic des robots doivent vérifier que les robots se présentant comme Amazonbot sont bien des robots Amazon légitimes. Amazon propose un processus de vérification utilisant des recherches DNS afin de confirmer l’authenticité du trafic Amazonbot. Pour vérifier la légitimité d’un robot, commencez par localiser l’adresse IP d’accès dans vos journaux serveur, puis effectuez une recherche DNS inversée sur cette adresse IP à l’aide de la commande host. Le nom de domaine obtenu doit être un sous-domaine de crawl.amazonbot.amazon. Ensuite, effectuez une recherche DNS directe sur ce nom de domaine pour vérifier qu’il se résout vers l’adresse IP d’origine. Ce processus de vérification bidirectionnelle permet d’éviter les attaques par usurpation, des acteurs malveillants pouvant potentiellement paramétrer des enregistrements DNS inversés pour usurper Amazonbot. Amazon publie les adresses IP vérifiées de tous ses robots sur le portail développeur à l’adresse developer.amazon.com/amazonbot/ip-addresses/, fournissant un point de référence supplémentaire pour la vérification.
Exemple de processus de vérification :
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Si vous avez des questions sur Amazonbot ou si vous devez signaler une activité suspecte, contactez directement Amazon à amazonbot@amazon.com en incluant les noms de domaine concernés dans votre message.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Amazonbot et l’entraînement des modèles IA
Il existe une distinction essentielle entre les robots d’Amazon concernant l’entraînement de modèles d’IA. Amazonbot peut être utilisé pour entraîner les modèles d’intelligence artificielle d’Amazon, ce qui est important pour les créateurs de contenu préoccupés par l’utilisation de leur travail à des fins d’entraînement d’IA. En revanche, Amzn-SearchBot et Amzn-User ne parcourent explicitement PAS le contenu à des fins d’entraînement de modèles d’IA générative, se concentrant uniquement sur l’amélioration des expériences de recherche et le support des requêtes utilisateurs. Si vous souhaitez empêcher votre contenu d’être utilisé pour l’entraînement des modèles d’IA, vous pouvez utiliser la balise meta robots noarchive dans l’en-tête HTML de votre page, ce qui indique à Amazonbot de ne pas utiliser la page à des fins d’entraînement. Cette distinction est importante pour les éditeurs, créateurs et propriétaires de sites web souhaitant garder le contrôle sur l’utilisation de leur contenu dans le pipeline d’entraînement IA, tout en permettant que leur contenu apparaisse dans les résultats de recherche Amazon et les recommandations Rufus.
Assistant d’achat Rufus et Amazonbot
Rufus est l’assistant d’achat IA avancé d’Amazon qui s’appuie sur l’exploration web et la technologie IA pour proposer des recommandations et une assistance personnalisées dans les achats. Bien qu’Amazonbot contribue à l’infrastructure IA globale d’Amazon, Rufus utilise spécifiquement Amzn-SearchBot pour indexer les informations sur les produits et le contenu web pertinent pour les requêtes d’achat. Rufus est construit sur Amazon Bedrock et exploite des modèles de langage de grande taille avancés, dont Claude Sonnet d’Anthropic et Amazon Nova, combinés à un modèle personnalisé entraîné sur le vaste catalogue de produits d’Amazon, les avis clients, les questions/réponses communautaires et les informations web. L’assistant d’achat aide les clients à rechercher des produits, comparer des options, suivre des prix, trouver des offres et même acheter automatiquement des articles lorsqu’ils atteignent des prix cibles. Depuis son lancement, Rufus est devenu extrêmement populaire, avec plus de 250 millions de clients l’utilisant, des utilisateurs actifs mensuels en hausse de 149 %, et des interactions en augmentation de 210 % sur un an. Les clients qui utilisent Rufus pendant leurs achats sont plus de 60 % plus susceptibles d’effectuer un achat lors de cette session, démontrant l’impact significatif de l’assistance aux achats alimentée par l’IA sur le comportement des consommateurs.
Bonnes pratiques pour les propriétaires de sites web
Les propriétaires de sites web doivent adopter une approche stratégique dans la gestion des robots d’Amazon en fonction de leurs objectifs professionnels et de leur politique de contenu :
Autorisez Amzn-SearchBot à accéder à votre contenu si vous souhaitez que vos produits et informations apparaissent dans les résultats de recherche Amazon, les réponses Alexa et les recommandations d’achat Rufus — ce robot n’entraîne pas les modèles IA et offre une visibilité précieuse
Réfléchissez à votre position concernant Amazonbot selon que vous acceptez ou non que votre contenu soit potentiellement utilisé pour l’entraînement de modèles d’IA ; dans le cas contraire, utilisez la balise meta robots noarchive ou bloquez-le complètement via robots.txt
Surveillez régulièrement vos journaux serveur pour comprendre les schémas de trafic des robots et identifier toute activité inhabituelle pouvant indiquer des robots malveillants usurpant des robots légitimes
Mettez en place des limitations de débit si le trafic des robots impacte les performances de votre serveur, mais évitez un blocage trop agressif, qui pourrait nuire à votre visibilité dans les fonctionnalités de recherche et d’achat Amazon
Vérifiez toujours la légitimité des robots à l’aide de recherches DNS avant d’agir contre un trafic suspect
Contactez l’équipe support d’Amazon à amazonbot@amazon.com en précisant votre domaine pour obtenir des conseils personnalisés si vous avez des préoccupations ou des questions spécifiques quant à l’interaction des robots Amazon avec votre site
Questions fréquemment posées
Quelle est la différence entre Amazonbot et Amzn-SearchBot ?
Amazonbot est le robot d'exploration généraliste d'Amazon utilisé pour améliorer les produits et services, et il peut être utilisé pour l'entraînement de modèles d'IA. Amzn-SearchBot est spécifiquement conçu pour les expériences de recherche sur Alexa et Rufus, et il NE fait PAS d'exploration pour l'entraînement de modèles d'IA. Si vous souhaitez empêcher l'utilisation à des fins d'entraînement d'IA, bloquez Amazonbot mais autorisez Amzn-SearchBot pour la visibilité dans la recherche.
Comment puis-je empêcher Amazonbot d'explorer mon site web ?
Ajoutez les lignes suivantes à votre fichier robots.txt à la racine de votre domaine : User-agent: Amazonbot suivi de Disallow: /. Cela empêchera Amazonbot d'explorer l'ensemble de votre site. Vous pouvez également utiliser Disallow: /chemin-spécifique/ pour bloquer uniquement certains répertoires.
Amazonbot utilise-t-il mon contenu pour entraîner des modèles d'IA ?
Oui, Amazonbot peut être utilisé pour entraîner les modèles d'intelligence artificielle d'Amazon. Si vous souhaitez l'empêcher, utilisez la balise meta robots dans l'en-tête HTML de votre page, ce qui indique à Amazonbot de ne pas utiliser la page pour l'entraînement de modèles.
Comment vérifier qu'un robot d'exploration est réellement Amazonbot ?
Effectuez une recherche DNS inversée sur l'adresse IP du robot et vérifiez que le domaine est un sous-domaine de crawl.amazonbot.amazon. Ensuite, effectuez une recherche DNS directe pour confirmer que le domaine se résout vers l'adresse IP d'origine. Vous pouvez également vérifier les adresses IP publiées par Amazon sur developer.amazon.com/amazonbot/ip-addresses/.
Quelle est la syntaxe robots.txt pour contrôler Amazonbot ?
Utilisez la syntaxe standard du fichier robots.txt : User-agent: Amazonbot pour cibler le robot, suivi de Disallow: / pour bloquer tout accès ou Disallow: /chemin/ pour bloquer des répertoires spécifiques. Vous pouvez également utiliser Allow: / pour autoriser explicitement l'accès.
Combien de temps faut-il pour que les modifications du fichier robots.txt prennent effet ?
Amazon prend généralement en compte les modifications du fichier robots.txt en environ 24 heures. Amazon récupère régulièrement votre fichier robots.txt et conserve une copie en cache jusqu'à 30 jours, donc les modifications peuvent mettre une journée entière à se propager dans leurs systèmes.
Puis-je autoriser Amzn-SearchBot mais bloquer Amazonbot ?
Oui, tout à fait. Vous pouvez créer des règles séparées pour chaque robot dans votre fichier robots.txt. Par exemple, autorisez Amzn-SearchBot avec User-agent: Amzn-SearchBot et Allow: /, tout en bloquant Amazonbot avec User-agent: Amazonbot et Disallow: /.
Que dois-je faire si j'ai des questions sur Amazonbot ?
Contactez directement Amazon à l'adresse amazonbot@amazon.com. Indiquez toujours votre nom de domaine et toute information pertinente liée à votre demande dans votre message. L'équipe support d'Amazon pourra vous fournir des conseils personnalisés pour votre situation spécifique.
Surveillez comment l'IA référence votre marque
Suivez les mentions de votre marque sur les systèmes d'IA comme Alexa, Rufus et Google AI Overviews grâce à AmICited - la plateforme leader de surveillance des réponses IA.
PerplexityBot : Ce que chaque propriétaire de site web doit savoir
Guide complet sur le robot d'indexation PerplexityBot – comprenez son fonctionnement, gérez l'accès, surveillez les citations et optimisez la visibilité sur Per...
Découvrez PerplexityBot, le robot d’indexation web de Perplexity qui indexe le contenu pour son moteur de réponses IA. Comprenez son fonctionnement, sa conformi...
Découvrez ce qu'est CCBot, son fonctionnement et comment le bloquer. Comprenez son rôle dans l'entraînement de l'IA, les outils de surveillance et les bonnes pr...
8 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.