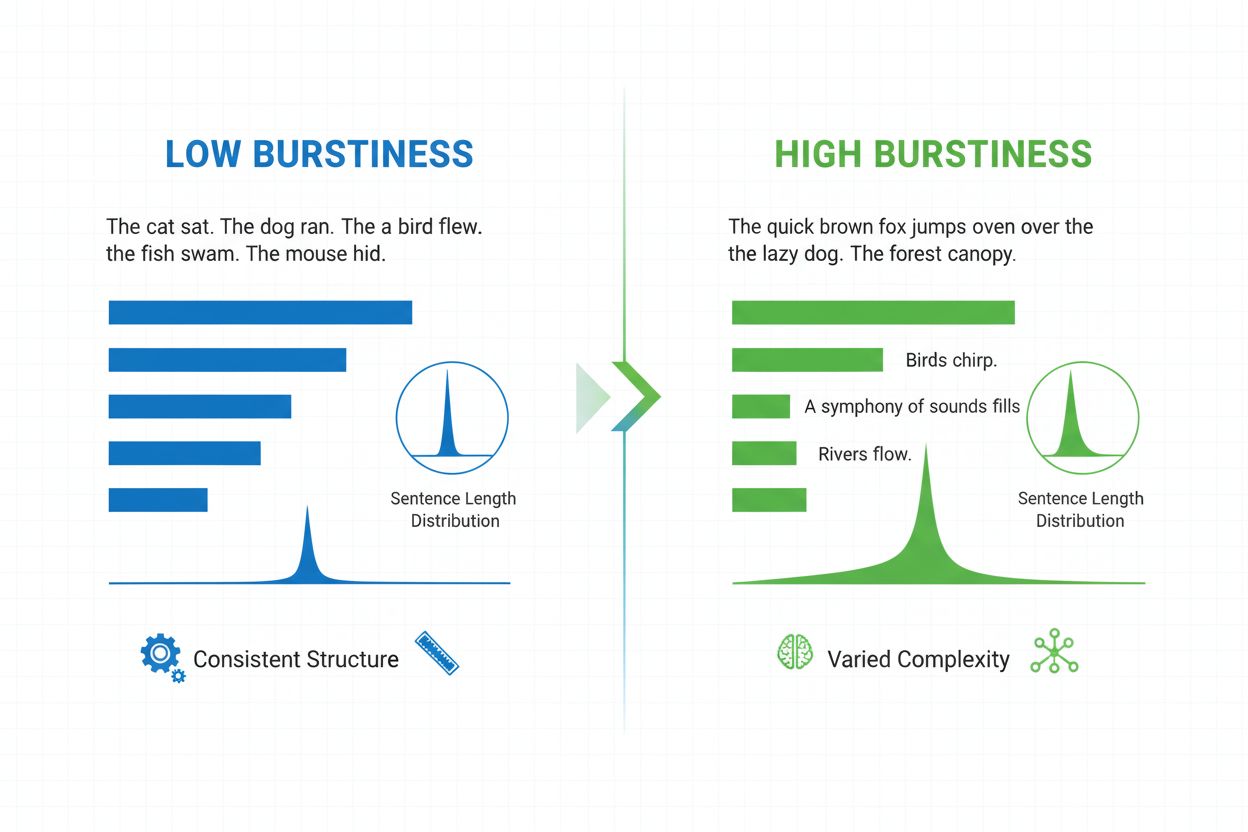
Définition de la Burstiness
La burstiness est une métrique linguistique quantifiable qui mesure la variabilité et la fluctuation de la longueur, de la structure et de la complexité des phrases dans un document écrit ou un extrait de texte. Le terme provient du concept de « sursauts » de schémas de phrases variés – alternant entre des phrases courtes et concises et des phrases plus longues et complexes. Dans le contexte du traitement automatique du langage naturel et de la détection de contenu IA, la burstiness sert d’indicateur clé pour déterminer si un texte a été rédigé par un humain ou généré par une intelligence artificielle. Les auteurs humains produisent naturellement un texte à forte burstiness car ils varient instinctivement leur construction de phrase selon l’emphase, le rythme et l’intention stylistique. À l’inverse, le texte généré par l’IA présente généralement une faible burstiness car les modèles de langage sont entraînés sur des schémas statistiques privilégiant la cohérence et la prévisibilité. Comprendre la burstiness est essentiel pour les créateurs de contenu, les enseignants, les chercheurs et les organisations qui surveillent le contenu généré par l’IA sur des plateformes telles que ChatGPT, Perplexity, Google AI Overviews et Claude.
Contexte historique et évolution
Le concept de burstiness est issu de la recherche en linguistique computationnelle et en théorie de l’information, où les scientifiques cherchaient à quantifier les propriétés statistiques du langage naturel. Les premiers travaux en stylométrie – l’analyse statistique du style d’écriture – ont mis en évidence que l’écriture humaine présente des schémas de variation distinctifs, fondamentalement différents de ceux des textes générés par machine. Au fur et à mesure que les grands modèles de langage (LLM) sont devenus plus sophistiqués dans les années 2020, les chercheurs ont reconnu que la burstiness, combinée à la perplexité (une mesure de la prévisibilité des mots), pouvait servir d’indicateur fiable du contenu généré par l’IA. D’après les recherches de QuillBot et d’institutions académiques, environ 78 % des entreprises utilisent désormais des outils de surveillance de contenu pilotés par l’IA intégrant l’analyse de burstiness dans leurs algorithmes de détection. L’étude de l’Université Stanford en 2023 sur les essais TOEFL a montré que les méthodes de détection basées sur la burstiness, bien qu’utiles, présentent d’importantes limites – notamment en matière de faux positifs dans l’écriture d’anglophones non natifs. Ces travaux ont conduit au développement de systèmes de détection IA plus sophistiqués et multi-couches, prenant en compte la burstiness ainsi que d’autres marqueurs linguistiques, la cohérence sémantique et la pertinence contextuelle.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Explication technique de la mesure de la burstiness
La burstiness se calcule en analysant la distribution statistique des longueurs de phrases et des schémas structurels dans un texte. La métrique quantifie la variance – mesurant à quel point chaque phrase s’écarte de la longueur moyenne de phrase dans un document. Un document à forte burstiness contient des phrases de longueur très variée : par exemple, un auteur peut écrire une phrase de trois mots (« Vous voyez ? ») suivie d’une phrase de vingt-cinq mots comportant plusieurs propositions et subordonnées. À l’inverse, une faible burstiness indique que la plupart des phrases tournent autour d’une même longueur, généralement entre douze et dix-huit mots, créant un rythme monotone. Le calcul s’effectue en plusieurs étapes : d’abord, le système mesure la longueur de chaque phrase en mots ; ensuite, il calcule la moyenne ; enfin, il détermine l’écart-type pour mesurer l’écart individuel des phrases par rapport à la moyenne. Un écart-type élevé indique une plus grande variation et donc une burstiness plus forte. Les détecteurs IA modernes comme Winston AI et Pangram utilisent des algorithmes sophistiqués qui ne se limitent pas au comptage de mots, mais analysent aussi la complexité syntaxique – l’arrangement structurel des propositions, groupes et éléments grammaticaux. Cette analyse approfondie révèle que l’écriture humaine recourt à une diversité de structures de phrases (simples, composées, complexes et composées-complexes) selon des schémas imprévisibles, tandis que les modèles IA privilégient des modèles structurels particuliers fréquemment rencontrés lors de l’entraînement.
Burstiness vs. Perplexité : analyse comparative
| Métrique | Burstiness | Perplexité | Axe de mesure |
|---|
| Définition | Variation de la longueur et de la structure des phrases | Prévisibilité des mots individuels | Phrase vs. mot |
| Écriture humaine | Élevée (structures variées) | Élevée (mots imprévisibles) | Rythme naturel et vocabulaire |
| Texte IA | Faible (structures uniformes) | Faible (mots prévisibles) | Cohérence statistique |
| Usage en détection | Détecte la monotonie structurelle | Détecte les schémas de choix de mots | Méthodes complémentaires |
| Risque de faux positifs | Plus élevé pour les auteurs ESL | Plus élevé pour l’écriture technique/ académique | Limites des deux côtés |
| Méthode de calcul | Écart-type des longueurs de phrases | Analyse de la distribution de probabilité | Approches mathématiques différentes |
| Fiabilité seule | Insuffisante pour une détection définitive | Insuffisante pour une détection définitive | Plus efficace combinée à d’autres |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Les grands modèles de langage comme ChatGPT, Claude et Google Gemini sont entraînés grâce à la prédiction du prochain jeton, où le modèle apprend à prédire le mot le plus probable à suivre dans une séquence donnée. Durant l’entraînement, ces modèles sont explicitement optimisés pour minimiser la perplexité sur leurs jeux de données, ce qui engendre involontairement une faible burstiness. Lorsqu’un modèle rencontre une structure de phrase fréquemment lors de l’entraînement, il la reproduit avec une forte probabilité, produisant ainsi des phrases de longueur constante et prévisible. Des études de Netus AI et Winston AI montrent que les modèles IA possèdent une empreinte stylométrique distincte, caractérisée par une construction de phrases uniforme, une surutilisation de connecteurs (« De plus », « Par conséquent », « En outre ») et une préférence pour la voix passive sur la voix active. La dépendance de ces modèles aux distributions de probabilité les pousse vers les schémas les plus communs dans leurs données d’entraînement, plutôt que d’explorer toute la gamme des constructions possibles. Cela crée un paradoxe : plus un modèle est entraîné sur de grandes quantités de données, plus il reproduit des schémas communs et plus sa burstiness diminue. De plus, les modèles IA manquent de spontanéité et de variations émotionnelles : ils n’écrivent pas différemment selon l’émotion ou l’intention, mais conservent une ligne stylistique constante qui reflète le centre statistique de leurs données d’entraînement.
Burstiness dans les systèmes de détection IA
Les plateformes de détection IA ont intégré l’analyse de burstiness comme composant central de leurs algorithmes, avec des degrés de sophistication variables. Les premiers systèmes misaient beaucoup sur la burstiness et la perplexité comme métriques principales, mais la recherche a révélé d’importantes limites à cette approche. Selon Pangram Labs, les détecteurs basés sur la perplexité et la burstiness produisent des faux positifs lorsqu’ils analysent des textes issus des jeux de données d’entraînement des modèles de langage – notamment, la Déclaration d’Indépendance est souvent signalée à tort comme générée par l’IA, car elle figure si fréquemment dans les données d’entraînement que le modèle lui attribue une perplexité uniformément basse. Les systèmes modernes comme Winston AI et Pangram utilisent désormais des approches hybrides combinant l’analyse de burstiness à des modèles d’apprentissage profond entraînés sur des échantillons humains et IA diversifiés. Ces systèmes analysent plusieurs dimensions linguistiques simultanément : variation de la structure des phrases, diversité lexicale (richesse du vocabulaire), schémas de ponctuation, cohérence contextuelle et alignement sémantique. L’intégration de la burstiness à des cadres de détection plus larges a nettement amélioré la précision – Winston AI annonce 99,98 % de précision pour distinguer contenus humains et IA en analysant de multiples marqueurs, plutôt qu’en se basant uniquement sur la burstiness. Néanmoins, la métrique reste précieuse comme élément d’une stratégie de détection globale, en particulier associée à l’analyse de la perplexité, des schémas stylométriques et de la cohérence sémantique.
Applications pratiques et bonnes pratiques
- Création de contenu : les auteurs peuvent varier intentionnellement la longueur et la structure des phrases pour produire un contenu plus engageant, humain et éviter les drapeaux de détection IA.
- Écriture académique : étudiants et chercheurs devraient recourir à des constructions de phrases variées pour démontrer la sophistication de leur écriture et éviter les faux positifs issus des systèmes de détection IA utilisés dans l’enseignement.
- SEO et marketing de contenu : les éditeurs peuvent améliorer la qualité du contenu et le référencement en augmentant la burstiness, ce qui corrèle avec une meilleure lisibilité et un engagement utilisateur supérieur.
- Surveillance de marque : les organisations utilisant des plateformes comme AmICited peuvent analyser les schémas de burstiness dans les réponses générées par l’IA pour déterminer si les citations de marque proviennent bien de contenus humains ou de textes IA.
- Détection et vérification IA : enseignants, éditeurs et modérateurs de contenu peuvent utiliser l’analyse de burstiness comme un des multiples signaux pour identifier les soumissions possiblement générées par l’IA et garantir l’authenticité du contenu.
- Amélioration de l’écriture : les auteurs peuvent utiliser les métriques de burstiness comme retour pour affiner leur style, maintenant l’engagement du lecteur par un rythme naturel et des constructions variées.
- Apprentissage des langues : les enseignants ESL peuvent montrer aux apprenants que le développement de structures variées est une compétence avancée qui contribue à une écriture anglaise plus naturelle et authentique.
Burstiness et métriques de lisibilité
La relation entre burstiness et lisibilité est bien documentée dans la recherche linguistique. Les scores Flesch Reading Ease et Flesch-Kincaid Grade Level, qui mesurent l’accessibilité du texte, sont fortement corrélés aux schémas de burstiness. Un texte à burstiness élevée obtient généralement de meilleurs scores de lisibilité, car la variation de longueur des phrases prévient la fatigue cognitive et maintient l’attention du lecteur. Si le lecteur rencontre un rythme constant de phrases similaires, le cerveau s’adapte à ce schéma, ce qui peut entraîner un désengagement et une compréhension réduite. À l’inverse, une burstiness élevée crée un effet de flux qui maintient l’implication du lecteur en variant la charge cognitive : les phrases courtes fournissent une information rapide, tandis que les plus longues permettent le développement nuancé d’idées. Selon Metrics Masters, une burstiness élevée génère environ 15 à 20 % de meilleure rétention mémorielle qu’un texte à faible burstiness, le rythme varié facilitant l’encodage en mémoire à long terme. Ce principe s’applique à tous types de contenus : billets de blog, articles académiques, textes marketing et documentation technique bénéficient tous d’une burstiness stratégique. Toutefois, la relation n’est pas linéaire : une burstiness excessive qui privilégie la variation au détriment de la clarté rend le texte haché et difficile à suivre. L’approche optimale repose sur une variation intentionnelle où le choix de la structure sert le sens et l’intention plutôt que d’augmenter artificiellement la métrique.
Limites et critiques de la détection basée sur la burstiness
Malgré son adoption généralisée dans les systèmes de détection IA, la détection fondée sur la burstiness présente d’importantes limites que chercheurs et praticiens doivent connaître. Pangram Labs a publié une recherche complète identifiant cinq faiblesses majeures : premièrement, les textes issus des jeux de données d’entraînement IA sont faussement classés comme générés par l’IA, car les modèles sont optimisés pour minimiser la perplexité sur ces données ; deuxièmement, les valeurs de burstiness sont relatives au modèle, donc chaque modèle présente des profils de perplexité différents ; troisièmement, les modèles commerciaux fermés comme ChatGPT ne divulguent pas les probabilités de jetons, ce qui rend le calcul de perplexité impossible ; quatrièmement, les anglophones non natifs sont disproportionnellement signalés comme IA à cause de leurs structures de phrases plus uniformes ; et cinquièmement, les détecteurs basés sur la burstiness ne peuvent pas s’améliorer itérativement avec de nouvelles données. L’étude Stanford 2023 sur les essais TOEFL a révélé qu’environ 26 % des écrits d’anglophones non natifs étaient faussement signalés comme IA par les détecteurs basés sur perplexité et burstiness, contre seulement 2 % de faux positifs sur des textes natifs. Ce biais soulève d’importantes questions éthiques dans l’éducation. Par ailleurs, les contenus à forte structure, comme le marketing, l’académique ou la documentation technique, présentent naturellement une burstiness plus faible en raison des conventions, entraînant des faux positifs. Ces limites ont poussé au développement d’approches plus sophistiquées où la burstiness devient un signal parmi d’autres, et non un indicateur définitif de génération IA.
Burstiness selon les contextes d’écriture
Les schémas de burstiness varient beaucoup selon les genres et contextes d’écriture, reflétant les buts et attentes propres à chaque domaine. L’écriture académique, notamment en STEM, affiche une burstiness plus faible car les auteurs suivent des guides stricts pour la clarté et la précision. Les documents juridiques, les spécifications techniques et les articles scientifiques privilégient la cohérence et la prévisibilité, d’où des scores de burstiness naturellement bas. À l’inverse, l’écriture créative, le journalisme et les textes marketing montrent généralement une burstiness élevée, car ces genres visent l’engagement du lecteur et l’impact émotionnel via le rythme et la variation. La fiction littéraire, en particulier, alterne fortement la longueur des phrases pour créer de l’emphase, du suspense et contrôler le rythme narratif. La communication d’entreprise se situe entre les deux : e-mails et rapports professionnels maintiennent une burstiness modérée pour équilibrer clarté et dynamisme. Le score Flesch-Kincaid Grade Level révèle que l’écriture académique destinée à un public diplômé comporte souvent des phrases longues et complexes, ce qui pourrait sembler baisser la burstiness ; cependant, la variation des structures et subordonnées y contribue toujours. Comprendre ces variations contextuelles est crucial pour les systèmes de détection IA, qui doivent tenir compte des conventions de chaque genre pour éviter les faux positifs. Un manuel technique aux phrases uniformément longues ne doit pas être signalé comme IA simplement à cause d’une faible burstiness – celle-ci reflète ici des choix stylistiques adaptés plutôt qu’une preuve de génération automatique.
Évolution future et implications stratégiques
L’avenir de l’analyse de la burstiness en détection IA s’oriente vers des approches plus sophistiquées et contextuelles, reconnaissant les limites de la métrique tout en tirant parti de ses apports. À mesure que les grands modèles de langage progressent, ils commencent à intégrer davantage de variation dans la burstiness de leurs productions, rendant la détection fondée uniquement sur ce critère moins fiable. Les chercheurs développent des systèmes de détection adaptatifs qui analysent la burstiness en synergie avec la cohérence sémantique, la véracité et la pertinence contextuelle. L’émergence d’outils d’humanisation IA qui augmentent volontairement la burstiness et d’autres caractéristiques humaines illustre la course entre technologies de détection et d’évasion. Toutefois, les experts prédisent que la détection IA vraiment fiable dépendra in fine de méthodes de vérification cryptographique et de traçabilité de la provenance, plus que de l’analyse linguistique seule. Pour les créateurs et organisations, l’implication stratégique est claire : plutôt que de chercher à jouer avec la burstiness, il faut développer un style authentique, varié, qui reflète naturellement les schémas de communication humaine. La plateforme de monitoring d’AmICited ouvre une nouvelle voie, analysant la présence des marques dans les réponses IA et leurs caractéristiques linguistiques. À mesure que l’IA se généralise dans la génération et la diffusion de contenus, comprendre la burstiness et les métriques associées devient crucial pour préserver l’authenticité des marques, garantir l’intégrité académique et maintenir la distinction entre écriture humaine et machine. L’évolution vers des méthodes de détection multi-signaux garantit que la burstiness restera pertinente dans les systèmes de surveillance IA, même si son rôle devient plus nuancé et contextuel.