
Sélection des sources par l'IA
Découvrez comment les systèmes d'IA sélectionnent et classent les sources à citer. Découvrez les algorithmes, signaux et facteurs qui déterminent quels sites we...
19 min de lecture

La composition du pool de sources fait référence au mélange spécifique de sites web, de types de contenus et de sources d’information qu’un système d’IA prend en compte lorsqu’il génère des réponses à une requête utilisateur. Cette composition détermine directement quels sites bénéficient de visibilité dans les réponses générées par l’IA et constitue le prérequis pour toute citation ou visibilité dans les systèmes d’IA. La composition varie selon la requête, le sujet et la plateforme d’IA, ce qui signifie qu’un site peut être inclus dans le pool de sources pour une requête et exclu pour une autre selon la pertinence, l’autorité et les signaux de qualité de contenu. Comprendre la composition du pool de sources est essentiel pour les créateurs de contenu et les marketeurs cherchant à gagner en visibilité dans la recherche alimentée par l’IA.
La composition du pool de sources fait référence au mélange spécifique de sites web, de types de contenus et de sources d’information qu’un système d’IA prend en compte lorsqu’il génère des réponses à une requête utilisateur. Cette composition détermine directement quels sites bénéficient de visibilité dans les réponses générées par l’IA et constitue le prérequis pour toute citation ou visibilité dans les systèmes d’IA. La composition varie selon la requête, le sujet et la plateforme d’IA, ce qui signifie qu’un site peut être inclus dans le pool de sources pour une requête et exclu pour une autre selon la pertinence, l’autorité et les signaux de qualité de contenu. Comprendre la composition du pool de sources est essentiel pour les créateurs de contenu et les marketeurs cherchant à gagner en visibilité dans la recherche alimentée par l’IA.
La composition du pool de sources fait référence au mélange spécifique de sites web, de types de contenus et de sources d’information qu’un système d’IA prend en compte pour générer des réponses à une requête utilisateur. Cette composition détermine directement quels sites bénéficient de visibilité dans les réponses générées par l’IA, ce qui la distingue fondamentalement du classement traditionnel par moteur de recherche. Comprendre la composition du pool de sources est essentiel pour les créateurs de contenu et les marketeurs, car l’inclusion dans le pool de sources d’un système d’IA est le prérequis pour toute citation ou visibilité : un site ne peut pas être cité s’il n’a jamais été pris en compte initialement. La composition varie selon la requête, le sujet et le système d’IA : un site peut être inclus dans le pool de sources pour une requête mais exclu pour une autre selon la pertinence, l’autorité et les signaux de qualité du contenu.

Les systèmes d’IA construisent des pools de sources via un processus en plusieurs étapes qui combine différents mécanismes sophistiqués d’identification et d’évaluation des sources potentielles. La méthode principale est la génération augmentée par la récupération (RAG), qui extrait des documents pertinents parmi les contenus indexés avant de générer une réponse, garantissant ainsi que les réponses reposent sur des sources réelles plutôt que seulement sur les données d’entraînement. Ce processus fonctionne en synergie avec deux autres mécanismes essentiels :
| Aspect | Moteurs de recherche traditionnels | Sélection de sources par l’IA |
|---|---|---|
| Signal principal | Backlinks et pertinence des mots-clés | Autorité, pertinence, extractibilité et diversité |
| Évaluation des sources | Classement au niveau de la page | Scoring de pertinence au niveau du document |
| Considération de la diversité | Diversité algorithmique limitée | Déduplication active et clustering thématique |
| Format de contenu | Tous formats pondérés également | Données structurées et clarté fortement valorisées |
| Mises à jour en temps réel | Crawl continu | Mises à jour périodiques de l’index avec signaux d’actualité |
De multiples facteurs se combinent pour déterminer si une source intègre le pool de sources d’un système d’IA pour une requête donnée, chaque facteur ayant un poids différent selon le type et le contexte de la requête. L’autorité reste le plus fort prédicteur d’inclusion, des études montrant que 76 % des citations dans AI Overview proviennent des 10 premiers résultats organiques, ce qui indique que l’autorité du domaine accroît significativement l’inclusion dans le pool de sources. L’actualité est cruciale pour les requêtes sensibles au temps—les systèmes d’IA filtrent activement les contenus récemment mis à jour pour les questions sur l’actualité, les lancements de produits ou les situations évolutives. La pertinence s’opère à plusieurs niveaux : pertinence thématique (le contenu traite-t-il du sujet ?), pertinence de la requête (répond-il à la question spécifique ?), pertinence des entités (traite-t-il des personnes, organisations ou concepts cités ?). La diversité garantit que les pools de sources incluent des perspectives et types de contenus variés au lieu de se concentrer sur une seule source dominante. L’alignement thématique mesure si la ligne éditoriale générale d’une source correspond au domaine de la requête, les systèmes d’IA privilégiant les sources démontrant une expertise durable sur les sujets concernés.
| Facteur de sélection | Impact sur l’inclusion | Pourquoi c’est important |
|---|---|---|
| Autorité du domaine | Très élevée (40-50 % du poids) | Signe de fiabilité et d’expertise ; corrèle avec la qualité du contenu |
| Actualité du contenu | Élevée (20-30 % du poids) | Garantit des réponses à jour ; essentiel pour les requêtes sensibles au temps |
| Pertinence thématique | Élevée (20-30 % du poids) | Garantit l’expertise de la source sur le domaine de la requête |
| Clarté du contenu | Moyenne à élevée (15-25 % du poids) | Améliore l’extractibilité et réduit les erreurs dans les réponses IA |
| Signaux de diversité | Moyen (10-20 % du poids) | Évite la dépendance à une seule source ; améliore l’exhaustivité des réponses |
La diversité des sources dans les réponses générées par l’IA joue un rôle clé : éviter la redondance tout en garantissant une couverture exhaustive des sujets. Les systèmes d’IA utilisent des algorithmes de clustering thématique qui regroupent les sources similaires et sélectionnent des sources représentatives pour chaque cluster, évitant ainsi que des sources quasi identiques dominent la réponse. Les mécanismes de déduplication identifient les sources au contenu substantiellement similaire et n’incluent que la version la plus autoritaire, empêchant la même information d’être citée plusieurs fois sous différentes URLs. Les techniques de diversité incluent :
Cette approche prévient le problème de « concentration des citations » où l’IA aurait tendance à citer sans cesse les mêmes sources à forte autorité, en favorisant des réponses plus équilibrées et complètes.
L’autorité du domaine et les signaux de confiance constituent la base de l’inclusion dans le pool de sources, les systèmes d’IA utilisant plusieurs indicateurs pour évaluer si une source mérite d’être prise en compte. Les profils de backlinks restent importants, mais l’IA valorise la qualité plus que la quantité—les liens provenant de sources faisant autorité et pertinentes thématiquement ont bien plus de poids que de nombreux liens de faible qualité. Les mentions de marque sont devenues aussi importantes que les backlinks : des études indiquent que les systèmes d’IA suivent la présence des marques et organisations sur le web comme signaux de confiance, ce qui signifie qu’être cité positivement dans des publications de référence accroît fortement l’inclusion dans le pool de sources. La cohérence des entités mesure si l’information relative à une entité (personne, organisation, produit) reste cohérente à travers les sources, l’IA utilisant cette cohérence comme indice de fiabilité. Les autres signaux de confiance incluent :
Des études montrent que les sources avec de forts signaux de confiance bénéficient d’un taux de citation 3 à 4 fois supérieur dans les réponses IA, même à qualité de contenu équivalente.
La qualité du contenu et son extractibilité—la facilité avec laquelle les systèmes d’IA peuvent analyser et comprendre le contenu—influencent fortement la composition du pool, du contenu mal structuré étant souvent exclu même doté d’une forte autorité. Le balisage de données structurées utilisant le vocabulaire Schema.org aide l’IA à comprendre le contexte, les relations et les informations clés du contenu, ce qui accroît considérablement la probabilité d’inclusion et de citation précise. La clarté du contenu est cruciale, car l’IA doit pouvoir identifier facilement les affirmations, faits et arguments spécifiques : un contenu dense ou mal organisé est plus difficile à extraire et donc moins susceptible d’être inclus. La présence de titres clairs, de paragraphes logiques et de phrases introductives explicites améliore l’extractibilité. Exemple simple de données structurées bénéfiques :
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Comprendre la composition du pool de sources IA",
"author": {"@type": "Person", "name": "Auteur Expert"},
"datePublished": "2024-01-15",
"articleBody": "La composition du pool de sources fait référence à..."
}
Un contenu utilisant correctement Schema.org affiche un taux d’inclusion 2 à 3 fois supérieur dans les pools de sources IA par rapport à un contenu identique sans balisage, rendant la mise en œuvre technique SEO essentielle pour la visibilité dans l’IA.
L’impact réel de la composition du pool de sources sur la visibilité dépasse largement les métriques de recherche traditionnelles, redéfinissant la façon dont les audiences découvrent et interagissent avec le contenu. Les taux de citation dans les réponses générées par l’IA sont directement corrélés au trafic et à la visibilité de la marque : les sources citées bénéficient de hausses mesurables de trafic et de notoriété, des études montrant que les sources citées dans les AI Overviews enregistrent une augmentation de 15 à 25 % du volume de recherche sur la marque. Le comportement de recherche sans clic s’oriente vers les réponses IA, ce qui signifie que l’inclusion dans le pool de sources détermine désormais la visibilité là où les utilisateurs ne consultent même plus les résultats classiques. La visibilité de marque et la construction de l’autorité s’effectuent grâce aux citations IA même sans clic, car les mentions répétées dans les réponses établissent la reconnaissance et l’autorité de la marque. Par exemple, une société de services financiers citée dans des réponses IA sur la retraite bénéficie d’une exposition quotidienne à des milliers d’utilisateurs, même si seule une minorité clique sur son site. La composition des pools de sources influence également le positionnement concurrentiel, les sites inclus dans les pools pour des requêtes à fort volume obtenant un avantage de visibilité significatif sur les concurrents exclus.
Être inclus et rester présent dans les pools de sources IA exige une stratégie combinant qualité de contenu, implémentation technique et développement d’autorité. Les organisations devraient appliquer les stratégies suivantes :
Des outils comme AmICited.com permettent aux organisations de suivre les sources incluses dans les pools IA sur leurs requêtes cibles, offrant une visibilité sur le positionnement concurrentiel et les schémas d’inclusion.
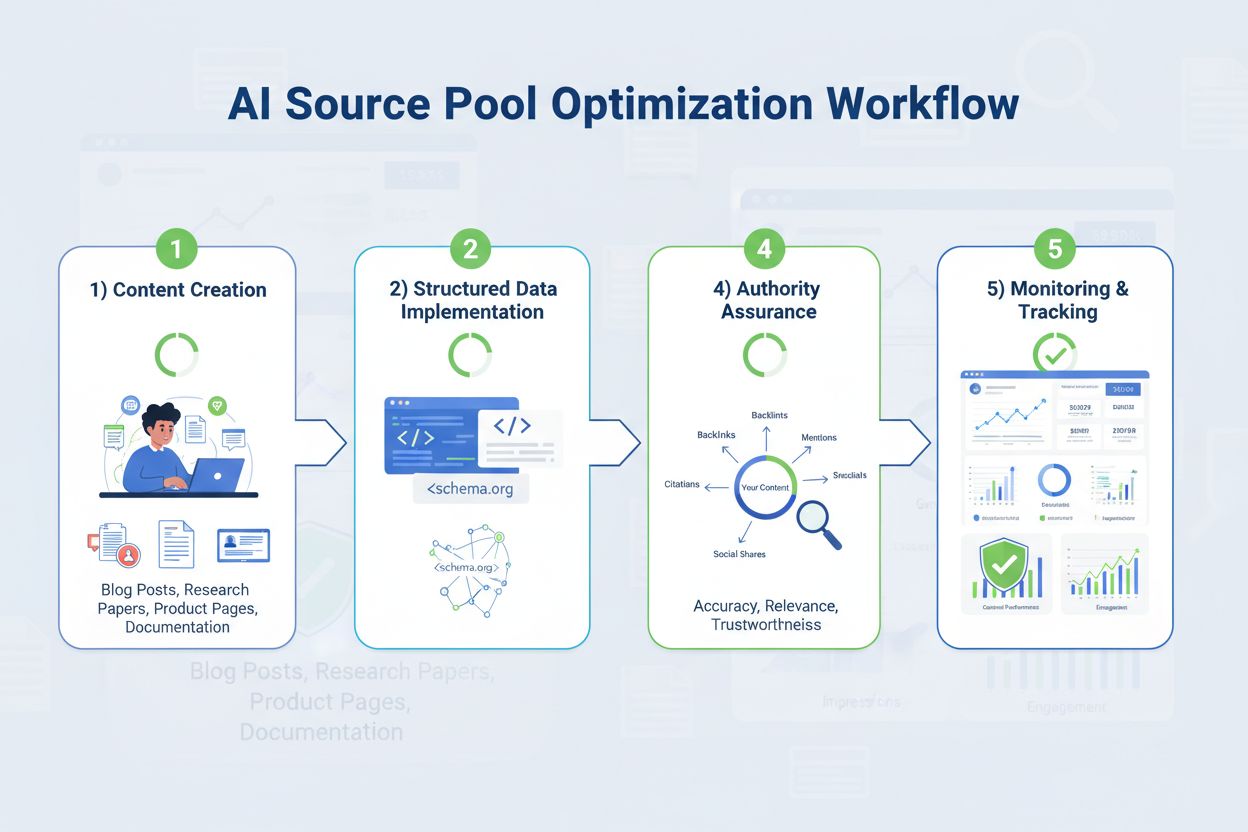
Mesurer l’inclusion dans les pools de sources et suivre l’évolution dans le temps nécessite une surveillance systématique de plusieurs indicateurs. Les organisations devraient suivre :
AmICited.com offre des outils dédiés pour suivre la composition des pools de sources, les schémas de citation et le positionnement concurrentiel sur plusieurs systèmes d’IA, permettant une optimisation data-driven de la stratégie de contenu pour la visibilité IA. En définissant des indicateurs de référence sur l’inclusion actuelle et en suivant les évolutions trimestrielles, les organisations peuvent mesurer l’impact de leurs efforts d’optimisation et ajuster leur stratégie selon les résultats. Cette approche transforme la composition du pool de sources d’un concept abstrait en un levier concret et mesurable de la stratégie globale de visibilité digitale.
Les moteurs de recherche traditionnels classent les pages individuelles selon des signaux d’autorité et de pertinence, les affichant dans une liste linéaire. Les systèmes d’IA, en revanche, commencent par constituer un pool de sources potentiellement pertinentes, puis sélectionnent des sources spécifiques de ce pool à citer dans les réponses générées. Un site peut être bien classé dans la recherche traditionnelle mais être exclu du pool de sources d’un système d’IA s’il manque d’autorité, de clarté ou d’alignement thématique. La composition du pool de sources est donc l’étape préalable qui détermine si un site peut même être envisagé pour une citation.
La composition du pool de sources détermine directement votre visibilité dans les réponses générées par l’IA. Si votre site n’est pas inclus dans le pool de sources pour une requête, il ne pourra pas être cité, quelle que soit la qualité du contenu. L’inclusion dans les pools de sources augmente vos chances d’être cité, ce qui favorise la visibilité de la marque, la notoriété et le trafic. Des études montrent que les sources citées dans les AI Overviews constatent une augmentation de 15 à 25 % du volume des recherches de marque, faisant de l’inclusion dans le pool de sources un élément crucial de la stratégie de visibilité dans l’IA.
Oui, les petits sites peuvent apparaître dans les pools de sources IA s’ils présentent une grande qualité de contenu, une structure claire, un balisage schema approprié et une expertise thématique. Les systèmes d’IA évaluent le contenu au niveau du document et non seulement au niveau du domaine, ce qui signifie qu’un seul article de haute qualité issu d’un petit site peut être inclus dans les pools de sources aux côtés de contenus de grands éditeurs. La clé est de créer un contenu plus pertinent, plus clair et mieux structuré que les sources concurrentes.
Les systèmes d’IA mettent à jour leurs pools de sources en continu en explorant de nouveaux contenus et en réévaluant les sources existantes. Cependant, la fréquence varie selon la plateforme d’IA et le type de requête. Les requêtes sensibles au temps déclenchent des mises à jour plus fréquentes pour garantir l’actualité des informations, tandis que les sujets intemporels peuvent avoir des pools de sources plus stables. La plupart des systèmes d’IA réévaluent les pools de sources pour les requêtes populaires au moins chaque semaine, bien que la fréquence exacte ne soit généralement pas divulguée publiquement.
Le balisage schema améliore significativement l’inclusion dans le pool de sources en aidant les systèmes d’IA à comprendre la structure, le contexte et les relations du contenu. Le contenu intégrant un balisage Schema.org approprié affiche des taux d’inclusion 2 à 3 fois supérieurs dans les pools de sources IA par rapport à un contenu identique sans balisage. Le balisage schema aide les systèmes d’IA à identifier les informations clés, à vérifier les faits et à comprendre la finalité du contenu, ce qui en fait un facteur technique SEO essentiel pour la visibilité dans l’IA.
Vous pouvez surveiller l’inclusion dans le pool de sources à l’aide d’outils comme AmICited.com, qui suit la fréquence d’apparition de votre contenu dans les réponses générées par l’IA sur plusieurs plateformes, dont ChatGPT, Google AI Overviews et Perplexity. Ces outils montrent la fréquence des citations, les sources incluses pour des requêtes spécifiques et comment vos taux d’inclusion se comparent à ceux de la concurrence. Une surveillance régulière vous aide à comprendre l’impact de vos efforts d’optimisation et à identifier des axes d’amélioration.
Non, être inclus dans un pool de sources ne garantit pas que votre contenu sera cité dans une réponse générée par l’IA. L’inclusion signifie que votre contenu est pris en compte comme source potentielle, mais les systèmes d’IA appliquent des critères supplémentaires de filtrage et de sélection pour déterminer quelles sources seront effectivement citées. Des facteurs tels que la pertinence du contenu pour la requête spécifique, la clarté des affirmations et les exigences de diversité influencent la sélection finale depuis le pool de sources.
Les différentes plateformes d’IA construisent leurs pools de sources à l’aide d’algorithmes, de données d’entraînement et de critères d’évaluation différents. ChatGPT, Google AI Overviews, Perplexity et d’autres systèmes d’IA peuvent inclure différentes sources dans leurs pools pour une même requête. Cela signifie qu’un site peut figurer dans le pool de sources d’une plateforme mais être exclu de celui d’une autre. Réussir sa visibilité dans l’IA nécessite donc d’optimiser pour plusieurs plateformes et de surveiller les schémas d’inclusion sur différents systèmes d’IA.
Suivez la façon dont votre marque apparaît dans les pools de sources IA sur ChatGPT, Google AI Overviews, Perplexity et d’autres plateformes d’IA. Obtenez des informations en temps réel sur vos schémas de citation et votre positionnement par rapport à la concurrence.
Découvrez comment les systèmes d'IA sélectionnent et classent les sources à citer. Découvrez les algorithmes, signaux et facteurs qui déterminent quels sites we...

Découvrez comment les systèmes d’IA choisissent entre la citation de multiples sources et la concentration sur des sources autorisées. Comprenez les schémas de ...
Découvrez ce qu'est le contenu pilier pour la recherche IA, pourquoi il est essentiel pour la visibilité sur l'IA, et comment créer des pages faisant autorité q...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.