Google-Extended
Learn about Google-Extended, the user-agent token that lets publishers control whether their content is used for AI training in Gemini and Vertex AI. Understand...
6 min read
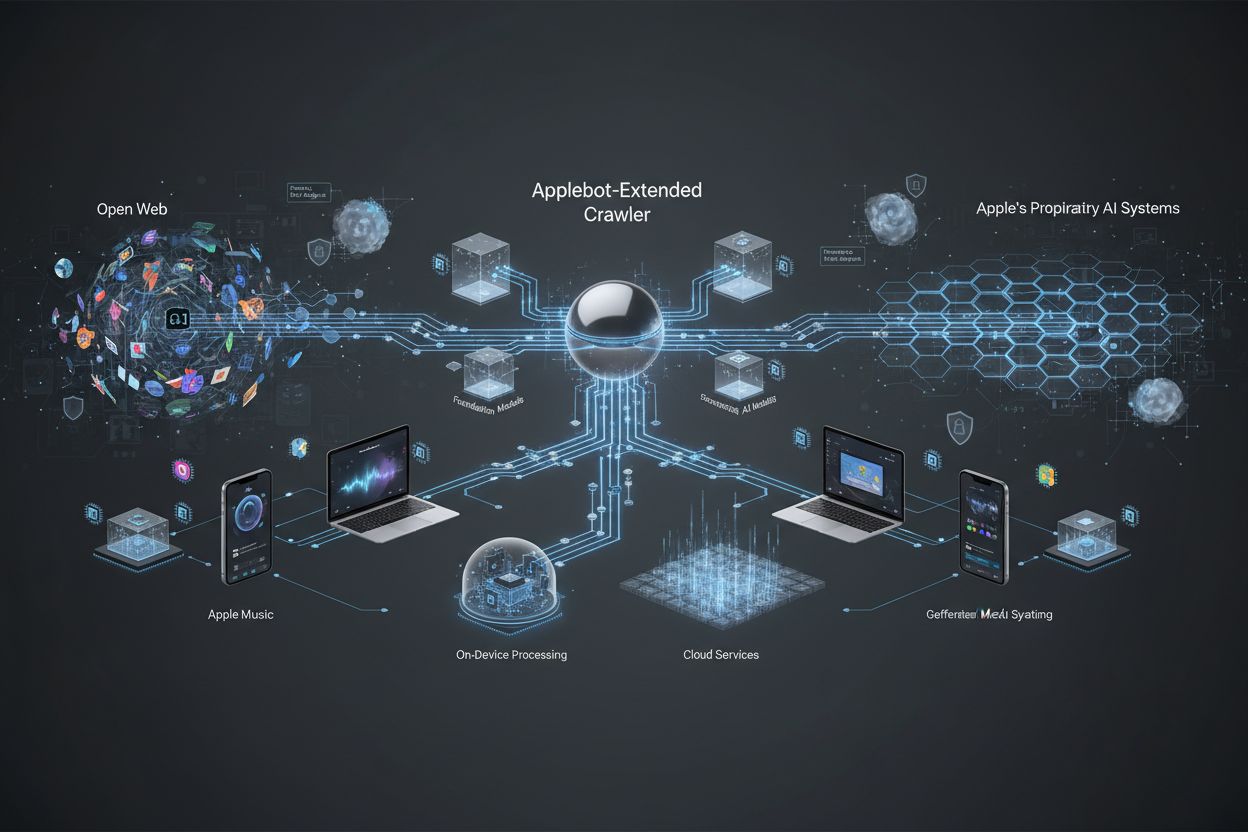
Apple’s specialized web crawler that evaluates content for training Apple Intelligence and generative AI models. It operates as a secondary evaluation mechanism to the standard Applebot, determining which publicly available web content is suitable for inclusion in Apple’s foundation models and LLMs. Website owners can control its access through robots.txt directives independently from standard Applebot.
Apple's specialized web crawler that evaluates content for training Apple Intelligence and generative AI models. It operates as a secondary evaluation mechanism to the standard Applebot, determining which publicly available web content is suitable for inclusion in Apple's foundation models and LLMs. Website owners can control its access through robots.txt directives independently from standard Applebot.
Applebot-Extended is a specialized web crawler operated by Apple that extends the capabilities of the standard Applebot to collect and evaluate content specifically for training Apple Intelligence systems. While the original Applebot primarily serves Apple’s search and indexing needs, Applebot-Extended operates as a distinct crawler focused on gathering high-quality content that can be used to improve Apple’s generative AI and machine learning models. This crawler represents Apple’s commitment to developing advanced AI training datasets by systematically identifying and processing web content that meets specific quality standards. The distinction between standard Applebot and Applebot-Extended is crucial for website owners, as the two crawlers serve different purposes and can be managed independently through robots.txt directives.
Applebot-Extended operates within a two-tier crawling system where initial content discovery by standard Applebot is followed by a secondary evaluation phase conducted by Applebot-Extended. When Applebot-Extended visits a webpage, it performs a comprehensive content evaluation to determine whether the material meets Apple’s standards for inclusion in AI training datasets. The crawler identifies itself through a specific user agent string that distinguishes it from standard Applebot, allowing website administrators to differentiate between the two crawlers in their server logs and analytics platforms. Applebot-Extended evaluates content based on multiple criteria including relevance, accuracy, originality, and adherence to quality guidelines that ensure only premium content contributes to Apple Intelligence systems.
| Feature | Applebot | Applebot-Extended |
|---|---|---|
| Primary Purpose | General indexing and search | AI training data collection |
| Content Focus | All web content | High-quality, curated content |
| User Agent | Applebot | Applebot-Extended |
| Evaluation Depth | Standard crawling | Advanced quality assessment |
| Blocking Method | robots.txt directives | Separate robots.txt rules |

Apple Intelligence represents Apple’s integrated suite of AI-powered features designed to enhance user experiences across iOS, iPadOS, macOS, and other Apple platforms through on-device and cloud-based processing. The generative AI capabilities powered by Applebot-Extended data include advanced writing tools, image generation, intelligent search enhancements, and context-aware assistant features that leverage foundation models and large language models (LLMs) trained on curated web content. These systems enable features such as Writing Tools for email and document composition, Image Playground for creative content generation, and enhanced Siri capabilities that understand complex user requests with greater nuance and accuracy. Apple’s approach emphasizes privacy-preserving AI by processing much of this intelligence on-device, while Applebot-Extended ensures that the training data underlying these systems comes from high-quality, diverse sources across the web. The crawler’s selective approach to content collection directly impacts the sophistication and reliability of Apple Intelligence features available to millions of users globally.
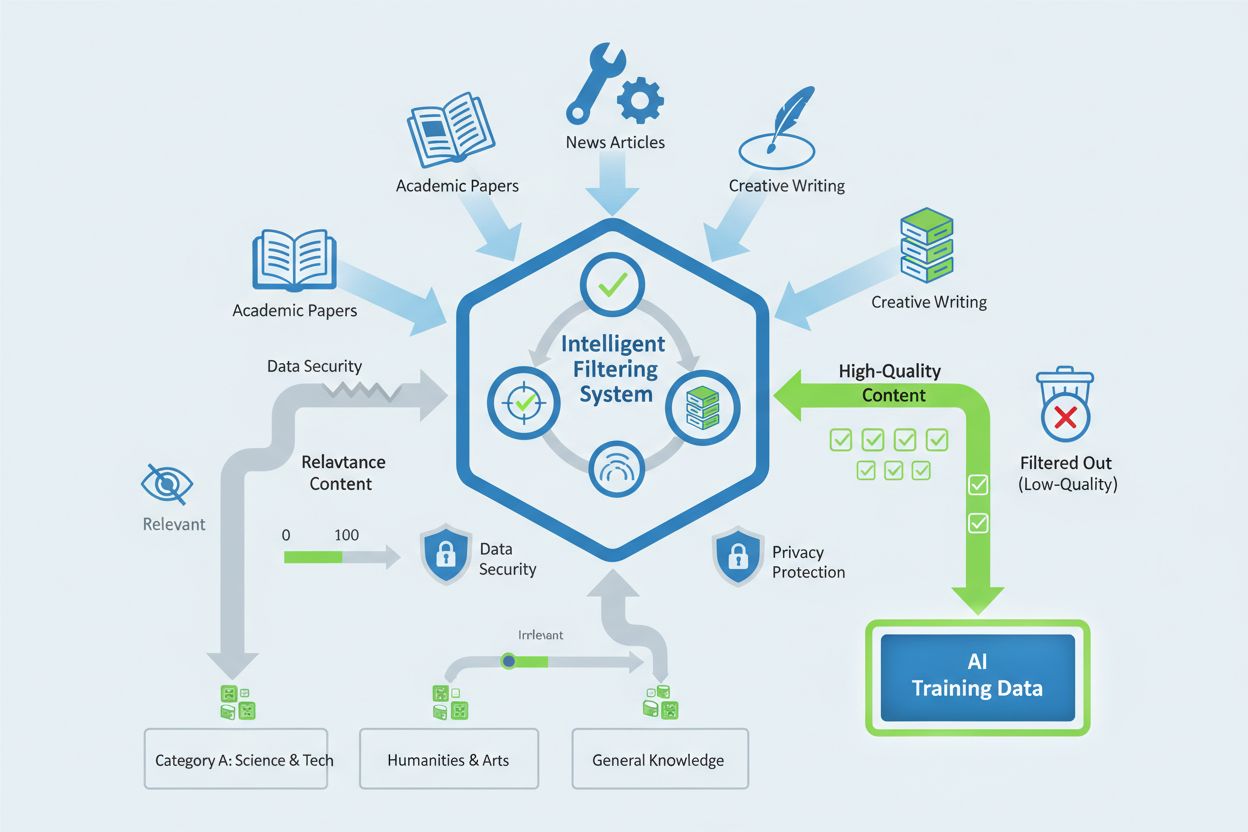
Applebot-Extended targets specific categories of content that demonstrate high informational value and reliability for AI training purposes. The crawler prioritizes content based on the following criteria:
The crawler employs sophisticated data filtering mechanisms to remove low-quality content, including spam, duplicate material, and content with minimal informational value. Apple implements privacy-preserving evaluation techniques that assess content quality without unnecessarily storing personal data or sensitive information. The selection process includes automated quality scoring systems that evaluate factors such as source credibility, content originality, factual accuracy, and relevance to Apple Intelligence training objectives. Website owners can influence their content’s inclusion by maintaining high editorial standards, ensuring original and authoritative material, and avoiding practices that artificially inflate content quality metrics.
Website administrators can control Applebot-Extended’s access to their content through robots.txt directives, which provide granular control over crawler behavior independent of standard Applebot restrictions. To block Applebot-Extended specifically while allowing standard Applebot to continue crawling, website owners can implement targeted rules that distinguish between the two crawlers using their respective user agent identifiers. The key distinction is that blocking standard Applebot does not automatically block Applebot-Extended, and vice versa—each crawler must be managed separately if different access policies are desired. Blocking Applebot-Extended may have minimal direct SEO implications since it doesn’t affect search rankings, but it prevents your content from contributing to Apple Intelligence training, potentially limiting your site’s visibility in Apple’s AI-powered features and services.
# Block only Applebot-Extended while allowing standard Applebot
User-agent: Applebot-Extended
Disallow: /
# Allow standard Applebot
User-agent: Applebot
Allow: /
# Block both Applebot and Applebot-Extended
User-agent: Applebot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Block specific directories from Applebot-Extended
User-agent: Applebot-Extended
Disallow: /private/
Disallow: /admin/
Allow: /public/
Apple maintains a privacy-first approach to Applebot-Extended operations, emphasizing that content collection for AI training respects user privacy and data protection regulations across jurisdictions. The company implements technical and organizational measures to ensure that personal data is not unnecessarily collected or retained during the crawling and evaluation process, with content assessment focused on informational value rather than personal information extraction. Website owners and content creators retain individual privacy rights regarding their data, including the ability to request information about how their content is used and to exercise removal rights under applicable privacy laws such as GDPR and CCPA. Apple provides the Apple Intelligence Privacy Inquiries form as a formal mechanism for individuals to submit questions, concerns, or requests related to how their content or personal data is handled in connection with Apple Intelligence systems. This structured approach to privacy ensures that the benefits of advanced AI capabilities are balanced against fundamental rights to data protection and user autonomy.
Website owners can detect Applebot-Extended visits by monitoring server logs and analyzing user agent strings, which will display “Applebot-Extended” in the crawler identification field. Specialized analytics tools such as Dark Visitors and UseHall provide enhanced visibility into AI crawler traffic, allowing administrators to track crawling patterns, frequency, and resource consumption associated with Applebot-Extended visits. These monitoring solutions help website owners understand the impact of AI crawlers on server resources and bandwidth, enabling informed decisions about crawler access policies and optimization strategies. By implementing proper traffic detection and logging mechanisms, administrators can distinguish Applebot-Extended activity from other crawler traffic and human user behavior, providing valuable insights into how their content contributes to Apple’s AI training infrastructure.
Applebot-Extended operates within a broader ecosystem of AI-focused web crawlers that serve different purposes and operate under distinct policies, each reflecting their parent company’s approach to AI development and data collection. Googlebot primarily serves Google’s search indexing and ranking functions, with separate crawlers like Googlebot-Extended handling content evaluation for Google’s AI systems, making it functionally similar to Apple’s two-tier approach but operating at significantly larger scale. Bingbot, Microsoft’s crawler, similarly supports both search indexing and AI training for Copilot and other generative AI services, though with different evaluation criteria and privacy frameworks. The ChatGPT crawler (operated by OpenAI) focuses specifically on content collection for large language model training, operating under explicit opt-out mechanisms and different data usage agreements than Apple’s approach. Unlike some competitors, Applebot-Extended distinguishes itself through Apple’s emphasis on on-device processing and privacy preservation, limiting cloud-based data retention and providing clearer opt-out mechanisms through robots.txt and formal privacy inquiry processes. The comparative analysis reveals that while all major tech companies employ AI crawlers, their evaluation criteria, data retention policies, and user control mechanisms vary significantly, reflecting different corporate philosophies regarding AI development, privacy, and content creator rights. Website owners should understand these differences when making decisions about crawler access, as each crawler’s policies and impact on their content’s use in AI systems differ substantially.
Applebot is Apple's primary web crawler used for search indexing and powering features like Spotlight and Siri search. Applebot-Extended is a secondary crawler that evaluates content already indexed by Applebot to determine if it's suitable for training Apple's generative AI models. They serve different purposes and can be managed independently through robots.txt.
You can block Applebot-Extended by adding specific rules to your robots.txt file. Use 'User-agent: Applebot-Extended' followed by 'Disallow: /' to block the entire site, or specify particular directories. This prevents your content from being used for Apple Intelligence training while still allowing standard Applebot to index your site for search purposes.
Blocking Applebot-Extended has minimal direct SEO impact since it doesn't affect search engine rankings. However, it prevents your content from contributing to Apple Intelligence training, which may reduce your visibility in Apple's AI-powered features and services in the future.
Applebot-Extended targets high-quality content including academic articles, technical documentation, professional news articles, original creative writing, and content from recognized subject matter experts. The crawler evaluates content based on credibility, originality, factual accuracy, and relevance to AI training objectives.
No. Apple explicitly states that it does not use users' private personal data or user interactions when training foundation models for Apple Intelligence. The company only uses publicly available web content, licensed materials, and synthetically created data. Apple implements privacy-preserving measures to remove personal information from training datasets.
You can detect Applebot-Extended visits by monitoring server logs for the 'Applebot-Extended' user agent string. Specialized analytics tools like Dark Visitors and UseHall provide enhanced visibility into AI crawler traffic, allowing you to track crawling patterns, frequency, and resource consumption.
Apple Intelligence is Apple's integrated suite of AI-powered features across iOS, iPadOS, macOS, and other platforms. Applebot-Extended collects high-quality web content that trains the foundation models and large language models powering Apple Intelligence features like Writing Tools, Image Playground, and enhanced Siri capabilities.
Yes. Apple provides the Apple Intelligence Privacy Inquiries form where individuals can submit requests regarding how their content or personal data is handled in connection with Apple Intelligence systems. You can also use standard robots.txt directives to opt out of Applebot-Extended crawling.
Track how your content appears in Apple Intelligence and other AI systems with AmICited's comprehensive AI monitoring platform.
Learn about Google-Extended, the user-agent token that lets publishers control whether their content is used for AI training in Gemini and Vertex AI. Understand...

Learn how to allow AI bots like GPTBot, PerplexityBot, and ClaudeBot to crawl your site. Configure robots.txt, set up llms.txt, and optimize for AI visibility.

Understand how AI crawlers like GPTBot and ClaudeBot work, their differences from traditional search crawlers, and how to optimize your site for AI search visib...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.