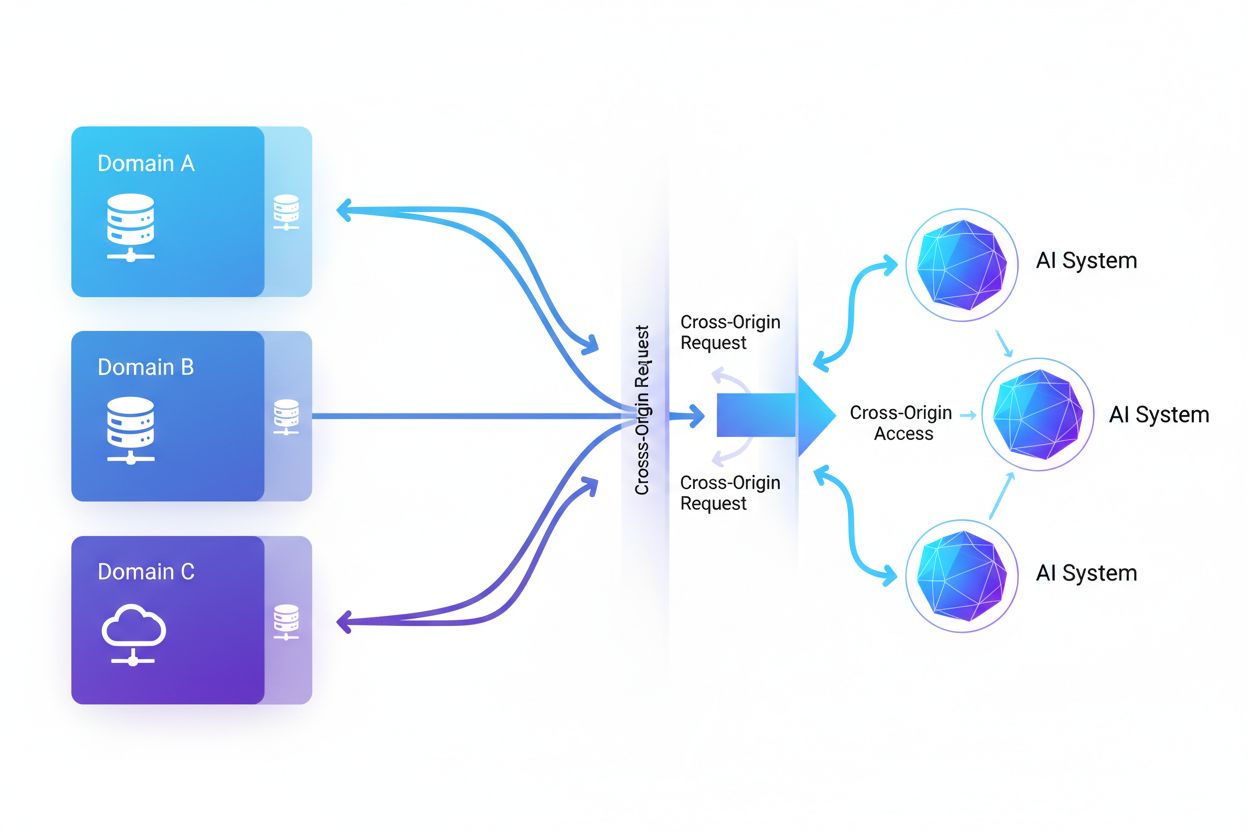
L’Accesso AI cross-origin si riferisce alla capacità dei sistemi di intelligenza artificiale e dei web crawler di richiedere e recuperare contenuti da domini diversi dalla loro origine, regolata da meccanismi di sicurezza come CORS. Comprende il modo in cui le aziende AI scalano la raccolta dati per l’addestramento di grandi modelli linguistici, gestendo le restrizioni cross-origin. Comprendere questo concetto è fondamentale per creatori di contenuti e proprietari di siti che vogliono proteggere la proprietà intellettuale e mantenere il controllo sull’uso dei loro contenuti da parte dei sistemi AI. La visibilità sull’attività AI cross-origin aiuta a distinguere tra accessi legittimi e scraping non autorizzato.
Accesso AI cross-origin
L’Accesso AI cross-origin si riferisce alla capacità dei sistemi di intelligenza artificiale e dei web crawler di richiedere e recuperare contenuti da domini diversi dalla loro origine, regolata da meccanismi di sicurezza come CORS. Comprende il modo in cui le aziende AI scalano la raccolta dati per l’addestramento di grandi modelli linguistici, gestendo le restrizioni cross-origin. Comprendere questo concetto è fondamentale per creatori di contenuti e proprietari di siti che vogliono proteggere la proprietà intellettuale e mantenere il controllo sull’uso dei loro contenuti da parte dei sistemi AI. La visibilità sull’attività AI cross-origin aiuta a distinguere tra accessi legittimi e scraping non autorizzato.
Comprendere l’Accesso AI cross-origin
L’Accesso AI cross-origin si riferisce alla capacità dei sistemi di intelligenza artificiale e dei web crawler di richiedere e recuperare contenuti da domini diversi dalla loro origine, regolata da meccanismi di sicurezza come il Cross-Origin Resource Sharing (CORS). Man mano che le aziende AI aumentano la raccolta dati per addestrare grandi modelli linguistici e altri sistemi AI, comprendere come questi sistemi gestiscono le restrizioni cross-origin è diventato fondamentale per i creatori di contenuti e i proprietari di siti web. La sfida principale è distinguere tra accessi AI legittimi per l’indicizzazione sui motori di ricerca e scraping non autorizzato per l’addestramento di modelli, rendendo essenziale la visibilità sull’attività AI cross-origin per proteggere la proprietà intellettuale e mantenere il controllo sull’utilizzo dei contenuti.
Meccanismo CORS e crawler AI
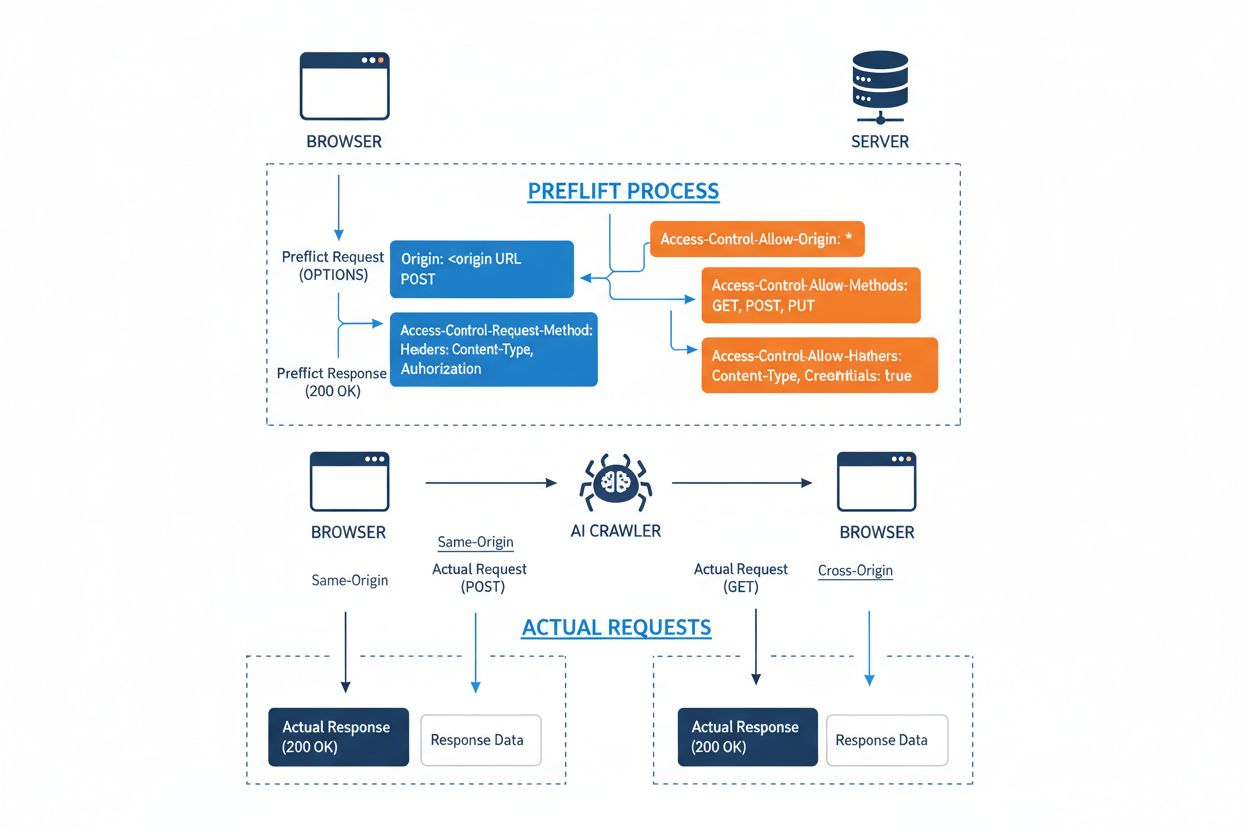
Il Cross-Origin Resource Sharing (CORS) è un meccanismo di sicurezza basato su header HTTP che consente ai server di specificare quali origini (domini, schemi o porte) possono accedere alle loro risorse. Quando un crawler AI o qualsiasi client tenta di accedere a una risorsa da un’origine diversa, il browser o il client avvia una richiesta preliminare tramite il metodo HTTP OPTIONS per verificare se il server consente la richiesta reale. Il server risponde con header CORS specifici che determinano i permessi d’accesso, inclusi quali origini sono consentite, quali metodi HTTP sono permessi, quali header possono essere inclusi e se credenziali come cookie o token di autenticazione possono essere inviati con la richiesta.
Header CORS
Scopo
Access-Control-Allow-Origin
Specifica quali origini possono accedere alla risorsa (* per tutte, o domini specifici)
Access-Control-Allow-Methods
Elenca i metodi HTTP permessi (GET, POST, PUT, DELETE, ecc.)
Access-Control-Allow-Headers
Definisce quali header di richiesta sono consentiti (Authorization, Content-Type, ecc.)
Access-Control-Allow-Credentials
Determina se credenziali (cookie, token di autenticazione) possono essere incluse nelle richieste
Access-Control-Max-Age
Indica per quanto tempo la risposta preliminare può essere memorizzata in cache (in secondi)
Access-Control-Expose-Headers
Elenca gli header di risposta a cui i client possono accedere
I crawler AI interagiscono con CORS rispettando questi header quando sono configurati correttamente, anche se molti bot sofisticati tentano di aggirare queste restrizioni camuffando i loro user agent o utilizzando reti proxy. L’efficacia di CORS come difesa contro accessi AI non autorizzati dipende interamente dalla corretta configurazione del server e dalla volontà del crawler di rispettare le restrizioni—una distinzione critica diventata sempre più importante man mano che le aziende AI competono per i dati di addestramento.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Il panorama dei crawler AI che accedono al web si è espanso notevolmente, con diversi attori principali che dominano i modelli di accesso cross-origin. Secondo l’analisi del traffico di rete di Cloudflare, i crawler AI più diffusi includono:
Bytespider (ByteDance) - Utilizzato per raccogliere dati di addestramento per modelli AI cinesi come Doubao, accede a circa il 40% dei siti sulla rete Cloudflare
GPTBot (OpenAI) - Raccoglie dati di addestramento per ChatGPT e futuri modelli, accedendo a circa il 35% dei siti protetti da Cloudflare
ClaudeBot (Anthropic) - Alimenta l’assistente Claude AI, con volumi di richieste in forte crescita e circa l’11% dei siti raggiunti
Amazonbot (Amazon) - Indicizza contenuti per le funzionalità di risposta alle domande di Alexa, rappresentando il secondo volume di richieste più alto
CCBot (Common Crawl) - Crawler no profit che produce dataset open web usati da diversi progetti AI, accede a circa il 2% dei siti
Google-Extended (Google) - Separato dal Googlebot standard, effettua crawling specificamente per Bard e Gemini AI
Perplexity Bot (Perplexity AI) - Raccoglie contenuti per il motore di ricerca Perplexity, noto però per aver camuffato i suoi user agent per aggirare le restrizioni
Questi crawler generano miliardi di richieste ogni mese, e alcuni come Bytespider e GPTBot accedono alla maggior parte dei contenuti pubblici su Internet. Il volume e la natura aggressiva di quest’attività hanno spinto grandi piattaforme come Reddit, Twitter/X, Stack Overflow e numerose testate giornalistiche ad implementare misure di blocco.
Vulnerabilità di sicurezza e rischi
Policy CORS configurate male creano gravi vulnerabilità che i crawler AI possono sfruttare per accedere a dati sensibili senza autorizzazione. Quando i server impostano Access-Control-Allow-Origin: * senza una corretta validazione, permettono involontariamente a qualsiasi origine—inclusi scraper AI malevoli—di accedere a risorse che dovrebbero essere protette. Una configurazione particolarmente pericolosa si verifica quando Access-Control-Allow-Credentials: true è combinato con impostazioni wildcard sull’origine, permettendo agli attaccanti di rubare dati autenticati tramite richieste cross-origin che includono cookie di sessione o token di autenticazione.
Errori comuni di configurazione CORS includono la riflessione dinamica dell’header Origin direttamente nella risposta Access-Control-Allow-Origin senza validazione, consentendo di fatto a qualsiasi origine di accedere alla risorsa. Allow-list troppo permissive che non validano correttamente i confini di dominio possono essere sfruttate tramite attacchi su sottodomini o manipolazioni di prefissi. Inoltre, molte organizzazioni non implementano una valida verifica dell’header Origin stesso, rendendole vulnerabili a richieste camuffate. Le conseguenze di queste vulnerabilità vanno oltre il furto di dati, includendo l’addestramento non autorizzato di modelli AI su contenuti proprietari, la raccolta di intelligence competitiva e la violazione di diritti di proprietà intellettuale—rischi che strumenti come AmICited.com aiutano a monitorare e quantificare.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Metodi di rilevamento per l’Accesso AI cross-origin
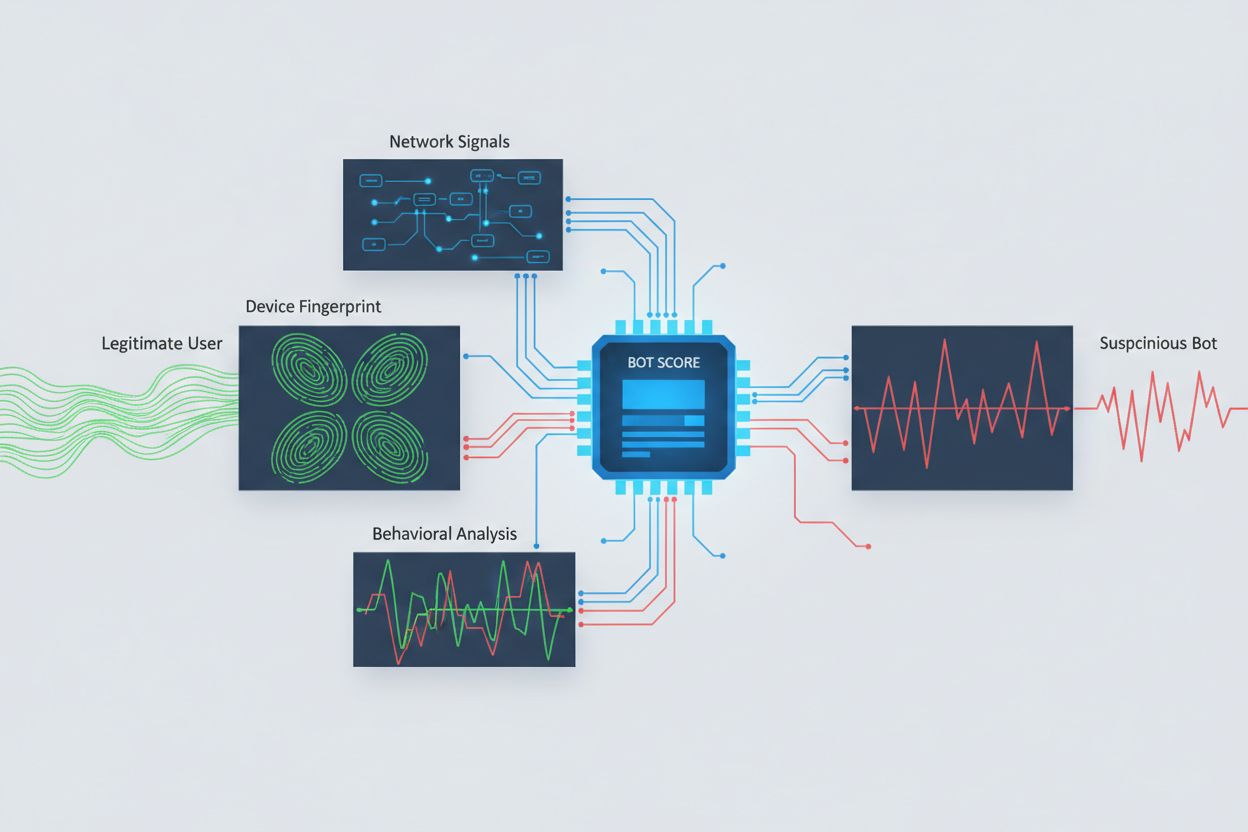
Identificare i crawler AI che tentano l’accesso cross-origin richiede l’analisi di molteplici segnali oltre alle semplici stringhe user agent, facilmente falsificabili. L’analisi dei user agent resta un primo metodo di rilevamento, poiché molti crawler AI si identificano tramite stringhe specifiche come “GPTBot/1.0” o “ClaudeBot/1.0”, ma i crawler sofisticati mascherano deliberatamente la loro identità impersonando browser legittimi. Il fingerprinting comportamentale analizza come vengono effettuate le richieste—esaminando pattern come tempistiche delle richieste, sequenza delle pagine visitate, presenza o assenza di esecuzione JavaScript e modelli di interazione diversi dalla normale navigazione umana.
L’analisi dei segnali di rete fornisce capacità di rilevamento più profonde esaminando le firme dell’handshake TLS, la reputazione IP, i pattern di risoluzione DNS e le caratteristiche della connessione che possono rivelare attività bot anche in presenza di user agent camuffati. Il fingerprinting dei dispositivi aggrega decine di segnali tra cui versione del browser, risoluzione schermo, font installati, dettagli sul sistema operativo e impronte TLS JA3 per creare identificativi unici per ogni fonte di richiesta. I sistemi avanzati di rilevamento possono individuare quando più sessioni provengono dallo stesso dispositivo o script, scoprendo tentativi di scraping distribuito che cercano di eludere il rate-limiting distribuendo le richieste su molti indirizzi IP. Le organizzazioni possono sfruttare questi metodi tramite piattaforme di sicurezza e servizi di monitoraggio per ottenere visibilità su quali sistemi AI stanno accedendo ai loro contenuti e come cercano di aggirare le restrizioni.
Bloccare e controllare l’accesso AI
Le organizzazioni utilizzano molteplici strategie complementari per bloccare o controllare l’accesso AI cross-origin, consapevoli che nessun metodo singolo offre protezione completa:
Regole Disallow su robots.txt - Aggiungere direttive di disallow per user agent AI noti (es. User-agent: GPTBot seguito da Disallow: /) offre un meccanismo educato ma volontario; efficace per i crawler rispettosi ma facilmente ignorato dagli scraper determinati
Filtraggio User Agent - Configurare server web o firewall per bloccare o reindirizzare specifiche stringhe user agent; più efficace di robots.txt ma vulnerabile al camuffamento, dato che i user agent sono facilmente falsificabili
Blocco indirizzi IP - Bloccare intervalli IP associati a scraper noti o provider cloud; efficace contro attacchi distribuiti ma aggirabile tramite rotazione proxy e reti IP residenziali
Rate Limiting e Throttling - Implementare limiti di frequenza che rallentano gli scraper; riduce l’impatto ma i bot sofisticati possono distribuire le richieste su molti IP per rimanere sotto soglia
Honeypot e Tarpit - Creare link nascosti o labirinti di link infiniti che solo i bot seguono, facendo sprecare risorse al crawler; sperimentale ma può degradare la qualità dei dataset degli scraper
Autenticazione e Paywall - Richiedere credenziali di accesso o pagamento per accedere ai contenuti; molto efficace ma scomodo per gli utenti legittimi e non sempre applicabile a tutti i tipi di contenuti
Fingerprinting avanzato dei dispositivi - Analisi di segnali comportamentali e di rete per identificare i bot indipendentemente dal camuffamento del user agent; approccio più sofisticato ma richiede integrazione con piattaforme di sicurezza
La difesa più efficace combina più livelli, poiché gli attaccanti determinati sfrutteranno le debolezze di qualsiasi approccio singolo. Le organizzazioni devono monitorare costantemente quali metodi di blocco funzionano e adattarsi man mano che i crawler evolvono le loro tecniche di elusione.
Best practice per la gestione dell’Accesso AI cross-origin
Una gestione efficace dell’accesso AI cross-origin richiede un approccio completo e stratificato che bilanci sicurezza ed esigenze operative. Le organizzazioni dovrebbero adottare una strategia a livelli, partendo da controlli di base come robots.txt e il filtraggio dei user agent, per poi aggiungere meccanismi di rilevamento e blocco più sofisticati in base alle minacce riscontrate. Il monitoraggio continuo è essenziale—tracciare quali sistemi AI accedono ai tuoi contenuti, con quale frequenza effettuano richieste e se rispettano le tue restrizioni fornisce la visibilità necessaria per prendere decisioni consapevoli sulle policy di accesso.
La documentazione delle policy di accesso deve essere chiara e applicabile, con termini di servizio espliciti che vietano lo scraping non autorizzato e specificano le conseguenze delle violazioni. Audit regolari delle configurazioni CORS aiutano a individuare errori prima che vengano sfruttati, mentre mantenere un inventario aggiornato di user agent e intervalli IP noti di crawler AI permette risposte rapide alle nuove minacce. Le organizzazioni dovrebbero anche considerare le implicazioni di business del blocco dell’accesso AI—alcuni crawler AI portano valore tramite l’indicizzazione nei motori di ricerca o partnership legittime, quindi le policy dovrebbero distinguere tra accessi utili e dannosi. Implementare queste pratiche richiede coordinamento tra team di sicurezza, legali e business per assicurare l’allineamento con obiettivi aziendali e requisiti normativi.
Strumenti e soluzioni per la gestione dell’accesso AI
Sono emersi strumenti e piattaforme specializzati per aiutare le organizzazioni a monitorare e controllare l’accesso AI cross-origin con maggiore precisione e visibilità. AmICited.com offre un monitoraggio completo di come i sistemi AI fanno riferimento e accedono al tuo brand su GPT, Perplexity, Google AI Overviews e altre piattaforme AI, fornendo visibilità su quali modelli AI utilizzano i tuoi contenuti e con quale frequenza il tuo brand appare nelle risposte generate. Questa capacità di monitoraggio si estende al tracciamento dei modelli di accesso cross-origin e alla comprensione dell’ecosistema più ampio di sistemi AI che interagiscono con le tue proprietà digitali.
Oltre al monitoraggio, Cloudflare offre funzionalità di gestione dei bot con blocco a un clic dei crawler AI noti, utilizzando modelli di machine learning addestrati su traffico di rete globale per identificare i bot anche quando camuffano i user agent. AWS WAF (Web Application Firewall) consente regole personalizzate per bloccare specifici user agent e intervalli IP, mentre Imperva offre rilevamento bot avanzato combinando analisi comportamentale e intelligence sulle minacce. Bright Data si specializza nella comprensione dei pattern di traffico bot e può aiutare le organizzazioni a distinguere tra i vari tipi di crawler. La scelta degli strumenti dipende da dimensione dell’organizzazione, maturità tecnica e necessità specifiche—da una semplice gestione di robots.txt per piccoli siti fino a piattaforme di gestione bot enterprise per grandi organizzazioni con dati sensibili. Indipendentemente dalla scelta, il principio fondamentale resta: la visibilità sull’accesso AI cross-origin è la base per un controllo e una protezione efficaci dei propri asset digitali.
Domande frequenti
Qual è la differenza tra CORS e Accesso AI cross-origin?
CORS (Cross-Origin Resource Sharing) è un meccanismo di sicurezza che controlla quali origini possono accedere alle risorse su un server. L’Accesso AI cross-origin si riferisce specificamente a come i sistemi AI e i crawler interagiscono con CORS per richiedere contenuti da domini differenti. Sebbene CORS sia il quadro tecnico, l’Accesso AI cross-origin descrive la sfida pratica di gestire il comportamento dei crawler AI all’interno di tale quadro, incluso il rilevamento e il blocco degli accessi AI non autorizzati.
Come si identificano i crawler AI quando accedono ai contenuti?
La maggior parte dei crawler AI ben comportati si identifica tramite specifiche stringhe user agent come 'GPTBot/1.0' o 'ClaudeBot/1.0' che indicano chiaramente il loro scopo. Tuttavia, molti crawler sofisticati falsificano deliberatamente i user agent impersonando browser legittimi come Chrome o Safari per aggirare i blocchi basati su user agent. Ecco perché sono necessari metodi di rilevamento avanzati che utilizzano fingerprinting comportamentale e analisi dei segnali di rete per identificare i bot indipendentemente dall’identità dichiarata.
robots.txt può bloccare efficacemente i crawler AI?
robots.txt fornisce un meccanismo volontario per chiedere ai crawler di rispettare le restrizioni di accesso, e i crawler AI ben comportati come GPTBot generalmente rispettano queste direttive. Tuttavia, robots.txt non è vincolante—i scraper determinati possono semplicemente ignorarlo. Molte aziende AI sono state sorprese a bypassare le restrizioni di robots.txt, rendendolo una difesa necessaria ma insufficiente che dovrebbe essere combinata con metodi tecnici come il filtraggio dei user agent, il rate limiting e il fingerprinting dei dispositivi.
Quali sono i principali rischi di sicurezza di una configurazione CORS errata per l’accesso AI?
Policy CORS configurate male possono permettere a crawler AI non autorizzati di accedere a dati sensibili, rubare informazioni di utenti autenticati tramite richieste abilitate alle credenziali e prelevare contenuti proprietari per l’addestramento non autorizzato di modelli AI. Le configurazioni più pericolose combinano impostazioni wildcard per l’origine con permessi di credenziali, consentendo di fatto a qualsiasi origine di accedere a risorse protette. Queste configurazioni errate possono portare a furto di proprietà intellettuale, raccolta di informazioni competitive e violazione di accordi di licenza dei contenuti.
Come posso rilevare se i sistemi AI stanno accedendo ai miei contenuti?
Il rilevamento richiede l’analisi di molteplici segnali oltre alle stringhe user agent. Puoi esaminare i log del server per user agent noti di crawler AI, implementare fingerprinting comportamentale per identificare i bot dai loro modelli di interazione, analizzare segnali di rete come handshake TLS e pattern DNS, e usare il fingerprinting dei dispositivi per identificare tentativi di scraping distribuito. Strumenti come AmICited.com forniscono monitoraggio completo di come i sistemi AI fanno riferimento al tuo brand, mentre piattaforme come Cloudflare offrono rilevamento bot basato su machine learning in grado di identificare anche i crawler camuffati.
Qual è il modo più efficace per bloccare i crawler AI indesiderati?
Nessun metodo singolo offre protezione completa, quindi l’approccio più efficace è stratificato. Inizia con robots.txt e il filtraggio dei user agent per una difesa di base, aggiungi il rate limiting per ridurre l’impatto, implementa il fingerprinting dei dispositivi per identificare i bot sofisticati e considera autenticazione o paywall per i contenuti sensibili. Le organizzazioni più efficaci combinano più tecniche e monitorano costantemente quali metodi funzionano, adattandosi man mano che i crawler evolvono le loro tecniche di evasione.
Tutte le aziende AI rispettano le restrizioni di accesso cross-origin?
No. Sebbene grandi aziende come OpenAI e Anthropic dichiarino di rispettare le restrizioni di robots.txt e CORS, indagini hanno rivelato che molti crawler AI aggirano tali restrizioni. Perplexity AI è stata sorpresa a camuffare i user agent per superare i blocchi, e ricerche mostrano che crawler di OpenAI e Anthropic sono stati osservati accedere a contenuti nonostante regole robots.txt esplicitamente restrittive. Questa incoerenza rende sempre più necessari metodi tecnici di blocco e azioni legali.
In che modo AmICited.com aiuta a monitorare l’accesso AI ai miei contenuti?
AmICited.com offre un monitoraggio completo di come i sistemi AI fanno riferimento e accedono al tuo brand su GPT, Perplexity, Google AI Overviews e altre piattaforme AI. Traccia quali modelli AI utilizzano i tuoi contenuti, con quale frequenza il tuo brand appare nelle risposte AI generate, e fornisce visibilità sull’ecosistema più ampio di sistemi AI che interagiscono con le tue proprietà digitali. Questo monitoraggio ti aiuta a comprendere l’estensione dell’accesso AI e a prendere decisioni informate sulla strategia di protezione dei tuoi contenuti.
Monitora come i sistemi AI accedono ai tuoi contenuti
Ottieni completa visibilità su quali sistemi AI stanno accedendo al tuo brand su GPT, Perplexity, Google AI Overviews e altre piattaforme. Traccia i modelli di accesso AI cross-origin e comprendi come i tuoi contenuti vengono utilizzati per l’addestramento e l’inferenza AI.
Audit di Accesso dei Crawler AI: I Bot Giusti Vedono i Tuoi Contenuti?
Scopri come eseguire un audit dell'accesso dei crawler AI al tuo sito web. Scopri quali bot possono vedere i tuoi contenuti e risolvi i blocchi che impediscono ...
Scopri come condurre un audit di accessibilità AI per assicurare che il tuo sito web sia individuabile dai crawler AI come ChatGPT, Claude e Perplexity. Guida t...
Come Garantire che i Crawler AI Vedano Tutti i Tuoi Contenuti
Scopri come rendere i tuoi contenuti visibili ai crawler AI come ChatGPT, Perplexity e l’AI di Google. Approfondisci i requisiti tecnici, le best practice e le ...
12 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.