
どのAIクローラーにアクセスを許可すべきか?2025年完全ガイド
どのAIクローラーをrobots.txtで許可またはブロックすべきかを解説。GPTBot、ClaudeBot、PerplexityBotなど25種類以上のAIクローラーと設定例を網羅した総合ガイド。...
2 分で読める

AIクローラの許可やブロックを戦略的に選択することで、コンテンツが学習用かリアルタイム検索用か、どのように利用されるかを管理する実践です。robots.txtファイル、サーバーレベルの制御、監視ツールを用いて、どのAIシステムがどの目的であなたのコンテンツにアクセスできるかを制御します。
AIクローラの許可やブロックを戦略的に選択することで、コンテンツが学習用かリアルタイム検索用か、どのように利用されるかを管理する実践です。robots.txtファイル、サーバーレベルの制御、監視ツールを用いて、どのAIシステムがどの目的であなたのコンテンツにアクセスできるかを制御します。
AIクローラ管理とは、人工知能システムによるウェブサイトコンテンツへのアクセスと利用(学習用・検索用)をコントロールおよび監視する実践を指します。従来の検索エンジンクローラがウェブ検索結果用にコンテンツをインデックスするのに対し、AIクローラは主に大規模言語モデルの学習やAI搭載検索機能のためにデータ収集を行います。この活動の規模は組織によって大きく異なり、OpenAIのクローラはリファレンス1回につき1,700回アクセス(1,700:1)、Anthropicは73,000:1と、現代AIシステムの学習には膨大なデータ消費が必要であることがわかります。効果的なクローラ管理により、ウェブサイト所有者は自分のコンテンツがAI学習に利用されるか、AI検索結果に表示されるか、あるいは自動アクセスから保護されるかを選択できます。
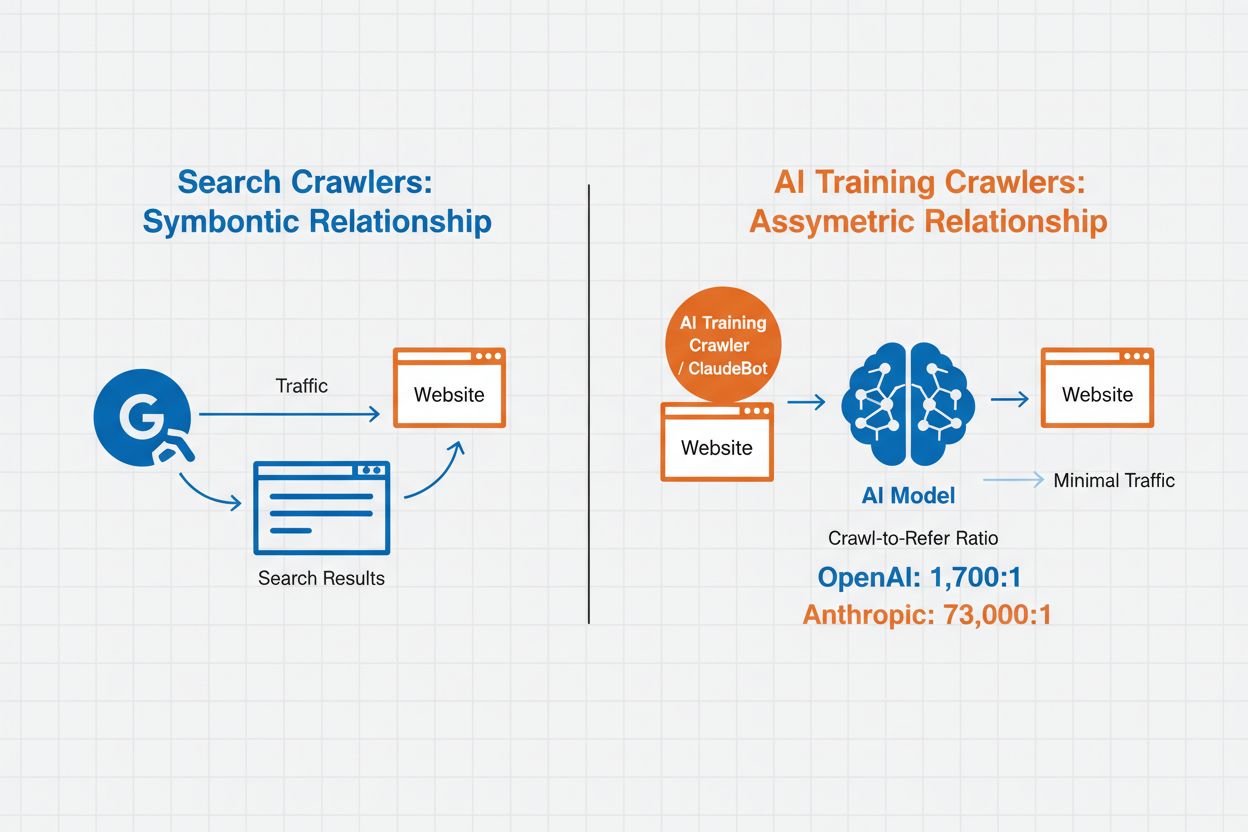
AIクローラは、その目的やデータ利用パターンに基づき3つのカテゴリに分けられます。学習用クローラは機械学習モデル開発のために膨大なコンテンツを収集し、AIの性能向上に貢献します。検索・引用クローラはAI検索機能やAI生成応答への引用のためにインデックス作成を行い、ユーザーがAI経由であなたのコンテンツを発見できるようにします。ユーザー起動型クローラは、ChatGPTユーザーがドキュメントをアップロードしたり、特定のウェブページの分析を依頼したときなど、ユーザー操作に応じてオンデマンドで動作します。これらのカテゴリを理解することで、コンテンツ戦略やビジネスゴールに沿ってどのクローラを許可・ブロックするか判断できます。
| クローラ種別 | 目的 | 例 | 学習データ利用 |
|---|---|---|---|
| 学習用 | モデル開発・改良 | GPTBot, ClaudeBot | あり |
| 検索・引用 | AI検索結果・引用 | Google-Extended, OAI-SearchBot, PerplexityBot | ケースによる |
| ユーザー起動型 | オンデマンド分析 | ChatGPT-User, Meta-ExternalAgent, Amazonbot | 文脈依存 |
AIクローラ管理はウェブサイトのトラフィック、収益、コンテンツ価値に直接影響します。クローラが補償なしでコンテンツを消費すると、リファラル流入や広告表示、ユーザーエンゲージメントなどの利益を得る機会が失われます。実際、多くのウェブサイトで、ユーザーがAI生成回答から直接情報を得て元サイトに遷移しなくなったことで、トラフィックと広告収入が大幅に減少した事例が報告されています。経済的な影響だけでなく、コンテンツは知的財産であり、その利用方法や帰属、補償をコントロールする権利があるという法的・倫理的側面も重要です。さらに、無制限のクローラアクセスはサーバー負荷や帯域コストを増大させ、特にレート制限を無視する攻撃的なクローラからのアクセスは深刻な問題となります。
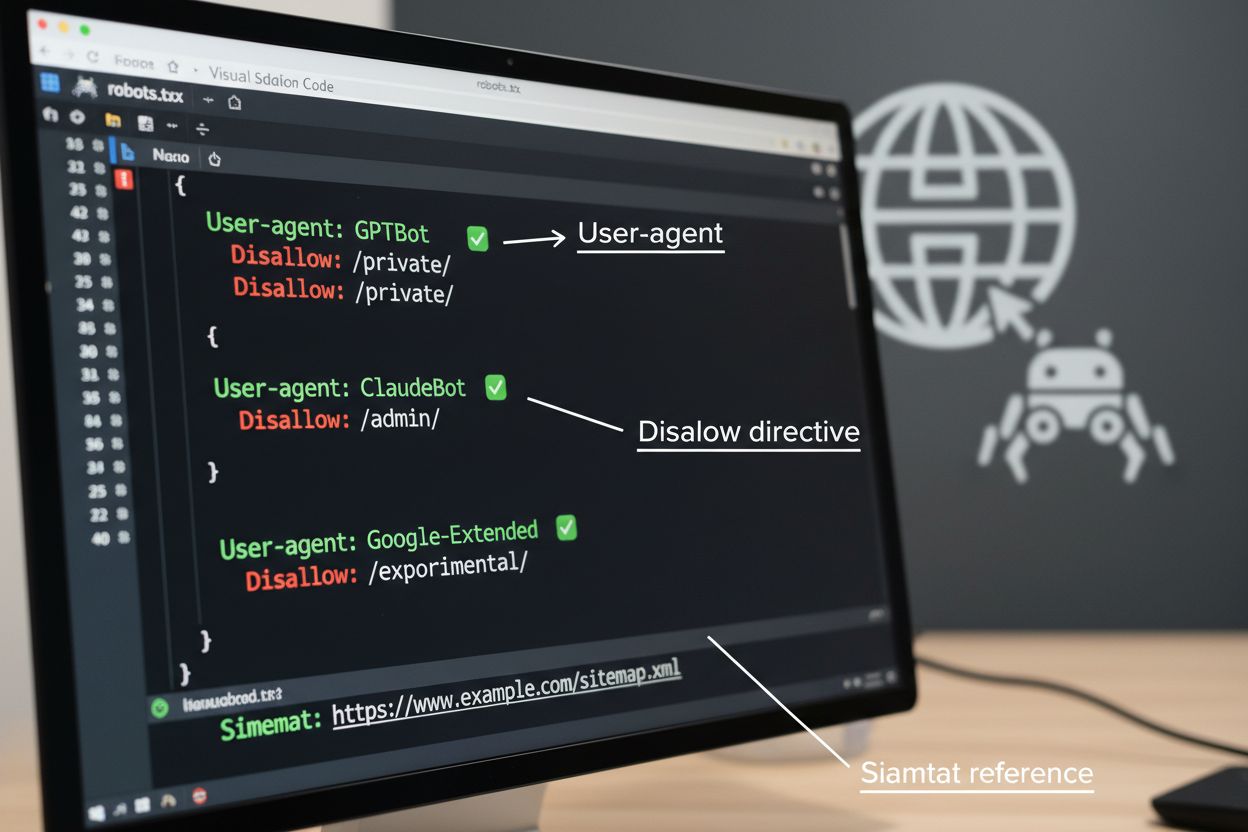
robots.txtファイルはクローラアクセス管理の基本ツールで、ウェブサイトのルートディレクトリに配置し、自動化エージェントにクロールの希望を伝えます。このファイルはUser-agentディレクティブで特定のクローラをターゲットにし、DisallowやAllowルールで特定パスやリソースへのアクセス可否を指定します。ただしrobots.txtには重大な制限があります。これはクローラの自主的遵守に依存する任意標準であり、悪意ある・未熟なボットは無視する可能性があります。また、robots.txtは公開コンテンツへのアクセスを技術的にブロックするものではなく、あくまで希望を伝えるだけです。そのため、robots.txtは多層的な管理策の一部として利用し、唯一の防御策としないことが重要です。
# AI学習用クローラをブロック
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# 検索エンジンは許可
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# その他クローラのデフォルトルール
User-agent: *
Allow: /
robots.txt以外にも、より強力な施行や詳細な制御を実現する方法があります。これらはインフラ層ごとに作用し、組み合わせて包括的な保護が可能です:
AIクローラをブロックするかどうかの判断には、コンテンツ保護と発見性のトレードオフが伴います。すべてのAIクローラをブロックすると、AI検索結果・AI要約・AIツールによる引用へのコンテンツ掲載可能性が失われ、これらの新しいチャネル経由での発見性が下がります。一方、無制限に許可すると、補償なくAI学習に利用され、AI経由でユーザーが直接回答を得てリファラル流入が減る可能性もあります。戦略的なアプローチとしては選択的ブロックが有効で、OAI-SearchBotやPerplexityBotなど引用型クローラ(リファラル流入源)は許可し、GPTBotやClaudeBotなど学習用クローラ(帰属なし消費)はブロックする方法が挙げられます。Google AI Overviewsでの可視性を維持したい場合はGoogle-Extendedのみ許可し、競合他社の学習用クローラはブロックするなど、コンテンツ種別・ビジネスモデル・オーディエンスに応じて最適な戦略を選択しましょう。ニュースメディアやパブリッシャーはブロックを優先し、教育コンテンツ提供者はAI可視性を重視する場合もあります。
クローラ制御は、クローラが実際に指示を守っているか検証して初めて効果を発揮します。サーバーログ分析がクローラ活動監視の主な方法で、アクセスログ内のUser-Agentやリクエストパターンを調査し、どのクローラがアクセスしているか、robots.txtルールを守っているかを確認できます。多くのクローラは遵守を主張しつつもブロックパスにアクセスし続けるため、継続的な監視が不可欠です。Cloudflare Radarなどのツールを利用すれば、トラフィックパターンをリアルタイムで可視化でき、不審または非準拠クローラも特定できます。ブロック対象リソースへのアクセス試行に自動アラートを設定し、新たなクローラや回避パターンの兆候を定期的に監査しましょう。
効果的なAIクローラ管理には、保護と戦略的可視性のバランスをとった体系的アプローチが必要です。包括的なクローラ管理戦略を構築するために、次の8ステップを実践しましょう:
AmICited.comは、さまざまなAIモデルやアプリケーションであなたのコンテンツがどのように参照・利用されているかを監視できる専門プラットフォームです。このサービスでは、AI生成回答でのあなたの引用をリアルタイムに追跡でき、どのクローラが最も積極的にコンテンツを利用しているか、どの程度AI出力に現れているかを可視化します。クローラパターンや引用データを分析することで、どのクローラが引用・リファラルを通じて価値をもたらし、どのクローラが帰属なしでコンテンツを消費しているかを把握できます。このインテリジェンスにより、クローラ管理を防御的だけでなく、AI時代のウェブにおけるコンテンツの可視性とインパクト最大化のための戦略的ツールへと進化させることができます。
GPTBotやClaudeBotのような学習用クローラは、大規模言語モデル開発のためのデータセット構築を目的にコンテンツを収集し、リファラル流入を伴わずにあなたのコンテンツを消費します。OAI-SearchBotやPerplexityBotなどの検索クローラは、AI検索結果用のインデックス作成を行い、引用を通じて訪問者をあなたのサイトに送り返す場合もあります。学習用クローラをブロックすることで、あなたのコンテンツがAIモデルに取り込まれるのを防げますが、検索クローラをブロックするとAI検索プラットフォームでの可視性が低下する可能性があります。
いいえ。GPTBot、ClaudeBot、CCBotなどのAI学習用クローラをブロックしても、GoogleやBingの検索順位には影響しません。従来の検索エンジンはGooglebotやBingbotといった別のクローラを使用しており、AI学習用ボットとは独立して動作します。検索結果から完全に消したい場合のみ、従来の検索クローラをブロックしてください(この場合はSEOに悪影響があります)。
サーバーのアクセスログを調べ、クローラのUser-Agent文字列を特定しましょう。User-Agent欄に「bot」「crawler」「spider」などが含まれるエントリを探してください。Cloudflare Radarなどのツールを使えば、どのAIクローラがどのようなトラフィックパターンであなたのサイトにアクセスしているかリアルタイムで確認できます。また、ボットトラフィックと人間の訪問者を区別できる分析プラットフォームも活用できます。
はい。robots.txtはクローラの遵守に依存する推奨標準で、強制力はありません。OpenAI、Anthropic、Googleなど主要企業のクローラは一般的にrobots.txtの指示を尊重しますが、中にはまったく無視するクローラも存在します。より強力な保護を求める場合は、.htaccess、ファイアウォールルール、IPベースの制限などサーバーレベルでのブロックを実施してください。
これはビジネス上の優先順位によります。すべての学習用クローラをブロックすれば、AIモデルへのコンテンツ取り込みを防げますが、リファラル流入の可能性がある検索クローラは許可することもできます。多くのパブリッシャーは、学習用クローラのみをターゲットにした選択的ブロックを行い、検索・引用クローラは許可しています。コンテンツの種類、トラフィック源、収益モデルを考慮して戦略を決定してください。
最低でも四半期ごとにクローラ管理ポリシーを見直し・更新しましょう。新しいAIクローラは定期的に現れ、既存クローラも通知なくUser-Agentを変更します。GitHub上のai.robots.txtプロジェクトなどコミュニティ管理リストをチェックし、毎月サーバーログを確認して新たなクローラを発見しましょう。
AIクローラはトラフィックや収益に大きな影響を及ぼします。ユーザーがAIシステムから直接回答を得てサイトを訪問しなくなると、リファラル流入や広告表示機会が失われます。あるAIプラットフォームでは、クローラのアクセス数に対するリファラル比率が73,000:1にもなるという調査結果もあり、実際には数千回アクセスされても訪問者はほとんど返ってきません。学習用クローラをブロックすることでトラフィックを守り、検索クローラを許可することで一部のリファラル恩恵を得られる場合もあります。
サーバーログをチェックし、ブロックしたはずのクローラがアクセスログに現れていないか確認しましょう。Google Search Consoleのrobots.txtテスターやMerkle's Robots.txt Testerなどのツールを使って設定を検証できます。yoursite.com/robots.txtに直接アクセスし、内容が正しいか確認しましょう。ログを定期的に監視し、ブロック対象のクローラが現れていないかチェックしてください。
AmICited.comは、ChatGPT、Perplexity、Google AI Overviewsなど様々なAIシステムによるブランド参照をリアルタイムで追跡します。クローラ管理戦略に関するデータ主導の意思決定を可能にします。
どのAIクローラーをrobots.txtで許可またはブロックすべきかを解説。GPTBot、ClaudeBot、PerplexityBotなど25種類以上のAIクローラーと設定例を網羅した総合ガイド。...

AIクローラーをブロックするかどうかの戦略的判断方法を解説します。コンテンツタイプ、トラフィックソース、収益モデル、競争状況を評価するための包括的な意思決定フレームワークをご紹介。...
GPTBot、PerplexityBot、ClaudeBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列やIP検証手法、AIトラフィック追跡のベストプラクティスもご紹介。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.