
ClaudeBot解説:Anthropicのクローラーとあなたのコンテンツ
ClaudeBotの仕組みやClaude-Web・Claude-SearchBotとの違い、robots.txt設定によるAnthropicのウェブクローラー管理方法について解説します。...
1 分で読める

ClaudeBotは、AnthropicによるClaude AIモデルの学習データ収集用ウェブクローラーです。公開されているウェブサイトを体系的にクロールし、機械学習モデルの学習用コンテンツを収集します。ウェブサイト管理者はrobots.txt設定によりClaudeBotのアクセスを制御できます。このクローラーはrobots.txtの標準指示に従うため、サイトごとにアクセス許可やブロックが可能です。
ClaudeBotは、AnthropicによるClaude AIモデルの学習データ収集用ウェブクローラーです。公開されているウェブサイトを体系的にクロールし、機械学習モデルの学習用コンテンツを収集します。ウェブサイト管理者はrobots.txt設定によりClaudeBotのアクセスを制御できます。このクローラーはrobots.txtの標準指示に従うため、サイトごとにアクセス許可やブロックが可能です。
ClaudeBotは、Anthropic社が運用するウェブクローラーで、ClaudeなどのAI製品を支える大規模言語モデル(LLM)の学習データをダウンロードするために利用されます。このAIデータスクレーパーは、従来の検索エンジンクローラーが検索インデックス目的で巡回するのとは異なり、機械学習モデルの学習専用にウェブサイトを体系的にクロールしてコンテンツを収集します。ClaudeBotはユーザーエージェント文字列で識別でき、robots.txt設定によってブロックまたは許可できるため、ウェブサイト管理者は自分のコンテンツがAnthropicのAIモデル学習に使われるかどうかを制御できます。

ClaudeBotは、インデックス済みサイトのリンク辿り、サイトマップの処理、公開ウェブサイトリストからのシードURL利用など、体系的なウェブ探索手法で運用されています。クローラーは認証不要な公開ページからコンテンツをダウンロードし、Claudeの言語モデル学習用データセットに含めます。検索エンジンクローラーがインデックス目的で優先順位を付けるのとは異なり、ClaudeBotのクロールパターンは一般に不透明であり、Anthropicは具体的なサイト選択基準やクロール頻度、コンテンツ種別ごとの優先順位をほとんど公開していません。
以下の表は、ClaudeBotと他のAnthropicクローラーの比較です。
| Bot Name | Purpose | User Agent | Scope |
|---|---|---|---|
| ClaudeBot | チャット引用取得・学習データ収集 | ClaudeBot/1.0 | モデル学習向け一般ウェブクロール |
| anthropic-ai | 大規模モデル学習データ収集 | anthropic-ai | 大規模学習データセット編成 |
| Claude-Web | Claude機能向けウェブ特化クロール | Claude-Web | ウェブ検索・リアルタイム情報取得 |
ClaudeBotは、GPTBot(OpenAI)やPerplexityBot(Perplexity)のような他の主要AI学習クローラーと類似の運用を行いますが、収集範囲や手法に明確な違いがあります。GPTBotはOpenAIの学習を主目的とし、PerplexityBotは検索と学習の両方を担っていますが、ClaudeBotはClaudeのモデル学習用コンテンツの収集に特化しています。Dark Visitorsのデータによれば、世界トップ1,000サイトの約**18%**がClaudeBotを積極的にブロックしており、そのデータ収集への懸念の大きさが伺えます。各社の最大の違いはコンテンツ収集の優先度にあり、Anthropicは体系的かつ広範囲な学習データ収集を重視する一方、検索系クローラーはインデックス化とリファラル流入のバランスを取っています。
ウェブサイト管理者は、ユーザーエージェント文字列をサーバーログで監視することでClaudeBotのアクセスを特定できます。該当する文字列は次の通りです:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
ClaudeBotは通常アメリカ合衆国のIP帯からアクセスし、サーバーログ解析や専用監視ツールで追跡できます。エージェント分析プラットフォームを導入すれば、ClaudeBotの訪問頻度やクロールパターンをリアルタイムで可視化できます。
サーバーログ上でのClaudeBotアクセス例:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
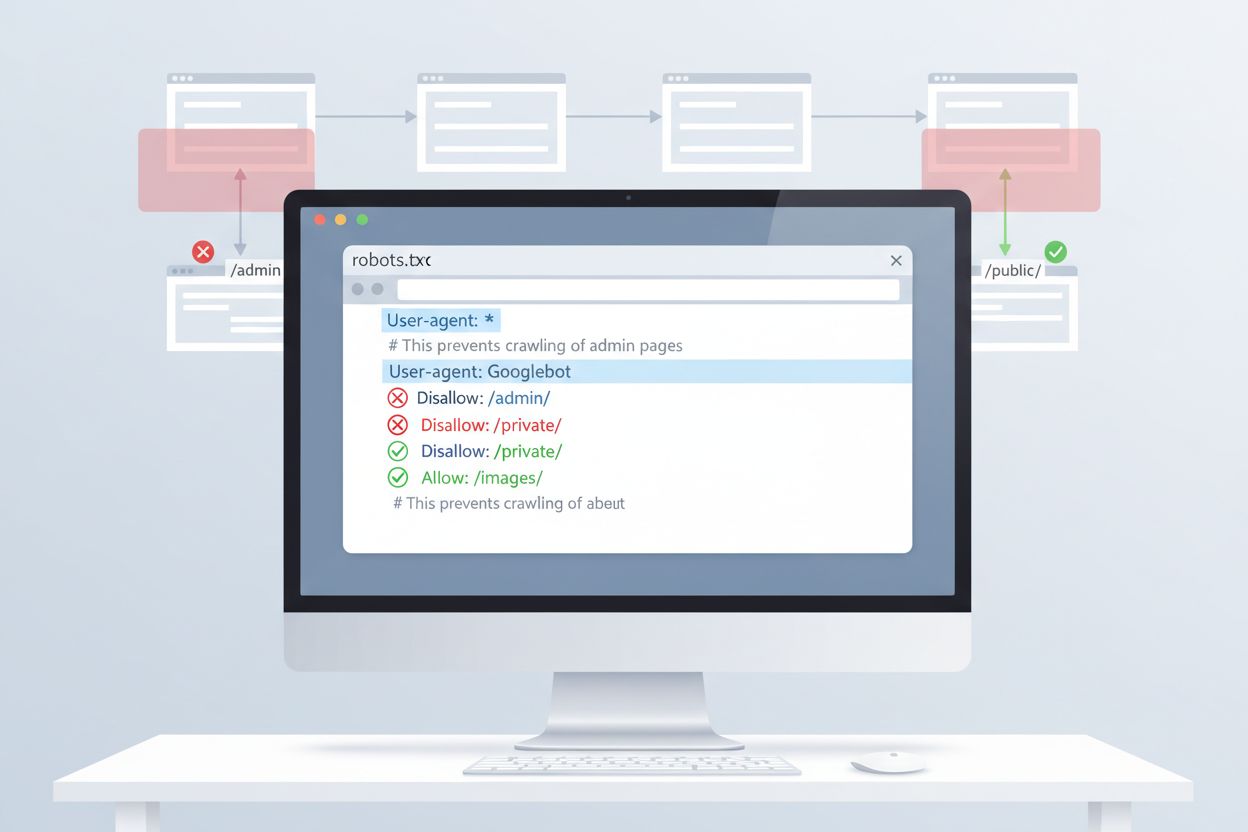
ClaudeBotへのアクセス制御で最も手軽な方法は、ウェブサイトのルートディレクトリにrobots.txtを設定することです。このファイルによりクローラーがアクセス可能な領域を指定でき、AnthropicのClaudeBotはこれを尊重します。ClaudeBotの全アクセスをブロックするには、下記のように設定します:
User-agent: ClaudeBot
Disallow: /
特定ディレクトリのみブロックし、他のコンテンツのクロールを許可する場合は以下のように記述します:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Anthropicの全クローラー(anthropic-aiやClaude-Web含む)を一括でブロックしたい場合は、それぞれに個別ルールを追加します:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
robots.txtは第一防衛線として有効ですが、遵守は任意です。より強力な制御を求める場合、次のような追加ブロック手法があります:
これらの方法はrobots.txtより高度な技術が必要ですが、ルールを守らないクローラーへの強固な対策となります。
ClaudeBotをブロックしても、従来型SEO順位への直接的な影響はほとんどありません。なぜなら学習用クローラーは検索エンジンのインデックスに寄与せず、GoogleやBingなどは独自クローラー(Googlebot、Bingbot)で独立運用しているためです。ただし、ClaudeBotをブロックするとClaudeによるAI生成回答でのコンテンツ掲載機会が減り、将来的なAI検索・チャット経由での発見性が下がる可能性もあります。ClaudeBotの許可・ブロックの戦略的判断は、コンテンツ収益モデル次第です。直接的なウェブトラフィックや広告収益を重視するなら、学習データへの吸収を防ぐことで訪問者減少を抑えられます。逆にClaudeの回答に自サイトが掲載されることでAIチャット経由の流入を期待するなら、ClaudeBotを許可するのも選択肢です。
ClaudeBotの効果的な管理には、継続的な監視と設定テストが重要です。Google Search Consoleのrobots.txtテスターやMerkleのrobots.txtテストツール、Dark Visitorsなどの専門プラットフォームを使い、ブロックルールが意図通り機能しているか確認しましょう。サーバーログも定期的に確認し、ClaudeBotがrobots.txt指示を守っているか、クロールパターンに変化がないか監視します。AIクローラーの状況は日々変化し新規ボットも頻繁に登場するため、robots.txtの四半期ごと見直しで新たなクローラーへの対応やコンテンツ保護戦略の維持が可能です。本番適用前の設定テストも重要で、正規クローラーや他の重要ボットの誤ブロックを防ぎましょう。
ClaudeBotはAnthropicのウェブクローラーで、Claude AIモデルの学習データ収集のために体系的にウェブサイトを巡回します。リンクの辿り、サイトマップの処理、公開ウェブサイトリストなどからあなたのサイトを発見します。クローラーは公開されているコンテンツを収集し、Claudeの言語モデル能力向上に役立てます。
ウェブサイトのルートディレクトリにrobots.txtルールを追加することでClaudeBotをブロックできます。「User-agent: ClaudeBot」の後に「Disallow: /」と記載すれば全アクセスを禁止できますし、特定パスのみブロックすることも可能です。AnthropicのClaudeBotはrobots.txtの指示に従います。
いいえ、ClaudeBotをブロックしてもGoogleやBingの検索順位には影響しません。ClaudeBotのような学習用クローラーは従来の検索エンジンとは独立して動作します。検索順位に影響するのはGooglebotやBingbotのブロックのみです。
Anthropicは主に3つのクローラーを運用しています:ClaudeBot(チャット引用取得と一般的な学習データ)、anthropic-ai(大量学習データ収集)、Claude-Web(リアルタイム機能向けのウェブクロール)。それぞれAnthropicのAIインフラで異なる目的を担っています。
サーバーログでClaudeBotのユーザーエージェント文字列「Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)」を確認してください。Dark Visitorsのような監視ツールやエージェント分析を導入することでリアルタイム追跡も可能です。
はい、ClaudeBotはAnthropic公式ドキュメント通りrobots.txtの指示を尊重します。ただし、全てのrobots.txtルール同様、遵守は任意です。より強力な制御にはサーバーレベルのブロックやIPフィルタ、WAFルールなどが有効です。
ClaudeBotはサイト規模やコンテンツ量によっては相応の帯域幅を消費する可能性があります。AIデータスクレーパーは従来の検索エンジンより積極的にクロールすることもあるため、サーバーログの監視で影響を把握し、ブロックや許可の判断材料にしましょう。
ビジネスモデルによって異なります。コンテンツの帰属や補償、AI利用方法に懸念がある場合はClaudeBotをブロックしましょう。Claudeの回答やAI検索結果に自分のコンテンツを表示したい場合は許可してください。集客収益戦略を考慮して判断しましょう。
ClaudeBotや他のAIクローラーによるコンテンツへのアクセスを追跡しましょう。どのAIシステムがあなたのブランドを引用し、コンテンツがAI生成回答でどのように使われているかを把握できます。
ClaudeBotの仕組みやClaude-Web・Claude-SearchBotとの違い、robots.txt設定によるAnthropicのウェブクローラー管理方法について解説します。...

CCBotとは何か、その仕組み、ブロック方法、AI訓練における役割や、監視ツール、AIによるデータ収集からコンテンツを守るためのベストプラクティスについて解説します。...

ブランド、ドメイン、URLをClaude AIのアンサー最適化する方法を学びましょう。プロンプトエンジニアリング、コンテンツ戦略、AI検索エンジンでの可視性向上のベストプラクティスを解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.