
Hoe om te gaan met dubbele content voor AI-zoekmachines
Leer hoe je dubbele content beheert en voorkomt bij het gebruik van AI-tools. Ontdek canonical tags, redirects, detectietools en best practices voor het behoude...
11 min lezen

Leer hoe canonieke URL’s problemen met dubbele content in AI-zoeksystemen voorkomen. Ontdek best practices voor het implementeren van canonicals om AI-zichtbaarheid te verbeteren en correcte toeschrijving van content te waarborgen.
Grote taalmodellen en AI-zoeksystemen gebruiken geavanceerde clustering-algoritmen om bijna-identieke URL’s te identificeren en te groeperen, waarbij meerdere versies van dezelfde content als één entiteit worden behandeld voor ranking- en citatiedoeleinden. Wanneer AI-systemen dubbele content tegenkomen, moeten ze bepalen welke versie prioriteit krijgt—een beslissing die direct invloed heeft op welke URL zichtbaarheid, autoriteitssignalen en gebruikersattributie ontvangt. Het kritieke probleem ontstaat wanneer AI de verkeerde versie selecteert: als je canonieke URL naar de voorkeurs-pagina verwijst, maar het AI-systeem een duplicaat van lagere kwaliteit groepeert en rangschikt, verliest je content zichtbaarheid en citatiekrediet. Intentsignalen raken verspreid over dubbele versies, waardoor de autoriteit die op één URL geconcentreerd zou moeten zijn, gefragmenteerd raakt en elke duplicaat zwakkere rankingsignalen ontvangt dan wanneer alle autoriteit was geconsolideerd op de canonieke versie.
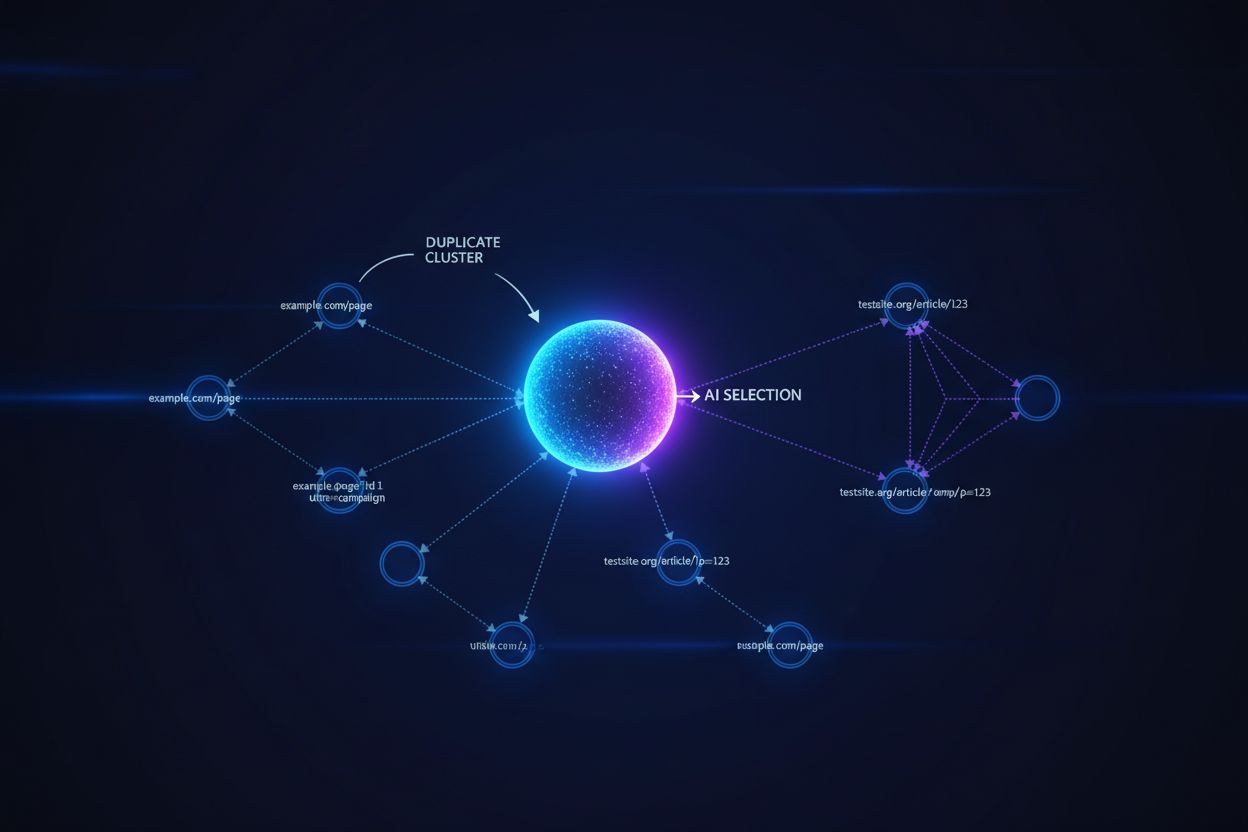
Canonieke tags dienen als expliciete signalen aan AI-systemen over welke versie van dubbele content als gezaghebbend moet worden beschouwd, wat direct beïnvloedt of je voorkeurs-URL verschijnt in AI-gegenereerde antwoorden en correct wordt toegeschreven. Zonder canonieke tags moeten AI-systemen hun eigen clusteringbeslissingen nemen op basis van contentgelijkenis, linkpatronen en actualiteitssignalen—vaak met als resultaat dat de verkeerde versie als canonieke bron wordt geselecteerd. Wanneer dubbele content bestaat zonder correcte canonical-implementatie, kunnen AI-antwoorden een gesyndiceerde versie, een gecachte kopie of een variant van lagere kwaliteit citeren in plaats van je originele content, waardoor je zichtbaarheid over meerdere URL’s wordt verspreid. Canonieke URL’s zorgen ervoor dat wanneer AI-systemen je content tegenkomen op verschillende domeinen, parameters of versies, ze begrijpen welke enkele URL krediet moet ontvangen en getoond moet worden in antwoorden.
| Scenario | Zonder Canonical | Met Canonical |
|---|---|---|
| Invloed op AI | AI groepeert duplicaten onafhankelijk; kan verkeerde versie kiezen voor ranking | AI herkent één gezaghebbende bron; consolideert alle signalen naar canonieke URL |
| Citatiekrediet | Toeschrijving verspreid over meerdere URL’s; zwakkere autoriteit per URL | Alle citaties en autoriteit vloeien naar de canonieke URL; sterkere zichtbaarheid |
| Resultaat | Content verschijnt in AI-antwoorden maar verkeerde URL krijgt krediet; gefragmenteerde zichtbaarheid | Voorkeurs-URL verschijnt in AI-antwoorden met geconsolideerde autoriteitssignalen |
Canonieke tags en redirects dienen verschillende doelen bij het beheren van dubbele content voor AI-systemen: canonieke tags vertellen zoekmachines en AI-systemen welke versie de voorkeur heeft terwijl beide URL’s toegankelijk blijven, terwijl redirects gebruikers en crawlers permanent van de ene naar de andere URL sturen. Redirects (301 voor permanent, 302 voor tijdelijk) zijn sterkere signalen omdat ze alle autoriteit samenvoegen in één URL en het duplicaat volledig van het web verwijderen, waardoor ze ideaal zijn als je een URL permanent verwijdert of domeinen samenvoegt. Canonieke tags zijn de voorkeur wanneer je om zakelijke redenen meerdere URL’s moet behouden—zoals trackingparameters voor analytics, legacy-URL’s voor gebruikersbladwijzers, of verschillende versies voor verschillende doelgroepen—terwijl je toch aan AI-systemen aangeeft welke versie gezaghebbend is. Gebruik redirects bij het samenvoegen van domeinen na een migratie, het verwijderen van verouderde versies, of het elimineren van parameter-variaties die geen onderscheidend doel dienen. Gebruik canonieke tags als je meerdere URL’s moet behouden maar dubbele content-penalty’s wilt voorkomen en AI-systemen wilt laten weten welke versie je voorkeur heeft.
Belangrijkste verschillen tussen canonicals en redirects:
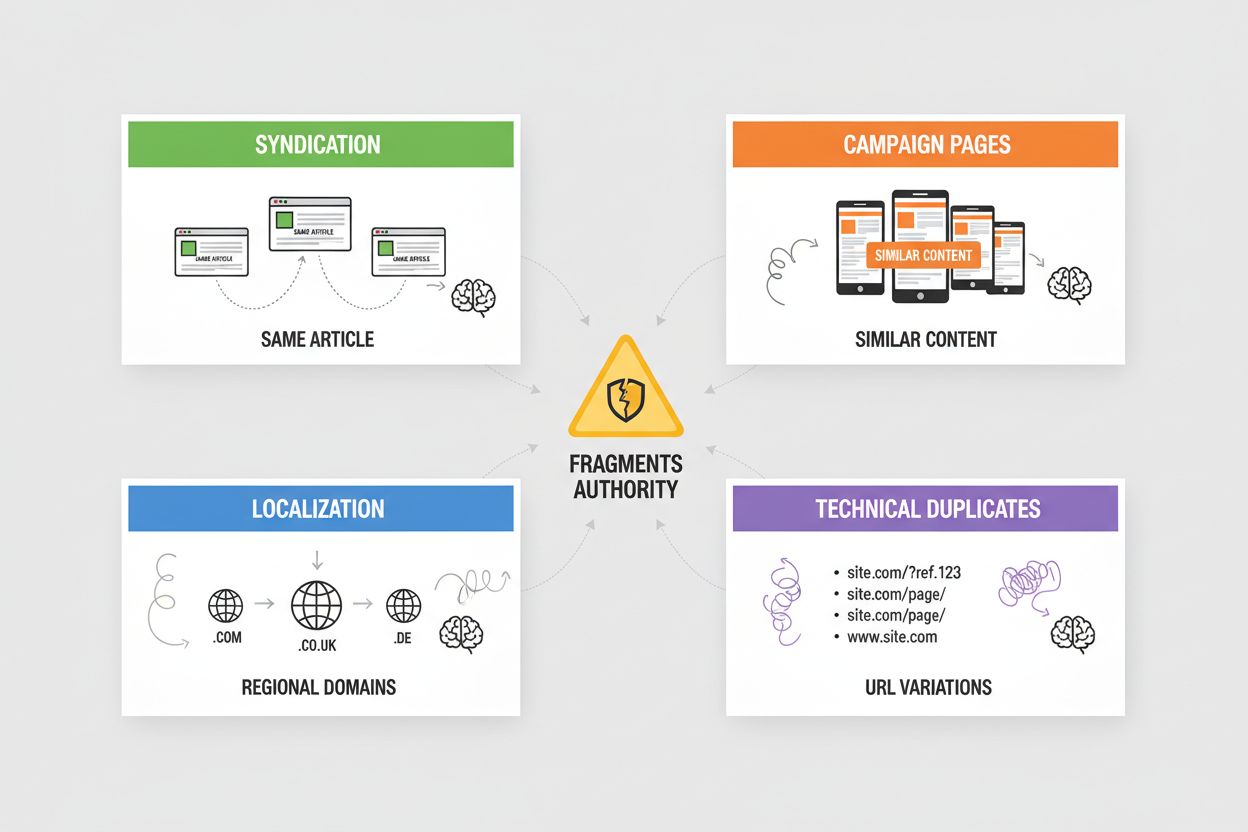
Syndicatie veroorzaakt wijdverspreide dubbele content wanneer je artikelen worden hergepubliceerd op partnerwebsites, nieuwsaggregatoren of contentnetwerken—AI-systemen moeten bepalen of ze het origineel of de gesyndiceerde versie krediet geven, en kiezen vaak voor degene die het eerst wordt gecrawld. Campagnepagina’s genereren duplicaten wanneer je meerdere landingspagina’s met identieke of bijna-identieke content maakt voor verschillende marketingkanalen, UTM-parameters of A/B-testen, waardoor AI-systemen de autoriteit verspreiden over variaties die eigenlijk geconsolideerd zouden moeten worden. Lokalisatie en internationalisatie veroorzaken duplicaten wanneer je vergelijkbare content serveert op regionale domeinen (voorbeeld.com, voorbeeld.co.uk, voorbeeld.de) of taalversies, wat hreflang-tags en canonical-implementatie vereist om te voorkomen dat AI-systemen deze als dubbele content behandelen in plaats van als bedoelde variaties. Technische duplicaten ontstaan door sessie-ID’s, trackingparameters, printervriendelijke versies en URL-variaties (www versus non-www, http versus https, trailing slashes) die meerdere URL’s naar identieke content laten wijzen—AI-systemen zien deze als duplicaten en moeten bepalen welke versie prioriteit krijgt. Elk van deze scenario’s verspreidt de autoriteit die op je voorkeurs-URL zou moeten concentreren, vermindert je zichtbaarheid in AI-gegenereerde antwoorden en zorgt dat citatiekrediet over meerdere versies wordt verspreid.
Gebruik altijd absolute URL’s in je canonieke tags in plaats van relatieve URL’s, zodat AI-systemen en zoekmachines de doel-URL ondubbelzinnig kunnen identificeren, ongeacht waar de tag verschijnt. Voeg zelfverwijzende canonicals toe aan je voorkeurs-pagina’s—zelfs pagina’s zonder duplicaten moeten zichzelf als canonical aanduiden, om te voorkomen dat AI-systemen canonicals afleiden op basis van linkpatronen of contentgelijkenis. Plaats canonieke tags in de <head>-sectie van je HTML-document, en implementeer voor niet-HTML-content (PDF’s, afbeeldingen) canonicals via HTTP-headers om te waarborgen dat AI-crawlers je voorkeur herkennen ongeacht het contenttype.
<!-- Correcte implementatie van canonical in de HTML-head -->
<link rel="canonical" href="https://voorbeeld.com/artikel/canonieke-urls-ai" />
Neem canonieke URL’s op in je XML-sitemaps om te onderstrepen welke versies gezaghebbend zijn, en combineer canonicals met hreflang-tags bij het beheren van internationale of gelokaliseerde content, zodat AI-systemen regionale variaties niet als duplicaten behandelen. Vermijd veelgemaakte fouten: maak nooit ketens van canonicals (A→B→C), wijs canonicals nooit naar noindex-pagina’s en gebruik canonicals nooit om rankings te manipuleren door naar niet-gerelateerde content te verwijzen. Monitor je canonical-implementatie met tools zoals Google Search Console, Bing Webmaster Tools en AmICited.com om te verifiëren dat AI-systemen je voorkeurs-URL’s herkennen en correct toeschrijven.
<!-- Correcte implementatie met hreflang voor internationale content -->
<link rel="canonical" href="https://voorbeeld.com/artikel/canonieke-urls-ai" />
<link rel="alternate" hreflang="en-GB" href="https://voorbeeld.co.uk/artikel/canonieke-urls-ai" />
<link rel="alternate" hreflang="de" href="https://voorbeeld.de/artikel/canonieke-urls-ai" />
Controleer je canonieke URL’s door je volledige site te crawlen met tools zoals Screaming Frog, SEMrush of Ahrefs om pagina’s zonder canonicals, gebroken canonical-ketens of canonicals die verwijzen naar noindex-pagina’s te identificeren—deze problemen voorkomen dat AI-systemen autoriteit correct samenvoegen. Gebruik het Coverage-rapport van Google Search Console om pagina’s met dubbele contentproblemen te identificeren en te verifiëren dat Google je canonical-voorkeuren herkent, en vergelijk dit met Bing Webmaster Tools om consistentie over AI-zoeksystemen te waarborgen. Implementeer IndexNow om zoekmachines en AI-crawlers direct op de hoogte te stellen wanneer je canonieke tags toevoegt, bijwerkt of verwijdert, zodat je voorkeuren sneller worden ontdekt in plaats van te wachten op natuurlijke crawl-cycli. Monitor AI-verwijzingen met tools zoals AmICited.com en handmatige zoekopdrachten in ChatGPT, Claude en Perplexity om te verifiëren dat je voorkeurs-URL’s worden toegeschreven in AI-gegenereerde antwoorden—als duplicaten worden geciteerd, herzie dan je canonical-implementatie en zorg dat tags correct geformatteerd en geplaatst zijn. Controleer regelmatig op nieuwe dubbele content die ontstaat via syndicatiepartners, campagne-lanceringen of technische wijzigingen, en implementeer canonicals proactief in plaats van reactief om consistente AI-zichtbaarheid te behouden.
Een canonieke URL is de voorkeursversie van een pagina die je wilt dat zoekmachines en AI-systemen als gezaghebbend herkennen. Dit is belangrijk voor AI-zoekopdrachten omdat LLM's bijna-identieke URL's groeperen en één versie kiezen om de set te vertegenwoordigen. Zonder correcte canonical-implementatie kunnen AI-systemen de verkeerde versie van je content citeren, waardoor je zichtbaarheid en toeschrijving over meerdere URL's wordt verspreid.
AI-systemen gebruiken clustering-algoritmen om bijna-identieke URL's te groeperen tot één entiteit, en selecteren vervolgens één versie om de hele cluster te vertegenwoordigen. Dit verschilt van traditionele zoekmachines omdat AI-antwoorden één bron-URL voor toeschrijving vereisen. Als je canonical niet goed is geïmplementeerd, kan AI een gesyndiceerde versie, gecachte kopie of variant van lagere kwaliteit kiezen in plaats van je voorkeurs-URL.
Gebruik canonieke tags als je om zakelijke redenen meerdere URL's moet behouden (trackingparameters, legacy-URL's, verschillende doelgroepen) en toch de voorkeur wilt aangeven aan AI-systemen. Gebruik redirects bij het permanent verwijderen van een URL, het consolideren van domeinen of het elimineren van parameter-variaties die geen doel dienen. Redirects zijn sterkere signalen omdat ze alle autoriteit volledig samenvoegen, terwijl canonicals de autoriteit verdelen maar voorkeur aangeven.
De meest voorkomende problemen zijn: syndicatie (herpublicatie van artikelen op partnerwebsites), campagnepagina's (meerdere landingspagina's met identieke content), lokalisatie (vergelijkbare content op regionale domeinen) en technische duplicaten (URL-parameters, sessie-ID's, trailing slashes). Elk van deze fragmenten verdeelt autoriteit over meerdere URL's, wat de zichtbaarheid in AI-gegenereerde antwoorden vermindert.
Gebruik altijd absolute URL's (https://voorbeeld.com/pagina, niet /pagina), plaats canonieke tags in de HTML-headsectie, voeg zelfverwijzende canonicals toe op alle pagina's en vermijd canonical-ketens (A→B→C). Gebruik voor niet-HTML-content zoals PDF's HTTP-headers. Neem canonicals op in je XML-sitemap en combineer ze met hreflang-tags voor internationale content.
Gebruik Google Search Console en Bing Webmaster Tools om canonical-herkenning te verifiëren, monitor AI-verwijzingen met AmICited.com en handmatige zoekopdrachten in ChatGPT/Claude/Perplexity, en analyseer je site met crawlers zoals Screaming Frog of SEMrush. Als duplicaten worden geciteerd in plaats van je canonical, herzie dan je implementatie en zorg dat tags correct geformatteerd zijn en in de HTML-head geplaatst zijn.
IndexNow is een protocol dat zoekmachines en AI-crawlers direct op de hoogte stelt wanneer je canonieke tags toevoegt, bijwerkt of verwijdert, in plaats van te wachten op natuurlijke crawl-cycli. Dit versnelt de ontdekking van je canonical-voorkeuren en zorgt ervoor dat AI-systemen je voorkeurs-URL's sneller herkennen, waardoor de tijd dat duplicaten in AI-antwoorden verschijnen wordt verkort.
Ja, canonieke tags zijn sterke signalen maar geen instructies. AI-systemen kunnen je canonical-voorkeur negeren als ze bepalen dat een andere versie meer gezaghebbend is op basis van contentkwaliteit, linkpatronen, actualiteit of andere signalen. Daarom is correcte implementatie in combinatie met sterke content en autoriteitssignalen belangrijk—dit vergroot de kans dat AI-systemen je canonical-voorkeur respecteren.
Volg hoe AI-systemen zoals ChatGPT, Claude en Perplexity jouw content citeren. Zorg dat je canonieke URL's goed worden herkend en dat je merk de juiste toeschrijving krijgt in AI-gegenereerde antwoorden.
Leer hoe je dubbele content beheert en voorkomt bij het gebruik van AI-tools. Ontdek canonical tags, redirects, detectietools en best practices voor het behoude...
Discussie binnen de community over hoe AI-systemen anders omgaan met dubbele content dan traditionele zoekmachines. SEO-professionals delen inzichten over conte...

Dubbele content is identieke of vergelijkbare inhoud op meerdere URL's die zoekmachines verwart en de autoriteit van pagina's verwatert. Ontdek hoe het SEO, AI-...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.