
AI-verlanglijst
Ontdek wat AI-verlanglijsten zijn, hoe ze werken en hun impact op conversiepercentages in e-commerce, klantbehoud en gepersonaliseerde winkelervaringen.
7 min lezen
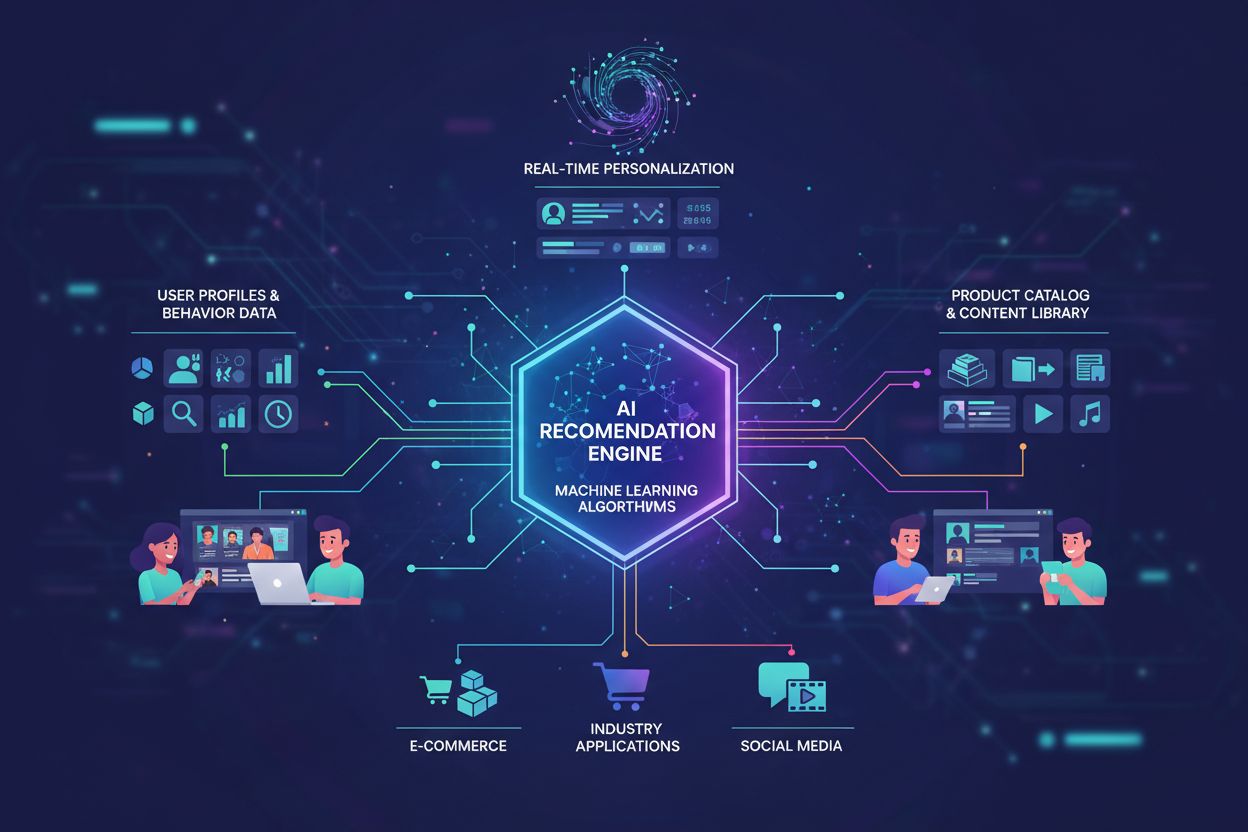
Machine learning-systemen die gebruikersgedrag en -voorkeuren analyseren om gepersonaliseerde product- en inhoudssuggesties te leveren. Deze systemen gebruiken algoritmen zoals collaboratief filteren en contentgebaseerd filteren om te voorspellen waar gebruikers mogelijk in geïnteresseerd zijn, waardoor bedrijven de betrokkenheid, verkoop en klanttevredenheid kunnen verhogen via op maat gemaakte aanbevelingen.
Machine learning-systemen die gebruikersgedrag en -voorkeuren analyseren om gepersonaliseerde product- en inhoudssuggesties te leveren. Deze systemen gebruiken algoritmen zoals collaboratief filteren en contentgebaseerd filteren om te voorspellen waar gebruikers mogelijk in geïnteresseerd zijn, waardoor bedrijven de betrokkenheid, verkoop en klanttevredenheid kunnen verhogen via op maat gemaakte aanbevelingen.
AI-gestuurde aanbevelingen vertegenwoordigen een geavanceerde technologie die machine learning-algoritmen gebruikt om gebruikersgedrag en -voorkeuren te analyseren, waardoor gepersonaliseerde suggesties worden gedaan die zijn afgestemd op individuele behoeften en interesses. Een aanbevelingsengine is het kernonderdeel van dit systeem en fungeert als een intelligente schakel tussen enorme productcatalogi en individuele gebruikers, waarmee ongekende niveaus van personalisatie op schaal mogelijk worden. De wereldwijde markt voor aanbevelingsengines heeft een explosieve groei doorgemaakt, met een waarde van ongeveer $2,8 miljard in 2023 en een verwachte groei naar $8,5 miljard in 2030, wat het cruciale belang van deze technologie in de digitale economie weerspiegelt. Deze AI-gestuurde aanbevelingen zijn onmisbaar geworden in diverse sectoren, met prominente toepassingen in e-commerceplatforms zoals Amazon en eBay, streamingdiensten als Netflix en Spotify, sociale medianetwerken en contentplatforms. Het fundamentele principe achter deze systemen is dat machine learning-algoritmen patronen in gebruikersgedrag kunnen herkennen die mensen niet gemakkelijk waarnemen, waardoor bedrijven de behoeften van klanten kunnen voorspellen voordat gebruikers zich hier zelf van bewust zijn. Door gebruik te maken van enorme datasets en rekenkracht hebben aanbevelingssystemen de manier waarop consumenten producten, content en diensten ontdekken getransformeerd, waardoor klantbetrokkenheidsstrategieën in alle sectoren fundamenteel zijn veranderd.

AI-gestuurde aanbevelingssystemen werken via een geavanceerd proces van vijf fasen dat ruwe gebruikersdata omzet in bruikbare gepersonaliseerde suggesties. De eerste fase omvat uitgebreide dataverzameling, waarbij systemen informatie verzamelen uit meerdere contactpunten, waaronder gebruikersinteracties, browsegeschiedenis, aankooprecords en expliciete feedbackmechanismen. Tijdens de analysefase verwerkt het systeem deze verzamelde data om betekenisvolle patronen en relaties te identificeren, waarbij machine learning-algoritmen zoals collaboratief filteren, contentgebaseerd filteren en neurale netwerken worden gebruikt om inzichten uit complexe datasets te halen. De patroonherkenningsfase vormt de computationele kern van het systeem, waarin algoritmen overeenkomsten tussen gebruikers, items of beide identificeren, en wiskundige representaties van voorkeuren en itemkenmerken creëren. De voorspellingsfase gebruikt deze geïdentificeerde patronen om te voorspellen met welke items een gebruiker waarschijnlijk zal interageren, waarbij vertrouwensscores worden toegekend aan potentiële aanbevelingen. Tot slot presenteert de leveringsfase deze voorspellingen aan gebruikers via gepersonaliseerde interfaces, zodat aanbevelingen op optimale momenten in de gebruikersreis verschijnen. Realtime verwerkingsmogelijkheden zijn steeds belangrijker geworden, waarbij moderne systemen aanbevelingen onmiddellijk bijwerken zodra er nieuwe gebruikersdata binnenkomt, waardoor dynamische personalisatie mogelijk is die zich aanpast aan veranderende voorkeuren. Geavanceerde aanbevelingssystemen gebruiken ensemble-methoden die meerdere algoritmen tegelijk combineren, waarbij elk algoritme zijn voorspellingen bijdraagt aan de uiteindelijke, robuustere en nauwkeurigere aanbevelingen dan een enkele aanpak zelfstandig zou kunnen bieden.
Aanbevelingssystemen vertrouwen op twee verschillende categorieën gebruikersdata, die elk unieke inzichten geven in voorkeuren en gedragspatronen:
Expliciete data:
Impliciete data:
Expliciete data geeft directe, ondubbelzinnige signalen van gebruikersvoorkeuren, maar is vaak schaars omdat de meeste gebruikers slechts een klein deel van de beschikbare items beoordelen. Impliciete data daarentegen is overvloedig en wordt continu gegenereerd door normaal gebruikersgedrag, maar vereist geavanceerde interpretatie, omdat bijvoorbeeld het bekijken van een product niet per se een voorkeur aangeeft. De meest effectieve aanbevelingssystemen integreren beide datatypes, waarbij expliciete feedback wordt gebruikt om impliciete signalen te valideren en te kalibreren, zodat volledige gebruikersprofielen ontstaan die zowel uitgesproken als feitelijk gedrag vastleggen.
Collaboratief filteren is een van de fundamentele benaderingen in aanbevelingssystemen en werkt vanuit het principe dat gebruikers met vergelijkbare voorkeuren in het verleden waarschijnlijk ook in de toekomst van vergelijkbare items zullen houden. Deze methode analyseert patronen over hele gebruikerspopulaties om overeenkomsten te identificeren, in tegenstelling tot benaderingen die individuele itemkenmerken onderzoeken. Gebruikersgebaseerd collaboratief filteren identificeert gebruikers met vergelijkbare voorkeurgeschiedenissen als een doelgebruiker en raadt vervolgens items aan die deze vergelijkbare gebruikers goed vonden maar die de doelgebruiker nog niet is tegengekomen, waarbij wordt geprofiteerd van de wijsheid van gelijkgestemden. Itemgebaseerd collaboratief filteren richt zich daarentegen op overeenkomsten tussen items, en raadt producten aan die lijken op items die de gebruiker eerder hoog heeft beoordeeld, op basis van hoe andere gebruikers deze items onderling hebben beoordeeld. Beide benaderingen gebruiken geavanceerde vergelijkingsmaten zoals cosinus-similariteit, Pearson-correlatie of Euclidische afstand om te kwantificeren hoe sterk gebruikers of items op elkaar lijken in het voorkeurenlandschap. Collaboratief filteren biedt belangrijke voordelen, waaronder de mogelijkheid om items zonder contentmetadata aan te bevelen en het ontdekken van onverwachte aanbevelingen waar gebruikers zelf niet aan zouden denken. De aanpak kent echter ook beperkingen, met name het “cold start-probleem” waarbij nieuwe gebruikers of items onvoldoende historische data hebben voor nauwkeurige vergelijkingen, en het probleem van dataschaarste in domeinen met miljoenen items, waar de meeste interacties niet waargenomen worden.
Contentgebaseerd filteren benadert aanbevelingen door de intrinsieke kenmerken en eigenschappen van items zelf te analyseren, en raadt producten aan die vergelijkbaar zijn met de items waar een gebruiker eerder de voorkeur aan gaf, gebaseerd op meetbare attributen. In plaats van te vertrouwen op collectieve gebruikerspatronen, bouwen contentgebaseerde systemen gedetailleerde itemprofielen op met relevante kenmerken zoals genre, regisseur en cast bij films; auteur, onderwerp en publicatiedatum bij boeken; of productcategorie, merk en specificaties bij e-commerceproducten. Het systeem berekent de overeenkomst tussen items door hun featurevectoren te vergelijken met wiskundige technieken zoals cosinus-similariteit of Euclidische afstand, en creëert zo een kwantitatieve maatstaf voor de gelijkenis in feature-ruimte. Wanneer een gebruiker een item beoordeelt of ermee interageert, identificeert het systeem andere items met vergelijkbare kenmerken en beveelt die alternatieven aan, waardoor suggesties worden gepersonaliseerd op basis van voorkeuren voor specifieke itemeigenschappen. Contentgebaseerd filteren is ideaal in situaties waar itemmetadata rijk en gestructureerd zijn, en het lost vanzelf het cold start-probleem op voor nieuwe items, omdat aanbevelingen afhankelijk zijn van itemkenmerken in plaats van historische gebruikersinteracties. Deze benadering kent echter beperkingen op het gebied van verrassende ontdekkingen, omdat veelal sterk gelijkende items worden aanbevolen, wat kan leiden tot filterbubbels die gebruikers beperken tot smalle categorieën. In vergelijking met collaboratief filteren vereist contentgebaseerde filtering expliciete feature engineering en is het minder geschikt voor items zonder duidelijke kenmerken, maar het biedt wel transparantie omdat aanbevelingen verklaarbaar zijn met verwijzing naar specifieke itemeigenschappen.
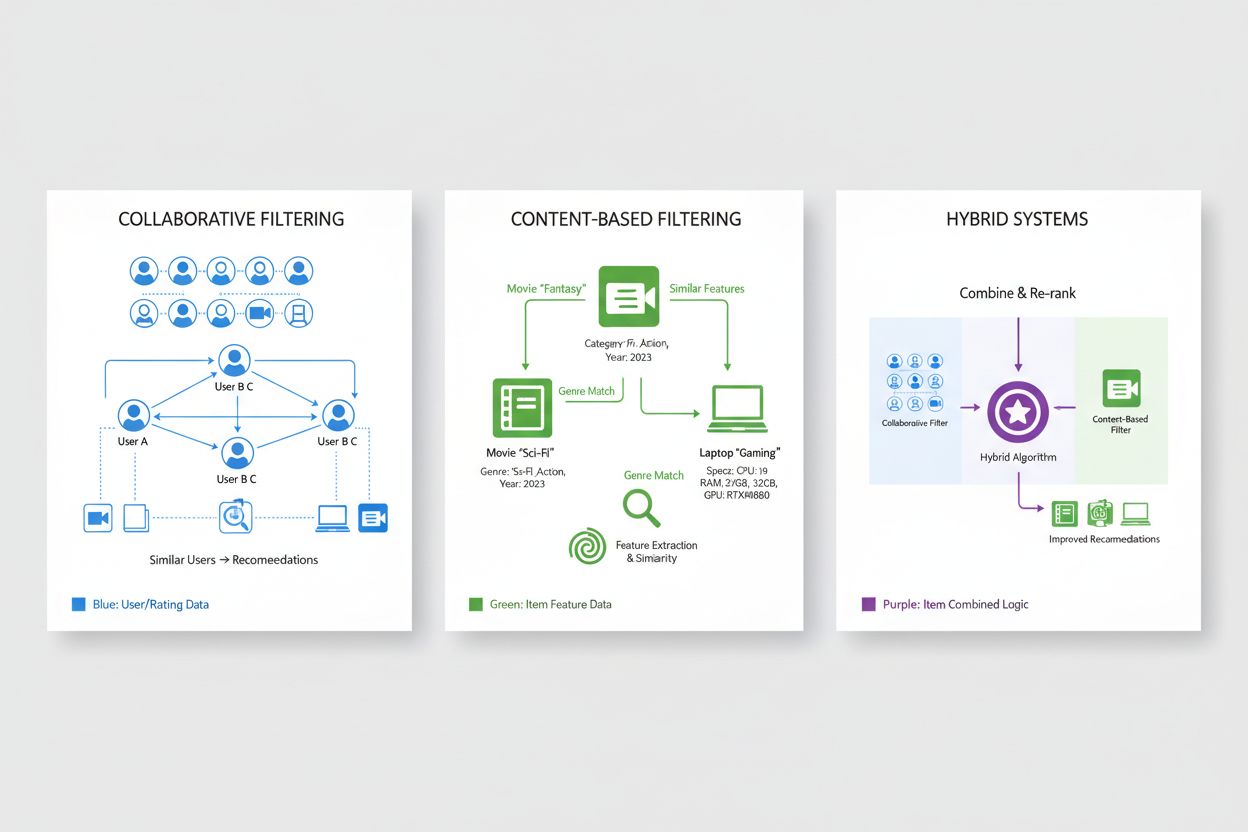
Hybride aanbevelingssystemen combineren strategisch collaboratief en contentgebaseerd filteren, waarbij de complementaire sterke punten van beide methoden worden benut om individuele beperkingen te overwinnen en een hogere aanbevelingsnauwkeurigheid te leveren. Deze systemen gebruiken verschillende integratiestrategieën, waaronder gewogen combinaties waarbij voorspellingen van meerdere algoritmen worden samengevoegd met vooraf bepaalde of geleerde gewichten, schakelmechanismen die het meest geschikte algoritme selecteren op basis van context, of cascadebenaderingen waarbij de output van het ene algoritme als input dient voor het andere. Door collaboratief filteren in te zetten voor het ontdekken van onverwachte aanbevelingen en complexe voorkeurspatronen, en contentgebaseerd filteren voor het behandelen van nieuwe items en het bieden van uitlegbare aanbevelingen, bereiken hybride systemen robuustere prestaties in uiteenlopende scenario’s. Grote technologiebedrijven hebben hybride benaderingen omarmd als industriestandaard; Netflix combineert collaboratief filteren met contentgebaseerde methoden en contextuele informatie om aanbevelingen te doen die populariteit, personalisatie en nieuwheid in balans brengen. De aanbevelingsengine van Spotify gebruikt eveneens hybride technieken, waarbij collaboratief filteren op basis van luisterpatronen wordt gecombineerd met contentanalyse van audio-eigenschappen en metadata, aangevuld met natuurlijke taalverwerking van door gebruikers samengestelde afspeellijsten en reviews. De voordelen van hybride systemen gaan verder dan verbeterde nauwkeurigheid: ze bieden betere dekking van het aanbod, gaan efficiënter om met schaarse data en zijn veerkrachtiger tegen veelvoorkomende uitdagingen in aanbevelingen. Deze systemen zijn de huidige stand van de techniek op het gebied van personalisatie, waarbij de meeste grootschalige aanbevelingsplatforms hybride architecturen gebruiken die continu evolueren met nieuwe algoritmische innovaties.
AI-gestuurde aanbevelingen zijn centraal komen te staan in de bedrijfsmodellen van grote technologie- en retailbedrijven, en transformeren fundamenteel hoe klanten producten ontdekken en kopen. Amazon, de e-commercepionier, genereert ongeveer 35% van de totale omzet via aanbevelingsgestuurde aankopen, waarbij het geavanceerde systeem browsegeschiedenis, aankoopgedrag, productbeoordelingen en vergelijkbare klantpatronen analyseert om op kritieke momenten in het kooptraject suggesties te doen. Netflix verwerkt kijkgeschiedenis, beoordelingen, zoekgedrag en tijdspatronen om content aan te bevelen; het bedrijf rapporteert dat gepersonaliseerde aanbevelingen ongeveer 80% van de bekeken uren op het platform verklaren, wat het enorme effect van effectieve personalisatie op gebruikersbetrokkenheid en retentie aantoont. Spotify gebruikt AI-gestuurde aanbevelingen op meerdere plekken, waaronder de “Discover Weekly”-afspeellijst, die collaboratief filteren combineert met analyse van audio-eigenschappen en contextuele informatie, en zo zeer gepersonaliseerde muziekvoorstellen genereert die centraal staan in gebruikersbetrokkenheid en abonnementsbehoud. Temu, het snelgroeiende e-commerceplatform, past geavanceerde aanbevelingssystemen toe die gebruikersgedrag, zoekopdrachten en aankoopgeschiedenis analyseren om producten te tonen die aansluiten bij individuele voorkeuren, wat aanzienlijk bijdraagt aan de snelle groei en betrokkenheid van gebruikers. Deze toepassingen tonen aan dat aanbevelingssystemen direct invloed hebben op belangrijke bedrijfsstatistieken zoals klantwaarde, herhaalaankopen en gebruikersduur, waarbij bedrijven fors investeren in aanbevelingstechnologie als onderscheidende factor in steeds drukkere digitale markten.
AI-gestuurde aanbevelingen leveren aanzienlijke waarde voor zowel bedrijven als gebruikers, en creëren een wederzijds voordelig ecosysteem dat betrokkenheid en tevredenheid stimuleert:
Zakelijke voordelen:
Gebruikersvoordelen:
De gezamenlijke impact van deze voordelen heeft aanbevelingssystemen tot essentiële infrastructuur gemaakt voor digitale handel en contentplatforms, waarbij gebruikers steeds meer gepersonaliseerde ervaringen als standaard verwachten in plaats van als luxe.
Ondanks hun wijdverbreide succes staan AI-gestuurde aanbevelingssystemen voor aanzienlijke uitdagingen die onderzoekers en praktijkmensen blijven aanpakken. Zorgen over gegevensprivacy zijn toegenomen nu regelgevingen zoals AVG en CCPA strikte eisen stellen aan dataverzameling en -gebruik, waardoor bedrijven moeten balanceren tussen effectieve personalisatie en gebruikersrechten op privacy en gegevensbescherming. Het cold start-probleem blijft vooral lastig bij nieuwe gebruikers en items, waar onvoldoende historische data nauwkeurige aanbevelingen verhindert en hybride benaderingen of alternatieve strategieën nodig zijn om personalisatie te starten. Algoritmische bias vormt een cruciale uitdaging, omdat aanbevelingssystemen bestaande vooroordelen in trainingsdata kunnen versterken, wat kan leiden tot discriminatie van bepaalde groepen of het creëren van filterbubbels die de blootstelling aan diverse perspectieven beperken.
Opkomende trends veranderen het landschap van aanbevelingen, waarbij realtime personalisatie steeds geavanceerder wordt via edge computing en streamverwerking die onmiddellijke aanpassing aan gebruikersgedrag mogelijk maken. Multimodale dataintegratie breidt zich uit buiten traditionele gedragsindicatoren en omvat visuele kenmerken, audio-eigenschappen, tekstuele content en contextuele informatie, waardoor een rijker en genuanceerder begrip van gebruikersvoorkeuren ontstaat. Emotiegedreven aanbevelingen vormen een nieuw grensgebied in personalisatie, waarbij systemen emotionele context en sentimentanalyse integreren om aanbevelingen te doen die niet alleen aansluiten bij historische voorkeuren maar ook bij actuele emotionele toestanden en behoeften. Toekomstige ontwikkelingen zullen waarschijnlijk focussen op uitlegbaarheid en transparantie, waardoor gebruikers kunnen begrijpen waarom bepaalde aanbevelingen verschijnen en controle krijgen over hun aanbevelingsprofielen. De samenkomst van deze trends voorspelt dat de volgende generatie aanbevelingssystemen privacyvriendelijker, transparanter en emotioneel intelligenter zal zijn, en in staat zal zijn echt transformerende personalisatie te leveren met respect voor gebruikersautonomie en datarechten.
AI-gestuurde aanbevelingen suggereren proactief items op basis van gebruikersgedrag en -voorkeuren zonder dat expliciete zoekopdrachten nodig zijn, terwijl bij traditionele zoekopdrachten gebruikers actief naar producten moeten zoeken. Aanbevelingen gebruiken machine learning om interesses te voorspellen, terwijl zoekopdrachten vertrouwen op het matchen van zoekwoorden. Aanbevelingen zijn gepersonaliseerd voor individuele gebruikers, terwijl zoekresultaten doorgaans algemener zijn. Moderne systemen combineren vaak beide benaderingen voor een optimale gebruikerservaring.
Nieuwe gebruikers hebben te maken met het 'cold start-probleem', waarbij systemen onvoldoende historische data hebben voor nauwkeurige aanbevelingen. Oplossingen zijn onder meer het gebruiken van demografische informatie, het tonen van populaire items, het toepassen van contentgebaseerd filteren op basis van itemkenmerken of het vragen naar expliciete voorkeuren. Hybride systemen combineren meerdere benaderingen om aanbevelingen voor nieuwe gebruikers op gang te brengen. Sommige platforms gebruiken collaboratief filteren met vergelijkbare gebruikersprofielen of contextuele informatie zoals apparaattype en locatie voor de eerste suggesties.
Aanbevelingssystemen verzamelen expliciete gegevens zoals beoordelingen, reviews en gebruikersfeedback, plus impliciete data waaronder browsegeschiedenis, aankooprecords, tijd besteed aan items, zoekopdrachten en klikpatronen. Ze kunnen ook contextuele informatie verzamelen zoals apparaattype, locatie, tijdstip en seizoensinvloeden. Geavanceerde systemen integreren demografische data, sociale connecties en gedragsindicatoren. Alle dataverzameling moet voldoen aan privacyregelgeving zoals AVG en CCPA, waarbij gebruikers toestemming moeten geven en transparant beleid over datagebruik vereist is.
Ja, aanbevelingssystemen kunnen vooroordelen in de trainingsdata in stand houden en versterken, wat kan leiden tot discriminatie van bepaalde gebruikersgroepen of een beperkte blootstelling aan diverse content. Algoritmische bias kan ontstaan door scheve historische data, ondervertegenwoordiging van minderheidsgroepen of feedbackloops die bestaande patronen versterken. Het aanpakken van bias vereist diverse trainingsdata, regelmatige audits, eerlijkheidsmaatstaven en transparant algoritmeontwerp. Bedrijven moeten actief monitoren op bias en strategieën implementeren om eerlijke aanbevelingen te waarborgen voor alle gebruikerssegmenten.
Hybride systemen combineren het vermogen van collaboratief filteren om verrassende aanbevelingen te doen met het vermogen van contentgebaseerd filteren om nieuwe items te behandelen en uitlegbare suggesties te bieden. Deze combinatie overwint individuele beperkingen: collaboratief filteren heeft moeite met nieuwe items, terwijl contentgebaseerd filteren minder verrassend is. Hybride benaderingen gebruiken gewogen combinaties, schakelmechanismen of cascade-methoden om de sterke punten van elk algoritme te benutten. Het resultaat is verbeterde nauwkeurigheid, betere dekking van het aanbod, betere omgang met schaarse data en robuustere prestaties in diverse scenario's.
Privacyzorgen omvatten de uitgebreide dataverzameling die nodig is voor nauwkeurige aanbevelingen, mogelijk ongeautoriseerd gebruik van data, risico's op datalekken en uitdagingen rond naleving van regelgeving zoals AVG, CCPA en vergelijkbare wetten. Gebruikers kunnen zich ongemakkelijk voelen bij het niveau van gedragsmonitoring dat nodig is voor personalisatie. Bedrijven moeten sterke databeveiliging implementeren, expliciete toestemming verkrijgen, transparant zijn over datagebruik en gebruikers controle geven over hun data. Het vinden van een balans tussen effectieve personalisatie en privacybescherming blijft een voortdurende uitdaging in de sector.
Realtime aanbevelingen verwerken gebruikersgedrag direct op het moment dat het plaatsvindt, waarbij suggesties onmiddellijk worden bijgewerkt op basis van huidige interacties. Systemen gebruiken streamverwerking en edge computing om acties zoals klikken, bekijken of aankopen binnen milliseconden te analyseren. Dit maakt dynamische personalisatie mogelijk die zich aanpast aan veranderende voorkeuren tijdens een sessie. Realtime systemen vereisen robuuste infrastructuur, efficiënte algoritmen en dataverbindingen met lage latentie. Voorbeelden zijn Netflix dat aanbevelingen bijwerkt tijdens het browsen, of Amazon dat nieuwe suggesties toont zodra je artikelen aan je winkelwagen toevoegt.
Toekomstige trends omvatten emotiegedreven aanbevelingen die rekening houden met de emotionele toestand van gebruikers, integratie van multimodale data waarbij visuele, audio- en tekstuele informatie wordt gecombineerd, verbeterde privacybeschermende technieken, betere uitlegbaarheid en transparantie, en realtime personalisatie op grote schaal. Opkomende technologieën zoals federated learning maken aanbevelingen mogelijk zonder gebruikersdata te centraliseren. Systemen worden contextbewuster en nemen tijdsgebonden en situationele informatie mee. De samenkomst van deze trends zal zorgen voor meer geavanceerde, transparante en privacyvriendelijke personalisatie, met respect voor gebruikersautonomie en datarechten.
AmICited volgt hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews jouw merk benoemen in gepersonaliseerde aanbevelingen en door AI gegenereerde content. Blijf op de hoogte van de zichtbaarheid van jouw merk in AI-gestuurde systemen.
Ontdek wat AI-verlanglijsten zijn, hoe ze werken en hun impact op conversiepercentages in e-commerce, klantbehoud en gepersonaliseerde winkelervaringen.

Ontdek hoe AI productaanbevelingen werken, de algoritmen erachter en hoe je je zichtbaarheid optimaliseert in AI-gestuurde aanbevelingssystemen op ChatGPT, Perp...
Ontdek de toekomst van adverteren in AI-zoekopdrachten: verwachte groei tot $26 miljard in 2029, platformstrategieën, uitdagingen voor merkzichtbaarheid en hoe ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.