
Kan AI Toegang Krijgen tot Afgeschermde Content? Methoden en Gevolgen
Ontdek hoe AI-systemen toegang krijgen tot betaalde en afgeschermde content, welke technieken ze gebruiken en hoe je je content kunt beschermen terwijl je AI-zi...
7 min lezen
Cross-Origin AI-toegang verwijst naar het vermogen van kunstmatige intelligentiesystemen en webcrawlers om content op te vragen en op te halen van domeinen die verschillen van hun oorsprong, beheerst door beveiligingsmechanismen zoals CORS. Het omvat hoe AI-bedrijven het verzamelen van data opschalen voor het trainen van grote taalmodellen, terwijl ze omgaan met cross-origin beperkingen. Inzicht in dit concept is essentieel voor contentmakers en website-eigenaren om intellectueel eigendom te beschermen en de controle te behouden over hoe hun content wordt gebruikt door AI-systemen. Inzicht in cross-origin AI-activiteit helpt onderscheid te maken tussen legitieme AI-toegang en ongeoorloofd scrapen.
Cross-Origin AI-toegang verwijst naar het vermogen van kunstmatige intelligentiesystemen en webcrawlers om content op te vragen en op te halen van domeinen die verschillen van hun oorsprong, beheerst door beveiligingsmechanismen zoals CORS. Het omvat hoe AI-bedrijven het verzamelen van data opschalen voor het trainen van grote taalmodellen, terwijl ze omgaan met cross-origin beperkingen. Inzicht in dit concept is essentieel voor contentmakers en website-eigenaren om intellectueel eigendom te beschermen en de controle te behouden over hoe hun content wordt gebruikt door AI-systemen. Inzicht in cross-origin AI-activiteit helpt onderscheid te maken tussen legitieme AI-toegang en ongeoorloofd scrapen.
Cross-Origin AI-toegang verwijst naar het vermogen van kunstmatige intelligentiesystemen en webcrawlers om content op te vragen en op te halen van domeinen die verschillen van hun oorsprong, beheerst door beveiligingsmechanismen zoals Cross-Origin Resource Sharing (CORS). Nu AI-bedrijven hun inspanningen voor dataverzameling opschalen om grote taalmodellen en andere AI-systemen te trainen, is inzicht in hoe deze systemen omgaan met cross-origin beperkingen essentieel geworden voor contentmakers en website-eigenaren. De uitdaging is het onderscheid te maken tussen legitieme AI-toegang voor zoekindexering en ongeoorloofd scrapen voor modeltraining, waardoor inzicht in cross-origin AI-activiteit onmisbaar is voor het beschermen van intellectueel eigendom en het behouden van controle over het gebruik van content.
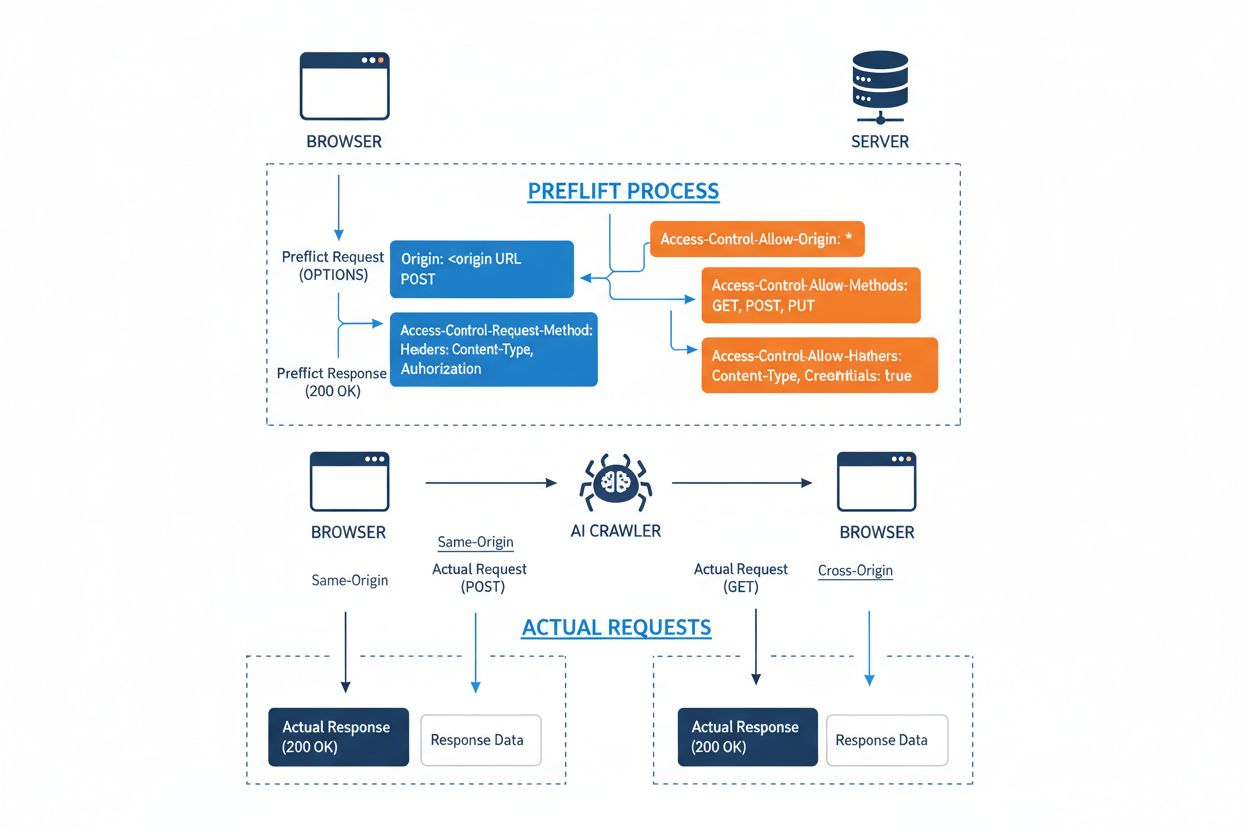
Cross-Origin Resource Sharing (CORS) is een op HTTP-headers gebaseerd beveiligingsmechanisme waarmee servers kunnen aangeven welke origins (domeinen, schema’s of poorten) toegang krijgen tot hun bronnen. Wanneer een AI-crawler of een andere client een bron van een andere origin probeert te benaderen, start de browser of client een preflight-verzoek via de OPTIONS HTTP-methode om te controleren of de server het daadwerkelijke verzoek toestaat. De server reageert met specifieke CORS-headers die toegangsrechten bepalen, waaronder welke origins zijn toegestaan, welke HTTP-methoden zijn toegestaan, welke headers mogen worden meegegeven en of er credentials zoals cookies of authenticatietokens met het verzoek mogen worden meegestuurd.
| CORS-header | Doel |
|---|---|
Access-Control-Allow-Origin | Geeft aan welke origins toegang hebben tot de bron (* voor allemaal, of specifieke domeinen) |
Access-Control-Allow-Methods | Lijst van toegestane HTTP-methoden (GET, POST, PUT, DELETE, etc.) |
Access-Control-Allow-Headers | Definieert welke request headers zijn toegestaan (Authorization, Content-Type, etc.) |
Access-Control-Allow-Credentials | Bepaalt of credentials (cookies, auth tokens) mogen worden meegestuurd |
Access-Control-Max-Age | Geeft aan hoe lang preflight-antwoorden gecachet mogen worden (in seconden) |
Access-Control-Expose-Headers | Lijst van response headers die door clients benaderd mogen worden |
AI-crawlers gaan om met CORS door deze headers te respecteren wanneer ze correct zijn ingesteld, al proberen veel geavanceerde bots deze beperkingen te omzeilen door user agents te spoofen of proxy-netwerken te gebruiken. De effectiviteit van CORS als verdediging tegen ongeoorloofde AI-toegang hangt volledig af van een juiste serverconfiguratie en de bereidheid van de crawler om de beperkingen te respecteren—een cruciaal onderscheid dat steeds belangrijker wordt naarmate AI-bedrijven strijden om trainingsdata.
Het landschap van AI-crawlers die het web benaderen is enorm gegroeid, waarbij enkele grote spelers de cross-origin toegangspatronen domineren. Volgens Cloudflare’s analyse van netwerkverkeer zijn de meest voorkomende AI-crawlers:
Deze crawlers genereren maandelijks miljarden verzoeken, waarbij enkele zoals Bytespider en GPTBot het grootste deel van de openbaar beschikbare internetcontent benaderen. Het enorme volume en het agressieve karakter van deze activiteit heeft grote platforms zoals Reddit, Twitter/X, Stack Overflow en talrijke nieuwsorganisaties ertoe aangezet blokkeermaatregelen te nemen.
Verkeerd ingestelde CORS-beleidsregels creëren aanzienlijke beveiligingskwetsbaarheden die AI-crawlers kunnen misbruiken om zonder toestemming toegang te krijgen tot gevoelige data. Wanneer servers Access-Control-Allow-Origin: * instellen zonder juiste validatie, geven ze onbedoeld elke origin—including kwaadaardige AI-scrapers—toegang tot bronnen die beperkt zouden moeten zijn. Een bijzonder gevaarlijke configuratie ontstaat wanneer Access-Control-Allow-Credentials: true wordt gecombineerd met wildcard origin-instellingen, waardoor aanvallers geauthentiseerde gebruikersdata kunnen stelen door cross-origin verzoeken te doen die sessiecookies of authenticatietokens bevatten.
Veelvoorkomende CORS-misconfiguraties zijn onder meer het dynamisch terugspiegelen van de Origin-header direct in het Access-Control-Allow-Origin-antwoord zonder validatie, wat feitelijk elke origin toegang geeft tot de bron. Te ruime allow-lists die domeingrenzen onvoldoende controleren, kunnen worden uitgebuit via subdomeinaanvallen of prefixmanipulatie. Daarnaast implementeren veel organisaties geen goede validatie van de Origin-header zelf, waardoor ze kwetsbaar zijn voor gespoofde verzoeken. De gevolgen van deze kwetsbaarheden reiken verder dan datadiefstal en omvatten ongeoorloofde training van AI-modellen op eigendomscontent, verzamelen van concurrentie-informatie en schending van intellectuele eigendomsrechten—risico’s die tools zoals AmICited.com helpen monitoren en kwantificeren.
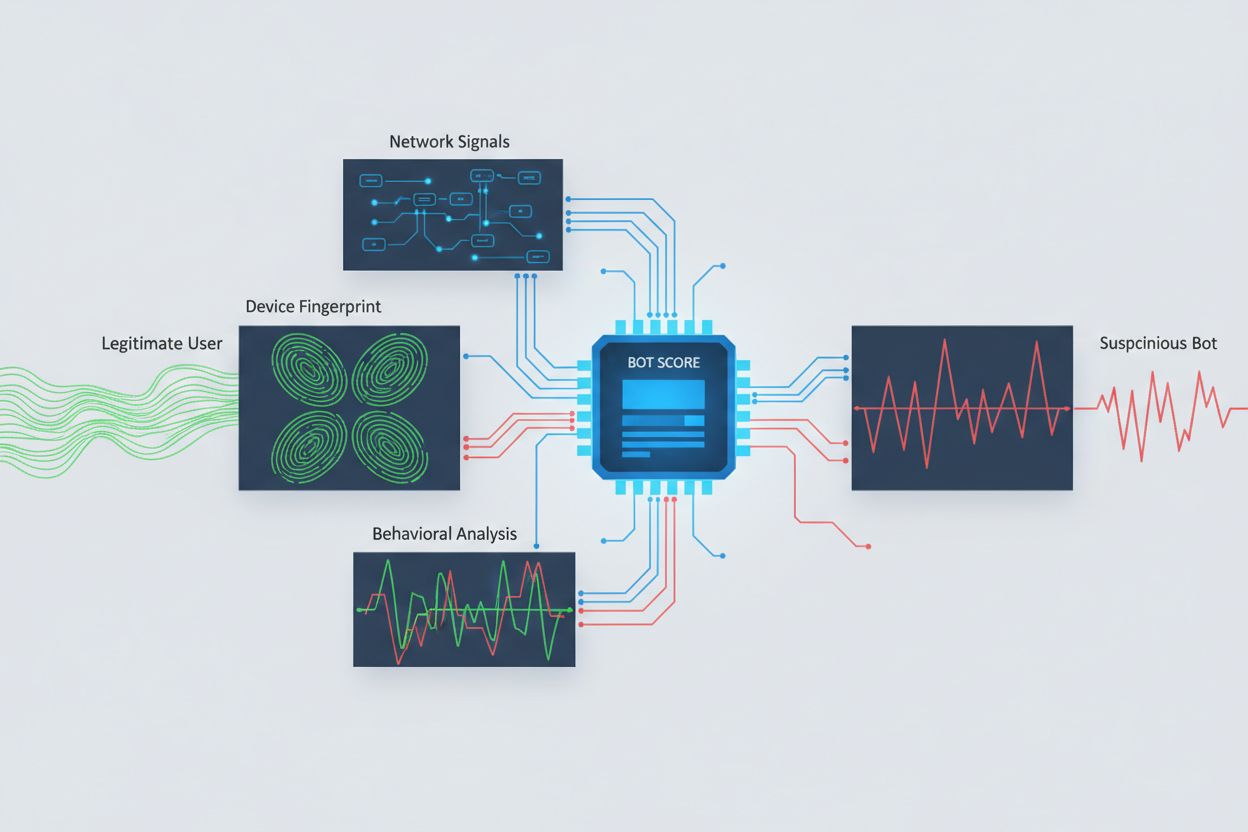
Het identificeren van AI-crawlers die cross-origin toegang proberen te krijgen vereist analyse van meerdere signalen, verder dan alleen user agent strings, die eenvoudig te spoofen zijn. User agent-analyse blijft een eerste detectiemethode, aangezien veel AI-crawlers zichzelf identificeren via specifieke user agent strings zoals “GPTBot/1.0” of “ClaudeBot/1.0”, hoewel geavanceerde crawlers bewust hun identiteit maskeren door zich voor te doen als legitieme browsers. Gedragsfingerprinting analyseert hoe verzoeken worden gedaan—door bijvoorbeeld te kijken naar tijdspatronen van verzoeken, de volgorde van bezochte pagina’s, de aanwezigheid of afwezigheid van JavaScript-uitvoering en interactiepatronen die wezenlijk verschillen van menselijk surfgedrag.
Netwerksignaalanalyse biedt diepere detectiemogelijkheden door het onderzoeken van TLS-handshakehandtekeningen, IP-reputatie, DNS-resolutiepatronen en verbindingskenmerken die botactiviteit onthullen, zelfs wanneer user agents worden gespoofd. Device fingerprinting aggregeert tientallen signalen zoals browserversie, schermresolutie, geïnstalleerde lettertypen, besturingssysteemdetails en JA3 TLS-vingerafdrukken om unieke identificatiekenmerken per bron te creëren. Geavanceerde detectiesystemen kunnen herkennen wanneer meerdere sessies afkomstig zijn van hetzelfde apparaat of script, zodat verspreide scrape-pogingen worden herkend die proberen rate limiting te omzeilen door verzoeken over veel IP-adressen te verdelen. Organisaties kunnen deze detectiemethoden benutten via beveiligingsplatforms en monitoringdiensten om inzicht te krijgen in welke AI-systemen hun content benaderen en hoe ze proberen beperkingen te omzeilen.
Organisaties passen meerdere complementaire strategieën toe om cross-origin AI-toegang te blokkeren of te beheersen, in het besef dat geen enkele methode volledige bescherming biedt:
User-agent: GPTBot gevolgd door Disallow: /) voor een beleefd maar vrijwillig mechanisme; effectief bij goedgedragende crawlers maar eenvoudig te negeren door vastberaden scrapersDe meest effectieve verdediging combineert meerdere lagen, omdat vastberaden aanvallers zwakke plekken in elke enkele methode zullen uitbuiten. Organisaties moeten continu monitoren welke blokkeringsmaatregelen werken en zich aanpassen naarmate crawlers hun ontwijkingstechnieken verder ontwikkelen.
Effectief beheer van cross-origin AI-toegang vereist een allesomvattende, gelaagde aanpak die beveiliging in balans brengt met operationele behoeften. Organisaties dienen een getrapte strategie te hanteren die begint met basiscontroles zoals robots.txt en user agent filtering, en vervolgens steeds geavanceerdere detectie- en blokkeermechanismen toevoegt op basis van waargenomen dreigingen. Continue monitoring is essentieel—het bijhouden van welke AI-systemen je content benaderen, hoe vaak ze verzoeken doen en of ze je beperkingen respecteren, geeft het inzicht dat nodig is om weloverwogen beslissingen te nemen over toegangsbeleid.
Documentatie van toegangsbeleid moet duidelijk en afdwingbaar zijn, met expliciete gebruiksvoorwaarden die ongeoorloofd scrapen verbieden en de gevolgen van overtredingen vermelden. Regelmatige audits van CORS-configuraties helpen misconfiguraties te identificeren voordat ze worden uitgebuit, terwijl een bijgewerkte inventaris van bekende AI-crawler user agents en IP-reeksen snelle reactie op nieuwe dreigingen mogelijk maakt. Organisaties moeten ook de zakelijke implicaties van het blokkeren van AI-toegang overwegen—sommige AI-crawlers leveren waarde door zoekindexering of legitieme samenwerkingen, dus beleid dient onderscheid te maken tussen nuttige en schadelijke toegangspatronen. Het implementeren van deze best practices vereist coördinatie tussen security, legal en business teams om ervoor te zorgen dat beleid aansluit bij de organisatiedoelstellingen en wettelijke vereisten.
Gespecialiseerde tools en platforms zijn ontwikkeld om organisaties te helpen cross-origin AI-toegang nauwkeuriger en met meer inzicht te monitoren en te beheersen. AmICited.com biedt uitgebreide monitoring van hoe AI-systemen jouw merk refereren en benaderen via GPT’s, Perplexity, Google AI Overviews en andere AI-platforms, en biedt inzicht in welke AI-modellen jouw content gebruiken en hoe vaak jouw merk voorkomt in AI-gegenereerde antwoorden. Deze monitoring strekt zich uit tot het volgen van cross-origin toegangspatronen en het begrijpen van het bredere ecosysteem van AI-systemen die interactie hebben met je digitale bezittingen.
Naast monitoring biedt Cloudflare botmanagementfuncties met eenmalige blokkering van bekende AI-crawlers, met behulp van machine learning modellen die getraind zijn op netwerkbreed verkeer om bots te identificeren, zelfs wanneer ze user agents spoofen. AWS WAF (Web Application Firewall) biedt aanpasbare regels voor het blokkeren van specifieke user agents en IP-reeksen, terwijl Imperva geavanceerde botdetectie levert door gedragsanalyse te combineren met threat intelligence. Bright Data is gespecialiseerd in inzicht in botverkeerpatronen en kan organisaties helpen verschillende typen crawlers te onderscheiden. De keuze van tools hangt af van de grootte van de organisatie, technische volwassenheid en specifieke vereisten—van eenvoudige robots.txt-beheer voor kleine sites tot enterprise-grade botmanagement voor grote organisaties met gevoelige data. Ongeacht de toolkeuze blijft het fundamentele principe: inzicht in cross-origin AI-toegang is de basis voor effectieve controle en bescherming van digitale assets.
CORS (Cross-Origin Resource Sharing) is een beveiligingsmechanisme dat bepaalt welke origins toegang hebben tot bronnen op een server. Cross-Origin AI-toegang verwijst specifiek naar hoe AI-systemen en crawlers omgaan met CORS om content op te vragen van verschillende domeinen. Waar CORS het technische kader is, beschrijft Cross-Origin AI-toegang de praktische uitdaging om AI-crawlergedrag binnen dat kader te beheren, inclusief het detecteren en blokkeren van ongeoorloofde AI-toegang.
De meeste goedgedragende AI-crawlers identificeren zichzelf via specifieke user-agent strings zoals 'GPTBot/1.0' of 'ClaudeBot/1.0' die duidelijk hun doel aangeven. Veel geavanceerde crawlers spoofen echter bewust user agents door zich voor te doen als legitieme browsers zoals Chrome of Safari om blokkades op basis van user agents te omzeilen. Daarom zijn geavanceerde detectiemethoden met gedragsfingerprinting en netwerksignaalanalyse noodzakelijk om bots te identificeren, ongeacht hun opgegeven identiteit.
robots.txt biedt een vrijwillig mechanisme om crawlers te verzoeken toegangsbeperkingen te respecteren, en goedgedragende AI-crawlers zoals GPTBot houden zich hier doorgaans aan. robots.txt is echter niet afdwingbaar—vaste scrapers kunnen het eenvoudig negeren. Veel AI-bedrijven zijn betrapt op het omzeilen van robots.txt-beperkingen, waardoor het een noodzakelijke maar onvoldoende verdediging is die gecombineerd moet worden met technische blokkades zoals user agent filtering, rate limiting en device fingerprinting.
Verkeerd ingestelde CORS-beleidsregels kunnen ongeoorloofde AI-crawlers toegang geven tot gevoelige data, geauthentiseerde gebruikersinformatie stelen via verzoeken met inloggegevens en eigendomscontent scrapen voor ongeautoriseerde AI-modeltraining. De gevaarlijkste configuraties combineren wildcard origin-instellingen met toestaan van credentials, waardoor elke origin toegang kan krijgen tot beschermde bronnen. Deze misconfiguraties kunnen leiden tot diefstal van intellectueel eigendom, verzamelen van concurrentie-informatie en schending van licentieovereenkomsten voor content.
Detectie vereist het analyseren van meerdere signalen, meer dan alleen user agent strings. Je kunt serverlogs onderzoeken op bekende AI-crawler user agents, gedragsfingerprinting toepassen om bots te identificeren aan de hand van interactiepatronen, netwerksignalen zoals TLS-handshakes en DNS-patronen analyseren en device fingerprinting gebruiken om verspreid scrape-pogingen te herkennen. Tools zoals AmICited.com bieden uitgebreide monitoring van hoe AI-systemen jouw merk refereren, terwijl platforms zoals Cloudflare machine learning gebruiken voor botdetectie die zelfs gespoofde crawlers herkent.
Geen enkele methode biedt volledige bescherming, dus een gelaagde aanpak is het meest effectief. Begin met robots.txt en user agent filtering voor basisverdediging, voeg rate limiting toe om de impact te verkleinen, implementeer device fingerprinting om geavanceerde bots te vangen en overweeg authenticatie of betaalmuren voor gevoelige content. De meest effectieve organisaties combineren meerdere technieken en monitoren continu welke maatregelen werken en passen zich aan naarmate crawlers hun ontwijkingstechnieken ontwikkelen.
Nee. Grote bedrijven zoals OpenAI en Anthropic beweren robots.txt en CORS-beperkingen te respecteren, maar uit onderzoek blijkt dat veel AI-crawlers deze beperkingen omzeilen. Perplexity AI werd betrapt op het spoofen van user agents om blokkades te omzeilen, en onderzoek toont aan dat crawlers van OpenAI en Anthropic content benaderden ondanks expliciete robots.txt-disallow regels. Deze inconsistentie maakt technische blokkades en juridische handhaving steeds noodzakelijker.
AmICited.com biedt uitgebreide monitoring van hoe AI-systemen jouw merk refereren en benaderen via GPT's, Perplexity, Google AI Overviews en andere AI-platforms. Het volgt welke AI-modellen jouw content gebruiken, hoe vaak jouw merk verschijnt in AI-gegenereerde antwoorden en biedt inzicht in het bredere ecosysteem van AI-systemen die interactie hebben met jouw digitale eigendommen. Deze monitoring helpt je het bereik van AI-toegang te begrijpen en weloverwogen beslissingen te nemen over je contentbeschermingsstrategie.
Krijg volledig inzicht in welke AI-systemen jouw merk benaderen via GPT's, Perplexity, Google AI Overviews en andere platforms. Volg patronen van cross-origin AI-toegang en begrijp hoe jouw content wordt gebruikt in AI-training en -inference.
Ontdek hoe AI-systemen toegang krijgen tot betaalde en afgeschermde content, welke technieken ze gebruiken en hoe je je content kunt beschermen terwijl je AI-zi...

Ontdek hoe cross-platform AI publishing content verspreidt over meerdere kanalen geoptimaliseerd voor AI-ontdekking. Begrijp PESO-kanalen, voordelen van automat...
Ontdek hoe je je content zichtbaar maakt voor AI-crawlers zoals ChatGPT, Perplexity en Google's AI. Leer technische vereisten, best practices en monitoringstrat...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.