Hoe vind je contentgaten voor AI-zoekopdrachten - Complete Strategie
Leer hoe je contentgaten identificeert voor AI-zoekmachines zoals ChatGPT en Perplexity. Ontdek methoden om LLM-zichtbaarheid te analyseren, ontbrekende onderwe...
9 min lezen
Query Anticipation is de strategische praktijk van het identificeren en creëren van content die inspeelt op vervolgvragen die gebruikers waarschijnlijk zullen stellen na hun eerste zoekopdracht in door AI aangedreven zoeksystemen. Deze aanpak is cruciaal voor AI-zoekopdrachten omdat moderne taalmodellen niet alleen het directe antwoord geven—ze anticiperen op wat gebruikers hierna willen weten en tonen proactief relevante content.
Query Anticipation is de strategische praktijk van het identificeren en creëren van content die inspeelt op vervolgvragen die gebruikers waarschijnlijk zullen stellen na hun eerste zoekopdracht in door AI aangedreven zoeksystemen. Deze aanpak is cruciaal voor AI-zoekopdrachten omdat moderne taalmodellen niet alleen het directe antwoord geven—ze anticiperen op wat gebruikers hierna willen weten en tonen proactief relevante content.
Query Anticipation is de strategische praktijk van het identificeren en creëren van content die inspeelt op vervolgvragen die gebruikers waarschijnlijk zullen stellen na hun eerste zoekopdracht in door AI aangedreven zoeksystemen. In tegenstelling tot traditionele SEO, die zich richt op het matchen van exacte zoekwoorden en het scoren op specifieke zoektermen, vereist Query Anticipation dat contentmakers meerdere stappen vooruit denken in de informatiezoektocht van de gebruiker. Deze aanpak is cruciaal voor AI-zoekopdrachten omdat moderne taalmodellen niet alleen de directe vraag beantwoorden—ze anticiperen op wat gebruikers hierna willen weten en tonen proactief relevante content. Door deze verwachte vragen te begrijpen en te behandelen, kunnen contentmakers hun zichtbaarheid op AI-platforms als ChatGPT, Claude, Perplexity en Google’s AI Overviews aanzienlijk vergroten. Query Anticipation betekent een fundamentele verschuiving van zoekwoordgericht naar conversatiegericht denken, waarbij het doel is om gedurende het hele informatieproces van de gebruiker een onmisbare bron te worden.
AI-systemen verwerken gebruikersvragen via een geavanceerd mechanisme dat query fan-out wordt genoemd, waarbij één gebruikersvraag wordt opgedeeld in meerdere gerelateerde subvragen die de AI onderzoekt om een volledig antwoord te bieden. Wanneer een gebruiker een eerste vraag stelt, zoekt de AI niet alleen naar die exacte zin—het genereert een reeks verwachte vervolgvragen en zoekt naar content die zowel de oorspronkelijke vraag als deze voorspelde vervolgstappen behandelt. Dit mechanisme van meerbeurtgesprekken betekent dat content die secundaire en tertiaire vragen behandelt, naar voren kan komen, zelfs als de gebruiker deze niet expliciet stelt. De AI creëert feitelijk een conversatieboom, die uitwaaiert vanaf de hoofdvraag naar gerelateerde onderwerpen, definities, vergelijkingen en praktische toepassingen. Hier is een voorbeeld van hoe dit werkt:
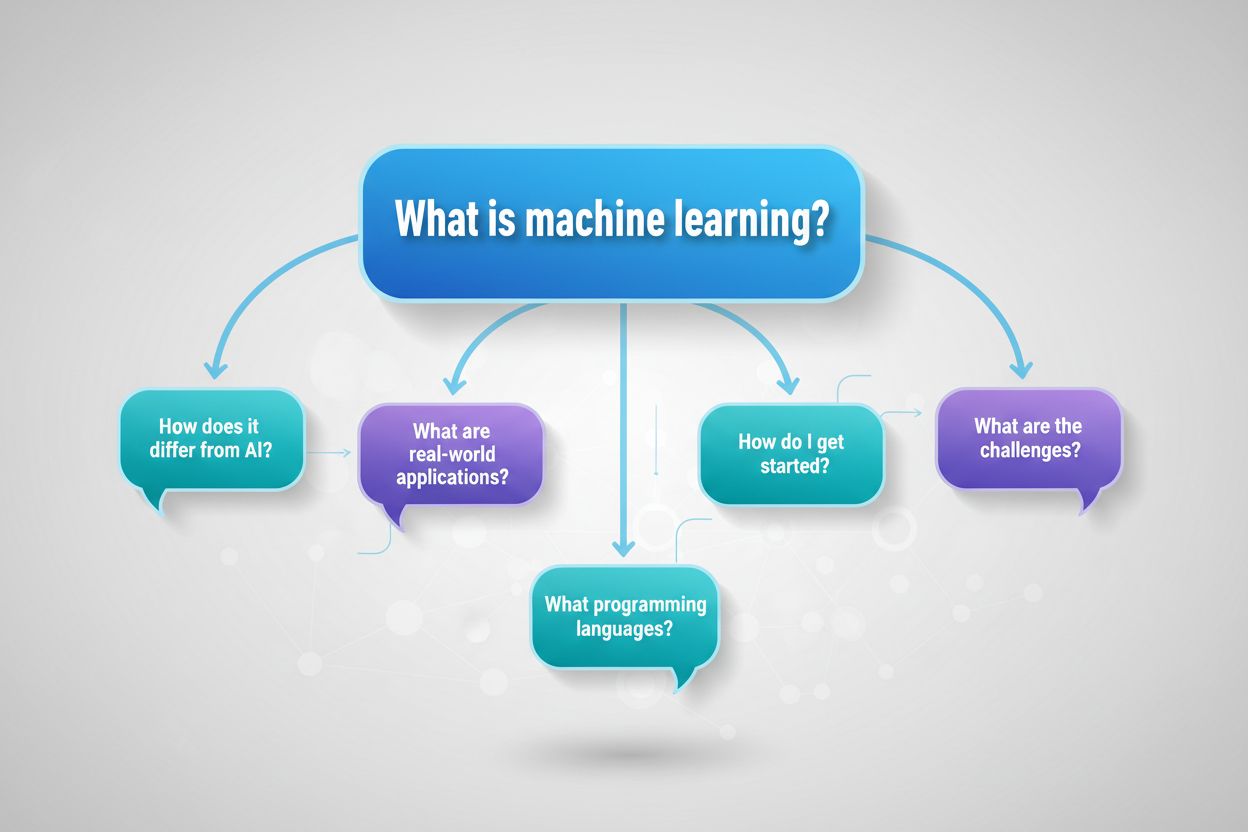
| Hoofdzoekopdracht | Verwachte Vervolgvragen |
|---|---|
| “Wat is machine learning?” | “Hoe verschilt machine learning van AI?” “Wat zijn praktijktoepassingen van machine learning?” “Hoe begin ik met machine learning?” “Welke programmeertalen worden gebruikt voor machine learning?” |
| “Best practices voor remote werken” | “Hoe blijf ik productief thuiswerken?” “Welke tools gebruiken remote teams?” “Hoe houd ik werk-privébalans?” “Wat zijn de uitdagingen van remote werken?” |
Dit fan-out mechanisme begrijpen stelt contentmakers in staat hun materiaal strategisch te positioneren voor zichtbaarheid op meerdere verwachte zoekvertakkingen.
Query Anticipation is belangrijk omdat het direct invloed heeft op de zichtbaarheid van content, citatiefrequentie en gebruikersbetrokkenheid binnen AI-zoekplatforms—het snelst groeiende zoekkanaal van dit moment. Volgens recente gegevens is het gebruik van AI-zoekopdrachten met meer dan 150% jaar-op-jaar toegenomen, met platforms als ChatGPT, Perplexity en Claude die inmiddels miljarden zoekopdrachten per maand verwerken. Content die effectief inspeelt op verwachte vragen, wordt vaker geciteerd omdat het relevant is voor meerdere takken binnen de beslisboom van de AI. Wanneer jouw content wordt geciteerd door AI-systemen, bouwt het autoriteit en vertrouwen op, wat leidt tot meer zichtbaarheid, niet alleen in AI-zoekopdrachten maar ook in traditionele zoekresultaten. Het cumulatieve effect is aanzienlijk: content die goed scoort op verwachte vragen genereert meer verkeer, meer betrokkenheidssignalen en meer kansen op backlinks en sociale shares, wat een positieve spiraal van zichtbaarheid en autoriteit creëert.
Het identificeren van verwachte vragen vereist een combinatie van onderzoeksmethoden en analytisch nadenken over gebruikersgedrag en informatiebehoeften. De meest effectieve aanpak omvat het analyseren van zoekopdrachtlogs en autosuggesties om te zien wat gebruikers daadwerkelijk zoeken ná hun eerste vraag, het houden van gebruikersinterviews en enquêtes om informatiehiaten te begrijpen, het bestuderen van concurrentencontent om te zien welke vervolgonderwerpen worden behandeld, het bekijken van AI-chattranscripten en gespreksgeschiedenis om te zien welke vragen gebruikers stellen in meerbeurtgesprekken, het gebruiken van tools als Answer the Public en SEMrush om vraagclusters en gerelateerde zoekopdrachten te visualiseren, en het analyseren van je eigen websitestatistieken om te zien welke pagina’s gebruikers achtereenvolgens bezoeken. Hier zijn de belangrijkste methoden om verwachte vragen te ontdekken:

Contentstructuur voor Query Anticipation moet hiërarchisch zijn opgebouwd, met je hoofdonderwerp als H1, de belangrijkste verwachte vragen als H2-secties, en diepere vervolgvragen als H3-subsecties. Deze structuur geeft aan AI-systemen aan dat jouw content niet alleen de hoofdvraag behandelt, maar ook de verwachte vervolgvragen die gebruikers waarschijnlijk zullen stellen. Elke sectie moet zelfstandig genoeg zijn om afzonderlijk geciteerd te kunnen worden, terwijl het bijdraagt aan het totaalverhaal. Hier is een voorbeeld van hoe je content voor Query Anticipation structureert:
# Hoofdonderwerp (H1)
Inleidende alinea over de primaire zoekopdracht
## Verwachte Vraag 1 (H2)
Content over de eerste vervolgvraag
### Subvraag 1a (H3)
Diepere verkenning van een gerelateerd concept
### Subvraag 1b (H3)
Een ander perspectief op hetzelfde onderwerp
## Verwachte Vraag 2 (H2)
Content over de tweede vervolgvraag
### Subvraag 2a (H3)
Praktische toepassing of voorbeeld
## Verwachte Vraag 3 (H2)
Content over de derde vervolgvraag
Deze hiërarchische structuur maakt het voor AI-systemen eenvoudig om het verband te begrijpen tussen je hoofdcontent en verwachte vervolgonderwerpen, waardoor de kans op citatie via meerdere zoekvertakkingen toeneemt.
Query Anticipation implementeren vereist een systematische aanpak die begint bij onderzoek en doorloopt tot contentcreatie, optimalisatie en voortdurende verbetering. In plaats van content in isolatie te maken, moet je nadenken over de gehele gespreksreis en zorgen dat je content op alle punten vragen beantwoordt. Het implementatieproces moet methodisch en datagedreven zijn, waarbij inzichten uit gebruikersgedrag en AI-systemen je contentstrategie sturen. Hier is een stapsgewijze aanpak voor Query Anticipation:
Het monitoren en meten van Query Anticipation-succes vereist het bijhouden van metrieken die specifiek AI-zoekzichtbaarheid en citatiepatronen weergeven, die sterk verschillen van traditionele SEO-metingen. De belangrijkste metrieken zijn citatiefrequentie (hoe vaak je content wordt geciteerd in AI-antwoorden), citatiebreedte (voor hoeveel verschillende zoekopdrachten je content wordt geciteerd), en betrokkenheidssignalen vanuit AI-platforms. AmICited.com is de toonaangevende tool om AI-zichtbaarheid te monitoren en biedt gedetailleerd inzicht in welke contentstukken door grote AI-systemen worden geciteerd, welke zoekopdrachten citaties activeren en hoe je prestaties zich verhouden tot die van concurrenten. Naast AmICited.com moet je ook je website-analyse monitoren op verkeer van AI-platforms, je posities in traditionele zoekresultaten voor verwachte vragen volgen en gebruikersbetrokkenheidsstatistieken zoals tijd op pagina en scrolldiepte analyseren om te begrijpen welke verwachte vragen het meest resoneren bij je publiek. Door AI-specifieke metrieken te combineren met traditionele analyses krijg je een compleet beeld van je Query Anticipation-prestaties en kun je verbeterkansen identificeren.
Query Anticipation is een fundamenteel andere aanpak dan traditionele SEO en vereist een mentaliteitsverandering van zoekwoordoptimalisatie naar conversatiekaarten. Waar traditionele SEO zich richt op het scoren op specifieke zoekwoorden en het binnenhalen van zoekvolume per zoekopdracht, richt Query Anticipation zich op het worden van een volledige bron die het hele conversatieproces afdekt. De strategische verschillen zijn groot en vragen om een andere planning, contentcreatie en optimalisatie. Dit is het verschil:
| Aspect | Traditionele SEO | Query Anticipation |
|---|---|---|
| Focus | Individuele zoekwoorden en zoekvolume | Conversatiebomen en zoekopdrachtrelaties |
| Contentstrategie | Optimaliseren voor specifieke zoekwoorden | Hoofdzoekopdracht en alle verwachte vervolgvragen behandelen |
| Succesmeting | Posities en organisch verkeer | AI-citaties en conversatiebereik |
| Contentstructuur | Zoekwoordgeoptimaliseerde pagina’s | Hiërarchische structuur die zoekvertakkingen afdekt |
| Concurrentievoordeel | Zoekwoordtargeting en backlinks | Uitgebreide dekking en conversatiekaarten |
Deze verschillen begrijpen is essentieel om een effectieve Query Anticipation-strategie te ontwikkelen die je traditionele SEO-inspanningen aanvult in plaats van vervangt.
Veelgemaakte fouten bij de implementatie van Query Anticipation kunnen je inspanningen ernstig ondermijnen en leiden tot verspilling van middelen aan ineffectieve contentstrategieën. Een belangrijke valkuil is het anticiperen op vragen die gebruikers in werkelijkheid niet stellen—tijd besteden aan hypothetische vervolgvragen in plaats van te onderzoeken wat gebruikers écht willen weten. Een andere fout is het maken van oppervlakkige content die verwachte vragen slechts summier behandelt; AI-systemen geven de voorkeur aan diepgaande, gezaghebbende content die elk onderwerp grondig uitwerkt. Veel makers vergeten hun content bij te werken als er nieuwe verwachte vragen ontstaan of het gebruikersgedrag verandert, waardoor hun content verouderd raakt en niet meer aansluit bij de informatiebehoefte. Ook maken sommigen de fout om te ver door te schieten in optimalisatie voor AI-systemen, ten koste van de leesbaarheid voor mensen, waardoor onnatuurlijke, niet-betrokken content ontstaat. Best practices zijn onder meer: grondig gebruikersonderzoek doen vóór het maken van content, elke verwachte vraag voldoende diepte en detail geven, je content regelmatig monitoren en bijwerken op basis van prestatiegegevens, natuurlijk en leesbaar schrijven dat zowel mensen als AI-systemen dient, en focussen op echte gebruikersbehoeften in plaats van speculatieve vragen.
De toekomst van Query Anticipation zal zich ontwikkelen naarmate AI-zoeksystemen geavanceerder worden en gebruikersgedrag steeds meer verschuift naar conversationele interfaces. Opkomende trends zijn onder meer AI-systemen die gebruikersintentie met grotere precisie kunnen voorspellen, wat leidt tot nog complexere query fan-out patronen waar contentmakers op moeten anticiperen. Ook zien we de opkomst van multimodale AI-zoekopdrachten die tekst, afbeeldingen, video en andere contenttypen combineren, waardoor Query Anticipation-strategieën zich moeten uitstrekken tot meer dan alleen geschreven content. Naarmate AI-systemen persoonlijker worden, zal Query Anticipation rekening moeten houden met individuele gebruikersvoorkeuren en context, in plaats van one-size-fits-all verwachte vragen. Het concurrentielandschap zal intensiveren naarmate meer makers Query Anticipation-strategieën toepassen, waardoor het steeds belangrijker wordt om niet alleen verwachte vragen te behandelen, maar dit te doen met superieure diepgang, nauwkeurigheid en gebruikerswaarde. Organisaties die nu Query Anticipation beheersen, zullen een aanzienlijk voordeel hebben naarmate AI-zoekopdrachten blijven groeien en de belangrijkste manier worden waarop gebruikers informatie online ontdekken.
Traditioneel zoekwoordenonderzoek richt zich op het identificeren van afzonderlijke zoektermen en het optimaliseren van content voor die specifieke zoekwoorden. Query Anticipation daarentegen, brengt hele conversatiebomen in kaart—niet alleen de hoofdzoekopdracht, maar ook alle vervolgvragen die gebruikers waarschijnlijk zullen stellen. Dit vereist nadenken over gebruikersintentie in meerdere fasen van de informatiezoektocht in plaats van optimaliseren voor losse zoekwoorden.
Je kunt verwachte vragen identificeren via verschillende methoden: het analyseren van zoekopdrachtlogs en autosuggesties, het houden van gebruikersinterviews en enquêtes, het bestuderen van concurrentencontent, het bekijken van AI-chattranscripten, tools als Answer the Public en SEMrush gebruiken, en je eigen website-analyse bekijken om te zien welke pagina's gebruikers achtereenvolgens bezoeken. De sleutel is om meerdere onderzoeksmethoden te combineren voor een compleet beeld van de informatiebehoeften van gebruikers.
Ja, aanzienlijk. Content die effectief inspeelt op verwachte vragen, wordt vaker geciteerd omdat het relevant is voor meerdere takken binnen de beslisboom van de AI. Wanneer jouw content wordt geciteerd door AI-systemen, bouwt het autoriteit en vertrouwen op, wat leidt tot meer zichtbaarheid, niet alleen in AI-zoekopdrachten maar ook in traditionele zoekresultaten. Dit zorgt voor een cumulatief effect van zichtbaarheid en autoriteit.
Gebruik een hiërarchische structuur met je hoofdonderwerp als H1, de belangrijkste verwachte vragen als H2-secties, en diepere vervolgvragen als H3-subsecties. Deze structuur geeft aan AI-systemen aan dat jouw content niet alleen de hoofdvraag behandelt, maar ook verwachte vervolgvragen. Elke sectie moet zelfstandig genoeg zijn om afzonderlijk geciteerd te kunnen worden, terwijl het bijdraagt aan het totaalverhaal.
Volg metingen die specifiek gericht zijn op AI-zoekzichtbaarheid, waaronder citatiefrequentie (hoe vaak jouw content geciteerd wordt), citatiebreedte (voor hoeveel verschillende zoekopdrachten jouw content wordt geciteerd), en betrokkenheidssignalen van AI-platforms. Tools zoals AmICited.com bieden gedetailleerd inzicht in welke contentstukken worden geciteerd, welke zoekopdrachten je citaties activeren, en hoe je prestaties zich verhouden tot concurrenten. Combineer deze met traditionele analyses voor een compleet beeld.
Query Anticipation is vooral waardevol voor uitgebreide, informatieve content die van nature leidt tot vervolgvragen—zoals gidsen, tutorials, how-to-artikelen en educatieve content. Het is minder cruciaal voor transactionele content zoals productpagina's of simpele feitelijke content. Toch kunnen ook productpagina's profiteren door te anticiperen op vragen over specificaties, vergelijkingen en gebruiksmogelijkheden.
Query Anticipation draait fundamenteel om het voorbereiden van je content op conversationele AI-systemen die in interacties met meerdere beurten gaan. Deze systemen geven niet slechts één antwoord en stoppen dan—ze anticiperen op wat gebruikers hierna willen weten en tonen proactief relevante content. Door te begrijpen hoe conversationele AI werkt, kun je je content structureren om aan te sluiten bij de verwachtingen van deze systemen en je zichtbaarheid vergroten.
Verschillende tools ondersteunen je Query Anticipation-strategie: Answer the Public voor vraagonderzoek, Google Trends voor het identificeren van trending gerelateerde zoekopdrachten, SEMrush en Ahrefs voor concurrentieanalyse, Reddit en Quora voor het vinden van echte gebruikersvragen, Google Search Console voor inzicht in zoekgedrag van gebruikers, en AmICited.com om te monitoren hoe jouw content presteert in AI-zoekopdrachten op meerdere platforms.
Volg hoe jouw content wordt geciteerd in ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms. Begrijp welke zoekopdrachten jouw citaties activeren en optimaliseer je Query Anticipation-strategie met echte data.
Leer hoe je contentgaten identificeert voor AI-zoekmachines zoals ChatGPT en Perplexity. Ontdek methoden om LLM-zichtbaarheid te analyseren, ontbrekende onderwe...
Ontdek de beste inhoudsformaten voor AI-zoekmachines zoals ChatGPT, Perplexity en Google AI Overviews. Leer hoe je je content optimaliseert voor AI-zichtbaarhei...
Leer hoe je AI-contentkansen identificeert en benut door merkvermeldingen te monitoren in ChatGPT, Perplexity en andere AI-platforms. Ontdek strategieën om zich...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.